Python--并发编程(上)
目录
- 一、 multiprocessing模块介绍
- 二、 Process类的介绍
-
- 2.1、方法介绍
-
- join 方法拓展
- 2.2、属性介绍
- 三、 Process类的使用
-
- 3.1、创建并开启进程的两种方式
- 四、进程互斥(锁)--Lock
- 五、进程通信IPC--Queue
-
- 5.1、Queue使用方法介绍
- 5.2、实现进程通信
- 六、Tread 类与 Process 类的异同
-
-
- 主线程与主进程的结束标志不同
- 导入模块不同
- 需要传入的参数相同
- join 方法的区别
-
- 七、死锁与递归锁--Rlock
- 八、信号量--Semaphore
- 九、Event 事件
一、 multiprocessing模块介绍
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程。
Python提供了multiprocessing。multiprocessing模块 用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内
二、 Process类的介绍
![]()
需要使用关键字的方式来指定参数
args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号group参数未使用,值始终为None
target表示调用对象,即子进程要执行的任务
args表示调用对象的位置参数元组,args=(1,2,‘frank’,)
kwargs表示调用对象的字典,kwargs={‘name’:‘frank’,‘age’:18}
name为子进程的名称,如果不给会自动生成一个名字
2.1、方法介绍
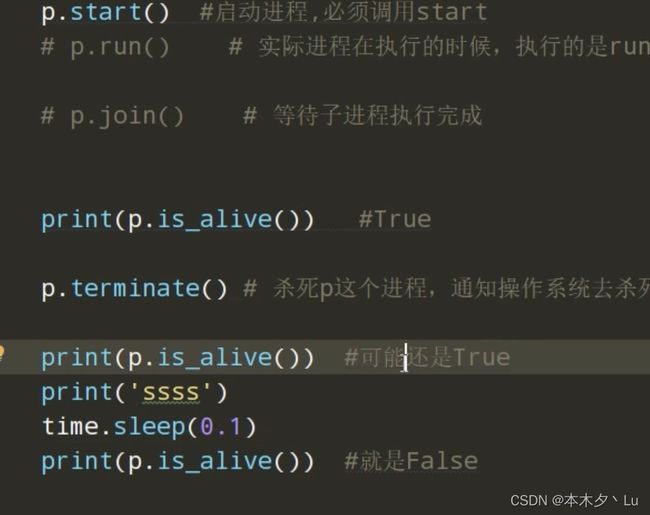
p.is_alive():如果p仍然运行,返回True
p.start( ):启动进程,并调用该子进程中的 p.run( )
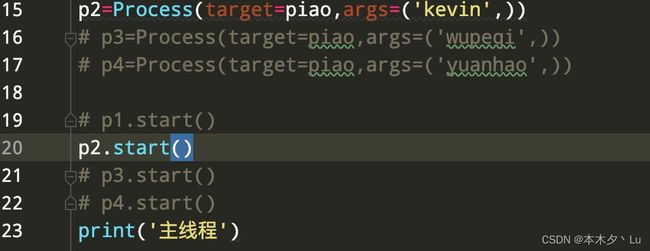

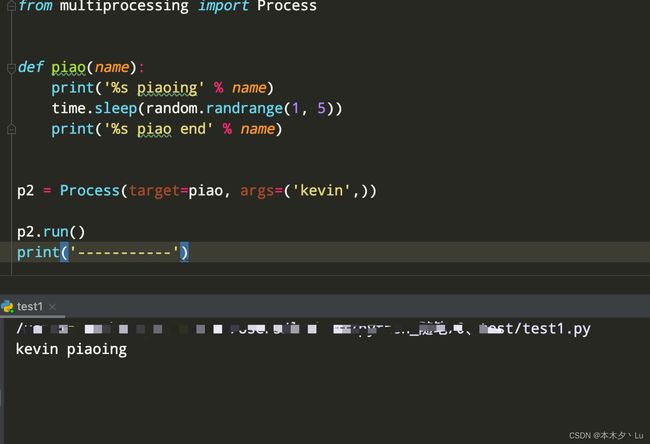
p.run( ):进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
注意:虽然 start( )方法是调用 run()方法执行,但是如果直接调用 run()方法是不会开启新的进程执行的,而是在主进程中执行
p.terminate(): 通知操作系统强制终止进程p,不会立即结束,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁

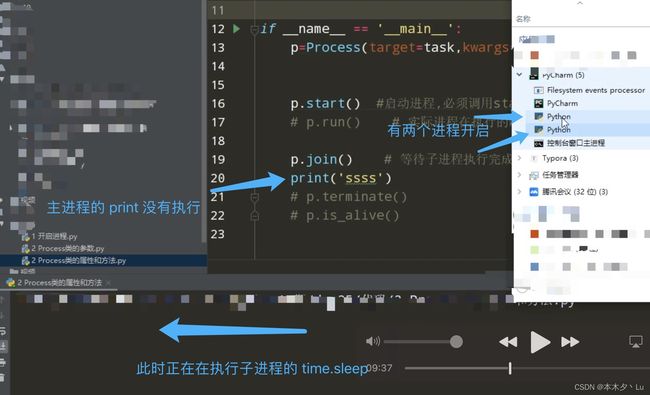
p.join([timeout]): 主线程等待子进程p终止之后再执行准成
(强调:是主线程处于等的状态,而p是处于运行的状态)。
timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
join 方法拓展
启动多个子进程,等多个子进程执行完在执行主进程
from multiprocessing import Process
import time
def task(i):
time.sleep(1)
print(f"子进程--task{i}")
if __name__ == '__main__':
ctime = time.time()
for i in range(5):
p = Process(target=task,args=(i,))
p.start()
p.join()
print('主进程')
print(time.time()-ctime) # 5.089050769805908
这种写法的问题在于,每个子进程执行完了,才会执行下一个子进程,并不是多个子进程同时执行!
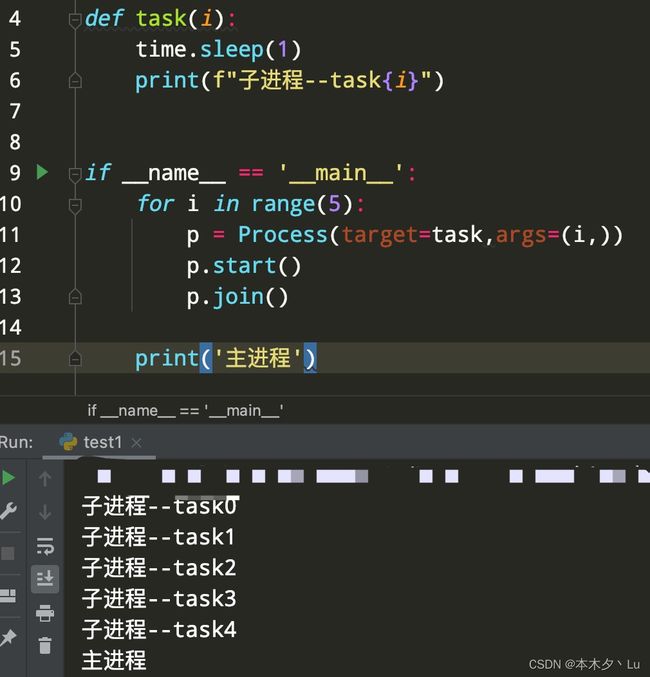
from multiprocessing import Process
import time
def task(i):
time.sleep(1)
print(f"子进程--task{i}")
if __name__ == '__main__':
ctime = time.time()
l=[]
for i in range(5):
p = Process(target=task,args=(i,))
p.start()
l.append(p) # 将进程加入列表中,这样 5 个子进程就会全部执行
for p in l:
p.join() # 当5 个子进程全部执行完,才会执行主进程
print('主进程')
print(time.time()-ctime) # 1.0185809135437012
2.2、属性介绍
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
获取进程 ID 还可以通过 os 模块:os.getpid( )–当前进程 id; os.getppid( )–当前进程的父进程 id;
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
注意:结束主进程,所有"守护进程"也会全部结束;主进程会等待所有的“非守护进程”全部结束,才会结束主进程
主进程的结束标志:所有主进程的代码全部运行结束;
区别于主线程,主线程即使代码全部运行结束,也会等待非守护线程全部结束
def task():
time.sleep(5)
print('子进程')

此时,直接右键结束主进程,那么子进程就会被终止。

默认情况下为:daemon = False ,结束主进程,子进程仍然会运行。
三、 Process类的使用
在windows中Process( )必须放到# if name == ‘main’:下
3.1、创建并开启进程的两种方式

方式一:将执行的任务单独写成一个函数,在传入 Process 类,再实例化得到对象
import time
import random
from multiprocessing import Process
def piao(name):
print('%s piaoing' %name)
time.sleep(random.randrange(1,5))
print('%s piao end' %name)
p1=Process(target=piao,args=('jason',)) #必须加,号
p2=Process(target=piao,args=('kevin',))
p3=Process(target=piao,args=('wupeqi',))
p4=Process(target=piao,args=('yuanhao',))
p1.start()
p2.start()
p3.start()
p4.start()
print('主线程')
方法二: 自定义一个类继承 Process ,并重写 run 方法,再实例化,调用 start 方法
注意:该方法必须要 运行 Process 类的 init,同时在自定义的 init 中尽量不要与 Process 类中的属性重复
import time
import random
from multiprocessing import Process
class Piao(Process):
def __init__(self,name1):
# 必须要运行Process 类的__init__方法
super().__init__()
self.name1=name1
def run(self):
print('%s piaoing' %self.name1)
time.sleep(random.randrange(1,5))
print('%s piao end' %self.name1)
p1=Piao('egon')
p2=Piao('alex')
p3=Piao('wupeiqi')
p4=Piao('yuanhao')
p1.start() #start会自动调用run
p2.start()
p3.start()
p4.start()
print('主线程')
四、进程互斥(锁)–Lock
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的
而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理
1、在主进程中先生成lock 对象
2、对于使用同一个资源的进程需要加同一把锁
3、上锁–lock.acquire( )
4、释放锁–lock.release( )
5、可以将上锁和释放锁的操作放在 with 关键字后面
lock.acquire()
被上锁的代码....
lock.release()
with lock:
被上锁的代码....
from multiprocessing import Lock
import time
import random
def task(i,lock):
lock.acquire()
print(f'子进程--task{i}开始执行')
time.sleep(random.randint(1,3))
print(f"子进程--task{i}执行结束")
lock.release()
if __name__ == '__main__':
lock = Lock()
for i in range(5):
p = Process(target=task, args=(i,lock))
p.start()

多个进程共享同一文件–文件当数据库,模拟抢票
#文件db的内容为:{"count":1}
#注意一定要用双引号,不然json无法识别
from multiprocessing import Process,Lock
import time,json,random
def search():
dic=json.load(open('db.txt'))
print('\033[43m剩余票数%s\033[0m' %dic['count'])
def get():
dic=json.load(open('db.txt'))
time.sleep(0.1) #模拟读数据的网络延迟
if dic['count'] >0:
dic['count']-=1
time.sleep(0.2) #模拟写数据的网络延迟
json.dump(dic,open('db.txt','w'))
print('\033[43m购票成功\033[0m')
def task(lock):
search()
lock.acquire()
get()
lock.release()
if __name__ == '__main__':
lock=Lock()
for i in range(100): #模拟并发100个客户端抢票
p=Process(target=task,args=(lock,))
p.start()
五、进程通信IPC–Queue
由于,进程与进程之间的数据是隔离的,因此需要借助一些手段实现进程之间的数据通信
在一台机器:
借助Queue或者文件
不在同一台机器:
借助于数据库或者消息队列
在这里主要介绍 Queue 方法
5.1、Queue使用方法介绍
实例化得到对象
maxsize参数 表示Queue 的大小是多少,不传的话,默认为无限大
queue = Queue(3)
存值
put( ): 向管道中传入数据,( 括号中 传入数据 )
block 参数,默认为 True-----当传入的次数大于管道的总容量,进程就会一直阻塞,直到将数据取出到管道中有空余的位置 ,改为 False 的话,进程就不会阻塞,直接进行报错
timeout 参数 : 当传入的次数大于管道的总容量,进程会阻塞 timeout 秒,超过这个时间就会报错
put_nowait( ) : 当传入的次数大于管道的总容量,进程不会阻塞,直接报错
取值
get ( ) : 从管道中取出数据
block 参数,默认为 True-----当管道中没有数据时,get 方法也会导致进程一直阻塞,直到管道中又传入了数据
改为 False 的话,进程就不会阻塞,直接进行报错
timeout 参数 : 当管道中没有数据时,进程会阻塞 timeout 秒,超过这个时间就会报错
get_nowait ( ) : 当管道中没有数据时,进程不会阻塞,直接报错
判断管道是否有数据
full ( ) : 判断管道是否已经存满,返回 bool 值
empty ( ) : 判断管道是否为空,返回 bool 值
qsize ( ): 查看当前管道中有几个值
5.2、实现进程通信
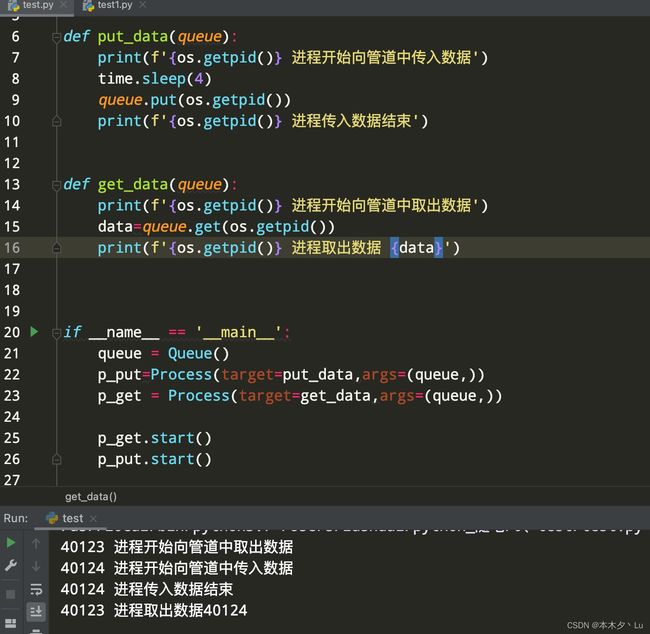
import os
import time
from multiprocessing import Process,Queue
def put_data(queue):
print(f'{os.getpid()} 进程开始向管道中传入数据')
time.sleep(4)
queue.put(os.getpid())
print(f'{os.getpid()} 进程传入数据结束')
def get_data(queue):
print(f'{os.getpid()} 进程开始向管道中取出数据')
data=queue.get(os.getpid())
print(f'{os.getpid()} 进程取出数据 {data}')
if __name__ == '__main__':
queue = Queue()
p_put=Process(target=put_data,args=(queue,))
p_get = Process(target=get_data,args=(queue,))
p_get.start()
p_put.start()
六、Tread 类与 Process 类的异同
主线程与主进程的结束标志不同
主进程是主进程的代码结束就结束。
主线程是非守护线程结束才算结束,并且主线程的代码结束。
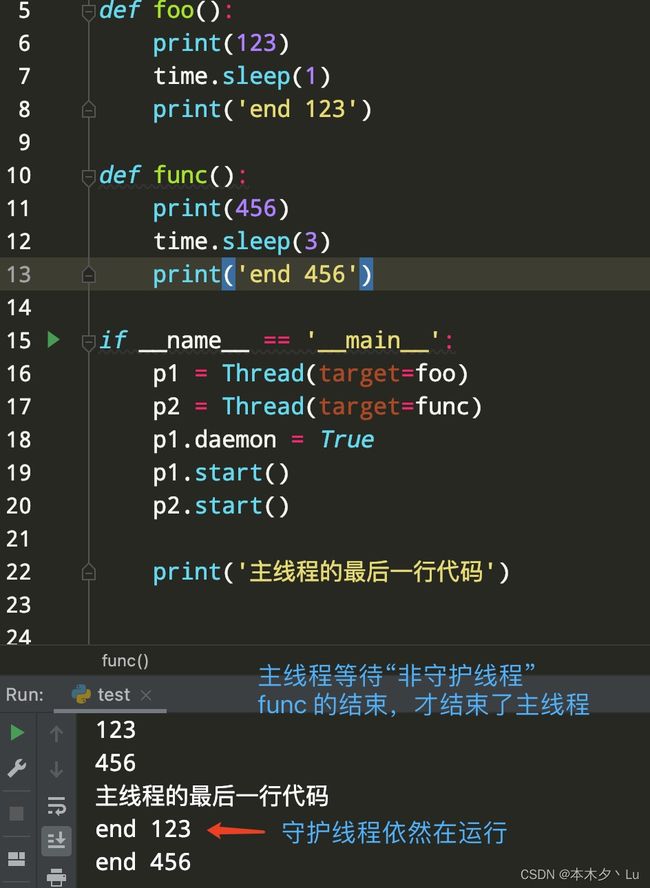
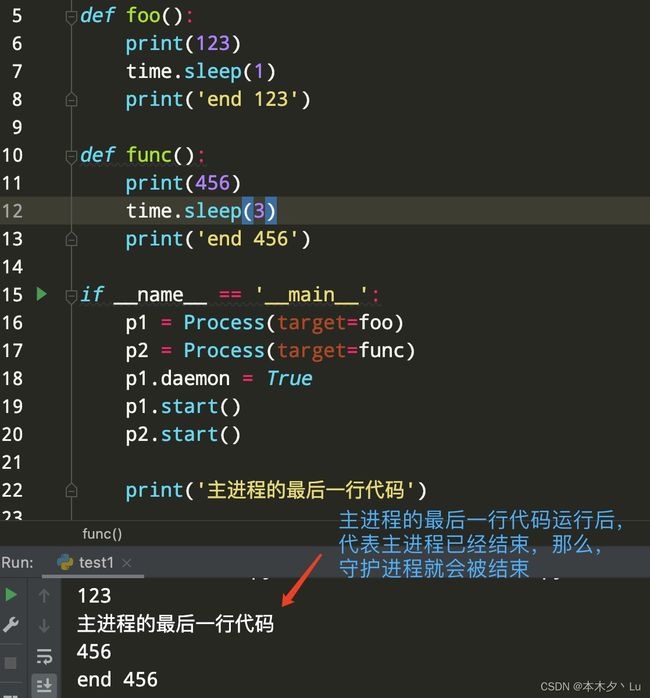
如果在主进程的最后一行下面加上一些代码,能够保证守护“进程”运行结束,再结束主进程,那么结果就会打印出“end 123”
导入模块不同
进程–> Process 类的导入
from multiprocessing import Process
线程–> Tread 类的导入
from threading import Thread
需要传入的参数相同
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ag3BQUqr-1648898105659)(图片.assets/并发编程-Process 类.jpg)]
join 方法的区别
进程的 join 方法:子进程运行结束才会执行主进程
线程的 join 方法:子线程运行结束才会执行主线程
七、死锁与递归锁–Rlock
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Lock
import time
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import RLock
import time
mutexA=RLock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
八、信号量–Semaphore
互斥锁:相当于同一时间只能有一个人上厕所
信号量:相当于公共厕所,有多个位置可以抢占,但是超过规定的数量,就会阻塞抢占资源的进程
在运行时,可以明显的观察到,三个进程为一组一起运行,然后再三个进程
from threading import Thread,Semaphore
import time
semaphore = Semaphore(3)
def task(index):
semaphore.acquire()
print(f'threading {index} is running ')
time.sleep(2)
semaphore.release()
if __name__ == '__main__':
for i in range(9):
t = Thread(target=task,args=(i,))
t.start()
九、Event 事件
一些进程/线程 需要等待另外的 进程/线程 运行结束后才能运行
汽车需要遵守红绿灯的指示才能通行
from threading import Thread,Event
import time
event = Event() # 造了一个红绿灯
def light_thread():
print('红灯亮着\n')
# 等待绿灯亮
time.sleep(3)
print('绿灯了!!!!')
# 需要通知汽车已经绿灯了,汽车接受这个信号
event.set()
def car_thread(name):
print(f'{name}号汽车正在等红灯')
# 等待收到绿灯信号
event.wait()
print(f'{name}号汽车通过')
if __name__ == '__main__':
# 先开启信号灯进程
light = Thread(target=light_thread)
light.start()
for i in range(5):
# 开启多个汽车进程
car = Thread(target=car_thread,args=(i,))
car.start()