LSTM机器学习预测沪深300指数涨跌来交易股指期货
1. 从tushare获取沪深300数据
指标计算模块下载
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import tushare as ts
import tool.MyTT as zb
import copy
from sklearn.preprocessing import MinMaxScaler
# ###################数据获取
pro = ts.pro_api('自己的key')
df = pro.index_daily(ts_code='000300.SH', start_date='20060101') # end_date='20220711'
df = df.iloc[::-1]
2. 特征工程
说明:用沪深300当日收益率、5日收益率和5日均线乖离作为输入特征,标签用第二天的收益率。将三个输入特征和标签转换为1和-1,如收益率大于零为1代表张,小于零为-1代表跌。
# 特征工程
df['cma_5'] = zb.MA(df.close.values, 5)
df['atr_5'] = (zb.ATR(df.close.values, df.high.values, df.low.values, 5))/df.close*100
df['syl_1'] = ((df['close']-df['close'].shift(1))/df['close'].shift(1)*100) > 0
df['syl_1'] = df['syl_1'] = (df['syl_1'].astype(int)).replace(0, -1) # 将bool变量转换为1 0数值, 并将0替换为-1
df['syl_5'] = ((df['close']-df['close'].shift(5))/df['close'].shift(5)*100) > 0
df['syl_5'] = df['syl_5'] = (df['syl_5'].astype(int)).replace(0, -1)
df['jxqs_5'] = ((df['close'] > df['cma_5']).astype(int)).replace(0, -1)
df = df.fillna(method='bfill') # 向上填充
sel_col = ['syl_1', 'syl_5', 'jxqs_5']
df_main = copy.deepcopy(df[sel_col])
# 数据归一化,这里本来就是用的1和-1也可以不归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
for col in sel_col: # 这里不能进行统一进行缩放,因为fit_transform返回值是numpy类型
df_main[col] = scaler.fit_transform(df_main[col].values.reshape(-1, 1))
# 将下一日的收盘价作为本日的标签
df_main['target'] = df_main['syl_1'].shift(-1)
# df_main = df_main.dropna() # 使用了shift函数,在最后必然是有缺失值的,这里去掉缺失值所在行
df_main['target'].iloc[-1] = df_main['target'].iloc[-2] # 替换最后一个nan为上一个值
df_main = df_main.astype(np.float32) # 修改数据类型


3. 建立LSTM模型
import torch.nn as nn
input_dim = 3 # 数据的特征数
hidden_dim = 32 # 隐藏层的神经元个数
num_layers = 2 # LSTM的层数
output_dim = 1 # 预测值的特征数(这是预测股票价格,所以这里特征数是1,如果预测一个单词,那么这里是one-hot向量的编码长度)
class LSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
super(LSTM, self).__init__()
# Hidden dimensions
self.hidden_dim = hidden_dim
# Number of hidden layers
self.num_layers = num_layers
# Building your LSTM
# batch_first=True causes input/output tensors to be of shape (batch_dim, seq_dim, feature_dim)
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
# Readout layer 在LSTM后再加一个全连接层,因为是回归问题,所以不能在线性层后加激活函数
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# Initialize hidden state with zeros
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
# 这里x.size(0)就是batch_size
# Initialize cell state
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
# One time step
# We need to detach as we are doing truncated backpropagation through time (BPTT)
# If we don't, we'll backprop all the way to the start even after going through another batch
out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))
4. 按照模型接口组织训练数据
# 创建两个列表,用来存储数据的特征和标签
data_feat, data_target = [], []
# 设每条数据序列有10组数据
seq = 10
for index in range(len(df_main) - seq):
# 构建特征集
data_feat.append(df_main[sel_col][index: index + seq].values)
# 构建target集
data_target.append(df_main['target'][index:index + seq])
# 将特征集和标签集整理成numpy数组
data_feat = np.array(data_feat)
data_target = np.array(data_target)
# ############## 训练集与测试集的划分 todo
# 这里按照9:1的比例划分训练集和测试集
test_set_size = int(np.round(1*df_main.shape[0])) # np.round(1)是四舍五入,
train_size = data_feat.shape[0] - (test_set_size)
print(test_set_size) # 输出测试集大小
print(train_size) # 输出训练集大小
trainX = torch.from_numpy(data_feat[800:train_size].reshape(-1, seq, input_dim)).type(torch.Tensor)
# 这里第一个维度自动确定,我们认为其为batch_size,因为在LSTM类的定义中,设置了batch_first=True
testX = torch.from_numpy(data_feat[train_size:].reshape(-1, seq, input_dim)).type(torch.Tensor)
testX2 = torch.from_numpy(data_feat[2000:].reshape(-1, seq, input_dim)).type(torch.Tensor)
trainY = torch.from_numpy(data_target[800:train_size].reshape(-1, seq, 1)).type(torch.Tensor)
testY = torch.from_numpy(data_target[train_size:].reshape(-1, seq, 1)).type(torch.Tensor)
testY2 = torch.from_numpy(data_target[2000:].reshape(-1, seq, 1)).type(torch.Tensor)
print('x_train.shape = ', trainX.shape)
print('y_train.shape = ', trainY.shape)
print('x_test.shape = ', testX.shape)
print('x_test.shape2 = ', testX2.shape)
print('y_test.shape = ', testY.shape)
5. 训练模型
import torch.utils.data
batch_size = train_size # 等于训练集大小
train = torch.utils.data.TensorDataset(trainX, trainY)
test = torch.utils.data.TensorDataset(testX, testY)
train_loader = torch.utils.data.DataLoader(dataset=train,
batch_size=batch_size,
shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test,
batch_size=batch_size,
shuffle=False)
# 实例化模型
model = LSTM(input_dim=input_dim, hidden_dim=hidden_dim, output_dim=output_dim, num_layers=num_layers)
# 定义优化器和损失函数
optimiser = torch.optim.Adam(model.parameters(), lr=0.01) # 使用Adam优化算法
loss_fn = torch.nn.MSELoss(size_average=True) # 使用均方差作为损失函数
# 打印模型结构
print(model)
# 打印模型各层的参数尺寸
for i in range(len(list(model.parameters()))):
print(list(model.parameters())[i].size())
# 设定数据遍历次数
num_epochs = 90
# 训练模型
hist = np.zeros(num_epochs)
for t in range(num_epochs):
y_train_pred = model(trainX)
loss = loss_fn(y_train_pred, trainY)
if t % 10 == 0 and t != 0: # 每训练十次,打印一次均方差,
print("训练次数 ", t, "均方差RMSE: ", loss.item())
hist[t] = loss.item()
# Zero out gradient, else they will accumulate between epochs 将梯度归零
optimiser.zero_grad()
# Backward pass
loss.backward()
# Update parameters
optimiser.step()

- 计算训练得到的模型在训练集上的均方差
y_train_pred = model(trainX)
loss_fn(y_train_pred, trainY).item()

6. 做出预测
y_test_pred = model(testX2)
loss_fn(y_test_pred, testY2).item()
pred_value = y_test_pred.detach().numpy()[:, -1, 0]
true_value = testY2.detach().numpy()[:, -1, 0]
data2 = pd.read_csv('公式读写数据库配置文件 - syl.csv')
data2['块名'] = ['hs300ycsyl' for var in range(len(pred_value))]
data2['键名'] = df['trade_date'][-len(pred_value):].values
data2['值'] = pred_value[:, 0] # 有归一化时用
# data2['值'] = pred_value
# data2 = pd.DataFrame(pred_value[:, 0], df['trade_date'][-len(pred_value):].values)
data2.to_csv('hs300ycsyl.csv', index=None, encoding='utf_8_sig')
print('样本外开始日期=', df['trade_date'][-len(testX):].values[0])
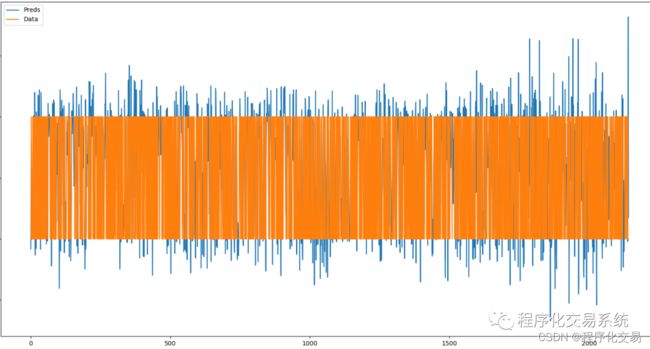
plt.plot(pred_value, label="Preds") # 预测值
plt.plot(true_value, label="Data") # 真实值
plt.legend()
plt.show()
• 看图拟合的可以
7. 将拟合的涨跌结果导出tb交易开拓者能识别的数据格式,然后导入tb本地数据库,读取进行回测
data2 = pd.DataFrame({'块名': [], '键名': [], '值': []})
data2['块名'] = ['hs300ycsyl' for var in range(len(pred_value))]
data2['键名'] = df['trade_date'][-len(pred_value):].values
data2['值'] = pred_value[:, 0] # 有归一化时用
• tb交易开拓者策略编写,预测值大于0时做多,小于0时开空,反手策略。
//------------------------------------------------------------------------
// 简称: lstm_hc
// 名称: 机器学习回测
// 类别: 公式应用
// 类型: 用户应用
// 输出: Void
//------------------------------------------------------------------------
Params
//此处添加参数
Vars
Series<Numeric> yc_close;
Series<Numeric> jiaoyiri;
Defs
//此处添加公式函数
Events
//初始化事件函数,策略运行期间,首先运行且只有一次,应用在订阅数据等操作
OnInit()
{
//与数据源有关
Range[0:DataCount-1]
{
//=========数据源相关设置==============
//AddDataFlag(Enum_Data_RolloverBackWard()); //设置后复权
//AddDataFlag(Enum_Data_RolloverRealPrice()); //设置映射真实价格
AddDataFlag(Enum_Data_AutoSwapPosition()); //设置自动换仓
AddDataFlag(Enum_Data_IgnoreSwapSignalCalc()); //设置忽略换仓信号计算
Bool ret = SetSwapPosVolType(2); //设置自动换仓量类型
//AddDataFlag(Enum_Data_OnlyDay()); //设置仅日盘
//AddDataFlag(Enum_Data_OnlyNight()); //设置仅夜盘
//AddDataFlag(Enum_Data_NotGenReport()); //设置数据源不参与生成报告标志
//=========交易相关设置==============
//MarginRate rate;
//rate.ratioType = Enum_Rate_ByFillAmount; //设置保证金费率方式为成交金额百分比
//rate.longMarginRatio = 0.1; //设置保证金率为10%
//rate.shortMarginRatio = 0.2; //设置保证金率为20%
//SetMarginRate(rate);
CommissionRate tCommissionRate;
tCommissionRate.ratioType = Enum_Rate_ByFillAmount;
tCommissionRate.openRatio = 1; //设置开仓手续费为成交金额的5%%
tCommissionRate.closeRatio = 1; //设置平仓手续费为成交金额的2%%
tCommissionRate.closeTodayRatio = 1; //设置平今手续费为0
SetCommissionRate(tCommissionRate); //设置手续费率
SetSlippage(Enum_Rate_PointPerHand,2); //设置滑点为2跳/手
//=========交易相关设置==============
SetInitCapital(10000000); //设置初始资金为100万
}
//Bar更新事件函数,参数indexs表示变化的数据源图层ID数组
OnBar(ArrayRef<Integer> indexs)
{
jiaoyiri = TrueDate();
if(jiaoyiri<>jiaoyiri[1]) data1.yc_close = Value(GetTBProfileString("hs300ycsyl",text(data1.Date)));
Commentary("预测收益率="+Text(data1.yc_close));
if(MarketPosition != 1 and data1.yc_close != InvalidNumeric and data1.yc_close>0.5)
{
Buy(1, Open);
}
if(MarketPosition != -1 and data1.yc_close != InvalidNumeric and data1.yc_close<-0.5)
{
SellShort(1, Open);
}
}
//------------------------------------------------------------------------
// 编译版本 2023/02/01 084226
// 版权所有 jinxin168
// 更改声明 TradeBlazer Software保留对TradeBlazer平台
// 每一版本的TradeBlazer公式修改和重写的权利
//------------------------------------------------------------------------
8. 信号与回测结果
• 下面是样本内信号,非常好。

• 下面是样本外信号,一般。

• 下面是回测结果。


结论:从回测结果看,有点过拟合,给的三个特征也不是很好,可以加入更多相关性强的特征,注意,类似于价格的特征需要做平稳性检验。