动态规划整理
文章目录
- 动态规划刷题
-
- ⭐⭐⭐网格型
-
- 62. 不同路径-中等
- 63. 不同路径 II-中等
- 64. 最小路径和-中等
- ⭐⭐⭐ 2字符串类型:
-
- 72. 编辑距离-hard
- 583.两个字符串的删除-中等
- 10.正则表达式匹配-hard-不太会
- 97. 交错字符串-困难
- 1143. 最长公共子序列LCS-中等
- 44. 通配符匹配-困难-不会
- ⭐⭐⭐单字符串、子序列问题
-
- 子序列求极值的题目,应该要考虑到贪心或者动态规划
- 674. 最长连续递增序列-简单
- 300. 最长上升(递增)子序列-LIS-中等
- 354.俄罗斯套娃信封问题
- 368. 最大整除子集
- 673. 最长递增子序列的个数
- 491. 递增子序列
- ⭐⭐⭐最长上升子序列DP×区间覆盖问题
-
- 435. 无重叠区间
- 646. 最长数对链
- 452. 用最少数量的箭引爆气球
- 1288. 删除被覆盖区间
- ⭐⭐⭐单数组/字符串×子序和相关问题
-
- 53. 最大子序和
- 面试题 17.24. 最大子矩阵
- 363. 矩形区域不超过 K 的最大数值和-困难
- 85. 最大矩形-困难
- ⭐⭐⭐单字符串补充×区间型DP
-
- 5-最长回文子串-中等
- 516. 最长回文子序列-中等
- 312. 戳气球-困难
- 87. 扰乱字符串-困难-不懂
- 131. 分割回文串
- 132. 分割回文串 II
- 1278. 分割回文串 III-困难
- ⭐⭐⭐单数组/字符串×划分型
-
- 139. 单词拆分-中等
- 140. 单词拆分 II-困难
- 55. 跳跃游戏
- 45. 跳跃游戏 II-hard-未作
- ⭐⭐⭐单数组×博弈型
-
- 877. 石子游戏-博弈型
- [1140. 石子游戏 II-中等]
- 1406. 石子游戏 III-困难
- 1510. 石子游戏 IV-困难
- ⭐⭐⭐完全背包
-
- 377. 组合总和 Ⅳ-同coinChange2
- 322. 零钱兑换-1-中等
- 279. 完全平方数-中等
- 518. 零钱兑换 II-中等
- ⭐⭐⭐0-1背包问题
-
- 416-分割等和子集
- 474. 一和零
- 494. 目标和
- ⭐⭐⭐极小极大值
-
- 887. (高楼扔鸡蛋)鸡蛋掉落-困难
- 375. 猜数字大小 II-中等-不好理解
- ⭐⭐⭐单调栈-单数组问题
-
- 84. 柱状图中最大的矩形
- 85. 最大矩形-困难
- 739. 每日温度-中等
- 496. 下一个更大元素 I-简单
- 42. 接雨水-困难-单调栈、双指针
- 221. 最大正方形-单调栈*DP
- 128. 最长连续序列-困难
- 303. 区域和检索 -前缀和-简单
- ⭐⭐⭐栈-单数组问题
-
- 316. 去除重复字母(困难)
- 321. 拼接最大数(困难)
- 402. 移掉 K 位数字(中等)
- 1081. 不同字符的最小子序列(中等)-同316
- ⭐⭐⭐打家劫舍系列
-
- 198-打家劫舍(house robber) -简单-序列型
- 213-house robber2 -破圈、序列型
- 337. 打家劫舍 III-中等
- ⭐⭐⭐股票买卖问题
-
- 121.买卖股票的最佳时机-简单
- 122.买卖股票2-简单
- 123. 买卖股票的最佳时机 III-hard-不会
- 188. 买卖股票的最佳时机 IV-困难-不会
- 309. 最佳买卖股票时机含冷冻期-中等-未做
- 714. 买卖股票的最佳时机含手续费-中等-未做
- ⭐⭐⭐单字符×DP
-
- Offer 46. 把数字翻译成字符串
- 91.解码方法(medium)
- ⭐⭐⭐KMP算法-单字符串
-
- KMP 算法详解
- 28. KMP实现 strStr()-简单
- 459. 重复的子字符串-简单
- 1392.最长快乐前缀-困难
- ⭐⭐⭐斐波那契系列
-
- 509. 斐波那契数
- 爬楼梯-简单
- ⭐⭐⭐其他
-
- 120.三角形最小路径和-中等
- 124. 二叉树中的最大路径和
- 376. 摆动序列
- 324.摆动排序 II-中等-未作
- 343. 整数拆分-中等
- 137.只出现一次的数字II
- 32. 最长有效括号-hard-动态规划不会
- 413.等差数列划分-单数组*DP
- 96. 不同的二叉搜索树-中等
- 95. 不同的二叉搜索树 II-中等-未做
- 329. 矩阵中的最长递增路径-DFS
- 650.只有两个键的键盘-中等-没懂-dp
- 263. 丑数-简单
- 264. 丑数 II-中等
- 1201. 丑数 III-中等
- 基础知识、拓展
-
-
- 基础1-动态规划详解
- 基础2-动态规划答疑篇
- 基础3-动态规划:不同的定义产生不同的解法
- 基础4-⭐动态规划初探及什么是无后效性?
- 基础5-DP总结
- 关于区间DP
-
动态规划刷题
⭐⭐⭐网格型
62. 不同路径-中等
LeetCode链接

- python实现
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
# 类型: 1) 网格型; 2)dp=m*n; 3)可加性求和:dp[i][j]=dp[i-1][j]+dp[i][j-1];
# 步骤1:dp含义/初始化: dp[i][j]:[0,0]到坐标[i,j]不同路径数目;
dp = [[1 for _ in range(n)] for _ in range(m)]
# 步骤4:边界条件;
for i in range(m):
dp[i][0] = 1
for j in range(n):
dp[0][j] = 1
# 步骤2:遍历填表;
for i in range(1, m):
for j in range(1, n):
# 步骤3:转移方程;
dp[i][j] = dp[i-1][j] + dp[i][j-1]
# 步骤5:返回结果
return dp[-1][-1]
63. 不同路径 II-中等
LeetCode链接

class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
# 类型: 1)网格型; 2)dp=m*n; 3)可加性求和:dp[i][j]=dp[i-1][j]+dp[i][j-1];
# 步骤1:dp定义/初始化:dp[i][j]:[0,0]到[i,j]不同路径数目;
m, n = len(obstacleGrid), len(obstacleGrid[0])
dp = [[0 for _ in range(n)] for _ in range(m)]
# 步骤4:边界条件;
if obstacleGrid[0][0] == 1:
dp[0][0] = 0
else:
dp[0][0] = 1
for i in range(1, m):
if obstacleGrid[i][0] == 1:
dp[i][0] = 0
else:
dp[i][0] = dp[i-1][0]
for j in range(1, n):
if obstacleGrid[0][j] == 1:
dp[0][j] = 0
else:
dp[0][j] = dp[0][j-1]
# 步骤2:遍历填表;
for i in range(1, m):
for j in range(1, n):
# 步骤3:转移方程;
if obstacleGrid[i][j] == 1:
dp[i][j] = 0
else:
dp[i][j] = dp[i-1][j] + dp[i][j-1]
# 步骤5:返回结果;
return dp[-1][-1]
64. 最小路径和-中等
LeetCode链接
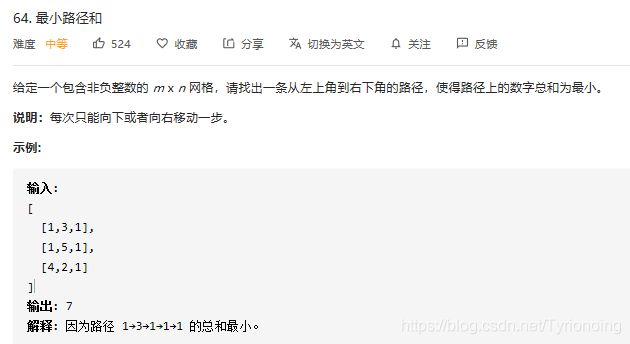
- python实现
class Solution:
def minPathSum(self, grid: List[List[int]]) -> int:
# 类型: 1)网格型; 2)dp=m*n; 3)最小值问题:dp[i][j]=min(dp[i-1][j], dp[i][j-1])+val
# 步骤1:dp定义/初始化:dp[i][j]:[0,0]到[i,j]最小路径和;
m, n = len(grid), len(grid[0])
dp = [[float('inf') for _ in range(n)] for _ in range(m)] # 初始化inf;
dp[0][0] = grid[0][0]
# 步骤4:边界条件;
for i in range(1, m):
dp[i][0] = dp[i-1][0] + grid[i][0]
for j in range(1, n):
dp[0][j] = dp[0][j-1] + grid[0][j]
# 步骤2:遍历填表;
for i in range(1, m):
for j in range(1, n):
# 步骤3:转移方程;
dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]
# 步骤5:返回
return dp[-1][-1]
⭐⭐⭐ 2字符串类型:
72. 编辑距离-hard
LeetCode链接
参考 详解一道腾讯面试题:编辑距离
参考编辑距离面试题详解
72. 编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')

- python代码-自己
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
# 类型:1)2字符串/数组; 2)dp=(m+1)*(n+1);
# 3)矩阵转移:dp=min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])
# 框架1: dp定义/初始化: dp[i][j]:字符串1前i个字符 与 字符串2前j个字符 的编辑距离;
m, n = len(word1), len(word2)
dp = [[0 for _ in range(n+1)] for _ in range(m+1)]
# 框架4: 边界条件;
for i in range(1+m):
dp[i][0] = i
for j in range(1+n):
dp[0][j] = j
# 框架2:遍历填表;
for i in range(1, m+1):
for j in range(1, n+1):
# 框架3:转移方程;
if word1[i-1] == word2[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
# dp[i-1][j]:删除; dp[i][j-1]:插入; dp[i-1][j-1]:替换;
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1
# 框架5:返回;
return dp[-1][-1]
583.两个字符串的删除-中等
LeetCode链接
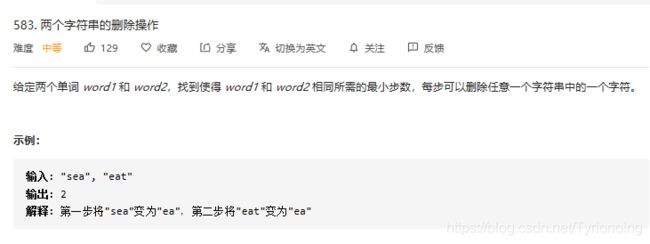
- 完全抄: 编辑距离
- 自己AC-python
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
# 本质依然是编辑距离: 设定word1变为word2,
# 对于: word1插入= word2删除;
# 对于: word1删除;
# 对于: 替换: 等于两次:删除; 此题可以不考虑, 包含在 分别删除操作中;
m, n = len(word1), len(word2)
if m * n == 0:
return m+n
dp = [[0 for _ in range(n+1)] for _ in range(m+1)]
# base case
for i in range(m+1):
dp[i][0] = i
for j in range(n+1):
dp[0][j] = j
# 遍历填表
for i in range(1, m+1):
for j in range(1, n+1):
if word1[i-1] == word2[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = 1 + min(
dp[i-1][j],
dp[i][j-1]
)
return dp[-1][-1]
10.正则表达式匹配-hard-不太会
LeetCode链接
参考* 题解-动态规划之正则表达式
10. 正则表达式匹配
难度
困难
1318
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。
因此,字符串 "aa" 可被视为 'a' 重复了一次。
参考 动态规划及回溯
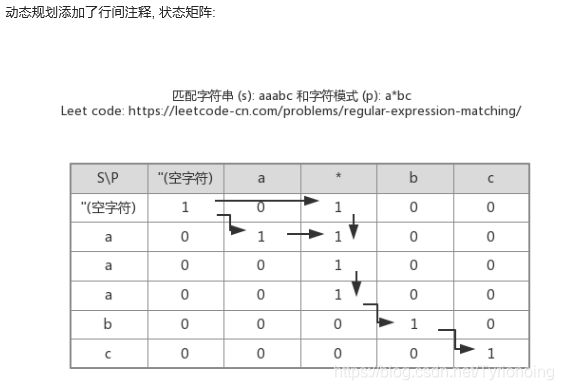
- python实现:上面思路截图
class Solution:
def isMatch(self, s: str, p: str) -> bool:
# 思路: 动态规划, ay沿着匹配串 和 字符串 构成矩阵的对角线传递状态;
# 1. 状态矩阵的首行和首列对应于空字符串匹配;
# 2. *** 对角线意味着匹配串是否匹配对应的字符串***。
ns, np = len(s), len(p)
dp = [[False for _ in range(np + 1)] for _ in range(ns+1)]
dp[0][0] = True
# 初始化: 匹配空字符串的情况, 匹配串为 空时已经为False, 不在跟新; [0, 列];
for i in range(1, np+1):
# 根据规则: * 前必须存在一个字符, 则 当前为 * 时候, 其状态与 前2的状态一致;
if p[i-1] == '*' and dp[0][i-2]:
dp[0][i] = dp[0][i-2]
# 更新状态矩阵
for i in range(1, ns+1):
for j in range(1, np+1):
# i,j 是矩阵的行与列, 对应到匹配串的索引要 -1
# 匹配串 与 字符串匹配(相等或为.) 传递状态;
if p[j-1] == s[i-1] or p[j-1] == '.':
dp[i][j] = dp[i-1][j-1]
# 匹配字符串 * 字符特殊处理
elif p[j-1] == '*':
# 根据匹配规则, 比较匹配串 * 的前一个字符与字符串的前一个字符;
# 情况1: 二者不相等时: a*只有作为 空串时才可能匹配;
# 这就是说:掠过前1个字符, *字符对应的状态 与 字符串中前2个字符的状态一直;
if p[j-2] != s[i-1]:
dp[i][j] = dp[i][j-2]
# ****** 最难、最经典的地方;
# 情况2: 二者相等时, 有三种情况
# 1) a* 作为 空字符串; 2) 单字符串a; 3) 多字符串 aaa
if p[j-2] == s[i-1] or p[j-2] == '.':
dp[i][j] = dp[i][j-2] or dp[i][j-1] or dp[i-1][j]
return dp[ns][np]
- 精简版本
class Solution:
def isMatch(self, s: str, p: str) -> bool:
# 思路:动态规划,沿着匹配串和字符串构成的对角线传递状态;
ns, np = len(s), len(p)
dp = [[False for _ in range(np+1)] for _ in range(ns+1)]
dp[0][0] = True
# 初始化
for i in range(1, np+1):
if p[i-1] == '*' and dp[0][i-2]:
dp[0][i] = dp[0][i-2]
# 更新状态矩阵
for i in range(1, ns+1):
for j in range(1, np+1):
# p[j-1]前两种情况;
if p[j-1] == s[j-1] or p[j-1] == '.':
dp[i][j] = dp[i-1][j-1]
elif p[j-1] == '*':
# 1) 二者不相等时候: a*只有为空串才可能匹配;
if p[j-2] != s[i-1]:
dp[i][j] = dp[i][j-2]
# 2) 两者相等时:三种情况;
if p[j-2] == s[i-1] or p[j-2] == '.':
dp[i][j] = dp[i][j-2] or dp[i][j-1] or dp[i-1][j]
return dp[ns][np]
97. 交错字符串-困难
LeetCode链接

参考 动态规划 逐行解释 python3
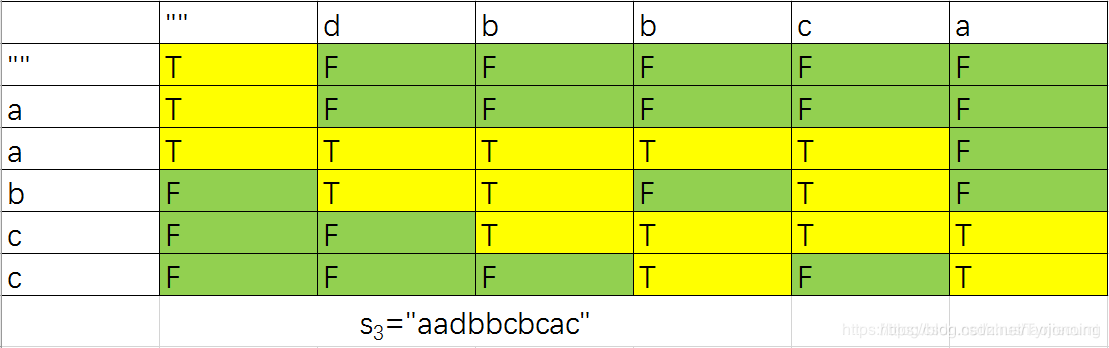

- 基本抄大佬代码:
- 知道两字符串怎么构建矩阵,但是没有想明白: 怎样转移,原本想法是通过: count 元素数目,但是发现没办法转移:
class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
# 思路: 动态规划;
# 没想明白转移方程: 之前考虑使用 滑动窗口思想,判断
len1 = len(s1)
len2 = len(s2)
len3 = len(s3)
# 剪枝
if len1 + len2 != len3:
return False
# dp[i][j]: s1:前i个字符串 + s2:前j字符串 能否组成s3: 前 i+j 字符串;
dp = [[False for _ in range(len2+1)] for _ in range(len1+1)]
# base case
dp[0][0] = True
# 第一行, s1= ''时候, 判断s2前j 字符是否完全匹配 s3前j 是否相等;
for j in range(1, len2 + 1):
if dp[0][j-1] and s2[j-1] == s3[j-1]:
dp[0][j] = True
# dp[0][j] = (dp[0][j-1] and s2[j-1] == s3[j-1])
# 第一列: s2 = ''时候, 判断 s1 前i 字符s是否完全匹配 s3前i字符;
for i in range(1, len1+1):
if dp[i-1][0] and s1[i-1] == s3[i-1]:
dp[i][0] = True
# dp[[i]][0] = (dp[i-1][0] and s1[i-1] == s3[i-1])
# 遍历填表;
for i in range(1, len1+1):
for j in range(1, len2+1):
# 两种情况: 1): 考虑: s1的前i-1个 + s2的前j 字符串和 s3是否匹配; 然后考虑将: s1的第i-1字符串加进去看看是否等于s3对应位置;
# 2):考虑 s2的前j-1 + s1的前i 字符串 和 s3是否匹配; 然后考虑: 将s2的第j-1字符串加进去看看是否等于s3对应位置;
dp[i][j] = (dp[i-1][j] and s1[i-1] == s3[i+j-1]) or (dp[i][j-1] and s2[j-1] == s3[i+j-1])
return dp[-1][-1]
1143. 最长公共子序列LCS-中等
LeetCode链接
参考 笔记-经典面试题:最长公共子序列
1143. 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的
最长公共子序列的长度。
一个字符串的 子序列 是指这样一个新的字符串:它是由
原字符串在不改变字符的相对顺序的情况下删除某些字符
(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,
但 "aec" 不是 "abcde" 的子序列。两个字符串的
「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。
示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc",它的长度为 3。
示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0。
- python实现
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
# 思路: 动态规划
# dp[i][j]: 字符1中: 1-i字符 与 字符2中: 1-j字符 的最长公共子序列
m, n = len(text1), len(text2)
dp = [[0 for _ in range(n+1)] for _ in range(m+1)]
# dp = [[0 for _ in range(n+1)] for_ in range(m+1)]
for i in range(1, m+1):
for j in range(1, n+1):
# 注意: dp[i][j] --> text1[i-1], text2[j-1]
if text1[i-1] == text2[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
return dp[-1][-1]
44. 通配符匹配-困难-不会
LeetCode链接

⭐⭐⭐单字符串、子序列问题
子序列求极值的题目,应该要考虑到贪心或者动态规划
674. 最长连续递增序列-简单
LeetCode链接
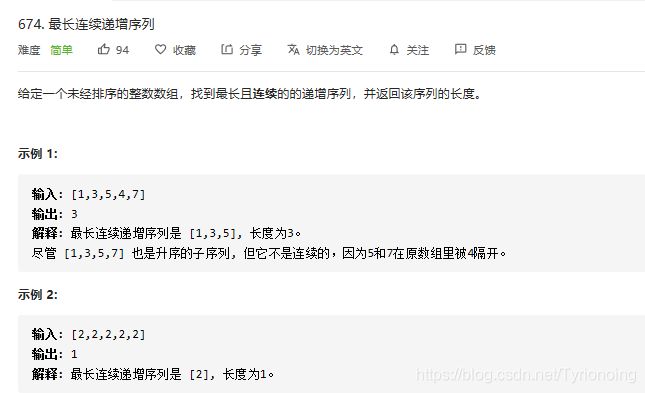
- python实现
class Solution:
def findLengthOfLCIS(self, nums: List[int]) -> int:
# 类型:1)单数组; 2)dp=m; 3)序列长度:dp[i]=dp[i-1]+1
if not nums:
return 0
# 步骤1:dp定义/初始化:dp[i]:以nums[i]结尾的最长递增序列长度;
dp = [1 for _ in range(len(nums))]
# 步骤4:边界条件;
# 步骤2:遍历填表;
for i in range(1, len(nums)):
# 步骤3:转移方程;
if nums[i] > nums[i-1]:
dp[i] = dp[i-1] + 1
# 步骤5:返回
return max(dp)
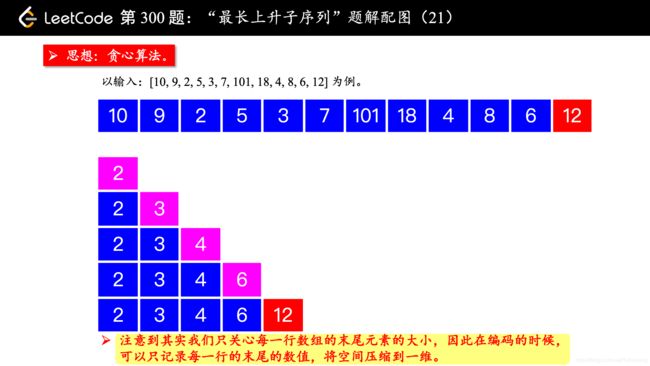
300. 最长上升(递增)子序列-LIS-中等
LeetCode链接
参考 动态规划设计之最长递增子序列
300. 最长上升子序列
给定一个无序的整数数组,找到其中最长上升子序列的长度。
示例:
输入: [10,9,2,5,3,7,101,18]
输出: 4
解释: 最长的上升子序列是 [2,3,7,101],它的长度是 4。
- python
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
'''
# 类型: 1)单数组; 2)dp=m; 3)最长序列长度:dp[i]=max(dp[i],dp[j]+1);
# 时间:O(n^2); 空间:O(n);
if not nums:
return 0
# 框架1:dp定义/初始化:dp[i]:以nums[i]结尾最长上升子序列长度;
dp = [1 for _ in range(len(nums))]
# 框架4:边界条件;
# 框架2: 遍历填表;
for i in range(len(nums)):
for j in range(i):
# 框架3:转移方程
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j]+1)
# 框架5:返回;
return max(dp)
'''
# 类型:1)采用二分查找进一步优化:内部判断过程;
# 时间复杂度:O(NlogN); 空间复杂度:O(N);
if not nums:
return 0
tails = [nums[0]]
# 遍历填表;
for i in range(len(nums)):
if nums[i] > tails[-1]:
tails.append(nums[i])
continue
# 二叉查找维护长度为l的最小结尾;
left, right = 0, len(tails)-1
while left <= right:
mid = left+(right-left)//2
if nums[i] > tails[mid]:
left = mid + 1
elif nums[i] < tails[mid]:
right = mid - 1
elif nums[i] == tails[mid]:
right = mid - 1
tails[left] = nums[i]
return len(tails)
参考1: ⭐最长上升子序列(动态规划 + 二分查找,清晰图解)
参考2:⭐动态规划 、优化(以贪心和二分作为子过程)
- 动态规划+二分查找:


354.俄罗斯套娃信封问题
LeetCode链接
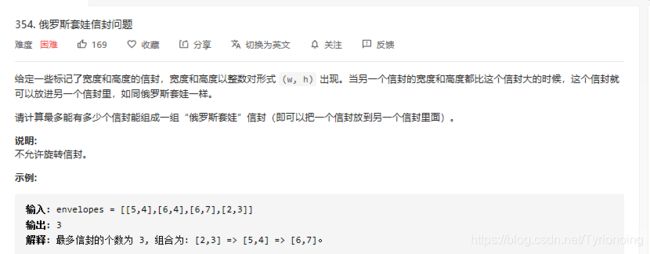
- python实现:
class Solution:
def maxEnvelopes(self, envelopes: List[List[int]]) -> int:
# 思路: 二维最长上升子序列;
if not envelopes or not envelopes[0]:
return 0
sortEnvelopes = sorted(envelopes, key= lambda x:(x[0], -x[1]))
enves = [w for h,w in sortEnvelopes]
'''
# 思路1:dp
# 类型: 1)单数组; 2)dp=m; 3)最长长度dp[i]=max(dp[i], dp[j]+1)
# 框架1:dp定义/初始化:dp[i]:以nums[i]结尾最长上升序列长度;
dp = [1 for _ in range(len(enves))]
# 框架4:边界条件;
# 框架2:遍历填表;
for i in range(len(enves)):
for j in range(i):
# 框架3:转移方程;
if enves[i] > enves[j]:
dp[i] = max(dp[i], dp[j]+1)
# 框架5:返回;
return max(dp)
'''
# 思路2:二分查找进一步优化内部判断过程;
tails = [enves[0]]
for i in range(len(enves)):
if enves[i] > tails[-1]:
tails.append(enves[i])
continue
# 二分查找找位置;
left, right = 0, len(tails)-1
while left <= right:
mid = left + (right-left)//2
if enves[i] < tails[mid]:
right = mid - 1
elif enves[i] > tails[mid]:
left = mid + 1
elif enves[i] == tails[mid]:
right = mid - 1
tails[left] = enves[i]
return len(tails)
368. 最大整除子集
LeetCode链接

- 最长上升子序列思路
class Solution:
def largestDivisibleSubset(self, nums: List[int]) -> List[int]:
# 类型: 1)单数组; 2)dp=m; 3)最长序列:dp[i]=max(dp[i], dp[j]+1)
if not nums:
return []
nums.sort()
# 框架1:dp定义/初始化:dp[i]:以nums[i]结尾的最长整除子集;
dp = [1 for _ in range(len(nums))]
result = [[] for _ in range(len(nums))]
# 框架4:边界条件;
# 框架2:遍历填表;
for i in range(len(nums)):
number = i
for j in range(i):
# 状态3:转移方程;
if nums[i]%nums[j] == 0 and dp[j]+1 > dp[i]:
dp[i] = dp[j] + 1
number = j
if number != i:
# 如果:dp[i]进行了更新,则将之前结果extend;
result[i].extend(result[number])
result[i].append(nums[i])
index = dp.index(max(dp))
return result[index]
673. 最长递增子序列的个数
LeetCode链接



- python两个数组实现:
- 复杂度分析
时间复杂度: O ( N 2 ) O(N^2) O(N2),两个forloopfor loopforloop
空间复杂度: O ( N ) O(N) O(N),dpdpdp与countercountercounter数组长度NNN
class Solution:
def findNumberOfLIS(self, nums: List[int]) -> int:
# 类型:1)单数组; 2)dp=m; 3)最长递增:dp[i]=max(dp[i],dp[j]+1)
# 思路:使用counter记录nums[i]结尾最长递增子序列次数出现次数;
if not nums:
return 0
# 框架1:dp定义/初始化:dp[i]:以nums[i]结尾最长递增子序列长度;
dp = [1 for _ in range(len(nums))]
counter = [1 for _ in range(len(nums))]
# 框架4:边界条件;
# 框架2:遍历填表;
for i in range(len(nums)):
for j in range(i):
# 框架3:转移方程;
# 变更的前提: nums[i] > nums[j]
if nums[i] > nums[j]:
# 如果dp[j]+1 > dp[i]的长度,说明此时:dp[i]的数字第一次更新;
# 则继承之前的方式数目;
if dp[j] + 1 > dp[i]:
dp[i] = dp[j] + 1
counter[i] = counter[j]
# 由于dp[i]更新是由之前更新而来,所以出现等于时候,说明前面已经有更新;
elif dp[j]+1 == dp[i]:
counter[i] = counter[i] + counter[j]
# 后序处理
maxCount = max(dp)
res = 0
for i in range(len(counter)):
if dp[i] == maxCount:
res += counter[i]
return res
491. 递增子序列
LeetCode链接

- python实现:
class Solution:
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
# 思路:回溯
if not nums:
return []
def trackBack(nums, start, track):
'''
nums:可以选择的节点;
start: 开始搜索结果的起始范围;
track: 已经访问的路径;
'''
# 结束条件判断;
if len(track) >= 2 and track not in res:
res.append(track[:])
# 回溯方向选择;
for i in range(start, len(nums)):
# 回溯条件限制;
if len(track) > 0 and nums[i] < track[-1]:
continue
# 做选择:
track.append(nums[i])
# 进入下一值进行递归;
trackBack(nums, i+1, track)
# 回溯
track.pop()
res = []
track = []
trackBack(nums, 0, track)
return res
⭐⭐⭐最长上升子序列DP×区间覆盖问题
⭐最长上升子序列DP***区间覆盖问题
435. 无重叠区间
LeetCode链接
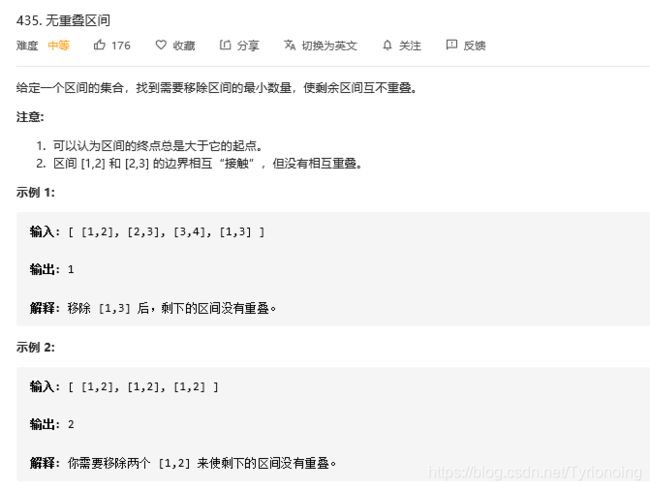
- python题解
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
if not intervals:
return 0
sortIntervals = sorted(intervals, key= lambda x:x[1])
compareBase = sortIntervals[0]
count = 1 # 无重叠区间个数;
for interval in sortIntervals:
if interval[0] >= compareBase[1]:
count += 1
compareBase = interval
# 计算最小移除区间数量 = 总数 - 最大不重叠个数;
return len(intervals) - count
- python-动态规划
- 复杂度分析
时间复杂度: O ( N 2 ) O(N ^ 2) O(N2)
空间复杂度: O ( N ) O(N) O(N)
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
n = len(intervals)
if n == 0: return 0
dp = [1] * n
ans = 1
intervals.sort(key=lambda a: a[1])
for i in range(len(intervals)):
for j in range(i - 1, -1, -1):
if intervals[i][0] >= intervals[j][1]:
dp[i] = max(dp[i], dp[j] + 1)
# 由于我事先进行了排序,因此倒着找的时候,找到的第一个一定是最大的数,因此不用往前继续找了。
# 这也是为什么我按照结束时间排序的原因。
break
dp[i] = max(dp[i], dp[i - 1])
ans = max(ans, dp[i])
return n - ans
646. 最长数对链
LeetCode链接

- python实现
class Solution:
def findLongestChain(self, pairs: List[List[int]]) -> int:
if not pairs:
return 0
sortPairs = sorted(pairs, key= lambda x:x[1])
count = 1
compareBase = sortPairs[0]
for pair in sortPairs:
if pair[0] > compareBase[1]:
count += 1
compareBase = pair
return count
- python动态规划
- 复杂度分析
时间复杂度: O ( N 2 ) O(N ^ 2) O(N2)
空间复杂度: O ( N ) O(N) O(N)
class Solution:
def findLongestChain(self, pairs: List[List[int]]) -> int:
n = len(pairs)
dp = [1] * n
ans = 1
pairs.sort(key=lambda a: a[0])
for i in range(n):
for j in range(i):
if pairs[i][0] > pairs[j][1]:
dp[i] = max(dp[i], dp[j] + 1)
ans = max(ans, dp[i])
return ans
452. 用最少数量的箭引爆气球
LeetCode链接

- 集合排序问题:
class Solution:
def findMinArrowShots(self, points: List[List[int]]) -> int:
pointsLen = len(points)
# base case
if pointsLen == 0:
return 0
# 按照end排序
sortPoints = sorted(points, key=lambda x:x[1])
print(sortPoints)
count = 1 # 无重叠区间个数;
compareBase = sortPoints[0]
for point in sortPoints:
if point[0] > compareBase[1]:
count += 1
compareBase = point
return count
- python动态规划
- 复杂度分析
时间复杂度: O ( N 2 ) O(N ^ 2) O(N2)
空间复杂度: O ( N ) O(N) O(N)
class Solution:
def findMinArrowShots(self, points: List[List[int]]) -> int:
n = len(points)
if n == 0: return 0
dp = [1] * n
cnt = 1
points.sort(key=lambda a:a[1])
for i in range(n):
for j in range(0, i):
if points[i][0] > points[j][1]:
dp[i] = max(dp[i], dp[j] + 1)
cnt = max(cnt, dp[i])
return cnt
1288. 删除被覆盖区间
LeetCode链接


- 菜鸡思路: 先排序,完了穷举;
- 时间复杂度: O ( N 2 ) O(N^2) O(N2)
class Solution:
def removeCoveredIntervals(self, intervals: List[List[int]]) -> int:
# 思路: 集合排序问题;
intervalsLen = len(intervals)
if intervalsLen == 0:
return 0
sortIntervals = sorted(intervals, key= lambda x:(x[0], -x[1]))
count = intervalsLen # 不重叠数目
for i in range(1, intervalsLen):
for j in range(i):
if sortIntervals[i][1] <= sortIntervals[j][1]:
count -= 1
break
return count
- 菜鸡进一步改进: 第二层的枚举用记录最大值代替;
- 时间复杂度: O ( N 2 ) O(N^2) O(N2)
class Solution:
def removeCoveredIntervals(self, intervals: List[List[int]]) -> int:
# 思路: 集合排序问题;
intervalsLen = len(intervals)
if intervalsLen == 0:
return 0
sortIntervals = sorted(intervals, key= lambda x:(x[0], -x[1]))
count = intervalsLen # 不重叠数目
maxValue = sortIntervals[0][1]
for i in range(1, intervalsLen):
if sortIntervals[i][1] <= maxValue:
count -= 1
else:
maxValue = sortIntervals[i][1]
return count
⭐⭐⭐单数组/字符串×子序和相关问题
53. 最大子序和
LeetCode链接

- python实现:
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
# 类型: 1)单数组; 2)dp=m; 3)求最大值:dp=max(dp[i],dp[i-1]+nums[i])
# 框架1:dp定义/初始化:dp[i]:以nums[i]结尾最大子序和;
dp = [num for num in nums]
# 框架4:边界条件;
# 框架2:遍历填表;
for i in range(1, len(nums)):
# 框架3:转移方程; nums[i]!!!nums[i]!!!nums[i]
dp[i] = max(dp[i], dp[i-1]+nums[i])
# 框架5:返回;
return max(dp)
面试题 17.24. 最大子矩阵
LeetCode链接

参考1 从最大子序和说起,由简到繁
参考2 python 最大子序和 ,leetcode 363套路

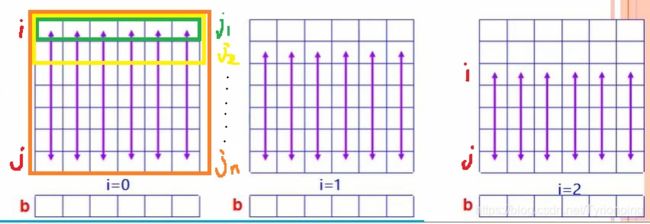
- 按照列进行求和; 每行求最大子序和;
# 时间复杂度:O(N^3)
class Solution:
def getMaxMatrix(self, matrix: List[List[int]]) -> List[int]:
# 类型:1)单数组(矩阵); 2)dp=m; 3)最大和:dp=max(nums[i],nums[i]+dp[i-1])
# 思路: 返回左上角、右下角坐标: 找到对应的行、列 即可;
# 二维DP转换为一维DP;
N, M = len(matrix), len(matrix[0])
# maxSum: 记录最大子矩阵和; i~j行;
maxSum = float('-inf')
# bestC1, bestR1:暂时记录左上角坐标:矩阵起始位置;
bestC1, bestR1 = 0, 0
ans = [0, 0, 0, 0] # 最终结果坐标;
# 遍历扫描1: 子矩阵的上边界: 第i行,按行扫描;
for i in range(N):
# 每次上边界更新,重新清空b,记录当前行起始每列的和;
# 数组b: 对应最大子序和中的给定数组,
# 记录第i行到第j行构成的矩阵对应的每一列之和; 二维变一维;
b = [0 for _ in range(M)]
# 遍历扫描2:子矩阵的下边界:第j行,按行扫描; 不断增加子矩阵的高;
for j in range(i, N):
# 此时:第i行~第j行构成矩阵,再在 列维度求最大和(子矩阵)即可;
# sums:相当于dp[i]:记录以nums[i]结尾最大子序和;
sums = 0
# 遍历扫描3: 计算第i行 到 第j行 b数组的值l
for k in range(M):
b[k] = b[k] + matrix[j][k]
# 按照最大子序和思路,计算最大值;
if sums>0:
sums = sums + b[k]
else:
# 重新开始一个区间; 暂时记录左上角开始位置;
sums = b[k]
bestC1 = i
bestR1 = k
# 全局找最大矩阵和;
if sums > maxSum:
maxSum = sums
ans[0] = bestC1
ans[1] = bestR1
ans[2] = j
ans[3] = k
return ans
- 按照行求和,然后对于列求最大子序和;
class Solution:
#leetcode 363 代码套路一样
def getMaxMatrix(self, matrix: List[List[int]]) -> List[int]:
row = len(matrix)
col = len(matrix[0])
maxArea = float('-inf') #最大面积
res = [0, 0, 0, 0]
for left in range(col): #从左到右,从上到下,滚动遍历
colSum = [0] * row #以left为左边界,每行的总和
for right in range(left, col): #这一列每一位为右边界
for i in range(row): #遍历列中每一位,计算前缀和
colSum[i] += matrix[i][right]
# 在left,right为边界下的矩阵中,前缀和colSum的最大值
startX, endX, maxAreaCur= self.getMax(colSum)
if maxAreaCur > maxArea:
# left是起点y轴坐标,right是终点y轴坐标
res = [startX, left, endX, right]
maxArea = maxAreaCur
return res
#这一列中,找最大值,同时记录起点,终点
#因为传进来的是列的前缀和,所以返回的起点、终点代表的是行坐标
def getMax(self, nums):
n = len(nums)
maxVal, curSum = nums[0], nums[0] #初始化最大值
startIndex, end, start = 0, 0, 0 #初始化临时起点,起点,终点
for i in range(1,n):
if curSum<0: #前缀和小于0了,前面就不要了,从当前开始
curSum = nums[i]
# 前面的前缀和小于0了,需要重置起点,从当前开始才有可能成为最大值
startIndex = i
else:
curSum = curSum + nums[i]
if curSum > maxVal:
maxVal = curSum
# 记录下前面的起点,默认0,或者是curSum<0后,重新更新的起点
start = startIndex
end = i #终点是当前坐标
return start, end, maxVal #起点,终点,最大前缀和(最大面积)
363. 矩形区域不超过 K 的最大数值和-困难
LeetCode链接

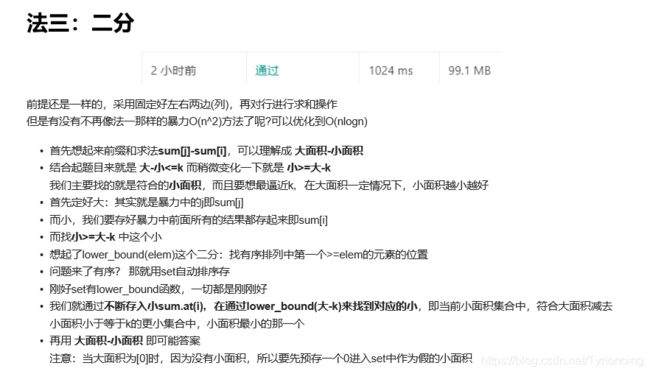
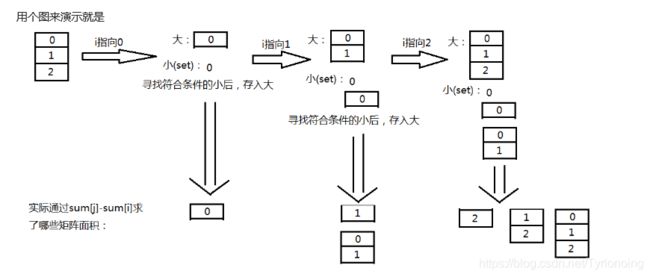
- 大佬代码实现:
- 子序和最大 - 子序和最接近某个值(抄最大子矩阵)
class Solution:
def maxSumSubmatrix(self, matrix: List[List[int]], k: int) -> int:
# 类型:1)单数组(矩阵); 2)dp=m; 3)最大和:dp=max(nums[i],nums[i]+dp[i-1])
# 思路: 返回左上角、右下角坐标: 找到对应的行、列 即可;
# 二维DP转换为一维DP;
import bisect
N, M = len(matrix), len(matrix[0])
# maxSum: 记录最大子矩阵和; i~j行;
maxSum = float('-inf')
# bestC1, bestR1:暂时记录左上角坐标:矩阵起始位置;
bestC1, bestR1 = 0, 0
ans = [0, 0, 0, 0] # 最终结果坐标;
res = float('-inf')
# 遍历扫描1: 子矩阵的上边界: 第i行,按行扫描;
for i in range(N):
# 每次上边界更新,重新清空b,记录当前行起始每列的和;
# 数组b: 对应最大子序和中的给定数组,
# 记录第i行到第j行构成的矩阵对应的每一列之和; 二维变一维;
b = [0 for _ in range(M)]
# 遍历扫描2:子矩阵的下边界:第j行,按行扫描; 不断增加子矩阵的高;
for j in range(i, N):
# 此时:第i行~第j行构成矩阵,再在 列维度求最大和(子矩阵)即可;
# sums:相当于dp[i]:记录以nums[i]结尾最大子序和;
sums = 0
# 遍历扫描3: 计算第i行 到 第j行 b数组的值l
for t in range(M):
b[t] = b[t] + matrix[j][t]
# 在left,right为边界下的矩阵,求不超过K的最大数值和; 前缀和+二分查找;
arr = [0]
cur = 0
for tmp in b:
cur += tmp
# 二分法
loc = bisect.bisect_left(arr, cur - k)
if loc < len(arr):
res = max(cur - arr[loc], res)
# 把累加和加入
bisect.insort(arr, cur)
return res
85. 最大矩形-困难
LeetCode链接

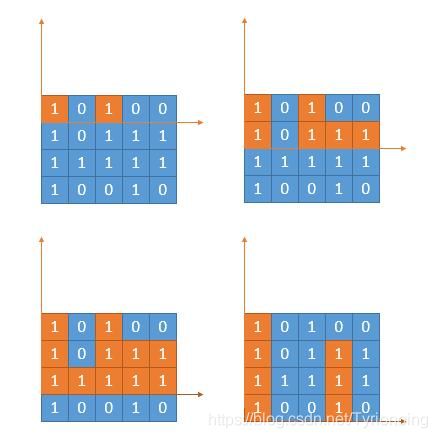
- 仿照84题的做法, 84题思路同样截图。
class Solution:
def maximalRectangle(self, matrix: List[List[str]]) -> int:
# 使用84题的思路做; 遍历每一层记录到顶点的高;
if not matrix or not matrix[0]:
return 0
rows = len(matrix)
cols = len(matrix[0])
# heights: 记录当前行为坐标的 柱状图高度;
heights = [0] * (cols+2)
res = 0
for row in range(rows):
# 类似84题使用单调栈的思路;
stack = []
# 计算当前行的 heights操作;
for col in range(cols):
if matrix[row][col] == '1':
# [0] + height + [0]
heights[col+1] += 1
else:
# 如果后续间断置为0
heights[col+1] = 0
# 计算柱状图的最大面积;
for col in range(cols+2):
# 需要判断stack是否为空; 可以设置哨兵;
while stack and heights[col] < heights[stack[-1]]:
tmp = stack.pop()
res = max(res, (col-stack[-1]-1)*heights[tmp])
stack.append(col)
return res
⭐⭐⭐单字符串补充×区间型DP
5-最长回文子串-中等
LeetCode链接
参考* 中心扩散法-经典面试题:最长回文子串
5. 最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。
示例 2:
输入: "cbbd"
输出: "bb"
参考* ⭐动态规划、中心扩散、Manacher 算法
- 方法二:动态规划
动态规划』问题的思考路径,供大家参考。
特别说明:
- 以下「动态规划」的解释只帮助大家了解「动态规划」问题的基本思想;
- 「动态规划」问题可以难到非常难,在学习的时候建议不要钻到特别难的问题中去;
- 掌握经典的动态规划问题的解法,理解状态的定义的由来、会列出状态转移方程;
- 然后再配合适当难度的问题的练习;
- 有时间和感兴趣的话可以做一些不太常见的类型的问题,拓宽视野;
1、思考状态(重点)
- 状态的定义,先尝试「题目问什么,就把什么设置为状态」;
- 然后思考「状态如何转移」,如果「状态转移方程」不容易得到,尝试修改定义,目的依然是为了方便得到「状态转移方程」。
状态转移方程」是原始问题的不同规模的子问题的联系。即大问题的最优解如何由小问题的最优解得到。
2、思考状态转移方程(核心、难点)
- 状态转移方程是非常重要的,是动态规划的核心,也是难点;
- 常见的推导技巧是:分类讨论。即:对状态空间进行分类;
- 归纳「状态转移方程」是一个很灵活的事情,通常是具体问题具体分析;
- 除了掌握经典的动态规划问题以外,还需要多做题;
- 如果是针对面试,请自行把握难度。掌握常见问题的动态规划解法,理解动态规划解决问题,是从一个小规模问题出发,逐步得到大问题的解,并记录中间过程;
- 「动态规划」方法依然是「空间换时间」思想的体现,常见的解决问题的过程很像在「填表」。
3、思考初始化
初始化是非常重要的,一步错,步步错。初始化状态一定要设置对,才可能得到正确的结果。
- 角度 1:直接从状态的语义出发;
- 角度 2:如果状态的语义不好思考,就考虑「状态转移方程」的边界需要什么样初始化的条件;
- 角度 3:从「状态转移方程」方程的下标看是否需要多设置一行、一列表示「哨兵」(sentinel),这样可以避免一些特殊情况的讨论。
4、思考输出
有些时候是最后一个状态,有些时候可能会综合之前所有计算过的状态。
5、思考优化空间(也可以叫做表格复用)
- 「优化空间」会使得代码难于理解,且是的「状态」丢失原来的语义,初学的时候可以不一步到位。先把代码写正确是更重要;
- 「优化空间」在有一种情况下是很有必要的,那就是状态空间非常庞大的时候(处理海量数据),此时空间不够用,就必须「优化空间」;
- 非常经典的「优化空间」的典型问题是「0-1 背包」问题和「完全背包」问题。
这道题比较烦人的是判断回文子串。因此需要一种能够快速判断原字符串的所有子串是否是回文子串的方法,于是想到了「动态规划」。
「动态规划」的一个关键的步骤是想清楚「状态如何转移」。事实上,「回文」天然具有「状态转移」性质。
- 一个回文去掉两头以后,剩下的部分依然是回文(这里暂不讨论边界情况);
依然从回文串的定义展开讨论:
- 如果一个字符串的头尾两个字符都不相等,那么这个字符串一定不是回文串;
- 如果一个字符串的头尾两个字符相等,才有必要继续判断下去;
- 如果里面的子串是回文,整体就是回文串;
- 如果里面的子串不是回文串,整体就不是回文串。
即:在头尾字符相等的情况下,里面子串的回文性质据定了整个子串的回文性质,这就是状态转移。因此可以把「状态」定义为原字符串的一个子串是否为回文子串。
第 1 步:定义状态
dp[i][j] 表示子串 s[i…j] 是否为回文子串, 这里子串 s[i…j] 定义为 左闭右闭区间, 可以取到 s[i] 和 s[j]。
第二步:思考状态转移方程
在这一步分类讨论(根据头尾字符是否相等),根据上面的分析得到:
dp[i][j] = dp[i+1][j-1] if s[i] == s[j]
说明:
- 动态规划 事实上是在填一张二维表格,由于构成子串,因此 i 和 j 的关系是 i <= j,因此,只需要填这张表格对角线以上的部分。
- 看到 dp[i+1][j-1] 就得考虑边界问题情况。
边界条件是: 表达式 [i+1, j-1] 不构成区间,即 长度严格小于2, 即 j-1 - (i+1) + 1 < 2,整理得 j-i < 3。
这个结论很显然: j -i < 3等价于 j -i + 1 < 4, 即当子串 s[i…j] 的长度等于2或者等于3的时候,其实只需要判断一下头尾2个字符是否相等就可以直接下结论了。
- 如果子串 s[i + 1…j - 1] 只有 1 个字符,即去掉两头,剩下中间部分只有 11 个字符,显然是回文;
- 如果子串 s[i + 1…j - 1] 为空串,那么子串 s[i, j] 一定是回文子串。
因此,在 s[i] == s[j] 成立和 j - i < 3 的前提下,直接可以下结论,dp[i][j] = true,否则才执行状态转移。
第 3 步:考虑初始化
初始化的时候,单个字符一定是回文串,因此把对角线先初始化为 true,即 dp[i][i] = true 。
事实上,初始化的部分都可以省去。因为只有一个字符的时候一定是回文,dp[i][i] 根本不会被其它状态值所参考。
第 4 步:考虑输出
只要一得到 dp[i][j] = true,就记录子串的长度和起始位置,没有必要截取,这是因为截取字符串也要消耗性能,记录此时的回文子串的「起始位置」和「回文长度」即可。
第 5 步:考虑优化空间
因为在填表的过程中,只参考了左下方的数值。事实上可以优化,但是增加了代码编写和理解的难度,丢失可读和可解释性。在这里不优化空间。
注意事项:总是先得到小子串的回文判定,然后大子串才能参考小子串的判断结果,即填表顺序很重要。
大家能够可以自己动手,画一下表格,相信会对「动态规划」作为一种「表格法」有一个更好的理解。
以字符串 ‘babad’ 为例:
从上到下写,或者从下到上写,都是可以的。
下面分别展示了错误的填表顺序和正确的填表顺序,以便大家理解动态规划要满足「无后效性」的意思。
说明:表格中的数字表示「填表顺序」,从 1 开始。表格外的箭头和数字也表示「填表顺序」,与表格中的数字含义一致。


动态规划:
* 时间复杂度: O( N 2 N^2 N2)
* 空间复杂度:O( N 2 N^2 N2)
class Solution:
# 填表顺序选择上图: 4, 截图图4; 截图DP+中心扩散法;
def longestPalindrome(self, s: str) -> str:
# 时间复杂度: O(n^2)
# 空间复杂度: O(n^2)
# 类型: 1)单字符串; 2)dp=m*m; 3)根据头尾字符是否相等:dp[i][j]=dp[i+1][j-1]
m = len(s)
if m<2:
return s
# 步骤1: dp定义/初始化:dp[i][j]:字符串s[i]~s[j]是否是回文串;
dp = [[False for _ in range(m)] for _ in range(m)]
maxLen = 1 # 记录最长回文串长度;
start = 0 # 记录最长回文串的起始下标;
# 对角线初始化:
for i in range(m):
dp[i][i] = True
# 步骤4: 边界条件;
# 步骤2:遍历填表; 调表顺序:图4: 列:从0~m; 行:j-1~0;
for j in range(1, m):
for i in range(j-1, -1, -1):
# 步骤3: 转移方程;
if s[i] == s[j]:
if j-i < 3:
dp[i][j] = True
else:
dp[i][j] = dp[i+1][j-1]
# 可以删除;
else:
dp[i][j] =False
# 中间结果比较;
if dp[i][j]:
curLen = j - i + 1
if curLen > maxLen:
maxLen = curLen
start = i
# 步骤5:返回;
return s[start:start+maxLen]
- 方法三:中心扩散法
暴力法采用双指针两边夹,验证是否是回文子串。
除了枚举字符串的左右边界以外,比较容易想到的是枚举可能出现的回文子串的“中心位置”,从“中心位置”尝试尽可能扩散出去,得到一个回文串。
因此中心扩散法的思路是:遍历每一个索引,以这个索引为中心,利用“回文串”中心对称的特点,往两边扩散,看最多能扩散多远。
枚举“中心位置”时间复杂度为 O ( N ) O(N) O(N),从“中心位置”扩散得到“回文子串”的时间复杂度为 O ( N ) O(N) O(N),因此时间复杂度可以降到 O ( N 2 ) O(N^2) O(N2)。
在这里要注意一个细节:回文串在长度为奇数和偶数的时候,“回文中心”的形式是不一样的。
- 奇数回文串的“中心”是一个具体的字符,例如:回文串 “aba” 的中心是字符 “b”;
- 偶数回文串的“中心”是位于中间的两个字符的“空隙”,例如:回文串串 “abba” 的中心是两个 “b” 中间的那个“空隙”。

我们看一下一个字符串可能的回文子串的中心在哪里?
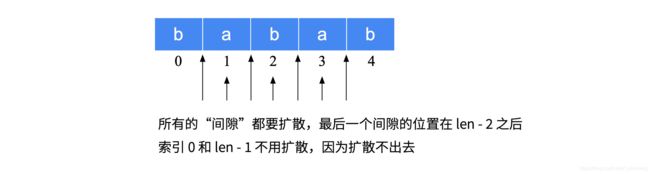
我们可以设计一个方法,兼容以上两种情况:
1、如果传入重合的索引编码,进行中心扩散,此时得到的回文子串的长度是奇数;
2、如果传入相邻的索引编码,进行中心扩散,此时得到的回文子串的长度是偶数。
中心扩散算法
* 时间复杂度:O( N 2 N^2 N2)
* 空间复杂度:O( 1 1 1)
class Solution:
# 时间复杂度: O(N^2)
# 空间复杂度: O(1)
def longestPalindrome(self, s:str) -> str:
size = len(s)
if size < 2:
restrn s
# 至少是1
max_len = 1
res = s[0]
for i in range(size):
palindrome_odd, odd_len = self._center_spread(s, size, i, i)
palindrome_even, even_len = self._center_spread(s, size, i, i+1)
# 当前找到的最长回文子串
cur_max_sub = palindrome if odd_len >= even_len else palindrome_even
if len(cur_max_sub) > max_len:
max_len = len(cur_max_sub)
res = cur_max_sub
return res
def _crnter_spread(self, s, size, left, right):
'''
left = right 的时候, 此时回文中心是一个字符,回文串的长度是奇数
right = left + 1的时候,此时的回文中心是一个空隙,回文串的长度是偶数
'''
while left >= 0 and right< size and s[left] == s[right]:
left -= 1
right += 1
return s[left+1:right], right-left-1
516. 最长回文子序列-中等
LeetCode链接

参考*子序列解题模板:最长回文子序列


516. 最长回文子序列
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。
示例 1:
输入:
"bbbab"
输出:
4
一个可能的最长回文子序列为 "bbbb"。
示例 2:
输入:
"cbbd"
输出:
2
一个可能的最长回文子序列为 "bb"。
- python 代码
class Solution:
def longestPalindromeSubseq(self, s: str) -> int:
# 思路: 动态规划
# dp[i][j]: s[i] 到 s[j] 为止的最长子序列长度
strLen = len(s)
# 初始化全部为0, 左下边可以处理
dp = [[0]*strLen for _ in range(strLen)]
# 对角线初始化为1
for i in range(strLen):
dp[i][i] = 1
# 步骤2:遍历填表; 调表顺序:图4: 列:从0~m; 行:j-1~0;
for j in range(1, strLen):
for i in range(j-1, -1, -1):
# 状态转移方程
if s[i] == s[j]:
dp[i][j] = dp[i+1][j-1] + 2
else:
dp[i][j] = max(dp[i+1][j], dp[i][j-1])
return dp[0][strLen-1]
312. 戳气球-困难
LeetCode链接

参考* 经典动态规划:戳气球问题
class Solution:
def maxCoins(self, nums: List[int]) -> int:
n = len(nums)
# 添加左右两侧的虚拟气球;
points = [1] + nums + [1]
# dp[i][j]: 开区间(i, j): 戳破气球 i 和 气球 j 之间(开区间, 不包括 i 和 j)的
# 所有气球,可以获得的最高分数为 x;
# 初始化为全0
dp = [[0 for _ in range(n+2)] for _ in range(n+2)]
# 状态: 位置i 和 位置j
# 选择: i~j中 戳皮的气球k;
# 遍历填表;
# 顺序思考: 状态穷举, 最重要的一点就是: 状态转移所依赖的状态必须被提前计算出来;
# dp[i][j]所依赖的状态是 dp[i][k] 和 dp[k][j], 则必须保证: 计算dp[i][j] 时候:
# dp[i][k] 和 dp[k][j] 都已经被计算出来;
# 具体计算顺序: 可以根据 base case 和 dp[0][n+1]进行转移推导;
for i in range(n+1, -1, -1): # 从下往上
for j in range(i+1, n+2): # 从左到右
for k in range(i+1, j):
dp[i][j] = max(
dp[i][j],
dp[i][k] + dp[k][j] + points[i]*points[k]*points[j]
)
return dp[0][n+1]
87. 扰乱字符串-困难-不懂
LeetCode链接


- powcai大佬递归思路:

class Solution:
def isScramble(self, s1: str, s2: str) -> bool:
if len(s1) != len(s2):
return False
if s1 == s2:
return True
if sorted(s1) != sorted(s2):
return False
for i in range(1, len(s1)):
S1, S2 = s1[:i], s1[i:]
T1, T2 = s2[:i], s2[i:]
if self.isScramble(S1, T1) and self.isScramble(S2, T2):
return True
T1, T2 = s2[:-i],s2[-i:] # S1、S2不变,更新T1、T2
if self.isScramble(S1, T2) and self.isScramble(S2, T1):
return True
return False
- 动态规划


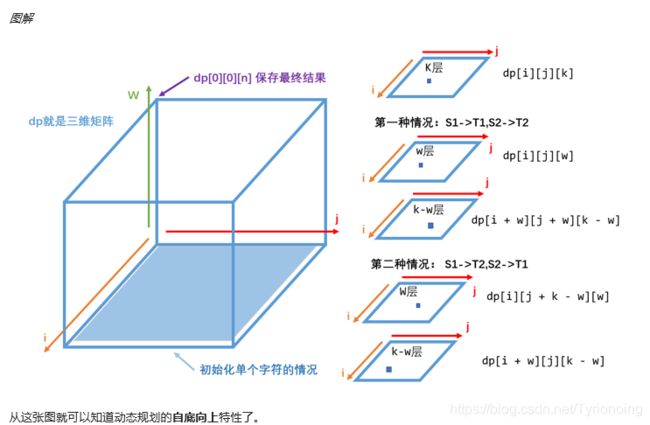
class Solution:
def isScramble(self, s1, s2):
S_len = len(s1)
T_len = len(s2)
# 一些特判
if S_len != T_len: return False
if s1 == s2: return True
if sorted(s1) != sorted(s2): return False
# 初始化 dp 三维数组dp[i][j][k]
# i为0~S_len共S_len+1个, j为0~S_len-1共S_len个, k为1~S_len+1共S_len个
dp = [ [ [False]*(S_len+1) for _ in range(S_len) ] for _ in range(S_len) ]
# 初始化单个字符的情况
for i in range(S_len):
for j in range(T_len):
dp[i][j][1] = s1[i] == s2[j]
# 前面排除了s1和s2为单个字符的情况,那么我们就要划分区间了,k从2到S_len,也就是划分为s1[:k]和s1[k:]
for k in range(2, S_len + 1): # 枚举区间长度2~S_len
# 枚举S中的起点位置 i,也就是在s1中枚举i的位置,因为后面会出现i+w的情况,而w最大就是k,就会有i+k的情况,所以i的取值范围就是0~S_len-k。
for i in range(S_len - k + 1):
# 枚举T中的起点位置 j
for j in range(T_len - k + 1):
# 枚举划分位置 w
for w in range(1, k):
# 第一种情况:S1->T1,S2->T2
if dp[i][j][w] and dp[i + w][j + w][k - w]:
dp[i][j][k] = True
break
# 第二种情况:S1->T2,S2->T1
# S1起点i,T2起点j + 前面那段长度 k-w,S2起点i+前面长度w,T1起点为j。
if dp[i][j + k - w][w] and dp[i + w][j][k - w]:
dp[i][j][k] = True
break
return dp[0][0][S_len]
131. 分割回文串
LeetCode链接

参考*回溯、优化(使用动态规划预处理数组)
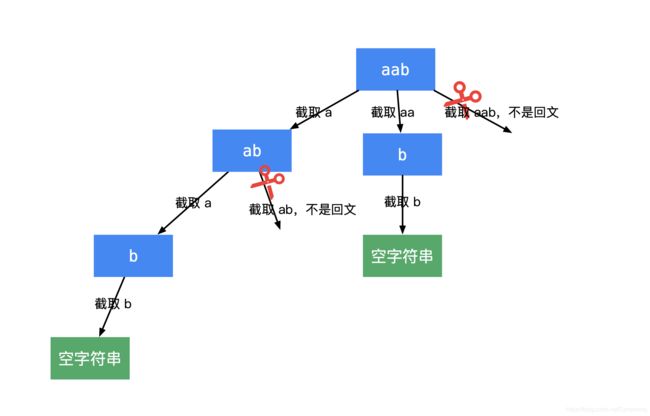

- 完全回溯实现(先截图这个,完了再截图DP优化)
- 时间复杂度: O ( N 3 ) O(N^3) O(N3)
class Solution:
def partition(self, s: str) -> List[List[str]]:
# 判断字符串是不是回文串;
# 双指针思想遍历; 最差时间复杂度: O(N)
def check_is_palindrome(left, right):
while left < right:
if s[left] != s[right]:
return False
left = left + 1
right = right - 1
return True
# 回溯操作: 递归判断符合要求的路径/选择
def dfs(start, path):
if start == length:
res.append(path[:])
for i in range(start, length):
if not check_is_palindrome(start, i):
continue
# 做选择
path.append(s[start:i + 1])
# 切完第一个字符, 进一步递归;
dfs(i + 1, path)
# 插销选择,回溯;
path.pop()
res = []
length = len(s)
if length == 0:
return res
path = []
dfs(0, path)
return res
- 回溯+动态规划
- 时间复杂度: O ( N 2 ) O(N^2) O(N2)
- 空间复杂度: O ( N 2 ) O(N^2) O(N2)
class Solution:
def partition(self, s: str) -> List[List[str]]:
# 判断字符串是不是回文串;
# 时间复杂度:O(N^2)
def longestPalindrome(s):
# 动态规划: dp[i][j] : 从位置i 到 j是否是回文串
size = len(s)
if size < 2:
return s
# 初始化二维数组: dp[i][j]:字符串i-j 是否是回文串
dp = [[False]*size for _ in range(size)]
# 初始条件设置
for i in range(size):
dp[i][i] = True
maxLen, start = 1, 0
# 遍历判断、填表: 状态、选择
# 考虑遍历顺序: 从上到下, 从左往右
for j in range(1, size):
for i in range(j):
if s[i] == s[j]:
# 这部分自己肯定想不到的
# 例子: cbba 初始化时候: 左下方初始化值设置为: False,会判断错误
if j - i < 3:
dp[i][j] = True
else:
dp[i][j] = dp[i+1][j-1]
else:
dp[i][j] = False
return dp
# 回溯操作: 递归判断符合要求的路径/选择
def dfs(start, path):
if start == length:
res.append(path[:])
for i in range(start, length):
print(start, i, dp[start][i])
if not dp[start][i]:
continue
# 做选择
path.append(s[start:i + 1])
# 切完第一个字符, 进一步递归;
dfs(i + 1, path)
# 插销选择,回溯;
path.pop()
res = []
length = len(s)
if length == 0:
return res
path = []
dp = longestPalindrome(s)
dfs(0, path)
return res
132. 分割回文串 II
LeetCode链接

-
思路1: 131回文串判断选择最小-超时
-
直接动态规划思路:
-
动态规划-weiwei

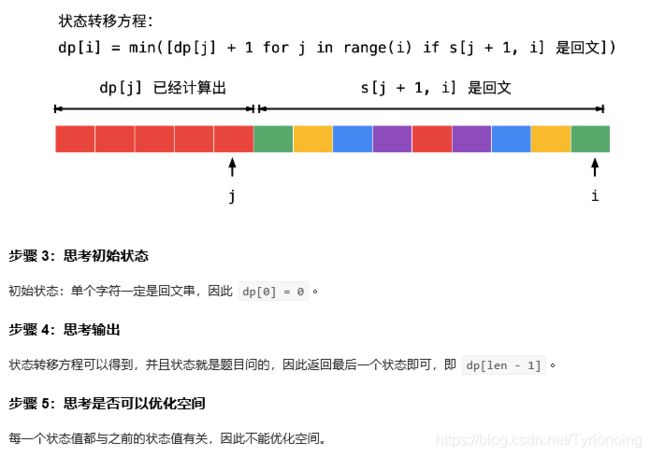
-
动态规划-python
-
时间复杂度: O ( N 2 ) O(N^2) O(N2)
-
空间复杂度: O ( n 2 ) O(n^2) O(n2)
class Solution:
def minCut(self, s: str) -> List[List[str]]:
# 思路: 按照问题定义dp[] 含义;
# dp[i]: 表示以 字符s[i]结尾的字符串s[0]--s[i]的最小分割次数;
# 类似于最长上升子序列 或者 最大子序和思想;
# 求最长回文子串的代码;
# 返回dp矩阵:dp[i][j]: 代表:s[i]~s[j]是不是回文串
def isPalindrome(s):
size = len(s)
# 初始化w二维数组: dp[i][j]:字符串i~j 是否为 回文串;
dp = [[False for _ in range(size)] for _ in range(size)]
# 初始化条件设置:对角线设置为1
for i in range(size):
dp[i][i] = True
# 遍历填表
for j in range(1, size):
for i in range(j):
if s[i] == s[j]:
if j-i < 3:
dp[i][j] = True
else:
dp[i][j] = dp[i+1][j-1]
else:
dp[i][j] = False
return dp
dp2 = isPalindrome(s)
length = len(s)
if length < 2:
return 0
dp1 = [i for i in range(len(s))]
# 遍历填表: 填写每个位置s[i]结尾对应的最小分割次数;
for i in range(len(s)):
# 剪枝;
# if s[0]~s[i]是回文串:
if dp2[0][i]:
dp1[i] = 0
continue
# 穷举0-i 所有可能的分割点; 1) 分割开以后 0-j 可分割 2)j+1~i回文串;
for j in range(i):
# if s[i+1]~s[i] 是回文串:
if dp2[j+1][i]:
dp1[i] = min(dp1[j] + 1, dp1[i])
return dp1[-1]
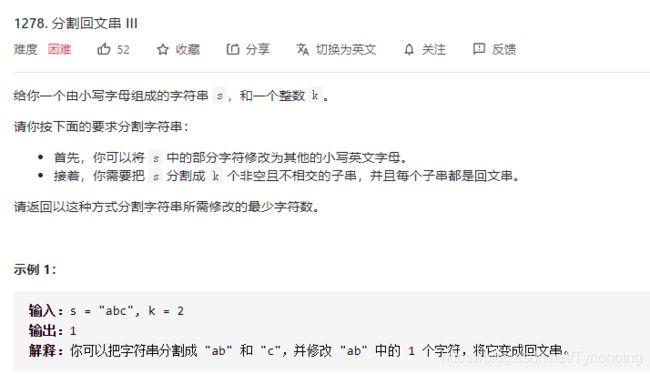
1278. 分割回文串 III-困难
LeetCode链接
⭐⭐⭐单数组/字符串×划分型
139. 单词拆分-中等
LeetCode链接

参考* 【手画图解】3种方法及优化:DFS、BFS、动态规划

- 划分型动态规划-python
- 时间复杂度: O( n 2 n^2 n2)
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
# 预处理: wordDita放入hash表中;
wordSet = {word for word in wordDict}
sLen = len(s)
# dp[i]: 以s[i] 结尾的s[:i+1]是否满足可拆分
dp = [False for _ in range(sLen)]
for i in range(sLen):
# 至关重要: True的初始化操作;
# 如果整个单词在wordSet则没必要继续做单词分割;
if s[:i+1] in wordSet:
dp[i] = True
continue
for j in range(i):
if dp[j] and s[j+1:i+1] in wordSet:
dp[i] = True
# 针对i, 如果已经得到则循环不必继续;
break
return dp[-1]
DFS-不会
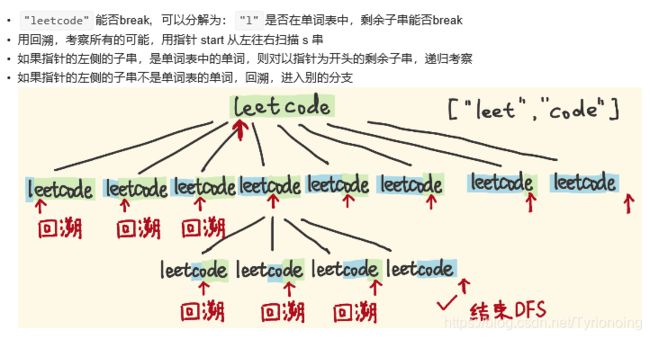
140. 单词拆分 II-困难
参考* “动态规划 + 回溯”求解具体值
思路差不多如下图: 最终返回结果;
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> List[str]:
# 思路: 先使用类似于139思路判断是不是可切分,如果可节分进一步进行回溯查找;
# 回溯思路: 结尾到 进行回溯(标准回溯模板);
def dfs(s, end, wordSet, res, path, dp):
# 如果不用拆分,整个单词就在 wordSet中,直接加入 res, 但是没有return, 仍然要递归;
if s[:end+1] in wordSet:
path.append(s[:end+1])
res.append(' '.join(path[::-1]))
path.pop()
for i in range(end):
if dp[i]:
suffix = s[i+1:end+1]
if suffix in wordSet:
path.append(suffix)
dfs(s, i, wordSet, res, path, dp)
path.pop()
wordSet = {word for word in wordDict}
sLen = len(s)
dp = [False for _ in range(sLen)]
for i in range(sLen):
# 至关重要: 初始化操作;
if s[:i+1] in wordSet:
dp[i] = True
continue
for j in range(i):
if dp[j] and s[j+1:i+1] in wordSet:
dp[i] = True
break
res = []
# 如果有解, 才有必要回溯;
if dp[-1]:
path = []
dfs(s, sLen-1, wordSet, res, path, dp)
return res
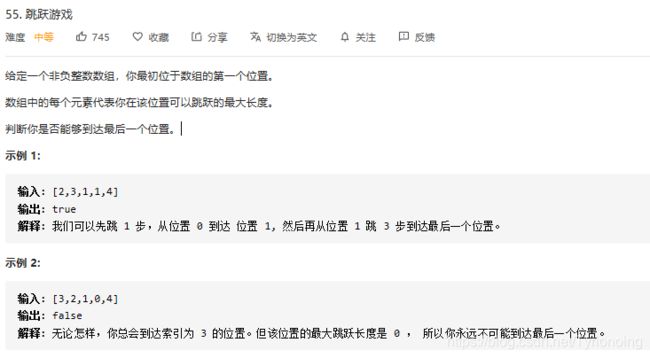
55. 跳跃游戏
LeetCode链接
- 贪心:时间复杂度:O(n)
class Solution:
def canJump(self, nums: List[int]) -> bool:
# 思路: 贪心
if not nums:
return False
if len(nums) == 1:
return True
maxLen = nums[0]
for i in range(len(nums)):
if i <= maxLen:
maxLen = max(maxLen, i+nums[i])
return maxLen >= len(nums)-1
- 动态规划:时间复杂度:O(N^2)
class Solution:
def canJump(self, nums: List[int]) -> bool:
# 思路: 动态规划
if len(nums) == 1:
return True
dp = [False for _ in range(len(nums))]
dp[0] = True
for i in range(1, len(nums)):
for j in range(i):
if dp[j] and (nums[j] + j) >= i:
dp[i] = True
break
return dp[-1]
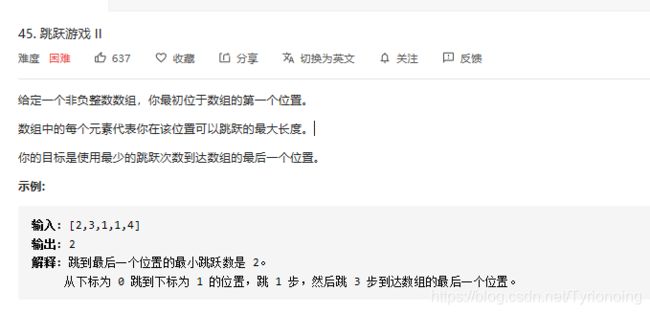
45. 跳跃游戏 II-hard-未作
LeetCode链接
⭐⭐⭐单数组×博弈型
877. 石子游戏-博弈型
LeetCode链接

- python 实现
class Solution:
def stoneGame(self, piles: List[int]) -> bool:
# 思路: 博弈型动态规划
# dp[i][j][0/1]: 从石t堆 i 到 j 先手/后手得到的分数;
n = len(piles)
dp = [[[0,0] for _ in range(n)] for _ in range(n)]
# 初始化
for i in range(n):
dp[i][i][0] = piles[i]
# for j in range(n):
# for i in range(j-1, -1, -1):
for i in range(n-2, -1, -1):
for j in range(i+1, n):
# 不管之前的顺序, 单字符串问题, 都是 字符串内部: 从位置i 到位置j 形成的结果;
left = piles[i] + dp[i+1][j][1]
right = piles[j] + dp[i][j-1][1]
if left > right:
dp[i][j][0] = left
dp[i][j][1] = dp[i+1][j][0]
else:
dp[i][j][0] = right
dp[i][j][1] = dp[i][j-1][0]
return dp[0][-1][0] > dp[0][-1][1]
[1140. 石子游戏 II-中等]
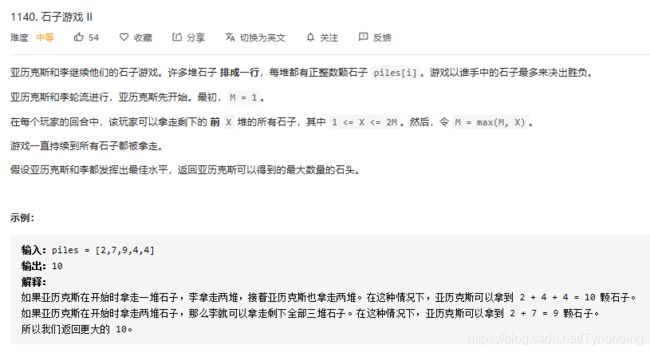
难哭了!!! 和上一题对比: 1: 状态的选择是 i~j ? 还是前 i 个?,还是剩余j~n?
本质上是对于: 最佳水平理解不清楚; 上题的的聪明: 选择left, right 中的最大的结果(后向选择最大的;);
本题想不清楚怎样才算做聪明: 1) 剩下石头里面结果最大?
看了递归思路: 确实有点反向求最大的意思,保证最后的结果最大,每一步都保证剩下里面取最大;

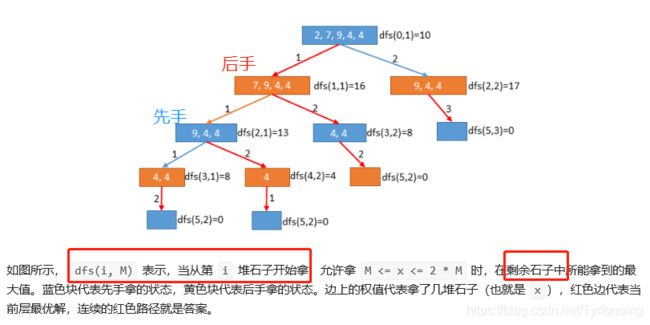
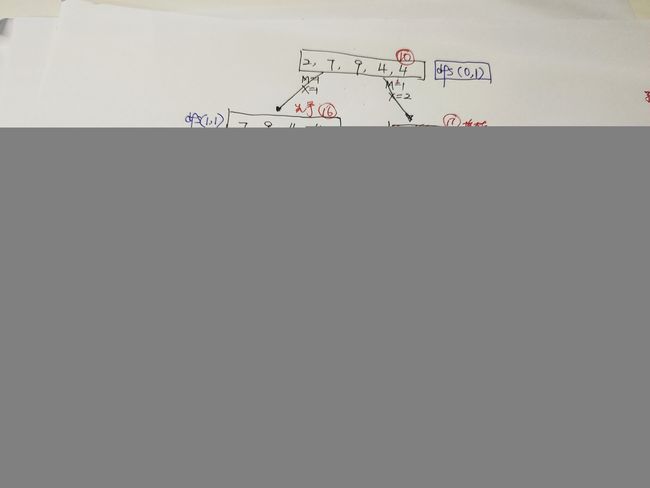
- 记忆化递归-抄大佬结果;
class Solution:
def stoneGameII(self, piles: List[int]) -> int:
# 数据规模与记忆化
n, memo = len(piles), dict()
# s[i]: 表示第i堆石子到最后一堆石子的总石子数;
# n+1: 为了好计算; 后缀和, 后 i-n+1向的和;
# 其中所有的取值操作都通过 后缀和实现;
s = [0] * (n+1)
for i in range(n-1, -1, -1):
s[i] = s[i+1] + piles[i]
# dfs(i, M): 表示从第i堆石子i开始取, 在M的条件下, 取到的最优值;
def dfs(i, M):
# 如果已经搜索过, 直接返回;
if (i, M) in memo:
return memo[(i, M)]
# 溢出拿不到任何石子;
if i>= n:
return 0
# 剪枝操作: 如果剩余堆数小于等于2M, 那么可以全部拿走;
if i + 2 * M >= n:
return s[i]
# 枚举拿x堆的最优值;
best = 0
for x in range(1, 2 * M + 1):
# 剩余石子减去对方最优策略:
# 每一步对于该情况下的先手而言: 计算自己取得的最大数目; 角色不停的发生转换;
# 这块不好理解: 自己选择1~2M+1时候,完了剩下让对方选: 对方肯定会在剩下的石子里面挑选最大值;
# 所以根据自己的1~2M选择,分别计算对方的最最优值,然后求自己的最大值;
best = max(best, s[i] - dfs(i+x, max(x, M)))
# 记忆化: 我感觉记忆化起的作用并不大;
memo[(i, M)] = best
return best
return dfs(0, 1)
- 动态规划方法
1406. 石子游戏 III-困难
链接

- 递归思路: 完全抄上一题答案,注意: 数组中元素可能为负数,初始化best = float(’-inf’)
class Solution:
def stoneGameIII(self, piles: List[int]) -> int:
# 数据规模与记忆化
n, memo = len(piles), dict()
# s[i]: 表示第i堆石子到最后一堆石子的总石子数;
# n+1: 为了好计算; 后缀和, 后 i-n+1向的和;
# 其中所有的取值操作都通过 后缀和实现;
s = [0] * (n+1)
for i in range(n-1, -1, -1):
s[i] = s[i+1] + piles[i]
# dfs(i, M): 表示从第i堆石子i开始取, 在M的条件下, 取到的最优值;
def dfs(i):
# 如果已经搜索过, 直接返回;
if i in memo:
return memo[i]
if i >= n:
return 0
# 枚举拿x堆的最优值;
best = float('-inf')
for x in range(1, 4):
# 剩余石子减去对方最优策略:
# 每一步对于该情况下的先手而言: 计算自己取得的最大数目; 角色不停的发生转换;
# 这块不好理解: 自己选择1~2M+1时候,完了剩下让对方选: 对方肯定会在剩下的石子里面挑选最大值;
# 所以根据自己的1~2M选择,分别计算对方的最最优值,然后求自己的最大值;
best = max(best, s[i] - dfs(i+x))
# 记忆化: 我感觉记忆化起的作用并不大;
memo[i] = best
return best
alice = dfs(0)
bob = sum(piles) - alice
if alice > bob:
return 'Alice'
elif alice < bob:
return 'Bob'
else:
return 'Tie'
- 动态规划



- 思路: 从最后一步倒着算: 这样就是信息透明的平等博弈;
- python实现:
class Solution:
def stoneGameIII(self, piles: List[int]) -> str:
sums = 0
# [0]*3: 防止i+j发生数组越界;
dp = [float('-inf')]*(len(piles)) + [0]*3
for i in range(len(piles)-1, -1, -1):
sums = sums + piles[i]
for j in range(1, 4):
dp[i] = max(dp[i], sums - dp[i+j])
alice = dp[0]
bob = sum(piles) - alice
if alice > bob:
return 'Alice'
elif alice < bob:
return 'Bob'
else:
return 'Tie'
1510. 石子游戏 IV-困难

- 博弈型动态规划思路:
class Solution:
def winnerSquareGame(self, n: int) -> bool:
# 思路: 博弈型动态规划: 还是先手、后手聪明条件的理解, 每个时候先手都会选择使得自己必胜的条件;
# dp[i]: 第i堆石子条件下先手获胜的情形;
dp = [False] * (n+1)
for i in range(1, n+1):
k = 1
while k*k <= i:
# i-k*k 肯定合法;
if not dp[i-k*k]:
dp[i] = True
break
k = k+1
return dp[n]
⭐⭐⭐完全背包
377. 组合总和 Ⅳ-同coinChange2
LeetCode链接

class Solution:
def combinationSum4(self, nums: List[int], target: int) -> int:
# 题目求组合, 本质是求 排列;
# 类似于 coinChange; 排列数目;
if not nums or not target:
return 0
dp = [0 for _ in range(target+1)]
dp[0] = 1
for i in range(1, target+1):
for num in nums:
if i >= num:
dp[i] = dp[i] + dp[i-num]
return dp[-1]
322. 零钱兑换-1-中等
LeetCode链接
- 零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例 1:输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
示例 2:输入: coins = [2], amount = 3
输出: -1
# 这是一个排列问题,考虑了顺序;
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
''''
# 思路: 最少硬币个数--》 动态规划
dp = [float('inf')] * (amount+1)
dp[0] = 0
for i in range(1, amount+1):
for j in range(len(coins)):
if i >= coins[j]:
dp[i] = min(dp[i], dp[i-coins[j]]+1) # 要不要当前硬币; 硬币可以出现多次;
return -1 if dp[-1] == float('inf') else dp[-1]
'''
'''
# 思路1:带备忘录的递归做法
memo = dict()
memo[0] = 0
def memoDp(amount):
if amount in memo:
return memo[amount]
# 根据题目: 不符合条件的情况返回 -1
if amount < 0:
return -1
res = float('inf')
for coin in coins:
subProblem = memoDp(amount - coin)
if subProblem == -1:
continue
res = min(res, 1 + subProblem)
# 计入备忘录
memo[amount] = res if res != float('inf') else -1
return memo[amount]
return memoDp(amount)
'''
# 解法2:动态规划:自底向上的解法
dp = [float('inf')] * (amount + 1)
dp[0] = 0
for num in range(1, amount + 1):
for coin in coins:
if num >= coin:
dp[num] = min(dp[num], 1 + dp[num - coin])
return -1 if dp[-1] == float('inf') else dp[-1]
# 解法3
# 完全背包的思想: coin 和 count顺序互换了一下;
# dp[i]: 凑成金额i 最少的 硬币数目
for coin in coins:
for i in range(1, amount+1):
if i >= coin:
dp[i] = min(dp[i], dp[i-coin]+1)
return dp[-1] if dp[-1] != float('inf') else -1
279. 完全平方数-中等
LeetCode链接
- python 实现: 类似coinchange
class Solution:
def numSquares(self, n: int) -> int:
# 思路: coinChange思路: 先找到 coin再进一步进行选择;
if not n:
return 0
dp = [float('inf')] * (n+1)
dp[0] = 0
coins = list(set([ (int(i**0.5)**2) for i in range(1, n+1)]))
for i in range(1, n+1):
for coin in coins:
if i >= coin:
dp[i] = min(dp[i], dp[i-coin]+1)
return dp[n]
518. 零钱兑换 II-中等
LeetCode链接
参考 经典动态规划:完全背包问题
518. 零钱兑换 II难度中等168给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
示例 1:
输入: amount = 5, coins = [1, 2, 5]
输出: 4
解释: 有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
示例 2:输入: amount = 3, coins = [2]
输出: 0
解释: 只用面额2的硬币不能凑成总金额3。
示例 3:输入: amount = 10, coins = [10]
输出: 1
- pytnon 组合数目
class Solution:
def change(self, amount: int, coins: List[int]) -> int:
# 思路: 由于求组合数目, 故转移方程、数组含义会发生变化;
# 不需要再求:最少组合,也就不需要:设置 inf, 以及求 min()
# 凑成金额 amount 的组合数目
dp = [0] * (amount + 1)
dp[0] = 1 # 待验证
for i in range(len(coins)):
for j in range(1, amount+1):
if j >= coins[i]:
dp[j] = dp[j] + dp[j - coins[i]]
return dp[amount]
- python排列数目
class Solution:
def change(self, amount: int, coins: List[int]) -> int:
# dp[i] 凑成i硬币的方式数目;
dp = [0 for _ in range(amount+1)]
dp[0] = 1
for i in range(1, amount+1):
for coin in coins:
if i >= coin:
dp[i] = dp[i] + dp[i-coin]
return dp[-1]
⭐⭐⭐0-1背包问题
416-分割等和子集
LeetCode链接
参考 笔记-经典动态规划:0-1背包问题的变体
416. 分割等和子集难度中等297给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。注意:每个数组中的元素不会超过 100数组的大小不会超过 200示例 1:输入: [1, 5, 11, 5]
输出: true
解释: 数组可以分割成 [1, 5, 5] 和 [11].
示例 2:输入: [1, 2, 3, 5]
输出: false
解释: 数组不能分割成两个元素和相等的子集.
# 需要进一步分析数组的初始化,如果初始化为: len(nums), 则会出现报错;
class Solution:
def canPartition(self, nums: List[int]) -> bool:
# 思路: 可以将此问题转换为 背包问题: 能否用其中的元素凑成 sum/2,如果可以凑出来则满足条件
sums = sum(nums)
if sums % 2 != 0:
return False
sums = int(sums / 2)
# 是否可以使用前i个元素凑成
dp = [[False for _ in range(sums+1)] for _ in range(len(nums)+1)]
# 边界条件: 凑成数字0, 无论前多少数组都可以凑出
for i in range(len(nums)+1):
dp[i][0] = True
'''
# 对于二维dp数组, 不管优先遍历哪个结果都一样, 但是对于一维数组发生变化;
for i in range(1, len(nums)+1): # 前i个数字
for j in range(1, sums+1): # 凑出数字j
if j >= nums[i-1]: # 前i个数字,对应最后下标是 nums[i-1]
dp[i][j] = dp[i-1][j] or dp[i-1][j-nums[i-1]]
else:
dp[i][j] = dp[i-1][j]
return dp[len(nums)][sums]
'''
# 对于二维dp数组, 不管优先遍历哪个结果都一样, 但是对于一维数组发生变化;
for j in range(1, sums+1): # 凑出数字j
for i in range(len(nums)): #
if j >= nums[i]: # 前i个数字,对应最后下标是 nums[i-1]
dp[i][j] = dp[i-1][j] or dp[i-1][j-nums[i]]
else:
dp[i][j] = dp[i-1][j]
return dp[len(nums)-1][sums]
474. 一和零
LeetCode链接

参考 weiwei大佬-动态规划(转换为 0-1 背包问题)
问题理解:
思路:把总共的 0 个 1 的个数视为背包的容量,每一个字符串视为装进背包的物品。这道题就可以使用 0-1 背包问题的思路完成。这里的目标值是能放进背包的字符串的数量。
思路:依然是“一个一个尝试,容量一点一点尝试”,每个物品分类讨论:选与不选。

class Solution:
def findMaxForm(self, strs: List[str], m: int, n: int) -> int:
# 0-1背包问题: dp[i][j]: 前i个物品装重量j的条件下的最大价值;
# 转换: dp[i][j][k]:前i个字符串满足j个0,k个1的条件下的最大字符串数量;
dp = [[[0]*(n+1) for _ in range(m+1)] for _ in range(len(strs)+1)]
for i in range(1, len(strs)+1):
ones = strs[i-1].count('1')
zeros = strs[i-1].count('0')
for j in range(m+1):
for k in range(n+1):
# 这一行必须要,根据定义是前i个字符串,如果当前0-1个数不满足,则保留之前结果;
dp[i][j][k] = dp[i-1][j][k]
if j>=zeros and k>=ones:
dp[i][j][k] = max(dp[i-1][j][k], dp[i-1][j-zeros][k-ones] + 1)
return dp[-1][-1][-1]
- 逆序–

494. 目标和
LeetCode链接

-
和分割等和自己一个模板


-
labuladong-三、动态规划

- 参考代码-powcai:
class Solution:
def findTargetSumWays(self, nums: List[int], S: int) -> int:
target = S + (t:=sum(nums))
if t < S or target < 0 or target % 2: return 0
target //= 2
dp = [0] * (target + 1)
dp[0] = 1
for num in nums:
for i in range(target, num - 1, -1):
if i - num >= 0:
dp[i] += dp[i - num]
return dp[-1]
⭐⭐⭐极小极大值
887. (高楼扔鸡蛋)鸡蛋掉落-困难

参考* ⭐高楼扔鸡蛋–labuladong
- 记忆化递归实现:
- 时间复杂度: O ( K N 2 ) O(KN^2) O(KN2)
class Solution:
def superEggDrop(self, K: int, N: int) -> int:
memo = dict()
def dp(K, N):
# base case
if K == 1: return N
if N == 0: return 0
# 避免重复计算
if (K, N) in memo:
return memo[(K, N)]
res = float('inf')
# 穷举所有可能的选择
for i in range(1, N + 1):
res = min(res,
max(
dp(K, N - i),
dp(K - 1, i - 1)
) + 1
)
# 记入备忘录
memo[(K, N)] = res
return res
return dp(K, N)
- 动态规划实现:
- 时间复杂度: O ( N K ) O(NK) O(NK)
class Solution:
def superEggDrop(self, K: int, N: int) -> int:
# dp[k][m]: 当前有k个鸡蛋, 可以尝试扔m次鸡蛋
# 这个状态下,最坏情况下、最多 能确切测试一栋n层的楼;
dp = [[0 for _ in range(N+1)] for _ in range(K+1)]
# 扔鸡蛋的次数;
m = 0
while dp[K][m] < N:
m += 1
for i in range(1, K+1):
dp[i][m] = dp[i][m-1] + dp[i-1][m-1] + 1
return m
375. 猜数字大小 II-中等-不好理解
LeetCode链接


- 填表顺序: i+1, j 和 i, j-1 必须提前知道;

dp[i][j]来代表[i,j]这个子序列最少要准备多少钱才足够用;
最少钱: 求剩余2个序列的最大值; 这样才满足至少; 最坏情况而言;
- 自己真的想不出来,想不通的:
class Solution:
def getMoneyAmount(self, n: int) -> int:
# 思路: 动态规划
# 难点: 1) 状态数组怎样定义; dp[i]? dp[i][j]? 模拟猜数字过程: i~x-1, x, x+1~j
# dp[i][j]: [i, j]这个子序列最少要准备多少钱才够用;
# [n+1][n+1]: 完全是为了计算方便; 和 1~n 下标进行对应;
# 初始化为0; 其中dp[i][i]=0, 代表只有一个数字时: 花费为0;
dp = [[0] * (n+1) for _ in range(n+1)]
# 遍历填表: 0可不用填;
for i in range(n-1, 0 ,-1):
for j in range(low+1, n+1):
# 三重遍历: 填写二维表格;
# 遍历low~high中的任意一个: 第一次 切分点;
tmp = float('inf')
for x in range(i, j):
dp[i][j] = min(tmp, x + max(dp[i][x-1], dp[x+1][j]))
tmp = dp[i][j]
return dp[1][n]
⭐⭐⭐单调栈-单数组问题
84. 柱状图中最大的矩形
LeetCode链接
参考*暴力解法、栈(单调栈、哨兵技巧)
以空间换时间,用到的数据结构是栈
要搞清楚这个过程,请大家一定要在纸上画图,搞清楚一些细节,这样在编码的时候就不容易出错了。
- 最长有效括号也是记录的下标;
记录什么信息? 记录高度是不是可以呢?其实是不够的,因为计算矩形还需要计算宽度,很容易知道宽度是由下标确定的,记录了下标其实对应的高度就可以直接从输入数组中得出,因此,应该记录的是下标。
我们就拿示例的数组 [2, 1, 5, 6, 2, 3] 为例:
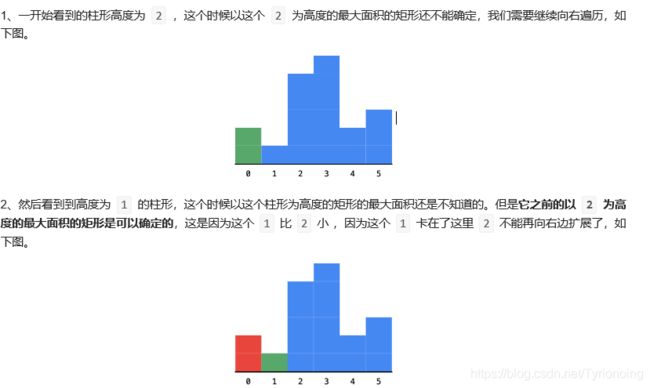
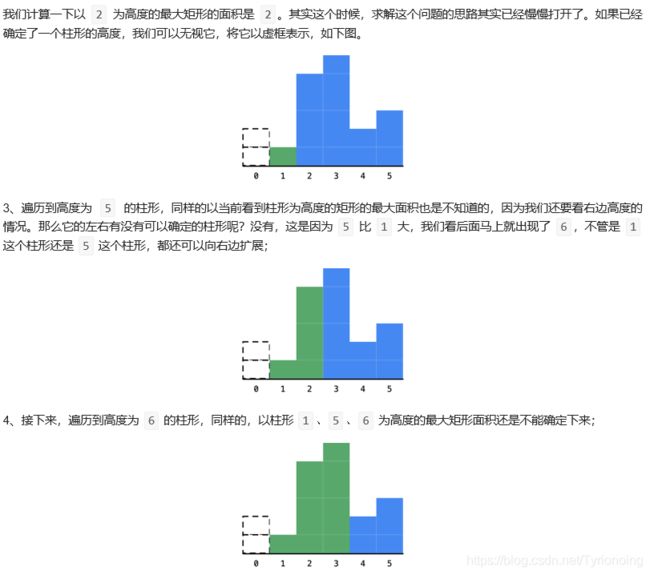

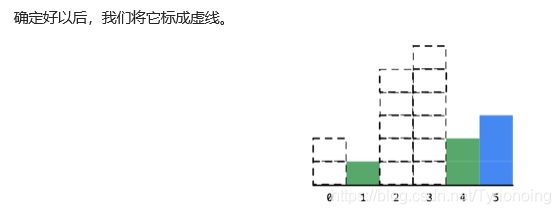
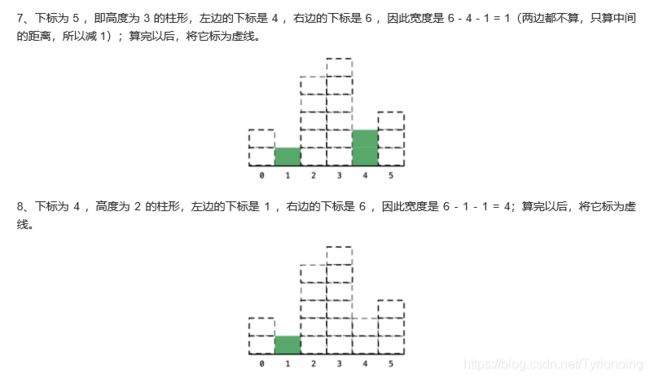
我们发现了,只要是遇到了当前柱形的高度比它上一个柱形的高度严格小的时候,
一定可以确定它之前的某些柱形的最大宽度,并且确定的柱形宽度的顺序是从右边向左边。
这个现象告诉我们,在遍历的时候需要记录的信息就是遍历到的柱形的下标,
它一左一右的两个柱形的下标的差就是这个面积最大的矩形对应的最大宽度。
这个时候,还要考虑的一个细节就是:在确定一个柱形的面积的时候,除了右边要比当前严格小,其实还蕴含了一个条件,那就是左边也要比当前严格小。
那如果是左边的高度和自己相等怎么办呢?我们想一想,我们之前是只要比当前严格小,我们才可以确定一些柱形的最大宽度。只要是大于或者等于之前看到的那一个柱形的高度的时候,我们其实都不能确定。
因此我们确定当前柱形对应的宽度的左边界的时候,往回头看的时候,一定要找到第一个严格小于我们要确定的那个柱形的高度的下标。这个时候 中间那些相等的柱形其实就可以当做不存在一样。因为它对应的最大矩形和它对应的最大矩形其实是一样的。
遍历的时候,需要记录的是下标,如果当前的高度比它之前的高度严格小于的时候,就可以直接确定之前的那个高的柱形的最大矩形的面积,为了确定这个最大矩形的左边界,我们还要找到第一个严格小于它的高度的矩形,向左回退的时候,其实就可以当中间这些柱形不存在一样。
我们在缓存数据的时候,是从左向右缓存的,我们计算出一个结果的顺序是从右向左的,并且计算完成以后我们就不再需要了,符合后进先出的特点。因此,我们需要的这个作为缓存的数据结构就是栈。



- 单调递增栈; (存储下标)
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
size = len(heights)
res = 0
heights = [0] + heights + [0]
# 先放入哨兵结点,在循环中就不用做非空判断
stack = [0]
size += 2
for i in range(1, size):
while heights[i] < heights[stack[-1]]:
cur_height = heights[stack.pop()]
cur_width = i - stack[-1] - 1
print('宽:', cur_width, '高:', cur_height)
res = max(res, cur_height * cur_width)
stack.append(i)
return res
85. 最大矩形-困难
LeetCode链接
- 仿照84题的做法。
class Solution:
def maximalRectangle(self, matrix: List[List[str]]) -> int:
# 使用84题的思路做; 遍历每一层记录到顶点的高;
if not matrix or not matrix[0]:
return 0
rows = len(matrix)
cols = len(matrix[0])
# heights: 记录当前行为坐标的 柱状图高度;
heights = [0] * (cols+2)
res = 0
for row in range(rows):
# 类似84题使用单调栈的思路;
stack = []
# 计算当前行的 heights操作;
for col in range(cols):
if matrix[row][col] == '1':
# [0] + height + [0]
heights[col+1] += 1
else:
# 如果后续间断置为0
heights[col+1] = 0
# 计算柱状图的最大面积;
for col in range(cols+2):
# 需要判断stack是否为空; 可以设置哨兵;
while stack and heights[col] < heights[stack[-1]]:
tmp = stack.pop()
res = max(res, (col-stack[-1]-1)*heights[tmp])
stack.append(col)
return res
739. 每日温度-中等
LeetCode链接

- 单调栈实现思路:
class Solution:
def dailyTemperatures(self, T: List[int]) -> List[int]:
# 思路: 等待天数: 对应下标相减即可, 单调栈的思路;
T = [float('inf')] + T + [0]
size = len(T)
res = [0]*(size-2)
# 加入哨兵,不用做非空判断;
# 存储对应下标;
stack = [0]
for i in range(1, size):
# 栈中圆元素递减;
while T[i] > T[stack[-1]]:
res[stack[-1]-1] = (i - stack[-1])
stack.pop()
stack.append(i)
return res
496. 下一个更大元素 I-简单
LeetCode链接

- 单调栈实现思路
class Solution:
def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:
# 单调栈思路:栈中元素递减;
nums2 = [float('inf')] + nums2
size = len(nums2)
stack = [0]
dct = {}
for i in range(1, size):
# 栈中元素递减;
# 注意 nums2:已经发生变化,下表对应;
while nums2[i] > nums2[stack[-1]]:
dct[nums2[stack[-1]]] = nums2[i]
stack.pop()
stack.append(i)
res = []
for num in nums1:
if num in dct:
res.append(dct[num])
else:
res.append(-1)
return res
42. 接雨水-困难-单调栈、双指针
LeetCode链接
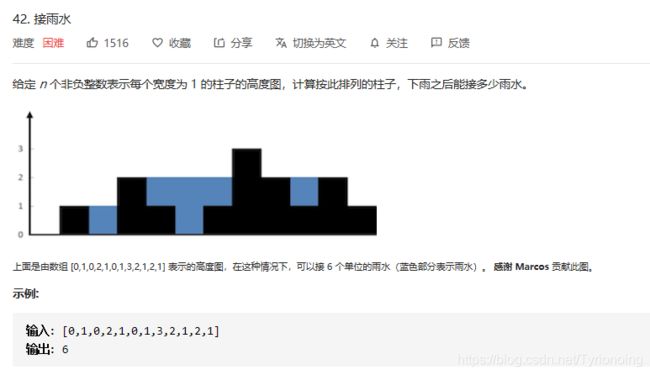
- 单调栈思路:
class Solution:
def trap(self, height: List[int]) -> int:
# 思路:单调栈;
# 单调栈: 1) 原来数组要不要添加元素(方便对齐处理;)
# 2) 要不要往栈中加入哨兵,不用判断栈空;
# 3) 栈的长度计算: 先pop() , 然后下标 i -stack[-1] - 1还是怎样?
# 接雨水: 左右两边都大于自己, 形成凹槽;
length = len(height)
res = 0
# 单调栈: 记录递减序列,查找凹陷;
# 记录下标值;
stack = [0]
for i in range(length):
# 凹陷判断、处理
while height[i] > height[stack[-1]]:
top = stack.pop()
# 是否是凹陷坑判断
if len(stack) == 0:
break
# 长度计算;
h = min(height[i], height[stack[-1]]) - height[top]
w = i - stack[-1] - 1
res += h*w
stack.append(i)
return res
221. 最大正方形-单调栈*DP
LeetCode链接

- 动态规划思路-真的想不到

统计全为 1 的正方形子矩阵


class Solution:
def maximalSquare(self, matrix: List[List[str]]) -> int:
if not matrix or not matrix[0]:
return 0
res = 0
n, m = len(matrix), len(matrix[0])
# dp(i,j) 表示以 (i,j) 为右下角,且只包含 1 的正方形的边长最大值
dp = [[0 for _ in range(m+1)] for _ in range(n+1)]
for i in range(1, n+1):
for j in range(1, m+1):
# 具体转移可以看图; 想到这个转移的人真的太牛逼了....
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1
if matrix[i-1][j-1] == '1' else 0
res = max(res, dp[i][j])
return res**2
- 单调栈思路:类似 最大矩形;
class Solution:
def maximalSquare(self, matrix: List[List[str]]) -> int:
# 抄 ‘最大矩形的题解’
# 使用84题的思路做; 遍历每一层记录到顶点的高;
if not matrix or not matrix[0]:
return 0
rows = len(matrix)
cols = len(matrix[0])
# heights: 记录当前行为坐标的 柱状图高度;
heights = [0] * (cols+2)
res = 0
for row in range(rows):
# 类似84题使用单调栈的思路;
stack = []
# 计算当前行的 heights操作;
for col in range(cols):
if matrix[row][col] == '1':
# [0] + height + [0]
heights[col+1] += 1
else:
# 如果后续间断置为0
heights[col+1] = 0
# 计算柱状图的最大面积;
for col in range(cols+2):
# 需要判断stack是否为空; 可以设置哨兵;
while stack and heights[col] < heights[stack[-1]]:
tmp = stack.pop()
# 选择短边;
res = max(res, min(col-stack[-1]-1, heights[tmp]))
stack.append(col)
# 短边平方
return res**2
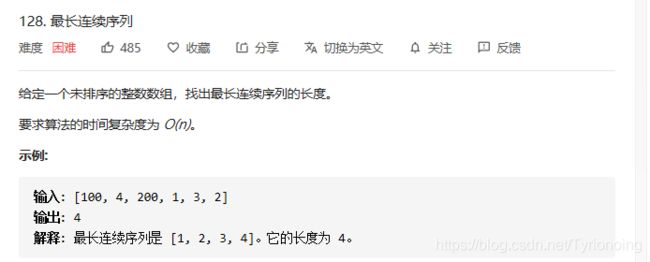
128. 最长连续序列-困难
LeetCode链接

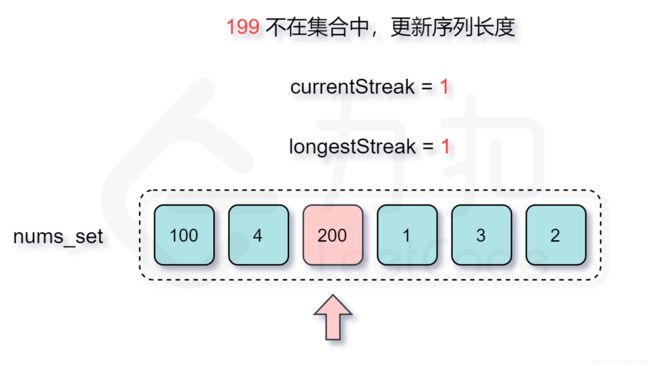
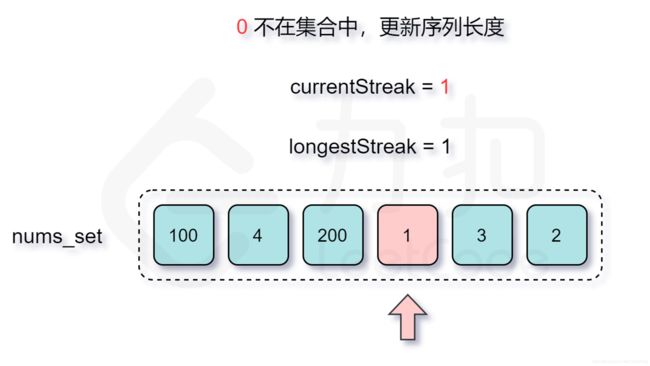
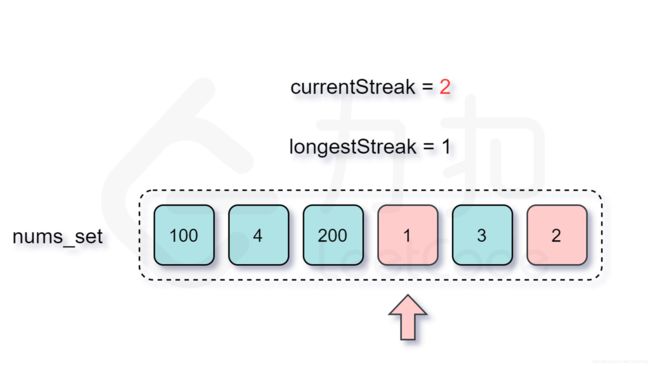
- 哈希表实现
class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
# 暴力: 1) 遍历数组中每个数字: O(n);
# 2) 遍历查找: x+1; 进一步 x+2;
# 复杂度: O(N^N)
# hash优化: 遍历查找使用hash存储, 直接进行查询; x+1查找, x+2查找; O(n^2)
# 缺点: x, x+1, x+2遇到以后都是重新迭代查询;
# hash进一步改进: 仅仅对于: x 进行查询;
longest = 0
nums_set = set(nums)
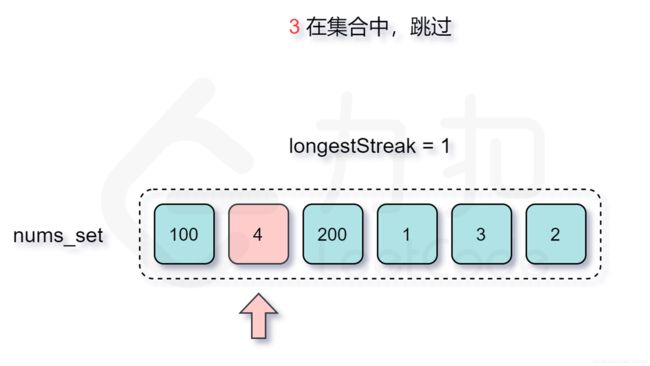
# 遍历: num-1: 1) 在hash中跳过; 2)不在hash计算长度, 并搜索: num+1, num+2...
for num in nums_set:
if num-1 not in nums_set:
curNum = num
curLong = 1
# 迭代找最长;
while curNum+1 in nums_set:
curNum += 1
curLong += 1
longest = max(longest, curLong)
return longest
303. 区域和检索 -前缀和-简单
LeetCode链接
⭐⭐⭐栈-单数组问题
⭐下面4题都巧妙利用栈解决,原来数组/字符顺序不变的问题;
316. 去除重复字母(困难)
LeetCode链接


- 大佬代码太牛逼了:

class Solution:
def removeDuplicateLetters(self, s: str) -> str:
# 思路: 字典序的概念: 比如: a, ac, abc 在字典中的 排序位置: a, ab, ac, 单词在字典中的排序位置;
# 使用词典记录: 剩余出现的次数;
stack = []
remain_count = collections.Counter(s)
for char in s:
# 前提: char 不在 stack
if char not in stack:
# 1) stack有值; 2) stack[-1] > char: 字典序选择;
# 3) 最后一个字符剩余出现次数(栈外面的)大于0;
while stack and char < stack[-1] and remain_count[stack[-1]] > 0:
stack.pop()
stack.append(char)
# 栈外面的char数量-1;
remain_count[char] -= 1
return ''.join(stack)
- 改进:

321. 拼接最大数(困难)
LeetCode链接

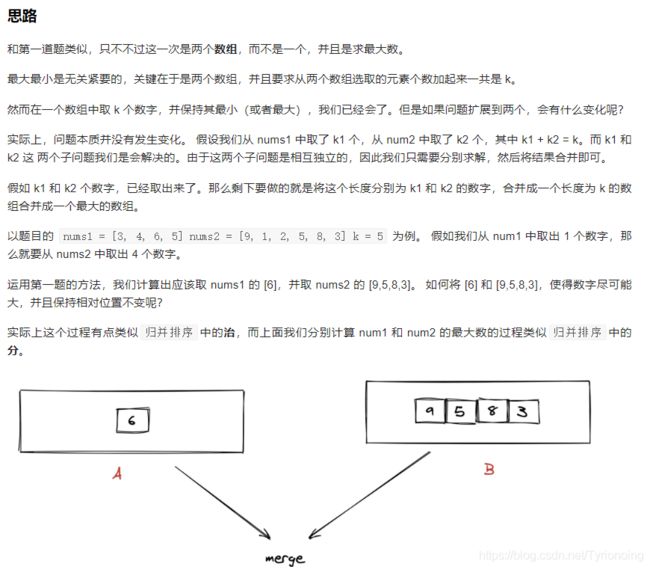


- 继续参考大佬代码实现:
class Solution:
def maxNumber(self, nums1: List[int], nums2: List[int], k: int) -> List[int]:
# 思路: 本题仍然是: 删除或保留若干个字符,使得剩下的数字最小(最大)、字典序最小(或者最大)。
# 原来数组、字符串中相对位置不发生变化。
# 解决方法: 贪心的删除栈中相邻 的元素;
if not k:
return []
if not nums1:
return nums2[:k]
if not nums2:
return nums1[:k]
# 将两个数组中的元素进行合并,并且不改变相对顺序;
# 两个数组进行比较大小,类似于 字典序, 从第一个元素进行比较;
# 默认不能改变顺序,所以从前到后排序即可;
def merge(A, B):
res = []
while A or B:
bigger = A if A > B else B
# 添加、删除最大的元素;
res.append(bigger[0])
bigger.pop(0)
return res
# 类似之前保留K最大数字,相对数字顺序不变化;
def pick_Max(nums, k):
stack = []
drop = len(nums) - k
for num in nums:
while drop and stack and stack[-1] < num:
drop -= 1
stack.pop()
stack.append(num)
return stack[:k]
return max(merge(pick_Max(nums1, i), pick_Max(nums2, k-i)) for i in range(k) if i<= len(nums1) and k-i <= len(nums2))

402. 移掉 K 位数字(中等)
LeetCode链接


- 特点: 字符串改变前后,相对位置不变
- 利用栈数据结构实现:
class Solution:
def removeKdigits(self, num: str, k: int) -> str:
# 时间复杂度:虽然内部有while循环, 但是对于每个数字还是出栈最多一次,
# 所以总的复杂度还是 O(N);
# 此题和戳气球好类似; 但是不一样
# 思路: 丢弃K个值,从前到后,如果出现 后一位小于前一位就丢弃;
stack = []
remain = len(num) - k
for digit in num:
# 利用栈: 删除前几位大的值,选择最小的结果;
# 模拟丢弃过程
while k and stack and stack[-1] > digit:
stack.pop()
k -= 1
stack.append(digit)
# lstrip('0') : 10200删除一位; 0200, 去除0
# [:remian] ... or '0' : 9删除一位: 0
return ''.join(stack[:remain]).lstrip('0') or '0'
1081. 不同字符的最小子序列(中等)-同316
LeetCode链接

class Solution:
def smallestSubsequence(self, text: str) -> str:
# 思路: 字典序的概念: 比如: a, ac, abc 在字典中的 排序位置: a, ab, ac,
# 单词在字典中的排序位置;
# 使用词典记录: 剩余出现的次数;
stack = []
remain_count = collections.Counter(text)
for char in text:
# 前提: char 不在 stack
if char not in stack:
# 1) stack有值; 2) stack[-1] > char: 字典序选择;
# 3) 最后一个字符剩余出现次数(栈外面的)大于0;
while stack and char < stack[-1] and remain_count[stack[-1]] > 0:
stack.pop()
stack.append(char)
# 栈外面的char数量-1;
remain_count[char] -= 1
return ''.join(stack)
⭐⭐⭐打家劫舍系列
198-打家劫舍(house robber) -简单-序列型
LeetCode链接

class Solution:
def rob(self, nums: List[int]) -> int:
# 思路: '最高金额' ==> 动态规划 ==> 序列型:前N房子
# 房子1 房子2 房子... 房子N-2, 房子N-1,房子N
# 最后一步: 偷不偷房子N
# 偷: 前N-2房子偷的最大+房子N
# 不偷: 前N-1房子偷的最大金额
# max()
# 状态定义: f[i] 前i个房子偷的最大金额数目;
# 转移方程: f[i] = max(f[i-2]+nums[i], f[i-1])
# 起始&边界: f[0] = 0, f[1] = nums[0], f[2] = nums[0]+nums[1]
'''
if len(nums) == 0:
return 0
dp_1 = 0 # f[i-2] f[0]
dp_2 = nums[0] # f[i-1] f[1]
for i in range(2, len(nums)+1):
t = max(dp_2, dp_1+nums[i-1]) # f[i]
dp_1 = dp_2
dp_2 = t
return dp_2
'''
# 思路: 动态规划: 序列型未看出。
# 房子1 房子2 房子3 房子4
# 最后一步: 偷不偷房子N
# 偷: 前N-2房子偷 + 房子N
# 不偷: 前N-1房子偷的最大金额
# max()
# 状态定义: f[i] 前i个房子偷的最大金额数目;
if len(nums) == 0:
return 0
dp = [0] * (len(nums)+1)
dp[1] = nums[0]
for i in range(2, len(nums)+1):
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1])
return dp[-1]
213-house robber2 -破圈、序列型
LeetCode链接
class Solution:
def rob(self, nums: List[int]) -> int:
# 思路: 主要方向还是动态规划,但是现在不是一个序列型,而是一个圈型的,可以分情况考虑,完了取max
# 1. 偷房子N-1 求: 1-N-1的最右策略
# 2. 不偷房子N-1m 求0-N-2的最右策略
# 序列型: 前N个房子偷的总数
def robmax(nums):
nums_len = len(nums)
opt = [0] * (nums_len+1)
opt[1] = nums[0]
for i in range(2,nums_len+1):
opt[i] = max(opt[i-1],opt[i-2]+nums[i-1])
return opt[nums_len]
if not nums: return 0
if len(nums) == 1: return nums[0]
# 注意: 这里比较坑的一点是: 一般是不用判断 len(nums) == 1的情况的,
# 因为照样可以切成两部分,但是使用切片的时候就会出现问题,切不出来。
nums1 = nums[1:] #[1,n] 找到到最大值
nums2 = nums[0:len(nums)-1] # [0,n-1] 找到到最大值
return max(robmax(nums1),robmax(nums2))
337. 打家劫舍 III-中等
LeetCode链接
337. 打家劫舍 III
在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,
我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,
聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
示例 1:
输入: [3,2,3,null,3,null,1]
3
/ \
2 3
\ \
3 1
输出: 7
解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.
示例 2:
输入: [3,4,5,1,3,null,1]
3
/ \
4 5
/ \ \
1 3 1
输出: 9
解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9.
- 错误方法1 : 65 / 124 个通过测试用例
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def rob(self, root: TreeNode) -> int:
# 思路: 二叉树的层次遍历结果存储,然后继续使用 动态规划
# 错误原因
def cengciTrave(root):
if not root:
return [0]
deque = []
deque.append(root)
res = []
while deque:
val = 0
deque_len = len(deque)
# 队列中每个节点进行相邻节点判断
for i in range(deque_len):
curNode = deque.pop(0)
val += curNode.val
# 加入当前节点的四周节点
if curNode.left:
deque.append(curNode.left)
if curNode.right:
deque.append(curNode.right)
res.append(val)
return res
def robMoney(nums):
if len(nums) == 0:
return 0
if len(nums) == 1:
return nums[0]
dp = [0] * (len(nums) + 1)
dp[1] = nums[0]
for i in range(2, len(nums)+1):
dp[i] = max(dp[i-1], dp[i-2]+nums[i-1])
return dp[-1]
nums = cengciTrave(root)
return robMoney(nums)
参考题解* 题解-树形 dp 入门问题

python实现树形DP,一般都是后序遍历,理由上述
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def rob(self, root: TreeNode) -> int:
return max(self.dp(root))
def dp(self, curRoot):
if not curRoot:
return [0, 0]
# 后序遍历
left = self.dp(curRoot.left)
right = self.dp(curRoot.right)
dp = [0, 0]
# dp[0]:以当前 node 为根结点的子树能够偷取的最大价值,规定 node 结点不偷
# dp[1]:以当前 node 为根结点的子树能够偷取的最大价值,规定 node 结点偷
dp[0] = max(left[0], left[1]) + max(right[0], right[1])
dp[1] = curRoot.val + left[0] + right[0]
return dp
⭐⭐⭐股票买卖问题
121.买卖股票的最佳时机-简单
LeetCode链接
参考 题解-团灭 LeetCode 股票买卖问题
121. 买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
注意:你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
# 思路: 一次买入, 一次卖出; 本质上求两个元素的最大差值; 1.找出最小值; 找出最小值后的最大值;
# 使用一个变量记录最小值
minValue = float('inf')
maxMoney = 0
for price in prices:
# 最小值记录;
if price < minValue:
minValue = price
# 到当前price的最大价值保存;
maxMoney = max(maxMoney, price - minValue)
return maxMoney
122.买卖股票2-简单
LeetCode链接
122. 买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
# 因为后期的股票是可知的,所以买之前看看后面有没有升高;
# 每次升高减去之前有差值,说明赚钱,那就 买卖;
# 因为可以每天多次买卖, 如果有更好,可以理解为 今天卖出去又买回来了
# 最流氓的地方在于 我后面是不是升值了,如果升值了,我前面就买
minValue = float('inf')
res = 0
for i in range(1, len(prices)):
money = prices[i] - prices[i-1]
if money > 0:
res += money
return res
123. 买卖股票的最佳时机 III-hard-不会
LeetCode链接
123. 买卖股票的最佳时机 III
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
示例 1:
输入: [3,3,5,0,0,3,1,4]
输出: 6
解释: 在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3
- python代码实现—不会
class Solution:
# 一个方法团灭 6 道股票问题
# dp[i][k][0 or 1] 在i天还剩k次交易次数,1持有 0不持有
# dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i]) 不动,昨天持有,今天卖了, + prices[i]
# dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i]) 不动,昨天没有,今天买入, - prices[i]
def maxProfit(self, prices: List[int]) -> int:
if len(prices)<=1:return 0
maxk = 2
dp = [[[0, 0] for i in range(maxk+1)] for i in range(len(prices))]
#第0天,不管还剩几次交易次数,不持有收益是0,也不可能持有(一天内不能瞬间买入卖出),所以设1为负数
dp[0][2][0] = 0
dp[0][2][1] = -prices[0]
dp[0][1][0] = 0
dp[0][1][1] = -prices[0]
for i in range(1, len(prices)):
#这里必须倒着,base case中k是倒着的,这里正序会出现0,1,与前面的设定不同了,就会出错
for k in range(maxk, 0, -1):
dp[i][k][0] = max(dp[i-1][k][0], dp[i-1][k][1] + prices[i])
dp[i][k][1] = max(dp[i-1][k][1], dp[i-1][k-1][0] - prices[i])
return dp[-1][maxk][0] #不持有就是卖出了,卖出肯定比持有收益多
188. 买卖股票的最佳时机 IV-困难-不会
LeetCode链接
309. 最佳买卖股票时机含冷冻期-中等-未做
LeetCode链接
714. 买卖股票的最佳时机含手续费-中等-未做
LeetCode链接
⭐⭐⭐单字符×DP
Offer 46. 把数字翻译成字符串
LeetCode链接

- 主要根据题目实现;
class Solution:
def translateNum(self, num: int) -> int:
nums = [int(n) for n in str(num)]
# 思路:
if len(nums) == 0:
return 0
# dp[i]: 前i个字符串有多少种解码方式;
dp = [0 for _ in range(len(nums)+1)]
dp[0] = 1
for i in range(1, len(nums)+1):
# 考虑一位: 这里具体分情况, 1.这个题0-9算一位; 2.lc那个 1-9
if nums[i-1] >= 0 and nums[i-1] <= 9:
dp[i] = dp[i] + dp[i-1]
# 同时考虑: 1.给定两位数字以上c考虑 nums[i-2] 2.考虑两位
if i > 1:
num = 10*nums[i-2] + nums[i-1]
if num >= 10 and num <= 25:
dp[i] = dp[i] + dp[i-2]
return dp[-1]
91.解码方法(medium)
LeetCode链接

- 动态规划实现:
class Solution:
def numDecodings(self, s: str) -> int:
nums = [int(i) for i in s]
# 空串: 返回0
if len(nums) == 0:
return 0
# 初始化为0, 考虑了: 如果出现不解码的片段,如00, 直接返回0种方式;
f = [0] * (len(nums)+1)
for i in range(1, len(nums)+1):
# 初始化f[0] = 1, 表示空串仅有一种解码方式, 初始化很重要。
f[0] = 1
# 考虑只有一位的情况下, 如果个位是0,只能看有没有10, 20处理
if nums[i-1] >= 1 and nums[i-1] <= 9:
f[i] += f[i-1]
# 同时考虑了: 1. 给定数字两位以上才考虑 nums[i-2], 考虑两位
# 2. 如果数字超出范围, 也是不进行考虑,
if i > 1:
num = 10*nums[i-2] + nums[i-1]
if num >= 10 and num <= 26:
f[i] += f[i-2]
return f[len(nums)]
⭐⭐⭐KMP算法-单字符串
KMP 算法详解
LeetCode链接
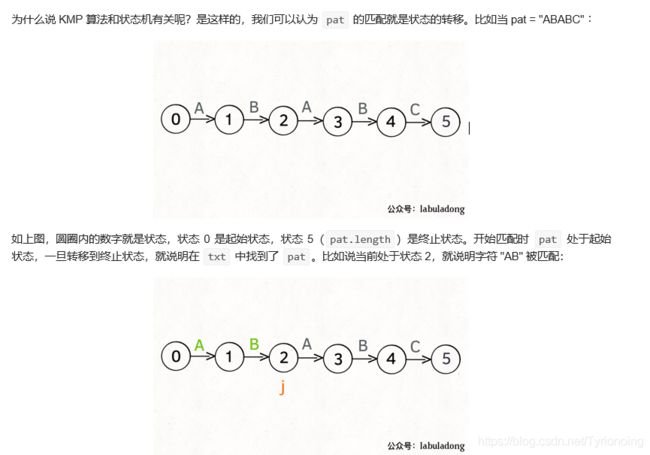
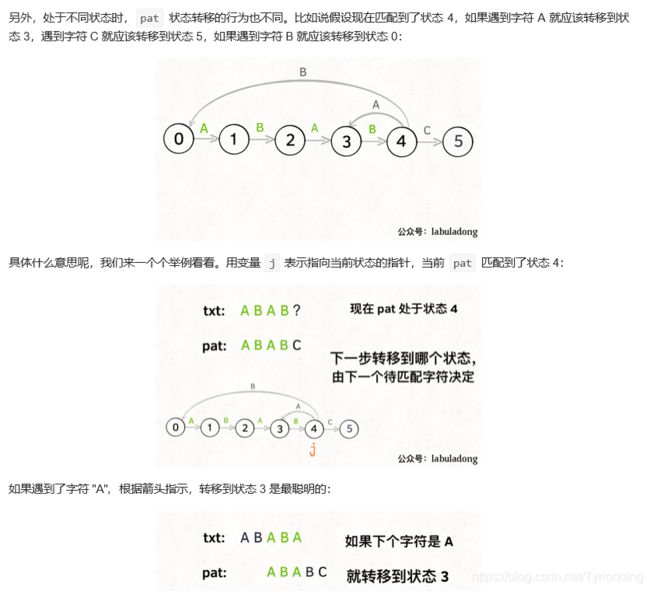
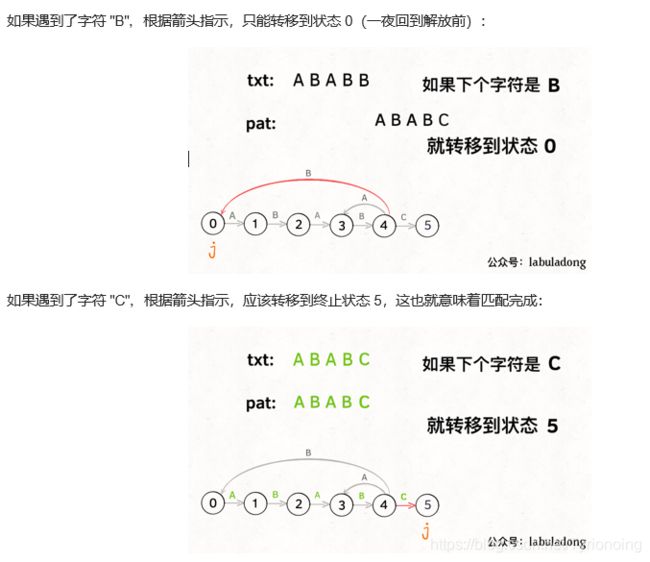
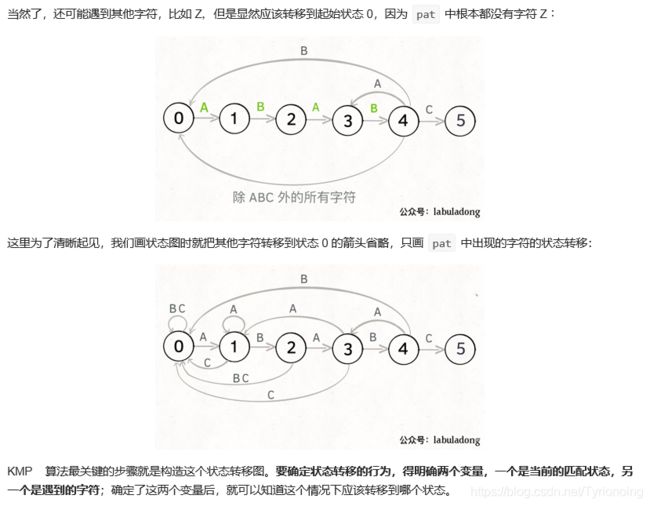

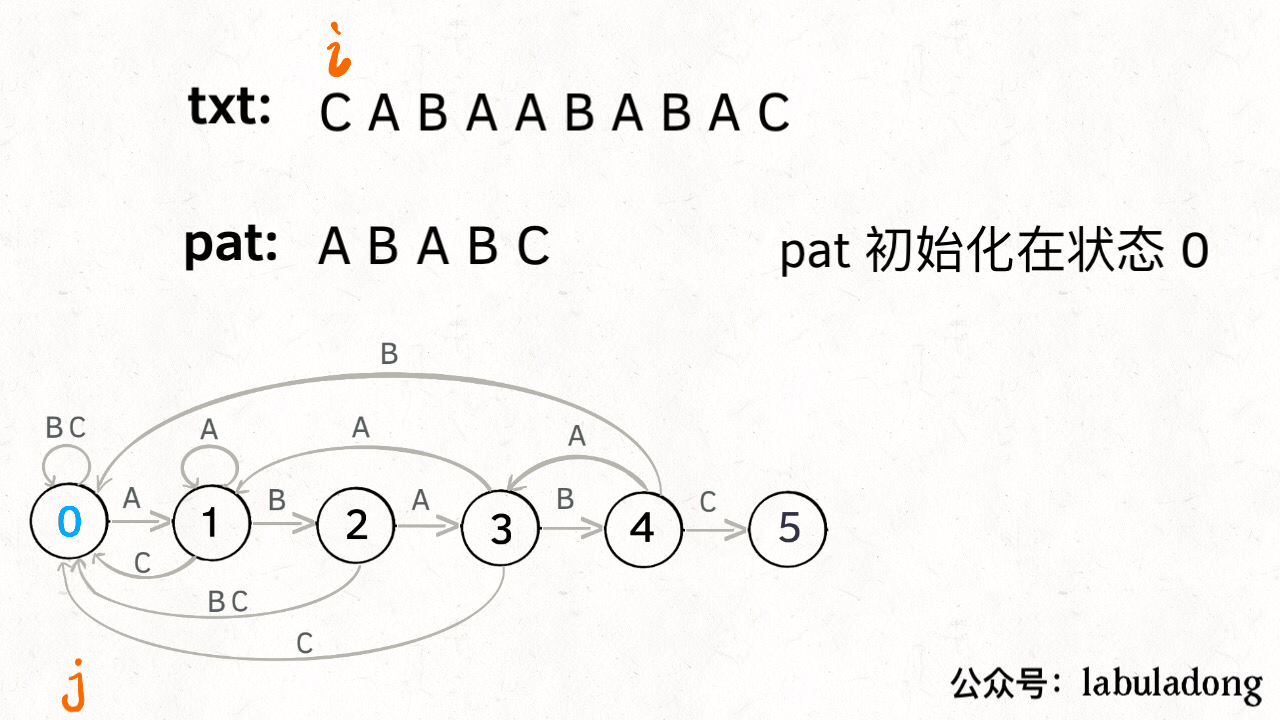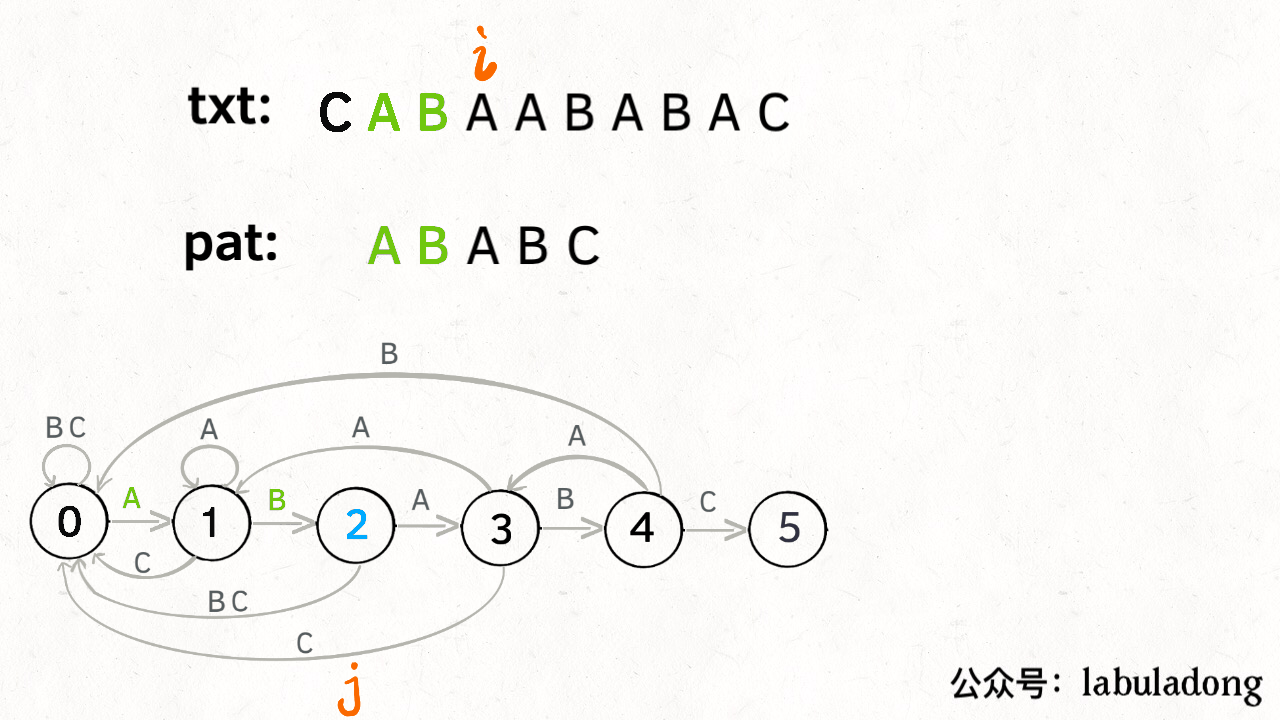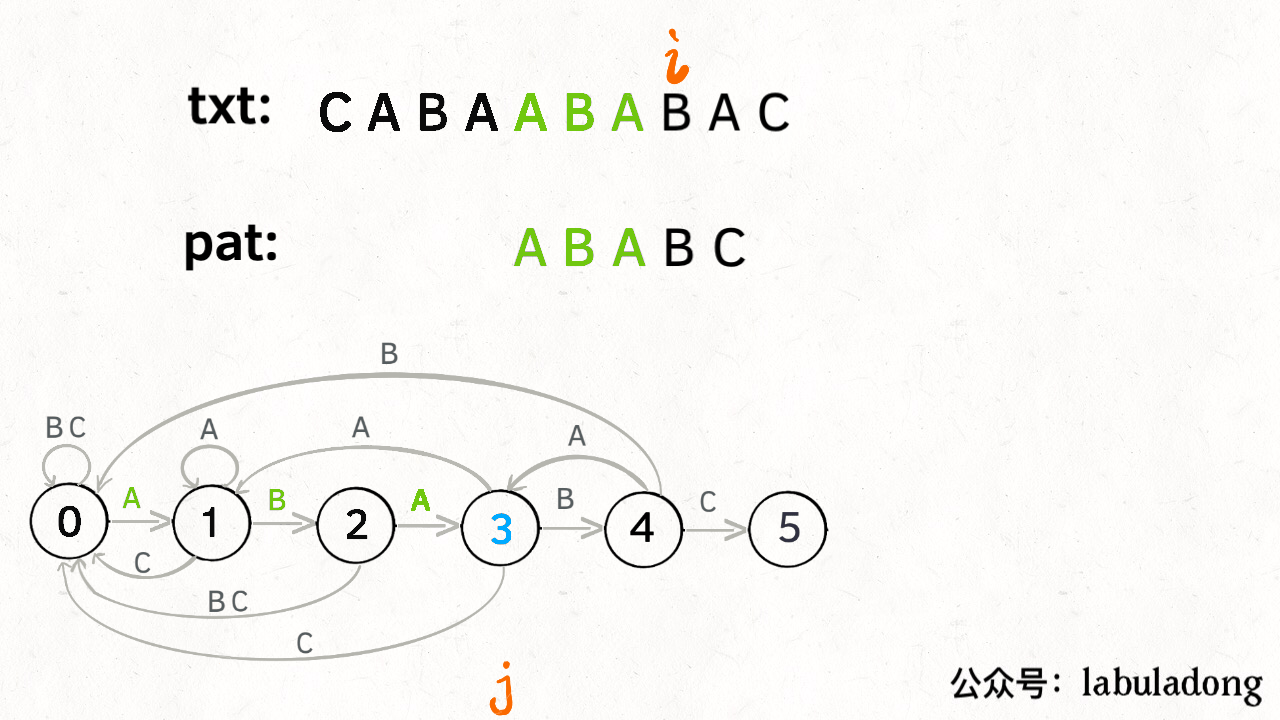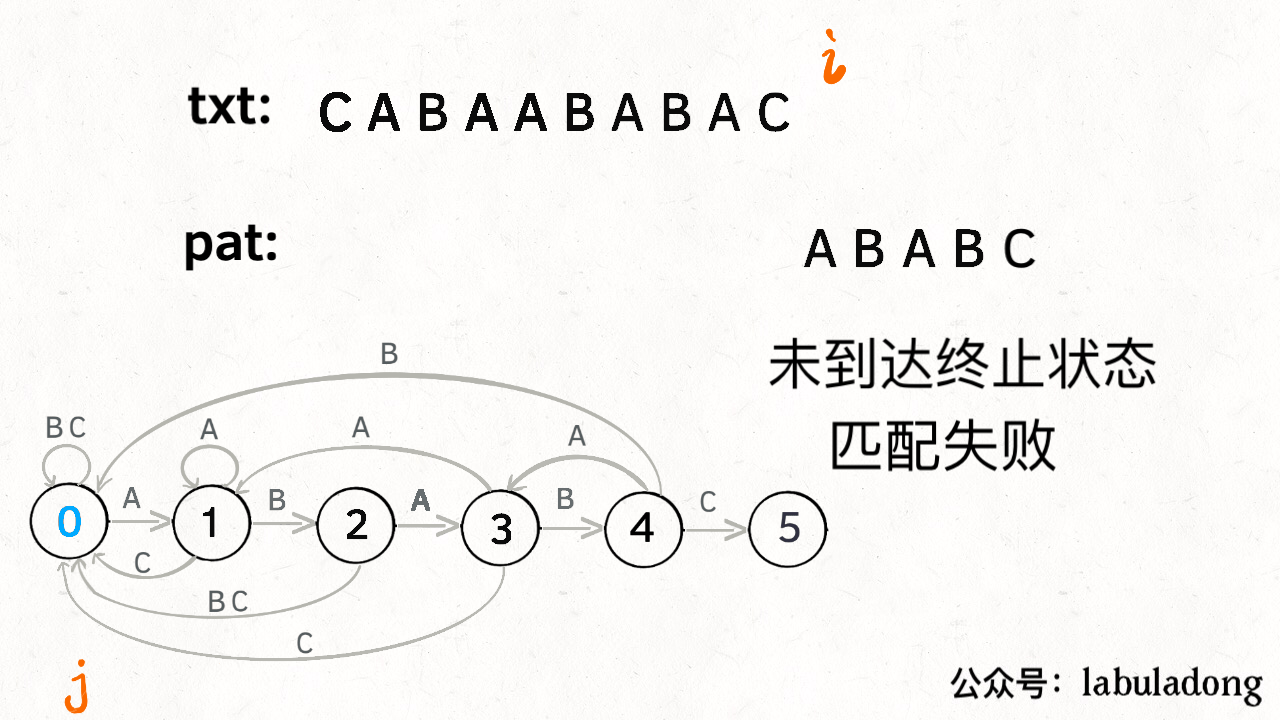

- 状态图完整转移构造过程: 理解状态: X 作用的精妙;

28. KMP实现 strStr()-简单
LeetCode链接
- KMP思路: 从大佬KMP讲解改编过来python;
- 难点: 影子
class KMP:
def __init__(self, pat):
# 构建KMP-pat状态;
self.pat = pat
M = len(pat)
# dp[j][c] = next
# next: 下一个状态;
self.dp = [[0 for _ in range(256)] for _ in range(M)]
# base case,只有遇到 pat[0] 这个字符才能使状态从 0 转移到 1,遇到其它字符的话还是停留在状态 0
self.dp[0][ord(pat[0])] = 1
# 影子初始状态: X : 0
X = 0
# 构建状态转移图
# j: 状态数量;
# 256: 有效字符
for j in range(1, M):
for c in range(256):
if ord(self.pat[j]) == c:
self.dp[j][c] = j+1
else:
self.dp[j][c] = self.dp[X][c]
# 影子: 这里指的下一个:下一个匹配字符出现重复;
# 更新影子状态
X = self.dp[X][ord(self.pat[j])]
def search(self, txt):
M = len(self.pat)
N = len(txt)
# pat的初始状态为: 0
j = 0
for i in range(N):
# 当前状态是: j, 遇到字符 txt[i]
# pat应该转移到哪一个状态;
j = self.dp[j][ord(txt[i])]
print(txt[i])
# 如果到达终止状态: 返回匹配开头的索引;
if j == M:
return i-M + 1
return -1
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
if not needle:
return 0
if not haystack:
return -1
kmp = KMP(needle)
res = kmp.search(haystack)
return res
- KMP-python 原版: next方式实现
class Solution:
def Build(self,p: str) -> List[int]:
m = len(p)
# nxt[i]:以字符串中 p[i-1]结尾的最大前缀、后缀重复长度;
# [0, 0] 1)对齐; 2) 第一个字符转移;
nxt = [0, 0]
j = 0
for i in range(1, m):
# 类似于双指针: 如果出现 p[i],p[j]不匹配, 则返回上一层前缀;
# 退出条件: 1) j==0; 2) p[i]==p[j];
while j > 0 and p[i] != p[j]:
j = nxt[j]
# 如果找到 p[i] == p[j],则长度j+1
if p[i] == p[j]:
j += 1
nxt.append(j)
print(i, nxt)
return nxt
def Match(s: str, p: str) -> List[int]:
n, m = len(s), len(p)
nxt = Build(p)
ans = []
j = 0
for i in range(n):
while j > 0 and s[i] != p[j]:
j = nxt[j]
if s[i] == p[j]:
j += 1
if j == m:
ans.append(i - m + 1)
j = nxt[j]
return ans
def longestPrefix(self, s: str) -> str:
return s[:self.Build(s)[-1]]
459. 重复的子字符串-简单
1392.最长快乐前缀-困难
LeetCode链接
- KMP前缀、后缀最大值选择;
class Solution:
def Build(self,p: str) -> List[int]:
m = len(p)
# nxt[i]:以字符串中 p[i-1]结尾的最大前缀、后缀重复最大长度;
nxt = [0, 0]
j = 0
for i in range(1, m):
# 类似于双指针: 如果出现 p[i],p[j]不匹配, 则返回上一层前缀;
# 退出条件: 1) j==0; 2) p[i]==p[j];
while j > 0 and p[i] != p[j]:
j = nxt[j]
# 如果找到 p[i] == p[j],则长度j+1
if p[i] == p[j]:
j += 1
nxt.append(j)
print(i, nxt)
return nxt
def Match(s: str, p: str) -> List[int]:
n, m = len(s), len(p)
nxt = Build(p)
ans = []
j = 0
for i in range(n):
while j > 0 and s[i] != p[j]:
j = nxt[j]
if s[i] == p[j]:
j += 1
if j == m:
ans.append(i - m + 1)
j = nxt[j]
return ans
def longestPrefix(self, s: str) -> str:
return s[:self.Build(s)[-1]]
⭐⭐⭐斐波那契系列
509. 斐波那契数
LeetCode链接
class Solution:
cache = {0: 0, 1: 1}
def fib(self, N: int) -> int:
'''
# 递归解法:出现 栈调用太深
if N == 1 or N == 2:
return 1
return self.fib(N-1) + self.fib(N-2)
'''
'''
# 暴力优化1:利用带 备忘录的递归解法
if N in self.cache:
return self.cache[N]
self.cache[N] = self.fib(N-1) + self.fib(N-2)
print(self.cache)
return self.cache[N]
'''
# 暴力优化2:动态规划解法
if N == 0:
return N
dp = [0] * (N + 1)
dp[1] = 1
for i in range(2, N+1):
dp[i] = dp[i-1] + dp[i-2]
return dp[N]
爬楼梯-简单
- 爬楼梯难度简单1045假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?注意:给定 n 是一个正整数。示例 1:输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。 - 1 阶 + 1 阶
- 2 阶示例 2:输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。 - 1 阶 + 1 阶 + 1 阶
2 . 1 阶 + 2 阶 - 2 阶 + 1 阶
class Solution:
def climbStairs(self, n: int) -> int:
# 思路: 1.动态规划
'''
# init array: 爬到第n阶梯需要的步数; 初始化: 0...n-->n+1数组大小;
dp = [0]*(n+1)
dp[0] = 1
dp[1] = 1
for i in range(2, n+1):
dp[i] = dp[i-2] + dp[i-1]
return dp[n]
'''
# 进一步空间优化
last = 1
now = 1
for i in range(2, n+1):
# tmp = now # 将当前值存储dp[i-1]--> dp[i-2]
# now = now + last # 计算当前 dp[i] 下次变为: dp[n-1]
# last = tmp # 更新dp[i-2], 下次变为: dp[n-2]
tmp = now+last
now, last = tmp, now
return now
⭐⭐⭐其他
120.三角形最小路径和-中等
LeetCode链接
- 从上到下-动态规划

class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
if not triangle:
return 0
n = len(triangle)
if n == 1:
return triangle[0][0]
# 自顶向下,逐层更新, 类似于: 维特比算法,因为不需要记录路径,所以直接求值就行
for i in range(1, n):
for j in range(len(triangle(i))):
# 每行开头
if j == 0:
triangle[i][j] = triangle[i][j] + triangle[i-1][j]
# 每行结尾
elif j == len(triangle[i]) -1 :
triangle[i][j] = triangle[i][j] + triangle[i-1][j-1]
# 剩余
else:
triangle[i][j] = min(triangle[i-1][j], triangle[i-1][j-1]) + triangle[i][j]
return min(triangle[-1])
参考 解法-由上至下,由下至上
- 记忆化递归
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
# 记忆化递归
rows = len(triangle)
# memo[i][j]: 位置i, j 到底部的最小和;
memo = [[None for _ in cols] for cols in triangle]
def helper(depth, posi, triang):
if memo[depth][posi]:
return memo[depth][posi]
if depth == rows-1:
return triang[depth][posi]
# 左下、右下结果;
left = helper(depth+1, posi, triang)
right = helper(depth+1, posi+1, triang)
# 选择当前节点到底层最小的结果;
tmp = min(left, right) + triang[depth][posi]
memo[depth][posi] = tmp
return tmp
res = helper(0, 0, triangle)
return res
- 由底向上,在原数组上改动
- 时间复杂度: O ( N 2 ) O(N^2) O(N2)
- 空间复杂度: O(1)
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
# 由底向上
rows = len(triangle)
for row in range(rows-2, -1, -1):
cols = len(triangle[row])
for col in range(cols):
triangle[row][col] = min(triangle[row+1][col], triangle[row+1][col+1]) + triangle[row][col]
return triangle[0][0]
- 从底向上,只使用一个一维数组记录
- 时间复杂度: O ( N 2 ) O(N^2) O(N2)
- 空间复杂度: O ( N ) O(N) O(N)
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
# 由底向上
# dp[i]: 一行中位置i的最小和;
dp = triangle[-1]
rows = len(triangle)
for row in range(rows-2, -1, -1):
cols = len(triangle[row])
for col in range(cols):
dp[col] = min(dp[col], dp[col+1]) + triangle[row][col]
return dp[0]
124. 二叉树中的最大路径和
LeetCode链接

参考 ⭐手绘图解-很优雅的一道DFS题

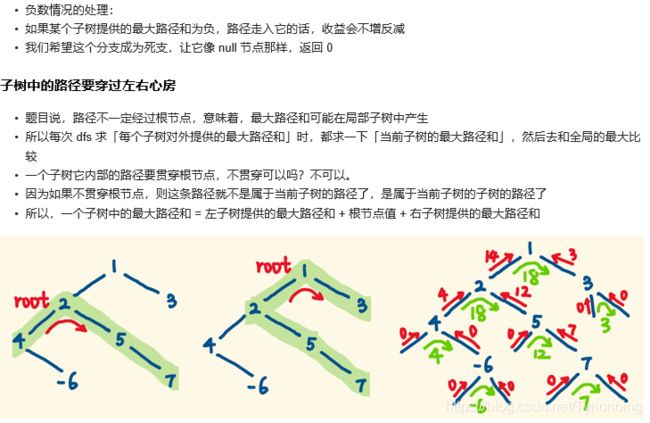
看这图差不多能懂意思,尤其是中间那个为什么 return curMax, 然后计算max_path_sum时候, 对于根节点而言总的路径和肯定是其左右子树其中的一个,但是计算全局可能的最大值的时候,有可能当前子树的结果就是全局最大值。
- DFS思路 + 动态规划思路:
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def maxPathSum(self, root: TreeNode) -> int:
def dfs(node):
# 叶子节点
if not node:
return 0
# 框架: 针对当前node分别求左右子树路径最大值;
left = dfs(node.left)
right = dfs(node.right)
curMax = max(
node.val, # 左右子树都为负数;
node.val + left, # 选择左子树路径;
node.val + right # 选择右子树路径;
)
# 更新全局变量;
self.max_path_sum = max(self.max_path_sum, curMax, node.val + left + right)
return curMax
self.max_path_sum = float('-inf')
dfs(root)
return self.max_path_sum
376. 摆动序列
LeetCode链接

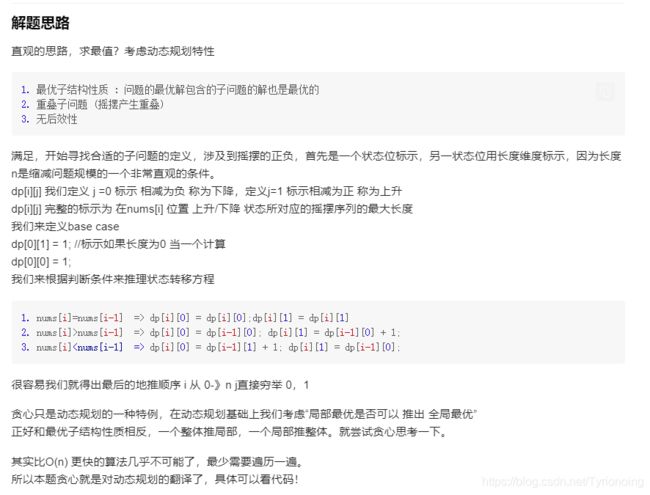

- python实现:
- 思路: 二维数组
class Solution(object):
def wiggleMaxLength(self, nums):
# 思路: 动态规划;
if not nums:
return 0
if len(nums) < 2:
return 1
# dp[i][0]: nums[i] 处在下降状态对应的摇摆序列最大长度;
# dp[i][1]: nums[i] 处在上升状态对应的摇摆序列最大长度;
dp = [[0 for _ in range(2)] for _ in range(len(nums))]
# base case
dp[0][1] = 1
dp[0][0] = 1
for i in range(1, len(nums)):
if nums[i] > nums[i-1]:
dp[i][1] = dp[i-1][0] + 1
dp[i][0] = dp[i-1][0]
elif nums[i] < nums[i-1]:
dp[i][1] = dp[i-1][1]
dp[i][0] = dp[i-1][1] + 1
else:
dp[i][0] = dp[i-1][0]
dp[i][1] = dp[i-1][1]
return max(dp[-1][0], dp[-1][1])
- python一维数组实现
class Solution(object):
def wiggleMaxLength(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
n = len(nums)
if n < 2:
return n
up = down = 1
for i in range(1, len(nums)):
if nums[i] > nums[i - 1]:
up = down + 1
if nums[i] < nums[i - 1]:
down = up + 1
return max(up, down)
324.摆动排序 II-中等-未作
LeetCode链接
343. 整数拆分-中等
LeetCode链接
参考 扒一扒这种题的外套(343. 整数拆分)
⭐⭐贪心选择-性质的简单证明、记忆化搜索、动态规划

注意:对于每一个状态而言,还要再比较“不再继续分割”和“继续分割”,取当中的最大值,将 nnn 进行分解的时候,以 8 为例:1 与 7 是一个解,1与 7 的分解的结果也是一个解。
- 代码1: 记忆化递归
- 复杂度分析:
- 时间复杂度: O ( N 2 ) O(N^2) O(N2), 循环里递归调用,相当于多一层循环;
- 空间复杂度: O ( N ) O(N) O(N), 使用了数组缓存;
class Solution:
def integerBreak(self, n: int) -> int:
def dfs(n):
if n == 1:
return 1
# 不在表中重新计算;
if memo[n] == -1:
res = 0
for i in range(1, n):
res = max(res, i*dfs(n-i), i*(n-i))
memo[n] = res
return memo[n]
memo = [-1 for _ in range(n+1)]
memo[0] = 1
memo[1] = 1
return dfs(n)
- 代码2: 动态规划
- 复杂度分析: O ( N 2 ) O(N^2) O(N2), 两层for循环
- 时间复杂度: O ( N ) O(N) O(N)
class Solution:
def integerBreak(self, n):
dp = [1 for _ in range(n + 1)]
for i in range(2, n + 1):
for j in range(1, i):
dp[i] = max(dp[i], j * dp[i - j], j * (i - j))
return dp[n]

- 代码3:动态规划
- 时间复杂度:O(N)
- 空间复杂度:O(N)
class Solution:
def integerBreak(self, n):
dp = [1 for _ in range(n+1)]
dp[0] = 0
dp[1] = 1
dp[2] = 1
for i in range(3, n+1):
dp[i] = max(
max(dp[i-1], i-1),
2*max(dp[i-2], i-2),
3*max(dp[i-3], i-3)
)
return dp[n]
137.只出现一次的数字II
LeetCode链接
32. 最长有效括号-hard-动态规划不会
LeetCode链接
413.等差数列划分-单数组*DP
LeetCode链接

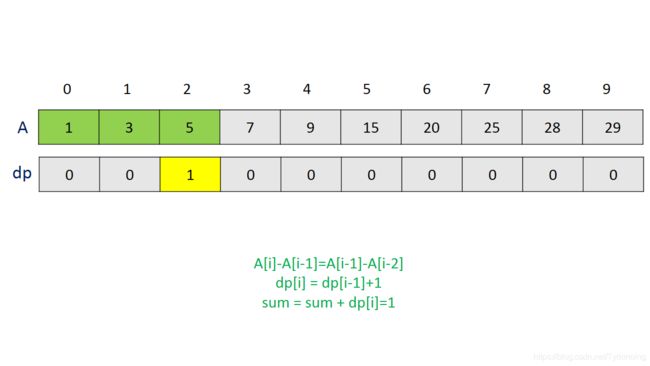

-
动规划思路: 记录以每个位置结尾的等差数列个数;
-
时间复杂度: O ( n ) O(n) O(n): 只需要遍历数组一遍,大小为n。
-
空间复杂度: O ( n ) O(n) O(n)
-
一维数组dp大小为n.
遇到题目还是需要好好分析分析,,, 这个应该算很简单的了.
class Solution:
def numberOfArithmeticSlices(self, A: List[int]) -> int:
res = 0
n = len(A)
dp = [0 for _ in range(n)]
for i in range(2, n):
if A[i]-A[i-1] == A[i-1]-A[i-2]:
dp[i] = 1 + dp[i-1]
res += dp[i]
return res
96. 不同的二叉搜索树-中等
LeetCode链接
- 数学规律方法



- python代码- 有点不像动态规划了
class Solution:
def numTrees(self, n: int) -> int:
if n<=1:
return 1
store = [1, 1]
for i in range(2, n+1):
s = i-1
count = 0
for j in range(i):
count += store[j]*store[s-j]
store.append(count)
print(i, count)
return store[n]
- 动态规划:转移方程有点奇怪
class Solution:
def numTrees(self, n: int) -> int:
if n<=1:
return 1
# dp[i] 代表什么含义呢?
# 以i 为结尾的
dp = [0 for _ in range(n+1)]
dp[0], dp[1] = 1, 1
for i in range(2, n+1):
for j in range(i):
dp[i] += dp[j]*dp[i-j-1]
return dp[n]
95. 不同的二叉搜索树 II-中等-未做
LeetCode链接

- 本题要求输出所有的: 二叉搜索数, 肯定不能像之前那样通过规律计算数字了;
- 回溯 + 记忆化(剪枝) 方法: 保存所有的可能结果;
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def generateTrees(self, n: int) -> List[TreeNode]:
if n == 0:
return []
# 记忆化递归思路: 记忆化: memo[(i, j)]: i-j的所有搜索二叉树;
# 记忆化词典; 避免重复计算: 比如: (left, right) = (2, 3); 可能计算多次;
memo = {}
# 递归函数: left~right范围内二叉搜索树的组织形式;
def left_right(left, right):
if left > right: # 一个数字情况的下一次处理;
return [None]
# 记忆化查询
if (left, right) in memo:
return memo[(left, right)]
# 当前范围: left~right结果存储;
ret = []
for i in range(left, right+1): # 2~3 搜索二叉树组织: [2, 4)
left_res = left_right(left, i-1)
right_res = left_right(i+1, right)
# 左右结果进行组合
for L in left_res:
for R in right_res:
# 对于当前节点构建左右子树,生成树;
tmp_Tree = TreeNode(i)
tmp_Tree.left = L
tmp_Tree.right = R
ret.append(tmp_Tree)
# 记忆化存储
memo[(left, right)] = ret
return ret
return left_right(1, n)
- 动态规划思路: 自底向上推导-不会
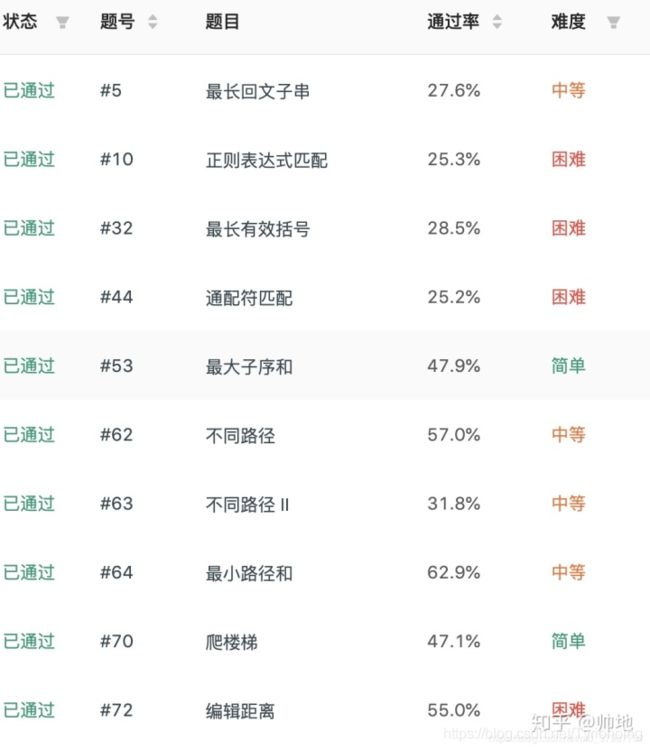
329. 矩阵中的最长递增路径-DFS
LeetCode链接

解题思路
直接暴力dfs果然超时
因此用记忆化解决重复搜索问题, 这时候memo就不再用字典而是一个二维数组了(因为是在矩阵上搜索), 这样的话就可以省掉visited位置的标记;
memo[i][j]记录的就是以i,j出发的最长递增路径. 因为路径上严格递增, 因此i,j出发的最长递增路径不会受 从周围那个点转移过来的 所影响.
- 实现python-参照大佬代码自己实现;
class Solution:
def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
# 记忆化搜索 + DFS, 之前的DFS一般都是直接得到答案;
if not matrix:
return 0
m, n = len(matrix), len(matrix[0])
directions = [(-1, 0), (1, 0), (0, 1), (0, -1)]
res = 0
self.memo = [[0]*n for _ in range(m)]
def dfs(i, j, matrix, directions):
# 如果(i, j)在 memory:直接返回 self.memo[i][j], 不用字典了;
if self.memo[i][j] != 0:
return self.memo[i][j]
for direction in directions:
new_i, new_j = i + direction[0], j + direction[1]
# 满足性检查;
if 0<= new_i < m and 0<= new_j < n and matrix[new_i][new_j] > matrix[i][j]:
# matrix[i][j] = '#' # 现在不需要标记了;
self.memo[i][j] = max(self.memo[i][j], dfs(new_i, new_j, matrix, directions))
# 每次访问节点自己, 最长路径+1;
self.memo[i][j] += 1
return self.memo[i][j]
for i in range(m):
for j in range(n):
res = max(res, dfs(i, j, matrix, directions))
return res
650.只有两个键的键盘-中等-没懂-dp
LeetCode链接

- 动态规划—不会。。。
- python素数分解—需要证明
- 1、质数次数为其本身。
2、合数次数为将其分解到所有不能再分解的质数的操作次数的和。
class Solution:
def minSteps(self, n: int) -> int:
# 分解质因数
res = 0
num = 2
while n > 1:
# 2, 3, 5
while n % num == 0:
res = res + num
n = n // num
num = num + 1
return res
263. 丑数-简单
LeetCode链接

- 思路: 不断除以: 2、3、5, 如果最终变为1, 则为: 丑数, 否则:不是;
class Solution:
def isUgly(self, num: int) -> bool:
if num == 1:
return True
if num <= 0:
return False
for number in [2, 3, 5]:
while num % number == 0:
num = num // number
if num == 1:
return True
else:
return False
264. 丑数 II-中等
LeetCode链接

- 大佬三指针思路: 自己能想到如何生成,但是想不清楚如何转移;
class Solution:
def nthUglyNumber(self, n: int) -> int:
if n <= 0:
return -1
# dp[i]: 第i+1个丑数;
dp = [1] * n
# 三指针初始化
i2 = 0
i3 = 0
i5 = 0
for i in range(1, n):
# 每次选择当前三者最小值;
minVal = min(dp[i2]*2, dp[i3]*3, dp[i5]*5)
dp[i] = minVal
# 三指针滑动: 找出哪个指针对应的数构造出了现在最小值,滑动一位(可能好几个指针同时滑动)
if minVal == dp[i2]*2:
i2 += 1
if minVal == dp[i3]*3:
i3 += 1
if minVal == dp[i5]*5:
i5 += 1
return dp[-1]
1201. 丑数 III-中等
LeetCode链接

参考 想不到-二分法思路剖析
基础思路:
首先,为什么第一时间能想到二分法?
让我们观察题目,可以看到,最终状态(即n)的范围非常大。试图自底向上递推或是按照通常的自顶向下回溯显然会超时(比如动态规划、DFS等方法)
面对这么大的状态空间,二分法的时间复杂度是logN,因此能够大大压缩需要遍历的状态数目
思路剖析:
既然已经确定了二分法作为切入点,关键问题来了,如何二分呢?
按照题意,所谓丑数是可以至少被a、b、c三者中的一者整除的,那么对于一个丑数X,我们能够确定它是第几个丑数吗?
–答案显然是可以的,我们只需要计算X中包含了多少个丑数因子即可。 例如: 6/2 = 3, 如果仅仅按照2看,有3个丑数;
即只需要知道在[0,X]范围内,还有多少个丑数即可,而这些丑数,无非就是一些能被a或者b或者c所整除的数。
那么显然,我们直接用X/a、X/b、X/c就能计算出[0,X]范围内有多少数能被a或者b或者c整除,然后把它们加起来就是答案!
但是仔细思考一下,我们是不是重复计算了些什么?如果一个数既能被a整除,又能被b整除,那么实际上该数在先前的计算中就被重复计算了一次(分别是在计算X/a和X/b时)。
好吧,让我们思考所有可能的情况
1.该数只能被a整除 (该数一定是a 的整数倍)
2.该数只能被b整除 (该数一定是b 的整数倍)
3.该数只能被c整除 (该数一定是c 的整数倍)
4.该数只能被a和b同时整除 (该数一定是a、b最小公倍数的整数倍)
5.该数只能被a和c同时整除 (该数一定是a、c最小公倍数的整数倍)
6.该数只能被b和c同时整除 (该数一定是b、c最小公倍数的整数倍)
7.该数只能被a和b和c同时整除(该数一定是a、b、c的最小公倍数的整数倍)
所以,我们只需要分别计算以上七项就能得到结果了!让我们分别来看(用MCM+下标表示最小公倍数):
情况1 = X/a - 情况4 - 情况5 - 情况7
情况2 = X/b - 情况4 - 情况6 - 情况7
情况3 = X/c - 情况5 - 情况6 - 情况7
情况4 = X/MCM_a_b - 情况7
情况5 = X/MCM_a_c - 情况7
情况6 = X/MCM_b_c - 情况7
情况7 = X/MCM_a_b_c
让我们整理上述方程后也就得到:
sum(情况) = X/a + X/b + X/c - X/MCM_a_b - X/MCM_a_c - X/MCM_b_c + X/MCM_a_b_c
好了,现在也就得到了计算X中包含多少个丑数因子的方法了!
至于计算最小公倍数的方法,这里不多介绍,概括而言就是对于两个数a和b,它们的最小公倍数 = a*b/(a和b的最大公约数),最大公约数可以通过辗转相除法得到
二分法思路
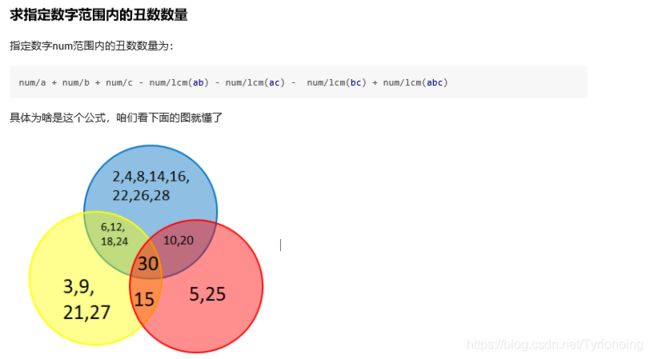
- 二分查找实现: python
class Solution:
def nthUglyNumber(self, n: int, a: int, b: int, c: int) -> int:
# 二分查找: 二分找 min(a, b, c) ~ n*min(a, b, c)区间中满足条件的结果;
# 求最小公倍数
def lcm(x, y):
return x * y / gcd(x, y)
# 求最大公约数: 辗转相除法
def gcd(x, y):
tmp = x % y
if tmp > 0:
return gcd(y, tmp)
else:
return y
# 求最小公倍数: 乘积 / 最大公约数(辗转相除法得到)
ab = lcm(a, b)
ac = lcm(a, c)
bc = lcm(b, c)
abc = lcm(ab, c)
# 二分查找边界: 0 ~ minValue*n
minValue = min(a, b, c)
low, high = 0, minValue*n
# 二分查找:
while low <= high:
mid = low + (high-low) // 2
# 探测当前mid范围内计算得到丑数结果数(范围: num(num∈[X,X + min(a,b,c))), 需要进一步找到左边界);
# 例如: 仅对于2而言, 14、15范围内都有7个丑数;
num = mid//a + mid//b + mid//c - mid//ab - mid//ac - mid//bc + mid//abc
# 三种情况判断
if num == n:
if mid % a == 0 or mid % b == 0 or mid % c == 0:
return mid
else:
high = mid - 1
elif num > n:
high = mid - 1
elif num < n:
low = mid + 1
return low
- 暴力方法: 超时
class Solution:
def nthUglyNumber(self, n: int, a: int, b: int, c: int) -> int:
# 思路: 和丑数2完全不同:此题仅仅要求被a,b,c整数, 未要求 因数只能是a,b,c
# 暴力方法: 每个数字都进行判断是不是丑数,然后选择第N个;
if n <= 0:
return -1
dp = [1]
count = 1
# 这种方法会超时
for i in range(1, n*a + 1):
if i%a == 0 or i % b == 0 or i % c == 0:
count += 1
dp.append(i)
return dp[n]
基础知识、拓展
基础1-动态规划详解
基础1-动态规划详解
基础2-动态规划答疑篇
基础2-动态规划答疑篇
基础3-动态规划:不同的定义产生不同的解法
基础3-动态规划:不同的定义产生不同的解法
基础4-⭐动态规划初探及什么是无后效性?
基础4-⭐动态规划初探及什么是无后效性?
基础5-DP总结
基础5-DP总结
关于区间DP

1。坐标型: 数据本身就是坐标型;
2. 序列型: 前几个,前0个; 思考带来好处
3. 划分型:划分若干段,每段有性质;
4. 区间型:
5. 背包型:
6. 最长序列型:
7. 博弈型:取石子、取数字; 必胜、必败;