朴素贝叶斯 半朴素贝叶斯_SQL Server中的朴素贝叶斯预测
朴素贝叶斯 半朴素贝叶斯
In this article, we will walk through Microsoft Naive Bayes algorithm in SQL Server.
在本文中,我们将逐步介绍SQL Server中的Microsoft Naive Bayes算法。
In my previous article, SQL data mining, we discussed what data mining is and how to set up the data mining environment in SQL Server. We briefly said that there are several algorithms which you can select during the setting up of the data mining environment. As mentioned before, we are going to discuss the first algorithm which is Microsoft Naive Bayes in this article.
在我的前一篇文章SQL数据挖掘中 ,我们讨论了什么是数据挖掘以及如何在SQL Server中设置数据挖掘环境。 简短地说,在设置数据挖掘环境期间,可以选择几种算法。 如前所述,我们将在本文中讨论第一个算法,即Microsoft Naive Bayes。
什么是朴素贝叶斯 (What is Naive Bayes)
Bayes theory was discovered by Rev. Thomas Bayes in 1763 with the example of a newborn child who is witnessing a sunrise for the first time. Let us look at a more modern example. Let us look at an example from the medical arena. The hospital that sees patients for dengue has started to collect data. So they have found that there are several symptoms of dengue patients. High fever, body ache, vomiting, and headaches are few those symptoms and we will limit the symptoms for only those for the purpose of discussion. Now, if you are statistician, you would say, out of the dengue patients, 75% had a high fever and 80% had vomiting. Though these numbers give you some idea, what we need to know as a policy decision-maker, what is the percentage that the patient will have dengue given that he has a fever? Naive Bayes theory can convert to unknown from what you know.
贝叶斯理论是由托马斯·贝叶斯牧师在1763年发现的,以一个初次目睹日出的新生婴儿为例。 让我们看一个更现代的例子。 让我们从医疗领域来看一个例子。 看到有登革热病人的医院已经开始收集数据。 因此,他们发现登革热患者有几种症状。 高烧,身体疼痛,呕吐和头痛是这些症状的极少数,出于讨论目的,我们仅将这些症状限制为仅这些症状。 现在,如果您是统计学家,您会说登革热患者中有75%的人发高烧,而80%的人有呕吐。 尽管这些数字使您有所了解,但作为政策决策者我们需要知道的是,患者发烧后登革热的百分比是多少? 朴素贝叶斯理论可以从您所知道的转变为未知。
Following is the equation for the famous Bayes theory.
以下是著名的贝叶斯理论的方程式。
P ( A / B) = P ( B / A) * P (A) / P(B)
P(A / B)= P(B / A)* P(A)/ P(B)
P ( A / B) = The likelihood of event A occurring, given that B is true.
P(A / B)=如果B为真,则发生事件A的可能性。
P ( B / A ) = The likelihood of event B occurring given that A is true.
P(B / A)=假设A为真,则事件B发生的可能性。
P ( A) and P(B) are the probabilities of events A and B independently of each other.
P(A)和P(B)是事件A和B彼此独立的概率。
Let us look at this from the dengue and fever example.
让我们从登革热和热病的例子来看一下。
The likelihood of having dengue given that the patient is having fever = the likelihood of the patient is having fever given that the patient is suffering from dengue * Probability of patient having dengue / Probability of patient having a fever.
假设患者发烧而患有登革热的可能性=鉴于患者患有登革热而患有发烧的可能性*患有登革热的患者的可能性/患有发烧的患者的可能性。
In the above example, to decide whether the patient is suffering from dengue, there are more than one parameter such as vomiting, body ache, headache etc. So you need all these parameters to be analyzed in order to predict whether the patient has dengue.
在上面的示例中,要确定患者是否患有登革热,有多个参数,例如呕吐,身体疼痛,头痛等。因此,需要对所有这些参数进行分析,以预测患者是否患有登革热。
微软朴素贝叶斯 (Microsoft Naive Bayes)
Microsoft Naive Bayes is a classification supervised learning. This data set can be bi-class which means it has only two classes. Whether the patient is suffering from dengue or not or whether your customers are bike buyers or not, are an example of the bi-class data set. There can be multi-class data set as well.
Microsoft Naive Bayes是分类监督学习。 该数据集可以是双类别的,这意味着它只有两个类别。 患者是否患有登革热,或者您的顾客是否是自行车购买者,都是双类数据集的一个例子。 也可以有多类数据集。
Let us take the example which we discussed in the previous article, AdventureWorks bike buyer example. In this example, we will use vTargetMail database view in the AdventureWorksDW database.
让我们以在上一篇文章中讨论过的AdventureWorks自行车购买者示例为例。 在此示例中,我们将在AdventureWorksDW数据库中使用vTargetMail数据库视图。
During the data mining algorithm wizard, the Microsoft Naive Bayes algorithm should be selected as shown in the below image.
在数据挖掘算法向导中,应选择Microsoft Naive Bayes算法,如下图所示。
Next is to select relevant attributes which we will think will be impacted on bike buying. As we said last time, there are three types of attributes, Key, Predictable and Input.
接下来是选择相关属性,我们认为这些属性会影响自行车的购买。 正如我们上次说的,属性共有三种类型,键,可预测和输入。
So, we are going to predict, whether the customer will buy a bike or not. Therefore the predictable column is Bike Buyer. Each row should be uniquely identified using a Key and Customer Key is the key in this example.
因此,我们将预测客户是否会购买自行车。 因此,可预测的列是“ 自行车购买者”。 在此示例中,应使用键唯一地标识每一行,而客户键是键。
Next is to select inputs which will impact customer buying.
接下来是选择将影响客户购买的输入。

In most cases, you can choose the necessary columns with your experience and sense. However, if you are unable to choose, there is a Suggest button which will give you suggestions as shown in the below image.
在大多数情况下,您可以根据自己的经验和感觉选择必要的列。 但是,如果您无法选择,则有一个“ 建议”按钮,它将为您提供建议,如下图所示。
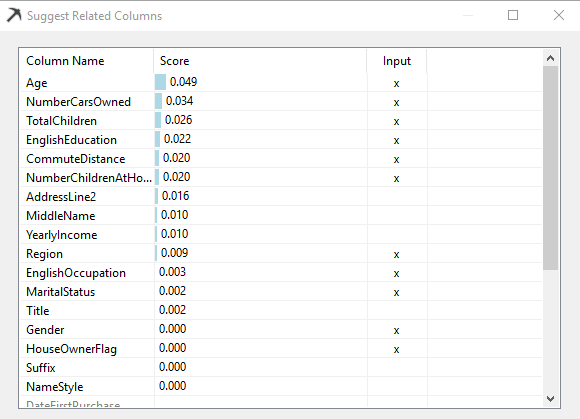
By analyzing data, a suggestion will provide you attributes which the system thinks will have a higher impact. You can choose the impact columns directly from this screen itself.
通过分析数据,建议将为您提供系统认为会产生更大影响的属性。 您可以直接从此屏幕本身选择影响列。
After completing the selection of input columns, the following screen will be displayed as shown in the below image.
完成输入列的选择后,将显示以下屏幕,如下图所示。
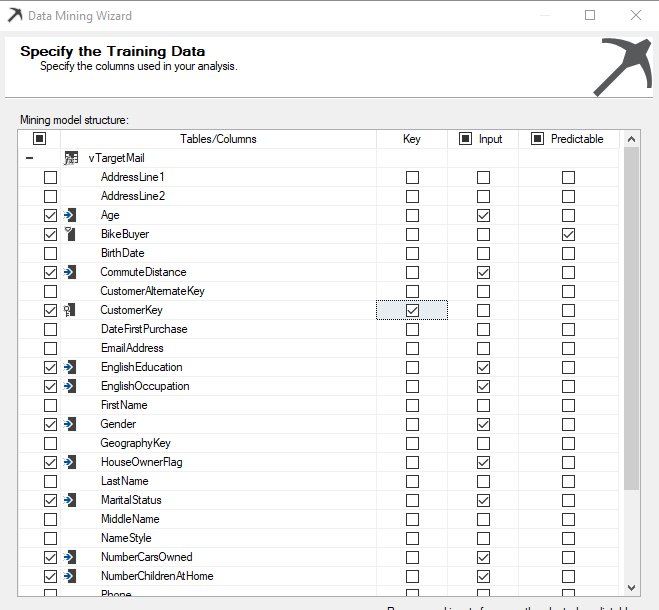
After the selection of attribute is completed, the next screen is to choose Content-Type and Data Type. You would notice that Age, Bike Buyer, Number Cars Owned, Number Children At Home and Total Children will have Discretized Content-Type and Data Type is Long. Discretized Content-Type is not compatible with Microsoft Naive Bayes. Therefore, those attributes have to be changed to Discrete, and Data type should be selected as text. The screen will appear like the following after you correctly configure the content type.
属性选择完成后,下一个屏幕是选择Content-Type和Data Type 。 您会注意到,年龄,自行车购买者,拥有的汽车数量,在家中的子代数和子代总数将具有离散化的Content-Type和Data Type为Long 。 离散内容类型与Microsoft Naive Bayes不兼容。 因此,必须将那些属性更改为“离散”,并且应选择“数据类型”作为文本。 正确配置内容类型后,屏幕将显示如下。

After this, next is to provide the test and train data set parameters and default values are used here. Next is to process the mining model so that it can be consumed by the end-users.
此后,下一步是提供测试和训练数据集参数,此处使用默认值。 接下来是处理挖掘模型,以便最终用户可以使用它。
挖掘模型查看器 (Mining Model Viewer)
After the mining model is built, next step is to analyze the model. The mining model Viewer is next to the model viewer. In the model viewer, there are four options namely, Dependency Network, Attribute Profiles, Attribute Characteristic and Attribute Discrimination as shown in the below image.
构建挖掘模型后,下一步是分析模型。 挖掘模型查看器位于模型查看器旁边。 在模型查看器中,有四个选项,即依赖网络,属性配置文件,属性特征和属性区分,如下图所示。

依赖网络 (Dependency Network)
The dependency network is a clear indicator of which attributes make a high or low impact towards the predictable attribute. In the following image, it elaborates what are the attributes which have a higher impact to decide Bike Buyer.
依存关系网络可以清楚地指示哪些属性对可预测属性产生高低影响。 在下图中,它详细说明了对决定“ 自行车购买者”具有更高影响的属性。
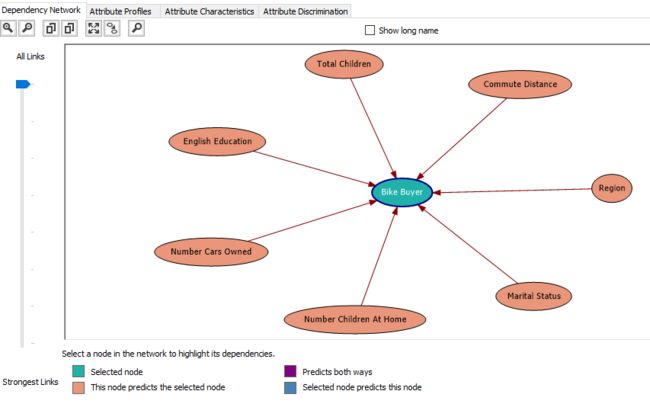
The above image indicates that Total Children, Commute Distance, Region, Marital Status, Number Children at Home, Number Cars Owned and English Education out of the other selected attributes. Out of these attributes, different attributes have different weightages of impacts. This can be identified by moving down the All Links to Strongest Links Slide bar which is at the left-hand side of the screen.
上图显示了其他所选属性中的“总孩子数”,“通勤距离”,“地区”,“婚姻状况”,“在家中的孩子数”,“拥有的汽车数量”和“英语教育”。 在这些属性中,不同的属性具有不同的影响权重。 可以通过将所有链接向下移动到最强链接滑动条(位于屏幕左侧)来识别此问题。
If the slide is at the very lowest place in the slide bar, you will see the strongest link as shown in the below image.
如果幻灯片位于幻灯片栏中的最低位置,您将看到最牢固的链接,如下图所示。

属性配置文件 (Attribute Profile)
In this classification problem, we will have two classes. Buying Bike (1) or Not Buying Bikes (0). Attribute Profile shows how each category has different combinations.
在这个分类问题中,我们将有两个类。 购买自行车(1)或不购买自行车(0)。 属性配置文件显示每个类别如何具有不同的组合。

This view can provide you a better view of understanding your data.
此视图可以为您提供更好的理解数据的视图。
属性特征 (Attribute Characteristics)
As a user, it would be nice to know what feature will make people buy a car so that they can target the customers who have those attributes.
作为用户,很高兴知道什么功能将使人们购买汽车,以便他们可以针对具有这些属性的客户。
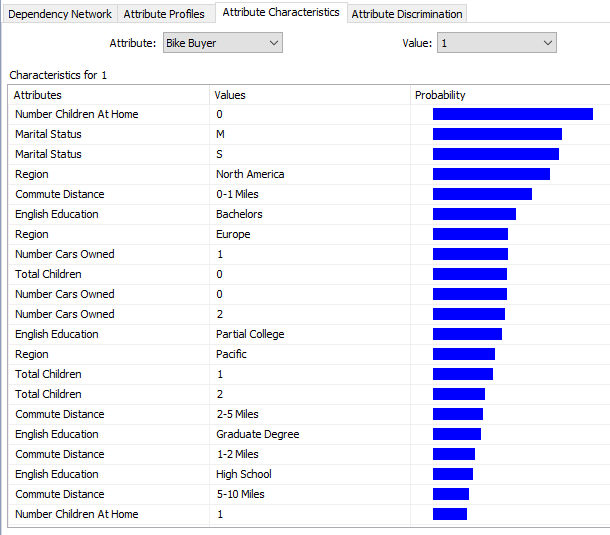
The above image indicates that customers who do not have children at home tend to buy bikes. Also, North America Region and Customers who commute 0-1 Miles will tend to buy bikes. This information is handy for the marketing department so that they can specifically target customers with these parameters.
上图表明,在家中没有孩子的顾客倾向于购买自行车。 同样,北美地区和通勤0-1英里的客户也倾向于购买自行车。 此信息对于市场部门很方便,因此他们可以使用这些参数专门针对客户。
属性区分 (Attribute Discrimination)
This tab gives you an answer to the question,” What is the difference between a bike buyer and not bike buyer”.
此标签为您提供了以下问题的答案:“自行车购买者与非自行车购买者有什么区别”。
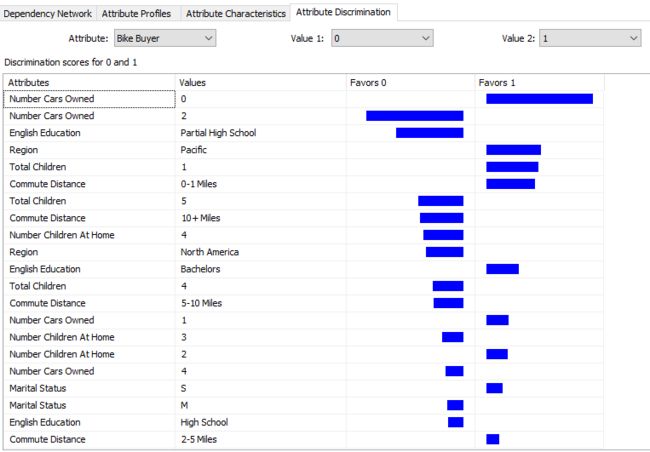
We will leave the prediction and accuracy calculation in a separate article as it is a discussion for all the algorithms.
我们将把预测和准确性计算放在单独的文章中,因为它是所有算法的讨论。
型号参数 (Model Parameters)
Depending on the environment, there are model parameters for each algorithm. By using these parameters, you can fine-tune the model. In the case of Microsoft Naive Bayes, there are four parameters which can be modified from the Mining Models and by selecting Set Algorithm Parameters from the Mining Model option in the main menu.
根据环境的不同,每种算法都有模型参数。 通过使用这些参数,您可以微调模型。 对于Microsoft Naive Bayes,有四个参数可以从挖掘模型中修改,也可以通过从主菜单的“ 挖掘模型”选项中选择“ 设置算法参数”来修改。
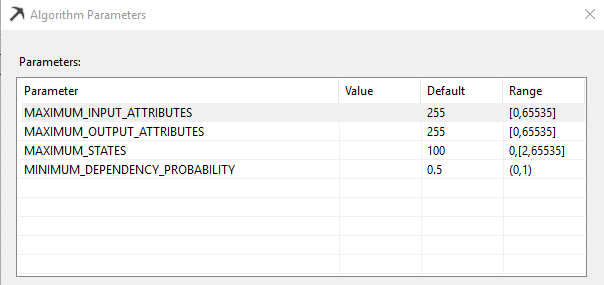
Maximum_Input_Attributes (Maximum_Input_Attributes)
Specifies the maximum number of input attributes that the algorithm can handle before invoking feature selection. Setting this value to 0 disables feature selection for input attributes. This is an Enterprise edition feature. The default value is 255.
指定在调用功能部件选择之前算法可以处理的最大输入属性数。 将此值设置为0将禁用输入属性的特征选择。 这是企业版功能。 默认值为255。
Maximum_Output_Attributes (Maximum_Output_Attributes)
Specifies the maximum number of output attributes that the algorithm can handle before invoking feature selection. Setting this value to 0 disables feature selection for output attributes. This is an Enterprise edition feature. The default value is 255.
指定在调用功能选择之前算法可以处理的最大输出属性数。 将此值设置为0将禁用输出属性的功能选择。 这是企业版功能。 默认值为255。
Maximum_States (Maximum_States)
Specifies the maximum number of attribute states that the algorithm supports. If the number of states that an attribute has is greater than the maximum number of states, the algorithm uses the attribute’s most popular states and treats the remaining states as missing. This is an Enterprise edition feature. The default value is 100.
指定算法支持的最大属性状态数。 如果某个属性具有的状态数大于最大状态数,则该算法将使用该属性的最受欢迎状态,并将其余状态视为丢失。 这是企业版功能。 默认值为100。
Minimum_Dependency_Probability (Minimum_Dependency_Probability)
Specifies the minimum dependency probability between input and output attributes. This value is used to limit the size of the content generated by the algorithm. This property can be set from 0 to 1. Increasing this value reduces the number of attributes in the model. If this has a higher values, you might not see some attributes in the Dependency Network. The default value is 0.5.
指定输入和输出属性之间的最小依赖关系概率。 该值用于限制算法生成的内容的大小。 可以在0到1之间设置此属性。增加该值将减少模型中的属性数量。 如果此值较高,则在依赖网络中可能看不到某些属性。 默认值为0.5。
Microsoft朴素贝叶斯算法的局限性 (Limitations of the Microsoft Naive Bayes Algorithm)
The major issue is Microsoft Naive Bayes cannot handle continuous data. In the above example, we had to drop the yearly income though it is a very important attribute, simply because that attribute is a continuous variable.
主要问题是Microsoft Naive Bayes无法处理连续数据。 在上面的示例中,我们必须删除年收入,尽管它是一个非常重要的属性,只是因为该属性是一个连续变量。
Naive Bayes Algorithm has a basic assumption that input attributes are independent of each other. If you look at the example, we know that Occupation and Qualification have a link between them. However, this algorithm will not be able to understand the relation between inputs.
朴素贝叶斯算法有一个基本假设,即输入属性彼此独立。 如果您看一下示例,我们知道职业和资格之间存在联系。 但是,该算法将无法理解输入之间的关系。
摘要 (Summary)
Microsoft Naive Bayes algorithm is a basic algorithm when you start into a data mining project. It will provide you a basic understanding about your data.
当您开始数据挖掘项目时,Microsoft Naive Bayes算法是一种基本算法。 它将为您提供有关数据的基本知识。
In the next article, we will discuss Microsoft Decision Trees algorithms.
在下一篇文章中,我们将讨论Microsoft决策树算法。
目录 (Table of contents)
| Introduction to SQL Server Data Mining |
| Naive Bayes Prediction in SQL Server |
| Microsoft Decision Trees in SQL Server |
| Microsoft Time Series in SQL Server |
| Association Rule Mining in SQL Server |
| Microsoft Clustering in SQL Server |
| Microsoft Linear Regression in SQL Server |
| Implement Artificial Neural Networks (ANNs) in SQL Server |
| Implementing Sequence Clustering in SQL Server |
| Measuring the Accuracy in Data Mining in SQL Server |
| Data Mining Query in SSIS |
| Text Mining in SQL Server |
| SQL Server数据挖掘简介 |
| SQL Server中的朴素贝叶斯预测 |
| SQL Server中的Microsoft决策树 |
| SQL Server中的Microsoft时间序列 |
| SQL Server中的关联规则挖掘 |
| SQL Server中的Microsoft群集 |
| SQL Server中的Microsoft线性回归 |
| 在SQL Server中实现人工神经网络(ANN) |
| 在SQL Server中实现序列聚类 |
| 在SQL Server中测量数据挖掘的准确性 |
| SSIS中的数据挖掘查询 |
| SQL Server中的文本挖掘 |
翻译自: https://www.sqlshack.com/naive-bayes-prediction-in-sql-server/
朴素贝叶斯 半朴素贝叶斯