你真的懂自增主键(auto_increment)?
自增主键是我们在设计数据库表结构时经常使用的主键生成策略,主键的生成可以完全依赖数据库,无需人为干预,在新增数据的时候,我们只需要将主键设置为null,0或者不设置该字段,数据库就会为我们自动生成一个主键值。而且,自增主键是整数型,单调递增,对创建索引也十分友好,
自增主键使用起来方便、简单,但是你真的了解它吗?或者可以尝试回答一下几个问题?
1.自增主键标识符 auto_increment 如何增长?
2.并发环境下,数据库是如何保证主键值的正确性的?
3.可以用最大主键代替count()吗?
auto_increment如何使用
1.关键字auto_increment是用来定义主键是自增的。
定义自增主键:
CREATE TABLE `game` (
`id` int(10) unsigned not null auto_increment comment '主键',
`game_name` varchar(128) not null default '' comment '名称',
primary key (`id`) USING BTREE,
key `ix_status` (`status`) USING BTREE
) ENGINE=InnoDB;
2.auto_increment 用来记录,下一次插入记录主键的值。
通过命令
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
可以查看表 game 当前 auto_increment 的值。
3.auto_increment 在建表是设置主键的自增的起始值。
CREATE TABLE `game` (
`id` int(10) unsigned not null auto_increment comment '主键',
`game_name` varchar(128) not null default '' comment '名称',
primary key (`id`) USING BTREE,
key `ix_status` (`status`) USING BTREE
) ENGINE=InnoDB auto_increment = 5;
表示自增主键以5为起始,也就是插入的第一条记录的主键值为5.
也可以通过以下命令,进行设置。
alter table game auto_increment=5;
auto_increment什么时候会发生变化
(1)当插入一个主键为nul,0或者没有明确指定的记录时
insert into game (id,game_name,game_id) value(null,'game01',1);
insert into game (id,game_name,game_id) value(0,'game02',2);
insert into game (game_name,game_id) value('game03',3);
select * from game;
结果如下:
5 game05 5
6 game06 6
7 game07 7
注:auto_increment的起始值为5.
(2)当明确指定主键时
如果指定的主键小于auto_increment时,auto_increment不发生变化
查看当前 auto_increment 的值
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result=8
插入一个主键比当前auto_increment小的值
insert into game (id,game_name,game_id) value(4,'game04',4);
查看当前game表中的数据
select * from game;
result:
id game_name game_id
4 game04 4
5 game05 5
6 game06 6
7 game07 7
查看当前auto_increment的值:
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
8
如果指定的主键大于auto_increment时,auto_increment会发生变化
insert into game (id,game_name,game_id) value(10,'game010',10);
那么会变成多少呢?默认情况下会变成比明确指定的主键值大1。查看当前auto_increment的值:
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
11
为什么会是1呢?其实auto_increment的变化,受到两个参数的影响,auto_increment_offset和auto_increment_increment,这两个参数分别表示,自增主键起始值和步长。插入数据时,如果没有明确指定主键的话,数据插入后,auto_increment会变成,插入数据前的auto_increment+auto_increment_automent。
如果插入数据时候,指定了一个比当前auto_increment大的值时,auto_increment会从当前主键值开始,按照auto_increment_increment累加,直到找到第一个比指定的主键值大的置。
注:使用update 更改数据行的主键,auto_increment不会发生变化,如果更改后主键值大于等于当前auto_increment的话,可能会产生违反主键约束的错误。
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
11
更新数据行的主键为11
update game set id = 11 where game_name = 'game05';
查看当前auto_increment的值
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
11
插入一条数据
insert into game (game_name,game_id) value('game11',11);
产生报错信息如下:
[SQL]insert into game (game_name,game_id) value('game11',11);
[Err] 1062 - Duplicate entry '11' for key 'PRIMARY'
并发场景下,如何保证自增主键的正确性
当多个线程同时插入数据到数据库中,是否存在两个记录有相同的主键值呢?答案是不会的。mysql提供了一个保证自增主键值正确性的机制–自增锁(一种排他锁)。它让申请自增主键的操作由并行变成串行,保证了每个插入操作都能申请到一个唯一的主键值。而且随着mysql的版本迭代,自增锁也在不在优化。
在mysql5.0版本的时候,自增锁是语句级别的,也就是说,自增锁的粒度是一条语句,只有等申请到自增锁的语句执行完,自增锁才能释放。在锁释放前,其申请锁的语句只能阻塞等待。显然这种设计会影响到插入数据的并发度。
在mysql5.1.2版本引入一个可以对自增锁进行配置的参数。改参数为:innodb_autoinc_lock_mode,改参数的值可以是0,1,2。
0:表示采用mysql5.0版本的策略,即自增锁需要等到语句执行完才能释放。
1:对于普通insert语句,申请到自增锁,获取到主键值后,立即释放自增锁。而非等到整条语句执行完才释放。而对于insert ... select 这种批量到插入操作,自增锁的粒度还是语句级别的。为什么对于insert ... select 自增锁就变成了的语句级别呢,这个其实是出于数据一致性考虑的一种优化。具体原因我们后边在说。
2:表示所有自增锁的申请,都是获取到主键值后,立即释放。
自增锁使用语句级别锁,会降低获取自增值得效率,但是对于insert ... select批量插入,还是采用了语句级别锁。上文说了原因:保证数据数据的一致性。
数据一致性如何体现的
insert...select是一个批量插入操作,这条语句执行过程中,需要获取多个主键值,如果采用获取到自增锁立即释放的模式,会导致获取的多个主键值不连续。也就是失去了insert…select 的语义了,具体原因如下图:
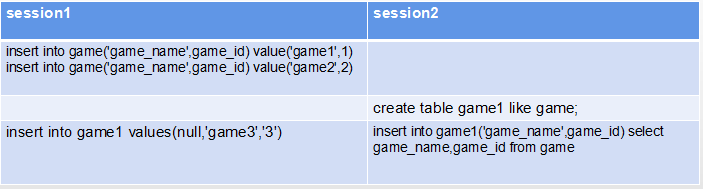
session1:向game表中插入两条记录,game表中的内容为(1,’game1’,1),(2,’game2’,2)。
session2:创建一个表结构和game相同的表game1,然后将game表中的2条记录插入到game1中。
session1:向game1中插入一条记录,game_name和game_id分别为"game3"和3。
如果自增锁使用"获取到自增锁立即释放"的模式,插入到game1中的记录可能有如下几种情况:
1.(1,’game3’,3)
(2,’game1’,1)
(3,’game2’,2)
2.(1,’game1’,1)
(2,’game3’,3)
(3,’game2’,2)
3.(1,’game1’,1)
(2,’game2’,2)
(3,’game3’,3)
以上三种情况都是有可能会产生的,如果出现了1和2这两种情况话,那么game和game1中的数据是对应不上的。如果game1表为主从结构的话,主库和从库之间数据同步时,也会出现数据不一致的情况。默认情况下,从库从主库同步数据时,binlog的格式是statement,也就是binlog记录的是主库中执行的sql语句,对于session1和session2同时执行对game1插入操作,在binlog中记录的结果要么是:
insert into game1 values(null,‘game3’,3)
insert into game1('game_name',game_id) select game_name,game_id from game
要么是:
insert into game1('game_name',game_id) select game_name,game_id from game
insert into game1 values(null,‘game3’,3)
因为从库执行binlog是串行执行的,无论binlog是那种顺序,从库中的数据都不可能是第2中结果。那么从库中主库的数据也就存在不一致的可能,这个是无法忍受的。
mysql为了保证数据一致性,针对insert ... select获取主键锁的模式为语句级别的,这种设计模式是以牺牲性能为代价的。
当insert ... select语句插入的数据过多时,比如10万时,那么就需要申请10万次自增锁,然后在逐个的插入10万条记录,这种做法不但速度慢,而且影响数据插入的并行度。在这10万条记录插入的过程中,其他session的插入语句只能阻塞等待。这严重影响了数据插入的性能。
mysql针对insert ... select 获取自增锁的方式进行了优化,优化措施是提高这10万条数据插入时获取自增锁的效率,在原来的方式中,因为每次获取一个可用主键值,所以只能并行插入一条记录。优化后,每次可以获取多个主键值,那么就可以并行插入多个记录。优化后的主键获取方式按照每次获取2的幂次方个,第一次获取1个,第二次获取2个,第三次获取4个…直到获取足够的主键值。这样理论上插入数据的效率也是呈指数速度增长的。
处了mysql的优化方案外,我们还可以通过修改binlog格式为row,然后将获取主键锁的模式改成2。在保证主从数据一致的前提下提高插入数据的效率。
是否可以利用最大主键值判断表的数据量
可以使用最大主键值,大致估计一下表的数据量,但是这种方式是不准确的,主要原因在于自增主键不连续,而且中间是会产生空洞的。只能说自增主键值大于等于数据量。
那么会有那些情况导致自增主键不连续呢?
在分析自增主键不连续前,我们需要先了解一下,自增值增长的时机。下图是一次数据插入的流程图(默认自增步长为1):
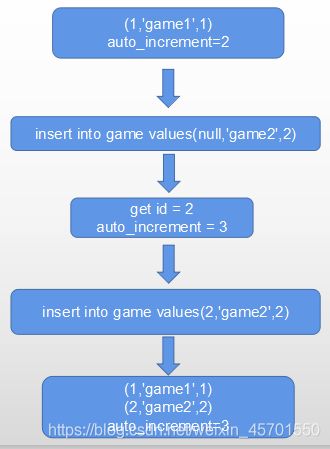
1.game表初始数据信息。
2.插入一个主键为null的记录,(null,’game2’,2)。
3.数据库将game表 auto_increment值,分配给要插入的记录。
4.game表的auto_increment增长为3
5.执行插入操作。
真正执行数据插入操作是在4完成的,而auto_increment的更新是在4之前执行的。如果4以为某些原因执行失败了,整个表的记录数量没有增长,但是auto_increment却已经增加了。下一次插入操作,继续按照上面的流程执行,主键继续增加,那么必然会导致主键产生空洞不连续的情况,也就是产生了整个表的数据量小于主键的最大值。
示例演示
获取当前 auto_increment
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
12
当前表中的数据:
id game_name game_id
6 game06 6
7 game7 7
10 game010 10
11 game05 5
插入一条违反唯一键约束的记录
insert into game (id,game_name,game_id) value(null,'game05',5);
[SQL]insert into game (id,game_name,game_id) value(null,'game05',5);
[Err] 1062 - Duplicate entry '5' for key 'ix_game_id'
查看此时的auto_incremnt
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game';
result:
13
再次查看当前表中的数据:
id game_name game_id
6 game06 6
7 game7 7
10 game010 10
11 game05 5
数据量没有发生变化,但是自增值取增加了。
除此之外,mysql对自增锁的优化也会产生主键空洞不连续,因为对于insert … select mysql采用批量获取主键的方式,每次获取2的幂次方个主键,来提高数据插入的并行效率,最后一次批量获取,很大可能会获取到多余的主键。
创建一个表结构和game相同的表game2
create table game2 like game;
查看此时auto_increment的值
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game2';
result:1
使用insert ... select 将game表中的数据复制到game2中
select * from game;
result:
id game_name game_id
6 game06 6
7 game7 7
10 game010 10
11 game05 5
同步数据
insert into game2(game_name,game_id) select game_name,game_id from game
game表中共有4条数据,需要分3次获取主键,每次获取的主键数据分别是 1,2,4
此次数据同步申请了7个主键。
查看此时auto_increment的值
select auto_increment from information_schema.tables where table_schema='ad' and table_name='game2';
result:
8
此时game2表中只有4条记录,mysql的这种优化也会造成主键的空洞产生。
用主键的最大值可以衡量数据表中数据量的数据量级,但是无法精确衡量表中的数据量。
感谢阅读,希望本篇文章能对你有所帮助。