从Google Aquila和RMA谈谈数据中心互联技术变革,NUPA和UMA
最近Google发布了“全新”数据中心架构,一个可预测、低延迟、高带宽、低成本、低碳的数据中心架构。并提出了TiN和RMA概念。今天笔者从边缘智芯的技术路线,谈谈什么是TiN和RMA,以及边缘智芯的NUPA+UMA架构。同时笔者认为这个变革将是未来10年甚至20年数据中心和云计算最重要的技术突破口。


一、数据中心到底有什么问题?
和传统芯片公司和大部分IT公司认为的观点不一样,数据中心的真正问题其实不在CPU和GPU或者所谓的DPU。“计算从来都不是问题”。从Google发布Hadoop分布式计算模型开始(虽然这个分布式思路非常简单),Scale-out就开始占据主导地位。Scale-out分布式的兴起就说明对于绝大部分应用场景,算力都不是问题。一个CPU不行,我们换多个CPU就可以了,集群计算是实际发生的事情。云计算的兴起进一步加强了这个趋势。
云公司要的是成本和计算吞吐率的性价比。达到Scale-out的计算优势通常三种方案:1)多核心,2)多路服务器,3)多服务器集群。本质上来说,就是把多个计算核心连起来组成规模优势。仔细分析这三种模式,本质是一致,就是核心互联问题。虽然技术路线不一样,但解决的问题都是让通信更加高效和快速。GPU更加彻底,是一个完全的NoC结构,Network of Massive Cores。

-
芯片内互联是NoC,network of cores,没有标准
-
系统内互联是NoC,network of CPUs,基本为私有协议 + BUS统一内存空间
-
服务器间互联是Net,network of systems,以太网 + TCP/IP协议
传统计算架构下, 这四种范式界限非常清晰,基本上Intel定义了系统内主流IO标准,Cisco定义了以太网大部分标准,大家相安无事。但最近随着网络速率的提升,系统间互联出现了问题。什么问题呢?很多公司说是计算跟不上了。其实本质原因不是计算跟不上了,是功耗和成本太高了!计算本质上没有不够用的时候,只有成本和scaling问题。如果scaling不是问题,计算是可以和美元一样,无限量供应的!
二、什么是Scaling?
Scaling是指事物在一个核心上运行的时间和在多个核心上运行时间总和的关系。简单说,如果一个任务在一个核心上得运行10小时,在10个核心上只要运行1小时(总和是10x1小时=10小时)。那么我们说scaling是线性的,效率是100%,可以scale,完全scale的算法也是完全可以并行处理的算法。但实际情况是,大部分应用场景无法做到完全的并行,或者scale不可能到达100%。在无法scale的场景下,增加计算核心就无法达到提速的目标了。这个就是并行运算的Amdahl定律,这个定律适合多核心系统,也适合多机互联的集群系统。在无法解决算法难题的情况下,我们只能做的就是提高通讯效率,降低通讯损耗。

所以更快、更高带宽的IPC成为当代CPU发展的趋势,包括AMD、Apple、Intel和Ampere都一样。通过堆核心,提升IPC的能力来增加整体算力。
但笔者认为CPU一味增加核心会造成另外一个问题,就是CPU和设备的通讯出现不平衡问题。英伟达第一时间指出CPU核心数越来越多,会造成CPU和GPU之间的链路速度不够。也就是PCIe Switch出了问题。于是英伟达推出了NVSwitch来重新定义设备互联。

三、多核CPU vs 多互联CPU,Chiplet vs TiN (XPU)?
虽然多核心CPU可以通过Chip-to-Chip和IPC的方式增加计算性能和吞吐率,但一味的增加核心数会导致CPU和设备之间互联的失衡。在GPU领域Nvidia由于封闭体系,给出了NVLink,NVSwitch解决方案。但到底是多核心CPU还是再搞一个Hadoop样式的CPU和CPU互联呢?这个答案或者技术路线一直是系统架构公司努力的方向。
Intel携几乎所有芯片公司给出了接口协议标准UCIe!笔者认为虽然这个协议看上去是要解决chiplet的问题,实际上真正要解决的是CPU-2-CPU的问题。果然在边缘智芯发布NUPA解决方案之后,Google也给出了TiN和RMA解决方案。Google更加进一步,利用SDN的思路,进一步简单化互联的要求,将NIC变成简单的MAC+PCIe link+Routing的结构。其中Routing的部分被认为取代ToR交换机的功能,实现简单的流表控制。从设计来看,由于采取的是PCIe Gen3的主机互联架构,目前一个TiN只支持两个主机复用,在未来升级成5.0之后,预计将会支持8到16个主机复用。
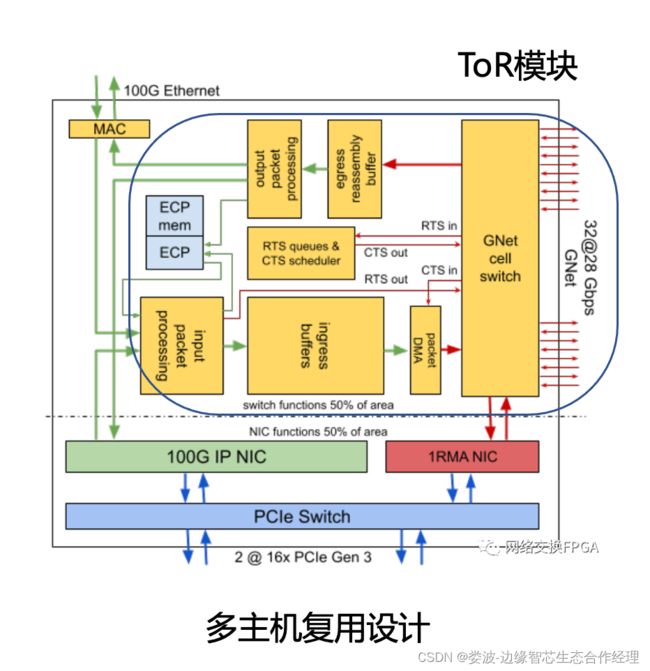
该设计最大的一个亮点就是ToR模块非常简单,没有复杂的处理模块,只有链路路由模块,而且路由模块由SDN控制器提供。这个设计和当前的DPU公司过度设计计算核心和提供计算能力不一样,是完全面向数据链路的ASIC。这个思路和我们XPU的思路完全一致。我们只处理数据路径问题,不处理数据内容。
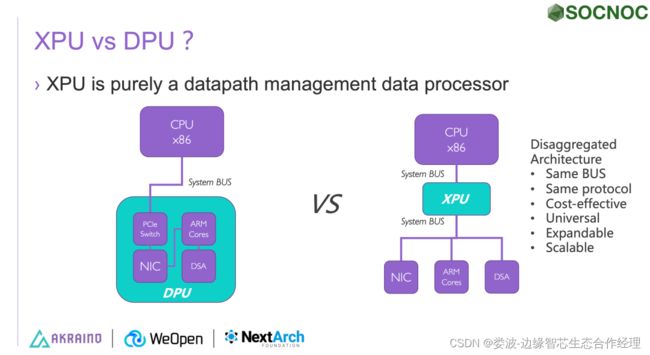
四、协议问题 TiN RMA vs XPU IPoPCIe
虽然笔者非常赞成Google的技术路线,只提供路由能力的TiN ASIC。但从芯片设计来看,显然Google没有找到更加友好的协议融合答案,而是简单将以太网和GNet通过一个芯片TiN融合起来,构建RMA内存系统。而XPU通过IP over PCIe的方式达到统一内存管理UMA。RMA和UMA都是从RDMA衍生而来,RMA去掉了D强调Remote和内存,而我们UMA强调统一,不区分Remote和Local。

区别于TiN和RMA,我们引入UMA层统一管理内存。NUPA中将RAM也看出一种通信介质
NUPA:Networking Unified Protocol Architecture
在XPU,和TiN解决方案中,核心思想为将ToR交换机放在服务器上,而服务器从单系统变成集群!本质上来看TiN和XPU完全一样,包括路由规则,内存配置完全一致!我们称这种适应新互联技术的服务器为CoB(云原生服务器)!
五、新物种:Cloud-on-Board服务器
和20多年前Google引入Hadoop开创了分布式计算的时代一样,这次Google引入TiN架构核心是要云化服务器设计。在可以预见的未来,我们将无法区分服务器个体和服务器集群的区别,Intel等芯片公司还在希望借助UCIe池化机柜的时候,Google为代表的云计算公司开始云化服务器了!和我们预测的一样,IT产业的创新核心是供应链标准话语权的争夺问题,和20年前巨型机败给小机一样,这次云化服务器的趋势将进一步挤压芯片公司的利润空间和生存空间。
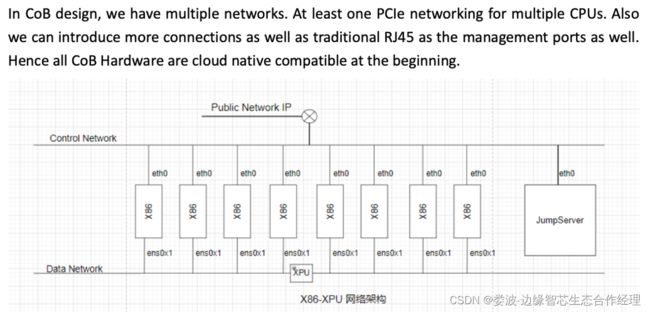
六、新趋势:服务器内的东西南北流量
和传统芯片公司关注的不一样,TiN和CoB关注的核心是云应用(Pod)之间的互联问题。同时不同于数据中心层面,东西流量远远大于南北流量的事实。在云计算应用中,Pod和Pod之间的流量多为服务器和服务器之间的流量,而不是服务器内单颗CPU内或者多路CPU间的流量。我们把跨服务器的Pod流量称之为虚拟机南北流量,而服务器内的Pod间流量称为虚拟机东西流量。毫无疑问,在目前的云计算中,虚拟机南北流量远远大于虚拟机东西流量。
这个和传统设计CPU芯片思路不一样,在适应云计算的应用场景中,CPU内的核心间通讯不需要完全一致,也不需要非常快了。而转向追求CPU内和CPU间的平衡了。DPU和SmartNIC的出现只是缓解了这一问题,但从根本上来说,增加算力无法解决这个问题。协议的创新才是解决互联问题,特别是跨系统互联问题的核心!Google TiN通过简单的以太网和GNet融合解决这个问题。而我们通过PCIe和以太网融合解决这个问题。

在跨服务器CPU之间构建一致、高效、低成本、低碳、同时兼容传统协议的网络将成为趋势。Google称之为Aquila,我们称之为NUPA架构。
One More Thing
虽然100+GbE SmartNIC和DPU吹起了数据中心变革的序幕,但数据中心本质是大规模算力和能耗的转换。算力和能耗的转换随着工艺提升困境和功耗指标的限制,在后摩尔时代无法得到重大的突破。而规模效益中最关键的互联技术才刚刚兴起。随着NVSwitch(GPU-GPU),HBM3技术(RAM-RAM),苹果M1 Ultra(CPU-CPU),Intel UCIe(Core-Core)和最近Google Aquila(System-system)的出现,各个尺度的互联技术暗流涌动。以前总线技术(BUS)和以太网(ethernet)平分天下的格局将被打破。