leetcode(力扣)刷题笔记(c++)【中】
文章预览:
- 回溯算法
-
- 77. 组合
- 216.组合总和III
- 17.电话号码的字母组合
- 39. 组合总和
- 40.组合总和II
- 131.分割回文串
- 93.复原IP地址
- 78. 子集
- 90.子集II
- 491.递增子序列
- 46.全排列
- 47. 全排列 II
- 332.重新安排行程
- 第51题. N皇后
- 37. 解数独
- 贪心算法
-
- 455. 分发饼干
- 376. 摆动序列
- 53. 最大子数组和
- 122. 买卖股票的最佳时机 II
- 55. 跳跃游戏
- 45. 跳跃游戏 II
- 1005. K 次取反后最大化的数组和
- 134. 加油站
- 135. 分发糖果
- 860.柠檬水找零
- 406.根据身高重建队列
- 452. 用最少数量的箭引爆气球
- 435. 无重叠区间
- 763.划分字母区间
- 56. 合并区间
- 738. 单调递增的数字
- 714. 买卖股票的最佳时机含手续费
- 968.监控二叉树
- 动态规划
-
- 509. 斐波那契数
- 70. 爬楼梯
- 746. 使用最小花费爬楼梯
- 62.不同路径
- 63. 不同路径 II
- 343. 整数拆分
- 96.不同的二叉搜索树
- 0-1背包理论基础
- 416. 分割等和子集
- 1049. 最后一块石头的重量 II
- 494. 目标和
- 474.一和零
- 518. 零钱兑换 II
- 377. 组合总和 Ⅳ
- 322. 零钱兑换
- 279.完全平方数
- 139. 单词拆分
- 198. 打家劫舍
- 213. 打家劫舍 II
- 337. 打家劫舍 III
- 121. 买卖股票的最佳时机
- 122.买卖股票的最佳时机II
- 123.买卖股票的最佳时机III
- 188.买卖股票的最佳时机IV
- 309.最佳买卖股票时机含冷冻期
- 714.买卖股票的最佳时机含手续费
- 300.最长递增子序列
- 674. 最长连续递增序列
- 718. 最长重复子数组
- 1143.最长公共子序列
- 1035.不相交的线
- 53. 最大子数组和
- 392. 判断子序列
- 115. 不同的子序列
- 583. 两个字符串的删除操作
- 72. 编辑距离
- 编辑距离总结篇
- 647. 回文子串
- 516.最长回文子序列
参考刷题链接代码随想录
回溯算法
77. 组合
c++
法一:回溯
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracking(int max,int min,int k,int depth){
if(depth==k){
result.push_back(temp);
return;
}
depth++;//当前为第几层,树的深度
for(int i=min;i<=max;i++){
temp.push_back(i);
backtracking(max,i+1,k,depth);
temp.pop_back();//回溯
}
}
vector<vector<int>> combine(int n, int k) {
//k为树的深度,n为第一层的宽度
backtracking(n,1,k,0);
return result;
}
};
剪枝优化
这种写法和代码随想录的写法不一样,但是思路一致
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracking(int max,int min,int k,int depth){
if(max-min+1+depth<k) return;//剪枝优化,如果可以访问到的元素不够k个数则返回,不进行循环
if(depth==k){
result.push_back(temp);
return;
}
depth++;//当前为第几层,树的深度,相当于已经选择的元素个数
for(int i=min;i<=max;i++){
temp.push_back(i);
backtracking(max,i+1,k,depth);
temp.pop_back();//回溯
}
}
vector<vector<int>> combine(int n, int k) {
//k为树的深度,n为第一层的宽度
backtracking(n,1,k,0);
return result;
}
};
216.组合总和III
c++
法一:回溯
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;//存放路径值
int s=0;//和
void backtracking(int max,int min,int s,int k,int n){
if(s==n&&temp.size()==k){//相加之和为n且为k个数
result.push_back(temp);
return;
}
for(int i=min;i<=max;i++){
temp.push_back(i);
s+=i;
backtracking(max,i+1,s,k,n);
s-=i;
temp.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
int max=9;
int min=1;
backtracking(max,min,s,k,n);
return result;
}
};
剪枝优化
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
int s=0;
void backtracking(int max,int min,int s,int k,int n){
if(max-min+1+temp.size()<k||s>n) return;//剪枝优化,个数不足或者超过了目标值均返回
if(temp.size()==k){//且为k个数
if(s==n) result.push_back(temp);//相加之和为n
return;//访问了k个数就返回
}
for(int i=min;i<=max;i++){
temp.push_back(i);
s+=i;
backtracking(max,i+1,s,k,n);
s-=i;
temp.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
int max=9;
int min=1;
backtracking(max,min,s,k,n);
return result;
}
};
17.电话号码的字母组合
c++
法一:回溯
注意需要按照给出电话按键的顺序进行字母的组合
如果在现场面试的时候,一定要注意各种输入异常的情况,例如本题输入1 * #按键。
class Solution {
private:
const string letterMap[10] = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
public:
vector<string> result;
string temp;
void backtracking(string &digits,int index){
if(index==digits.size()){
result.push_back(temp);
return;
}
int k=digits[index]-'0';//取digits的第index个值
index++;
string letter=letterMap[k];
for(int i=0;i<letter.size();i++){
temp.push_back(letter[i]);
backtracking(digits,index);
temp.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if(digits.size()==0) return result;
backtracking(digits,0);
return result;
}
};
39. 组合总和
c++
法一:回溯
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
int s=0;
void backtracking(vector<int>& candidates,int target,int index){
if(s>target) return;
if(s==target){
result.push_back(temp);
return;
}
for(int i=index;i<candidates.size();i++){//注意每次开始的下标不是0
temp.push_back(candidates[i]);
s+=candidates[i];
backtracking(candidates,target,i);
s-=candidates[i];
temp.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
//每一层的元素都相同
backtracking(candidates,target,0);
return result;
}
};
剪枝优化:如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
int s=0;
void backtracking(vector<int>& candidates,int target,int index){
if(s>target) return;
if(s==target){
result.push_back(temp);
return;
}
for(int i=index;i<candidates.size()&&s<=target;i++){//条件判断里加了剪枝优化
temp.push_back(candidates[i]);
s+=candidates[i];
backtracking(candidates,target,i);
s-=candidates[i];
temp.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
//每一层的元素都相同
backtracking(candidates,target,0);
return result;
}
};
40.组合总和II
c++
法一:回溯,在插入路径时利用find函数进行去重,但是超时了,代码如下
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
int s=0;
void backtracking(vector<int>& candidates, int target,int index){
if(s>target) return;
if(s==target){
vector<vector<int>>::iterator it=find(result.begin(),result.end(),temp);
if(it==result.end()) result.push_back(temp);
return;
}
for(int i=index;i<candidates.size();i++){
s+=candidates[i];
temp.push_back(candidates[i]);
backtracking(candidates,target,i+1);
s-=candidates[i];
temp.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
backtracking(candidates,target,0);
return result;
}
};
优化:如果同一树层中遇到了重复元素就跳过,因为前面的重复元素和后面元素的组合一定会重复。注意if条件中i>index必须写在&&的前面,不然会报错。
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
int s=0;
void backtracking(vector<int>& candidates, int target,int index){
if(s>target) return;
if(s==target){
result.push_back(temp);
return;
}
for(int i=index;i<candidates.size();i++){
if(i>index&&candidates[i]==candidates[i-1]) continue;//去重步骤,同一层的节点值不能重复
s+=candidates[i];
temp.push_back(candidates[i]);
backtracking(candidates,target,i+1);
s-=candidates[i];
temp.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
backtracking(candidates,target,0);
return result;
}
};
131.分割回文串
c++
法一:回溯。
每层按照1~s.size()的大小依次进行截取
class Solution {
public:
vector<vector<string>> result;
vector<string> temp;
bool isPalindrome(const string &s,int start,int end){//这里必须要加const,因为回溯函数中加了
//双指针判断是否为回文串
for(int i=start,j=end;i<j;i++,j--){
if(s[i]!=s[j]) return false;
}
return true;
}
void backtracking(const string &s,int start_index){
if(start_index >= s.size()){//分割结束
result.push_back(temp);
return;
}
for(int i=start_index;i<s.size();i++){
if(isPalindrome(s,start_index,i)) {//是回文串
string str=s.substr(start_index,i-start_index+1);//start_index位置开始的子串
temp.push_back(str);
}
else continue;//不是回文串就跳过
backtracking(s,i+1);
temp.pop_back();
}
}
vector<vector<string>> partition(string s) {
backtracking(s,0);
return result;
}
};
93.复原IP地址
c++
法一:回溯
先分割三次,就会形成四段字符串,循环里每次都会对前三段字符串是否有效进行判断,结束条件里面会对第四段进行判断,但是都不能忘记path需要回溯
class Solution {
public:
vector<string> result;
string path;
bool isValid(const string &s,int start,int end){//判断字符串是否有效
if(start>end) return false;
if(s[start]=='0'&&start!=end) return false;
int num=0;
for(int i=start;i<=end;i++){
num = num * 10 + (s[i] - '0');
if(num>255) return false;
}
return true;
}
void backtracking(const string &s,int index,int depth){
if(depth==3){//分割三次后就进行处理判断剩下的字符串是否符合要求
if(isValid(s,index,s.size()-1)){
string str=s.substr(index,s.size()-index);
path+=str;
result.push_back(path);
for(int j=0;j<str.size();j++)
path.pop_back();//这里也需要回溯
}
return;
}
for(int i=index;i<s.size();i++){
string str=s.substr(index,i-index+1);//[index,i]之间的字符串
if(isValid(s,index,i)){//字符串符合要求
path+=str;
depth++;
if(depth<4) path+=".";
backtracking(s,i+1,depth);
for(int j=0;j<str.size();j++)
path.pop_back();//这样写每次只会弹出一个字符,但是str不止一个字符,所以需要加循环处理
if(depth<4) path.pop_back();
depth--;
}
else break;
}
}
vector<string> restoreIpAddresses(string s) {
//树的深度为四层,
if (s.size() < 4 || s.size() > 12) return result; // 算是剪枝了
backtracking(s,0,0);
return result;
}
};
二刷写法:更简便
class Solution {
public:
vector<string> result;
vector<string> path;//记录分割得到的字符串
void backtracking(string s,int index){
if(path.size()>4) return;
if(index==s.size()&&path.size()==4){
string str="";
for(int i=0;i<path.size();i++){
str+=path[i];
if(i<path.size()-1) str+=".";
}
result.push_back(str);
}
for(int i=index;i<s.size();i++){
// if(i-index+1>3) return;
string str=s.substr(index,i-index+1);
if(stoi(str)>255) return;
if(str.size()>1&&str[0]=='0') return;//不能含有前导 0
path.push_back(str);
backtracking(s,i+1);
path.pop_back();
}
}
vector<string> restoreIpAddresses(string s) {
backtracking(s,0);
return result;
}
};
78. 子集
c++
法一:回溯
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracking(vector<int>& nums,int index){
if(true){//每种分割的结果都放进去
result.push_back(temp);//后面就不要再加上return了
}
for(int i=index;i<nums.size();i++){
temp.push_back(nums[i]);
backtracking(nums,i+1);
temp.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
backtracking(nums,0);
return result;
}
};
90.子集II
c++
法一:回溯
注意:去重必须要先对数组进行排序!
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracking(vector<int>& nums,int index){
result.push_back(temp);
for(int i=index;i<nums.size();i++){
if(i>index&&nums[i]==nums[i-1]){
continue;
}
else{
temp.push_back(nums[i]);
backtracking(nums,i+1);
temp.pop_back();
}
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
backtracking(nums,0);
return result;
}
};
491.递增子序列
c++
法一:回溯
踩坑记录:采用和上一题90题类似的去重写法,但是这样做只能去除前后出现的重复数字,如果后面又出现了重复数字就去重不了,比如数组[1,2,2,7,5,7]
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracjing(vector<int>& nums,int index){
if(temp.size()>1) result.push_back(temp);
for(int i=index;i<nums.size();i++){
if(i>index&&nums[i]==nums[i-1]){//因为并不是有序数组,所以这样做只能去除前后出现的重复数字,如果后面又出现了重复数字就去重不了
continue;
}
if(temp.size()>0&&nums[i]<temp.back()) continue;
temp.push_back(nums[i]);
backtracjing(nums,i+1);
temp.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracjing(nums,0);
return result;
}
};
改进后:需要直到同一层中哪些数字用过了,一个for循环就代表横向树的一层,所以在for循环上面添加一个unordered_set容器(该容器底层为哈希表,且不会自动排序,这道题并不需要对元素进行排序),unordered_set中不允许有重复的元素。同一层的元素会出现在路径容器的同一个位置,所以不能出现重复值,回溯代码最后不需要对unordered_set删除nums[i]这个元素,因为unordered_set只记录同一层的元素哪些用过了
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracjing(vector<int>& nums,int index){
if(temp.size()>1) result.push_back(temp);
unordered_set<int> use_num;//这里也可以用数组,耗时更少
for(int i=index;i<nums.size();i++){
if(use_num.find(nums[i])!=use_num.end()){
continue;
}
use_num.insert(nums[i]);//注意后面不需要再删除这个元素
if(temp.size()>0&&nums[i]<temp.back()) continue;//保持递增顺序
temp.push_back(nums[i]);
backtracjing(nums,i+1);
temp.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracjing(nums,0);
return result;
}
};
46.全排列
c++
法一:回溯
需要查找temp里面已经用过的元素,如果用过了就不能再用了,且每次循环都是从0开始
class Solution {
public:
vector<vector<int>> result;
vector<int> temp;
void backtracjing(vector<int>& nums,int index){
if(temp.size()>1) result.push_back(temp);
unordered_set<int> use_num;
for(int i=index;i<nums.size();i++){
if(use_num.find(nums[i])!=use_num.end()){
continue;
}
use_num.insert(nums[i]);//注意后面不需要再删除这个元素
if(temp.size()>0&&nums[i]<temp.back()) continue;//保持递增顺序
temp.push_back(nums[i]);
backtracjing(nums,i+1);
temp.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracjing(nums,0);
return result;
}
};
写法二:使用 unordered_set
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
unordered_set<int> use_num;
void back(vector<int>& nums){
if(path.size()==nums.size()){
result.push_back(path);
return;
}
for(int i=0;i<nums.size();i++){
if(use_num.find(nums[i])!=use_num.end()) continue;
else use_num.insert(nums[i]);
path.push_back(nums[i]);
back(nums);
path.pop_back();
use_num.erase(nums[i]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
back(nums);
return result;
}
};
47. 全排列 II
c++
法一:回溯
也可以使用unordered_set来记录同一层的元素使用情况,利用find函数来进行去重
需要注意的是:使用set去重的版本相对于数组的版本效率都要低很多
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums,int* use_num){
if(path.size()==nums.size()) {
result.push_back(path);
return;
}
for(int i=0;i<nums.size();i++){
//use_num[i-1]==0:同层use_num[i-1]使用过
//use_num[i-1]==1:同一树枝use_num[i-1]使用过
if(i>0&&nums[i]==nums[i-1]&&use_num[i-1]==0) continue;//对同一层进行去重效率更高
if(use_num[i]==1) continue;//跳过本身
use_num[i]=1;//1代表用过了
path.push_back(nums[i]);
backtracking(nums,use_num);
path.pop_back();
use_num[i]=0;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
int size=nums.size();
int use_num[size];//记录路径元素是否用过,默认初始化为0
sort(nums.begin(),nums.end());
backtracking(nums,use_num);
return result;
}
};
二刷踩坑:如果把跳过本身写在前面就会出问题
 原因:因为第二个1在进入同层去重判断时会跳过,但是此时已经把数组赋1了,在循环到2时这个used_num=011,会出错
原因:因为第二个1在进入同层去重判断时会跳过,但是此时已经把数组赋1了,在循环到2时这个used_num=011,会出错
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void back(vector<int>& nums,int *used_num){
if(path.size()==nums.size()){
result.push_back(path);
return;
}
for(int i=0;i<nums.size();i++){
if(used_num[i]==1) continue;
else used_num[i]=1;
if(i>0&&nums[i]==nums[i-1]&&used_num[i-1]==0) continue;
path.push_back(nums[i]);
back(nums,used_num);
path.pop_back();
used_num[i]=0;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(),nums.end());
int used_num[nums.size()];
back(nums,used_num);
return result;
}
};
332.重新安排行程
c++
法一:回溯
踩坑记录:先找出第一个机票再做回溯的做法是不对的,因为找出的最小排序不一定能把所有的机票用完
正确做法: 利用unordered_map<出发机场, map<到达机场, 航班次数>> targets来储存所有的行程中相同出发地的行程,通过判断航班次数来判断该行程是否已经用过。map中所有元素都是pair
class Solution {
public:
vector<string> result;
// unordered_map<出发机场, map<到达机场, 航班次数>> targets
unordered_map<string, map<string, int>> targets;
bool backtracking(vector<vector<string>>& tickets){
if(result.size()==(1+tickets.size())){
return true;
}
for(pair<const string,int>& temp:targets[result[result.size()-1]]){//找出result的最后一个地点,也就是下一个行程的出发地点
if(temp.second>0){//说明还没用过
result.push_back(temp.first);//只需要放入到达机场
temp.second--;
if(backtracking(tickets)) return true;//
result.pop_back();
temp.second++;
}
}
return false;//如果没找到行程就会返回false
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
for(vector<string> &temp:tickets){
targets[temp[0]][temp[1]]++;//targets[temp[0]]相当于是key=temp[0]对应的map容器,targets[temp[0]][temp[1]]相当于是对map容器中key=temp[1]进行赋值
}
result.push_back("JFK");//初始机场
backtracking(tickets);
return result;
}
};
二刷写法:先找出所有路径,再一个个对比看哪个排序更靠前。超出时间限制了
class Solution {
public:
vector<vector<string>> result;
int sum=0;
vector<string> temp;
void backtracking(vector<vector<string>>& tickets,int* used_tickets,string start_loc){
if(sum==tickets.size()){
result.push_back(temp);
return;
}
for(int i=0;i<tickets.size();i++){
if(used_tickets[i]==1) continue;
if(tickets[i][0]!=start_loc) continue;
used_tickets[i]=1;
temp.push_back(tickets[i][1]);
sum++;
backtracking(tickets,used_tickets,tickets[i][1]);
sum--;
temp.pop_back();
used_tickets[i]=0;
}
}
vector<string> findItinerary(vector<vector<string>>& tickets) {
int used_tickets[tickets.size()];
temp.push_back("JFK");
backtracking(tickets,used_tickets,"JFK");
int index=0;
if(result.size()==1) return result[0];
vector<string> path=result[0];
for(int i=1;i<result.size();i++){
for(int j=0;j<result[i].size();j++){
if(path[j]!=result[i][j]){
string s1=path[j];
string s2=result[i][j];
if(s1.compare(s2)>0) path=result[i];
break;
}
}
}
return path;
}
};
第51题. N皇后
c++
法一:回溯
思路:通过used_column来记录用过的列,通过use_loc来记录皇后位置和会被攻击的地方,只需要将下面每一层的对角线的位置标记就可以了,但是n=6时报错了,出现皇后放在了对角线的位置。
class Solution {
public:
vector<vector<string>> result;
vector<string> conver(vector<vector<int>>& use_loc,int n){
vector<string> temp;
for(int i=0;i<n;i++){
string str="";
for(int j=0;j<n;j++){
if(use_loc[i][j]==2){
str+="Q";
}
else str+=".";
}
temp.push_back(str);
}
return temp;
}
void backtracking(int n,vector<vector<int>>& use_loc,int depth,vector<bool>& used_column){
if(depth==n){
vector<string> temp;
temp=conver(use_loc,n);
result.push_back(temp);
return;
}
for(int i=0;i<n;i++){
if(used_column[i]) continue;//跳过用过的列
if(use_loc[depth][i]==1) continue;//跳过会被攻击的地方
use_loc[depth][i]=2;//皇后
//下面每一层的对角线
for(int j=depth+1,k=i-1;j<n && k>=0;j++,k--){
use_loc[j][k]=1;
}
for(int j=depth+1,k=i+1;j<n && k<n;j++,k++){
use_loc[j][k]=1;
}
used_column[i]=true;
depth++;
backtracking(n,use_loc,depth,used_column);
depth--;
use_loc[depth][i]=0;
for(int j=depth+1,k=i-1;j<n && k>=0;j++,k--){
use_loc[j][k]=0;
}
for(int j=depth+1,k=i+1;j<n && k<n;j++,k++){
use_loc[j][k]=0;
}
used_column[i]=false;
}
}
vector<vector<string>> solveNQueens(int n) {
vector<vector<int>> use_loc(n,vector<int>(n,0));//全部初始化为0
vector<bool> used_column(n,false);//用过的列
backtracking(n,use_loc,0,used_column);
return result;
}
};
后来找出了错误,因为有些皇后的攻击的位置会有交叉,在回溯的时候将一些攻击位置置0后是不对的,该位置有可能是上层皇后的攻击位置,所以不能简单的置0和置1,应该每个位置的数值是被攻击的次数,这样回溯时才不会出错
class Solution {
public:
vector<vector<string>> result;
vector<string> conver(vector<vector<int>>& use_loc,int n){
vector<string> temp;
for(int i=0;i<n;i++){
string str="";
for(int j=0;j<n;j++){
if(use_loc[i][j]==-1){
str+="Q";
}
else str+=".";
}
temp.push_back(str);
}
return temp;
}
void backtracking(int n,vector<vector<int>>& use_loc,int depth,vector<bool>& used_column){
if(depth==n){
vector<string> temp;
temp=conver(use_loc,n);
result.push_back(temp);
return;
}
for(int i=0;i<n;i++){
if(used_column[i]) continue;//跳过用过的列
if(use_loc[depth][i]>0) continue;//跳过会被攻击的地方
use_loc[depth][i]=-1;//皇后
//下面每一层的对角线
for(int j=depth+1,k=i-1;j<n && k>=0;j++,k--){
use_loc[j][k]++;
}
for(int j=depth+1,k=i+1;j<n && k<n;j++,k++){
use_loc[j][k]++;
}
used_column[i]=true;
depth++;
backtracking(n,use_loc,depth,used_column);
depth--;
use_loc[depth][i]=0;
for(int j=depth+1,k=i-1;j<n && k>=0;j++,k--){
use_loc[j][k]--;
}
for(int j=depth+1,k=i+1;j<n && k<n;j++,k++){
use_loc[j][k]--;
}
used_column[i]=false;
}
}
vector<vector<string>> solveNQueens(int n) {
vector<vector<int>> use_loc(n,vector<int>(n,0));//全部初始化为0
vector<bool> used_column(n,false);//用过的列
backtracking(n,use_loc,0,used_column);
return result;
}
};
法二:改成下面这种判断上面的对角线中是否有皇后就会通过
class Solution {
public:
vector<vector<string>> result;
vector<vector<int>> use_loc;
vector<string> conver(vector<vector<int>>& use_loc,int n){
vector<string> temp;
for(int i=0;i<n;i++){
string str="";
for(int j=0;j<n;j++){
if(use_loc[i][j]==2){
str+="Q";
}
else str+=".";
}
temp.push_back(str);
}
return temp;
}
void backtracking(int n,vector<vector<int>>& use_loc,int depth,vector<bool>& used_column){
if(depth==n){
vector<string> temp;
temp=conver(use_loc,n);
result.push_back(temp);
return;
}
for(int i=0;i<n;i++){//i控制列
if(used_column[i]) continue;//跳过用过的列
if(use_loc[depth][i]==1) continue;//跳过会被攻击的地方
//下面每一层的对角线
bool r=false;
for(int j=depth-1,k=i+1;j>=0 && k<n;j--,k++){
if(use_loc[j][k]==2) r=true;
}
if(r) continue;
r=false;
for(int j=depth-1,k=i-1;j>=0 && k>=0;j--,k--){
if(use_loc[j][k]==2) r=true;
}
if(r) continue;
use_loc[depth][i]=2;//皇后
used_column[i]=true;
depth++;
backtracking(n,use_loc,depth,used_column);
//回溯
depth--;
use_loc[depth][i]=0;
// for(int j=depth+1,k=i-1;j=0;j++,k--){
// use_loc[j][k]=0;
// }
// for(int j=depth+1,k=i+1;j
// use_loc[j][k]=0;
// }
used_column[i]=false;
}
}
vector<vector<string>> solveNQueens(int n) {
vector<vector<int>> t(n,vector<int>(n,0));//全部初始化为0
use_loc=t;
vector<bool> used_column(n,false);//用过的列
backtracking(n,use_loc,0,used_column);
return result;
}
};
37. 解数独
c++
法一:回溯
踩坑记录:字符里面没有’10’,最高就是’9’
class Solution {
public:
bool isValid(int row,int col,char val,vector<vector<char>>& board){
for(int i=0;i<9;i++){//行
if(board[row][i]==val)
return false;
}
for(int i=0;i<9;i++){
if(board[i][col]==val) return false;
}
int startRow=(row/3)*3;
int startCol=(col/3)*3;
for(int i=startRow;i<startRow+3;i++){
for(int j=startCol;j<startCol+3;j++){
if(board[i][j]==val)
return false;
}
}
return true;
}
bool backtracking(vector<vector<char>>& board){
for(int i=0;i<board.size();i++){
for(int j=0;j<board[0].size();j++){
if(board[i][j]=='.') {
for(char k='1';k<='9';k++){//注意这里是<='9',不能写<'10',没有10这个字符
if(isValid(i,j,k,board)){
board[i][j]=k;
if(backtracking(board)) return true;
board[i][j]='.';
}
}
return false;//9个数都不对,返回false
}
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};
贪心算法
455. 分发饼干
c++
法一:小饼干先喂饱小胃口
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
sort(g.begin(),g.end());
sort(s.begin(),s.end());
int sum=0;
vector<bool> uset(s.size(),false);
for(int i=0;i<g.size();i++){
if(s.size()>0&&s.back()<g[i]) break;//如果s的最大值都小于孩子的胃口值,那直接退出循环
for(int j=0;j<s.size();j++){
if(uset[j]) continue;
if(s[j]>=g[i]){
sum++;
uset[j]=true;
break;
}
}
}
return sum;
}
};
376. 摆动序列
c++
**法一:贪心算法。**对于连续增长或连续递减的节点们应该怎么删除?保持这两个区间的端点,删掉其他的节点就可,所以只需要记录峰值个数就可以,但是需要处理最左边和最右边的节点。
保持区间波动,只需要把单调区间上的元素移除就可以了。
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
if(nums.size()<=1) return nums.size();
int preDiff=0;//把第一个节点的差值设为0
int curDiff=0;//当前节点和前一个节点的差值
int result=1;//包含了第一个节点
for(int i=1;i<nums.size();i++){
curDiff=nums[i]-nums[i-1];
if((curDiff>0&&preDiff<=0)||(curDiff<0&&preDiff>=0)){
result++;
preDiff=curDiff;//后面记录的pre一定不等于0,所以只有真的摆动时才会更新
}
}
return result;
}
};
法二:动态规划
设dp状态dp[i][0],表示考虑前i个数,第i个数作为山峰的摆动子序列的最长长度
设dp状态dp[i][1],表示考虑前i个数,第i个数作为山谷的摆动子序列的最长长度
dp[i][1]=max(dp[j][1],dp[j][0]+1):
情况一:第i个数取代第j个数作为山谷
情况二:第j个数作为山峰,第i个数作为山谷,那么最长长度应该是dp[j][0]+1
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
vector<vector<int>> dp(1001,vector<int>(2,1));
for(int i=1;i<nums.size();i++){
for(int j=0;j<i;j++){
if(nums[j]>nums[i]) dp[i][1]=max(dp[j][1],dp[j][0]+1);
}
for(int j=0;j<i;j++){
if(nums[j]<nums[i]) dp[i][0]=max(dp[j][0],dp[j][1]+1);
}
}
return max(dp[nums.size()-1][0],dp[nums.size()-1][1]);
}
};
53. 最大子数组和
c++
法一:暴力解法。设置两层循环,但是超过了时间限制
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int result = INT32_MIN;
int count = 0;
for (int i = 0; i < nums.size(); i++) { // 设置起始位置
count = 0;
for (int j = i; j < nums.size(); j++) { // 每次从起始位置i开始遍历寻找最大值
count += nums[j];
result = count > result ? count : result;
}
}
return result;
}
};
法二:贪心算法。当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。从而推出全局最优:选取最大“连续和”
其关键在于:不能让“连续和”为负数的时候加上下一个元素,而不是 不让“连续和”加上一个负数。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int result=INT_MIN;
int cout=0;//区间连续和
for(int i=0;i<nums.size();i++){
cout+=nums[i];
if(cout>result) result=cout;//取出最大连续和,不断调整终止位置
if(cout<0) cout=0;//如果出现负数,连续和清零,相当于不断调整区间起始位置
}
return result;
}
};
122. 买卖股票的最佳时机 II
c++
法一:贪心算法
class Solution {
public:
int maxProfit(vector<int>& prices) {
int result=0;
for(int i=0;i<prices.size();i++){
if(i>0&&prices[i]>prices[i-1]){//今天大于前一天就卖出
result+=(prices[i]-prices[i-1]);
}
}
return result;
}
};
55. 跳跃游戏
c++
法一:贪心
class Solution {
public:
bool canJump(vector<int>& nums) {
//能走到的位置处判断:当前位置元素值+当前位置下标值>=终点下标值
int cover=0;//能走到的覆盖范围
for(int i=0;i<=cover;i++){
cover=max(i+nums[i],cover);//及时更新覆盖范围
if(nums[i]+i+1>=nums.size()){
return true;
}
}
return false;
}
};
45. 跳跃游戏 II
c++
法一:贪心。在当前覆盖范围内的点:寻找下一个覆盖的更远的点
class Solution {
public:
int jump(vector<int>& nums) {
//当前覆盖范围内的点:寻找下一个覆盖的更远的点
int result=0;//跳跃次数
int curCover=0;//当前覆盖范围
int nextCover;//下一个点的覆盖范围
int index;
if(nums.size()==1) return 0;//特殊情况
for(int i=0;i<nums.size();){
curCover=nums[i];
nextCover=0;
result++;//不管当前点的覆盖范围有没有包含终点,步数都需要加一,所以nums的大小至少为2
if(curCover+i+1>=nums.size()){//说明当前覆盖范围已经到达终点
break;
}
//当前覆盖范围未到达终点
for(int j=1;j<=curCover;j++){//判断下一步的下标和覆盖范围
if(nextCover<nums[i+j]+i+j){
nextCover=nums[i+j]+i+j;
index=i+j;
}
}
i=index;//下一步的下标
}
return result;
}
};
法二:这种写法和法一思路一致,但是这种写法更加简便
class Solution {
public:
int jump(vector<int>& nums) {
int cover=0;//下一步所能覆盖的最远范围
int precover=0;//当前步所能跳到的最远距离
int ans=0;
// if(nums.size()==1) return 0;
for(int i=0;i<nums.size()-1;i++){
cover=max(cover,i+nums[i]);//一直在寻找最远范围
if(i==precover){//到达了当前步的最远距离
//更新下一步的覆盖范围,因为题目中说了可以到达,所以可以这样编写
ans++;
precover=cover;
}
}
return ans;
}
};
1005. K 次取反后最大化的数组和
法一:贪心算法 二刷写法:贪心思路 法一:贪心 写法二:对写法一进行改进 法一:贪心算法 c++ 法一:贪心 版本二:使用list,耗时更短 法一:贪心。先将气球直径按照开始的x坐标进行排序,再判断哪些气球具有交集,没有交集就更新新的开始直径范围,并且不断更新右边界 法一:贪心。先按照左边界从小到大进行排序 法一:和代码随想录一样 二刷写法:思路一致,但是写的复杂了一些。 法一:贪心 法一:暴力算法,超时 法二:贪心算法 法一:贪心。这道题不是很好理解,需要多思考思考 法一:贪心。大体思路就是从低到上,先给叶子节点的父节点放个摄像头,然后隔两个节点放一个摄像头,直至到二叉树头结点。 法一:使用递归 法二:动态规划 法一:动态规划 法二:动态规划完全背包 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划。 法一:动态规划 一维数组:每次循环在用下一个物品时使用的一维数组的各个值,就相当于二维数组时上一层的一行值,这里只是换成了一维数组,在遍历不同物品时不停地覆盖更改值 法一:动态规划一维数组,target为数组总和的一半,只要能找出子集和等于target的就符合要求 法一:动态规划。 法一:动态规划。 法一:动态规划 法一:动态规划完全背包 如果求组合数(没有顺序)就是外层for循环遍历物品,内层for遍历背包。 如果求排列数就是外层for遍历背包,内层for循环遍历物品。 法一:动态规划完全背包 法一:完全背包 法一:完全背包 写法二:物品重量就是i*i,不需要创建一个完全数数组 法一:完全背包 法一:动态规划 法一:动态规划 法一:动态规划+递归 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 所以:if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1); 只要i比之前的某个数大,就可以组成递增序列,再去判断和哪个数组成的递增序列的长度大 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 法一:动态规划 法一:动规 对以上代码进行优化:实际上在s[i-1]!=t[j-1]时只需要对t进行操作即可。 法一:动态规划 法一:动规 法一:动规 添加元素可以理解为删除另一个元素,删除元素就是dp[i-1][j]或者dp[i][j-1],删除某个元素可以理解成跳过该元素,继续下一个元素 替换就是dp[i - 1][j - 1] + 1 法一:动规 法一:动规
写法一:使用for循环,但是这种写法容易漏掉nums.size()class Solution {
public:
int largestSumAfterKNegations(vector<int>& nums, int k) {
//负数个数>k:找出最小的k个负数变成正数
//负数个数nclass Solution {
public:
int largestSumAfterKNegations(vector<int>& nums, int k) {
sort(nums.begin(),nums.end());
int sum=0;
for(int i=0;i<nums.size()&&k>0;i++,k--){
if(nums[i]<0) nums[i]=-nums[i];
else break;
}
for(int i=0;i<nums.size();i++){
sum+=nums[i];
}
if(k%2==0) return sum;
else{
//k为奇数,说明还需要操作
//先排序,对最小的数进行操作
sort(nums.begin(),nums.end());
sum-=nums[0];
nums[0]=-nums[0];
sum+=nums[0];
}
return sum;
}
};
134. 加油站
写法一:超出了时间限制class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升
//第 i+1 个加油站有汽油 gas[i+1] 升
//净含量=gas[i]-cost[i]>0的点才可以作为出发点
vector<int> temp;
vector<int> start_index;//出发点
if(gas.size()==1){
if(gas[0]-cost[0]>=0) return 0;
else return -1;
}//不能组成环路
for(int i=0;i<gas.size();i++){
if(gas[i]-cost[i]>0){
start_index.push_back(i);
}
temp.push_back(gas[i]-cost[i]);
}
if(start_index.size()==0) return -1;//没找到出发点
int sum=0;
int result;
for(int i=0;i<start_index.size();i++){//循环检查每个出发点
sum=0;
//检查是否能走完全程
for(int j=start_index[i];j<temp.size()+start_index[i];j++){
if(j<temp.size()) sum+=temp[j];
else sum+=temp[j-temp.size()];
if(sum<0) break;//小于零说明到不了下一个加油站
}
if(sum>=0) result=start_index[i];
}
return result;
}
};
利用cur来计算区间的净含量,如果一旦小于0,说明这个区间都不能作为出发点
因为一旦出现小于0的情况,那么一定是i这个位置的cur为负,才会出现这种情况,所以这个区间内的所有点都不能作为出发点class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
//从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升
//第 i+1 个加油站有汽油 gas[i+1] 升
//净含量=gas[i]-cost[i]>0的点才可以作为出发点
int cur=0;
int res_total=0;
int result=0;//这里必须初始化,如果cur一直大于0,那0号位置就是出发点
for(int i=0;i<gas.size();i++){
cur+=gas[i]-cost[i];
res_total+=(gas[i]-cost[i]);
if(cur<0){
result=i+1;
cur=0;
}
}
if(res_total<0) return -1;
return result;//净含量总量大于等于0,说明找到的出发点是能跑完全程的
}
};
135. 分发糖果
class Solution {
public:
int candy(vector<int>& ratings) {
int result=0;
vector<int> candyNum(ratings.size(),1);//先给每个孩子都分配一个糖果
if(ratings.size()==1) return 1;
//从前往后判断,遇到更高评分的就加一个糖果
for(int i=1;i<ratings.size();i++){
if(ratings[i]>ratings[i-1]){
candyNum[i]=candyNum[i-1]+1;
}
}
//从后往前进行判断
for(int i=ratings.size()-2;i>=0;i--){
if(ratings[i]>ratings[i+1]){
if(candyNum[i]<=candyNum[i+1])//判断糖果数是否满足要求
candyNum[i]=candyNum[i+1]+1;
}
}
//汇总
for(int i=0;i<candyNum.size();i++){
result+=candyNum[i];
}
return result;
}
};
860.柠檬水找零
法一:贪心class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
unordered_map<int,int> money{{5,0},{10,0},{20,0}};//第一位是钱的金额,第二位是钱的数量
for(int i=0;i<bills.size();i++){
if(bills[i]==5){
money[5]++;
}
if(bills[i]==10){
if(money[5]==0) return false;
else{
money[5]--;
money[10]++;
}
}
if(bills[i]==20){
if(money[10]>0&&money[5]>0){//优先消耗一个10和一个5,如果不够,再消耗三个5
money[5]--;
money[10]--;
money[20]++;
}
else if(money[10]==0&&money[5]>=3){
money[5]=money[5]-3;
money[20]++;
}
else return false;
}
}
return true;
}
};
406.根据身高重建队列
注意:类内sort自定义排序函数需定义为static否则报错。具体可见下面链接
类内sort自定义排序函数需定义为static否则报错
版本一:使用vectorclass Solution {
public:
static bool cmp(vector<int>& a,vector<int>& b){
if(a[0]==b[0]) return a[1]<b[1];//身高相同则k小的排前面
else return a[0]>b[0];//从高到矮进行排序
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
//身高矮的插在身高高的前面不会有影响
//所以先按照身高高矮进行排队,身高相同则k小的排前面
sort(people.begin(),people.end(),cmp);
vector<vector<int>> que;
//按照k进行插入,k就相当于要插入的下标
for(int i=0;i<people.size();i++){
int index=people[i][1];
que.insert(que.begin()+index,people[i]);
}
return que;
}
};
注意:使用list时,不能直接用迭代器+几个的写法,因为链表里面的地址不是连续的// 版本二
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
static bool cmp(const vector<int>& a, const vector<int>& b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list<vector<int>>::iterator it = que.begin();
while (position--) { // 寻找在插入位置
it++;
}
que.insert(it, people[i]);
}
return vector<vector<int>>(que.begin(), que.end());
}
};
452. 用最少数量的箭引爆气球
class Solution {
public:
static bool cmp(vector<int>& a,vector<int>& b){
return a[0]<b[0];
}
int findMinArrowShots(vector<vector<int>>& points) {
//算交集
sort(points.begin(),points.end(),cmp);
int result=points.size();//假设所有气球都没有交集
vector<int> start=points[0];
for(int i=1;i<points.size();i++){
if(points[i][0]>start[1]){
//没有交集
start=points[i];
}
else{//有交集
start[1]=start[1]>points[i][1]?points[i][1]:start[1];//更新直径共同范围的end,取二者最小值
result--;
};
}
return result;
}
};
435. 无重叠区间
class Solution {
public:
static bool cmp(vector<int>& a,vector<int>& b){
return a[0]<b[0];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
//后边界和前边界重叠不算重叠
//选定start后将和start有重叠的区间全算作一整块,看一共有多少块就是最小数量
//因为只要这些区间划分为一块了,那么这一块的区间只能留一个区间下来了
sort(intervals.begin(),intervals.end(),cmp);
int result=0;
vector<int> start=intervals[0];
for(int i=1;i<intervals.size();i++){
if(intervals[i][0]>=start[1]){
//第i个区间至少和前面界定的重叠区间内的区间内的一个区间(具有最小右边界的区间)不重叠
start=intervals[i];
}
else{//有重叠
start[1]=min(start[1],intervals[i][1]);//更新最小右边界
result++;//移除区间的数量
}
}
return result;
}
};
二刷写法:
和上一题其实类似的写法,先算出有多少个交集(注意这道题对重叠的定义和上一题有点不一样),再用减法就能求出答案class Solution {
public:
bool static cmp(vector<int> &a ,vector<int> &b){
return a[0]<b[0];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),cmp);
int start=intervals[0][0];
int end=intervals[0][1];
int result=1;
for(int i=1;i<intervals.size();i++){
if(intervals[i][0]<end){//有交集
start=intervals[i][0];
if(intervals[i][1]<end) end=intervals[i][1];
continue;
}
//无交集
start=intervals[i][0];
end=intervals[i][1];
result++;
}
return intervals.size()-result;
}
};
763.划分字母区间
区间内的字符出现最远下标就是最终的右边界了,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
注意:string里面的单个字符是用单引号表示class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> result;
int farthest_pos[26]={0};//每个字母在s中出现的最远位置
int right=0;
int left=0;
for(int i=0;i<s.size();i++){
farthest_pos[s[i]-'a']=i;
}
for(int i=0;i<s.size();i++){
right=max(right,farthest_pos[s[i]-'a']);
if(right==i){
result.push_back(right-left+1);
left=i+1;
}
}
return result;
}
};
这个写法每次都要再循环一遍区间的所有字符然后利用match_s函数再从后到前循环去找最远字符,其实这样会重复很多次,不如一刷写法简便class Solution {
public:
static int match_s(const string &s,const char &st){
for(int i=s.size()-1;i>=0;i--){
if(s[i]==st) return i;
}
return -1;
}
vector<int> partitionLabels(string s) {
vector<int> result;
int start=0;
int end=0;
while(end!=s.size()-1){
int temp=match_s(s,s[start]);//第一个字母匹配到的最远的字母下标
if(temp==s.size()-1){
result.push_back(temp-start+1);
break;
}
//寻找区间内的最远下标
for(int i=start+1;i<temp;i++){
int k=match_s(s,s[i]);
if(k>temp) temp=k;
}
//更新结果和边界
end=temp;
result.push_back(end-start+1);
start=end+1;
}
return result;
}
};
56. 合并区间
class Solution {
public:
static bool cmp(vector<int>& a,vector<int>& b){
return a[0]<b[0];
}
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),cmp);//按开始坐标从小到大进行排序
vector<vector<int>> result;
if(intervals.size()==0) return result;
result.push_back(intervals[0]);
for(int i=1;i<intervals.size();i++){
if(intervals[i][0]<=result[result.size()-1][1]){
//有重叠
//每次合并都取最大的右边界!而不是取新区间的右边界
//排序只是按照左边界进行排序的,右边界不一定
result[result.size()-1][1]=max(result[result.size()-1][1],intervals[i][1]);
}
else{//没有重叠
result.push_back(intervals[i]);
}
}
return result;
}
};
738. 单调递增的数字
class Solution {
public:
bool isValid(int n){
vector<int> num;
while(n){
if(num.size()>0&&(n%10>num.back())) return false;
num.push_back(n%10);//放入最后一位数字
n=n/10;
}
return true;
}
int monotoneIncreasingDigits(int n) {
while(n){
if(isValid(n)) return n;
n--;
}
return n;
}
};
class Solution {
public:
int monotoneIncreasingDigits(int n) {
string strNum = to_string(n);
int index;//开始赋'9'的下标起始位置
for(int i=strNum.size()-1;i>0;i--){
if(strNum[i]<strNum[i-1]){
index=i;
strNum[i-1]--;
}
}
for(int i=index;i<strNum.size();i++){
strNum[i]='9';
}
return stoi(strNum);
}
};
714. 买卖股票的最佳时机含手续费
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int result = 0;
int minPrice = prices[0]; // 记录最低价格
for (int i = 1; i < prices.size(); i++) {
//prices[i] + fee相当于是股票的成本价格
// 情况二:相当于买入
//经过情况一的minPrice = prices[i] - fee操作后,这里的判断条件相当于是prices[i]+fee<之前的prices,相当于此时卖出会亏,买也很便宜,所以适合买入。算上手续费已经不盈利了,所以适合在此时的点买入
if (prices[i] < minPrice) minPrice = prices[i];//此时相当于下一轮买入了
// 情况三:保持原有状态(因为此时买则不便宜,卖则亏本)
if (prices[i] >= minPrice && prices[i] <= minPrice + fee) {
continue;
}
// 计算利润,可能有多次计算利润,最后一次计算利润才是真正意义的卖出
//必须要大于买入价格+手续才能有正利润
if (prices[i] > minPrice + fee) {//因为后面minPrice= prices[i] - fee,所以这里需要加上fee进行对比,相当于和原始prices进行对比
result += prices[i] - minPrice - fee;
minPrice = prices[i] - fee; // 情况一,这一步很关键。避免多减去手续费
}
}
return result;
}
};
968.监控二叉树
class Solution {
public:
int result=0;
int tranversel(TreeNode* cur){
//0:无覆盖
//1:摄像头
//2:有覆盖
if(cur==NULL) return 2;//空节点设为有覆盖的状态,因为叶子节点不放摄像头
int left=tranversel(cur->left);
int right=tranversel(cur->right);
if(left==2&&right==2) return 0;
if(left==0||right==0){
//左右节点至少有一个未覆盖的情况
result++;
return 1;//安装摄像头
}
if(left==1||right==1) return 2;
return -1;
}
int minCameraCover(TreeNode* root) {
if(tranversel(root)==0) result++;
return result;
}
};
动态规划
509. 斐波那契数
class Solution {
public:
int add_recur(int n){
if(n==0) return 0;
if(n==1) return 1;
return add_recur(n-1)+add_recur(n-2);
}
int fib(int n) {
return add_recur(n);
}
};
class Solution {
public:
int fib(int n) {
if(n<=1) return n;//注意必须加上这个
vector<int> dp(n+1);
dp[0]=0;
dp[1]=1;
for(int i=2;i<n+1;i++){
dp[i]=dp[i-1]+dp[i-2];
}
return dp[n];
}
};
70. 爬楼梯
class Solution {
public:
int climbStairs(int n) {
if (n <= 1) return n; // 因为下面直接对dp[2]操作了,防止空指针
vector<int> dp(n + 1);
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) { // 注意i是从3开始的
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
};
class Solution {
public:
int climbStairs(int n) {
vector<int> dp(n+1,0);
dp[0]=1;
for(int j=1;j<=n;j++){
for(int i=1;i<3;i++){
if(j>=i) dp[j]+=dp[j-i];
}
}
return dp.back();
}
};
746. 使用最小花费爬楼梯
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
vector<int> dp(cost.size()+1);
dp[0]=0;
dp[1]=0;
for(int i=2;i<=cost.size();i++){
dp[i]=min(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2]);
}
return dp.back();
}
};
62.不同路径
class Solution {
public:
int uniquePaths(int m, int n) {
//当前位置路径总和=左边方块的路径数+上面方块的路径数
//第1行和第1列只有左边或者上面的路径数
// if(m==1||n==1) return 1;//下面的初始化已经考虑到这种情况了
int dp[m][n];
dp[0][0]=0;
for(int i=0;i<m;i++) dp[i][0]=1;
for(int i=0;i<n;i++) dp[0][i]=1;
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
}
return dp[m-1][n-1];
}
};
63. 不同路径 II
有障碍的话,其实就是标记对应的dp table(dp数组)保持初始值(0)就可以了。class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m=obstacleGrid.size();//行数
int n=obstacleGrid[0].size();//列数
vector<vector<int>> dp(m,vector<int>(n,0));
for(int i=0;i<m;i++){
if(obstacleGrid[i][0]==1) break;//遇到了障碍物,退出循环
dp[i][0]=1;
}
for(int i=0;i<n;i++){
if(obstacleGrid[0][i]==1) break;
dp[0][i]=1;
}
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
if(obstacleGrid[i][j]==1) continue;//遇到障碍物,继续下一个位置
dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
}
return dp[m-1][n-1];
}
};
343. 整数拆分
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。class Solution {
public:
int integerBreak(int n) {
//dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
vector<int> dp(n+1,1);
for(int i=3;i<=n;i++){
for(int j=1;j<=i/2;j++){
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));//记得和dp[i]进行对比,因为这是循环,前面也找过拆分i的最大值,所以需要全局对比
}
}
return dp[n];
}
};
96.不同的二叉搜索树
实际上就是求不同搜索树的数量,不用把具体的节点值都列出来class Solution {
public:
int numTrees(int n) {
//i个不同元素节点组成的二叉搜索树的个数为dp[i]
vector<int> dp(n+1);
dp[0]=1;
for(int i=1;i<=n;i++){
for(int j=1;j<=i;j++){//j-1相当于是左子树节点树,i-1-(j-1)=右子树节点
//左子树和右子树分别有多少个节点
dp[i]+=dp[j-1]*dp[i-j];//i为根节点,还剩下i-1个节点
}
}
return dp.back();
}
};
0-1背包理论基础
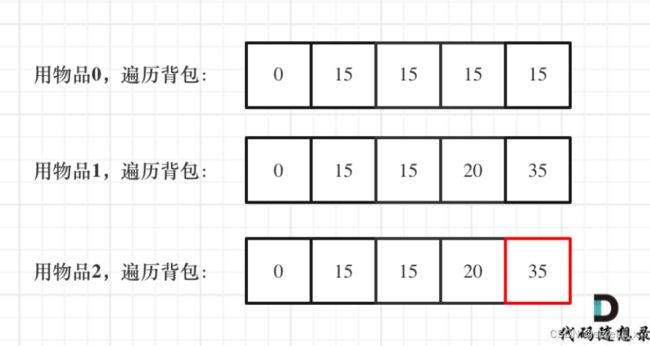
void test_1_wei_bag_problem() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
// 初始化
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
int main() {
test_1_wei_bag_problem();
}
416. 分割等和子集
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum=0;
vector<int> dp(10001,0);
for(int i=0;i<nums.size();i++){
sum+=nums[i];
}
if (sum%2==1) return false;
int target=sum/2;
for(int i=0;i<nums.size();i++){
for(int j=target;j>=nums[i];j--){
dp[j]=max(dp[j],dp[j-nums[i]]+nums[i]);
}
}
if(dp[target]==target) return true;
return false;
}
};
1049. 最后一块石头的重量 II
本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。class Solution {
public:
int lastStoneWeightII(vector<int>& stones) {
vector<int> dp(1501,0);
int target=0;
int sum=0;
for(int i=0;i<stones.size();i++){
sum+=stones[i];
}
target=sum/2;
for(int i=0;i<stones.size();i++){
for(int j=target;j>=stones[i];j--){
dp[j]=max(dp[j],dp[j-stones[i]]+stones[i]);
}
}
return sum-dp[target]-dp[target];
}
};
494. 目标和
dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法
dp[j] += dp[j - nums[i]]
dp[j]=不需要num[i]就能够凑出j的情况(nums[i-1]对应的dp[j])+需要num[i]凑出j空间的情况
第一个循环在遍历物品,前面已经遍历过的物品都可以放入背包中,在不同的背包容量下,方法各是多少种class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum=0;
for(int i=0;i<nums.size();i++) sum+=nums[i];
if(abs(target)>sum) return 0;
if((target+sum)%2==1) return 0;
int bagSize=(target+sum)/2;
vector<int> dp(bagSize+1,0);
dp[0]=1;
for(int i=0;i<nums.size();i++){
for(int j=bagSize;j>=nums[i];j--){
dp[j]+=dp[j-nums[i]];
}
}
return dp.back();
}
};
474.一和零
实际上还是01背包,只是物品的重量有两个维度class Solution {
public:
int findMaxForm(vector<string>& strs, int m, int n) {
vector<vector<int>> dp(m+1,vector<int>(n+1,0));
for(string str:strs){//遍历物品
int zeroNum=0;
int oneNum=0;
for(char c:str){
if(c=='0') zeroNum++;
else oneNum++;
}
//遍历背包,两个维度先后顺序无所谓
for(int i=m;i>=zeroNum;i--){//背包的容量必须要>=物品重量
for(int j=n;j>=oneNum;j--){
dp[i][j]=max(dp[i][j],dp[i-zeroNum][j-oneNum]+1);
}
}
}
return dp[m][n];
}
};
518. 零钱兑换 II
dp[0]=1还说明了一种情况:如果正好选了coins[i]后,也就是j-coins[i] == 0的情况表示这个硬币刚好能选,此时dp[0]为1表示只选coins[i]存在这样的一种选法。
注意:
外层for循环遍历物品(钱币),内层for遍历背包(金钱总额):得到组合数
外层for循环遍历背包(金钱总额),内层循环遍历物品(钱币):得到排列数class Solution {
public:
int change(int amount, vector<int>& coins) {
vector<int> dp(amount+1,0);//dp[i]代表可以凑成背包容量为i的总组合数
dp[0]=1;//后面需要累加,所以初始化为1
for(int i=0;i<coins.size();i++){//遍历物品
for(int j=coins[i];j<=amount;j++){
dp[j]+=dp[j-coins[i]];
}
}
return dp.back();
}
};
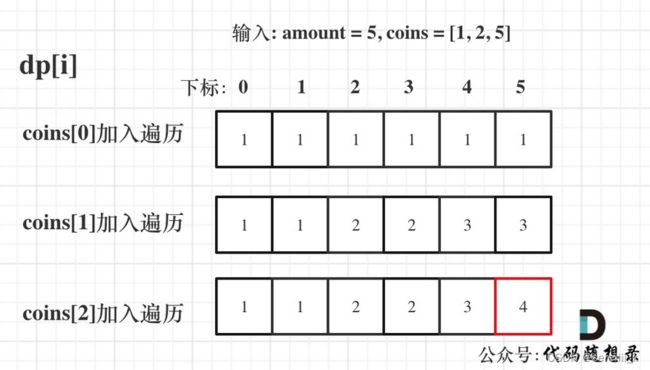

可以这样想:先遍历背包容量再遍历各个物品时,每个物品只要可以放进背包都会被循环一遍,当背包容量增加时,上一次循环过的物品还可以再次循环,这样就有相同的一些数字形成不同的组合,比如当j=3时,1和2在j=2和j=3时都可以装进背包,所以就会出现{1,2}和{2,1}。377. 组合总和 Ⅳ
踩坑记录:题目数据保证答案符合 32 位整数范围,但是dp数组中间的某些值可能会超过INT_MAX,既然答案不会超过,那就说明答案不会用到这些位置的数。C++测试用例有两个数相加超过int的数据,所以需要在if里加上dp[i] < INT_MAX - dp[i - num]。class Solution {
public:
int combinationSum4(vector<int>& nums, int target) {
vector<long long int> dp(target+1,0);
dp[0]=1;
for(int j=0;j<=target;j++){
for(int i=0;i<nums.size();i++){
if(j>=nums[i]&& dp[j]+dp[j-nums[i]]<INT_MAX) dp[j]+=dp[j-nums[i]];
}
}
return dp.back();
}
};
322. 零钱兑换
踩坑记录:必须加INT_MAX的判断,不然+1就会溢出class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount+1,INT_MAX);
dp[0]=0;
for(int i=0;i<coins.size();i++){
for(int j=coins[i];j<=amount;j++){//完全背包正序遍历
if(dp[j-coins[i]]!=INT_MAX)
dp[j]=min(dp[j],dp[j-coins[i]]+1);
}
}
if(dp.back()==INT_MAX) return -1;
else return dp.back();
}
};
279.完全平方数
class Solution {
public:
int numSquares(int n) {
vector<int> nums;//完全平方数数组
for(int i=1;i<=100;i++){
nums.push_back(i*i);
}
vector<int> dp(n+1,INT_MAX);
dp[0]=0;
for(int i=0;i<nums.size();i++){
for(int j=nums[i];j<=n;j++){
if(dp[j-nums[i]]!=INT_MAX)
dp[j]=min(dp[j],dp[j-nums[i]]+1);
}
}
return dp.back();
}
};
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i * i <= n; i++) { // 遍历物品
for (int j = i * i; j <= n; j++) { // 遍历背包
dp[j] = min(dp[j - i * i] + 1, dp[j]);
}
}
return dp[n];
}
};
139. 单词拆分
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
//完全背包、排列问题
//dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词
vector<bool> dp(s.size()+1,false);
dp[0]=true;
for(int j=1;j<=s.size();j++){//先遍历背包
for(int i=0;i<j;i++){ //遍历物品
string str=s.substr(i,j-i);
//看单词是否出现在字典里
if(find(wordDict.begin(),wordDict.end(),str)!=wordDict.end()&&dp[i])//vector没有find内置函数
dp[j]=true;
}
}
return dp.back();
}
};
198. 打家劫舍
class Solution {
public:
int rob(vector<int>& nums) {
if(nums.size()==1) return nums[0];
vector<int> dp(nums.size(),0);
dp[0]=nums[0];
dp[1]=max(nums[0],nums[1]);
for(int i=2;i<nums.size();i++){
dp[i]=max(dp[i-2]+nums[i],dp[i-1]);
}
return dp.back();
}
};
213. 打家劫舍 II
首尾元素只能存在一个,所以可以分开考虑去求解两种情况的打劫最大值

class Solution {
public:
int rob(vector<int>& nums) {
//不考虑尾元素
if(nums.size()==1) return nums[0];
if(nums.size()==2) return max(nums[0],nums[1]);
vector<int> dp1(nums.size()-1,0);
dp1[0]=nums[0];
dp1[1]=max(nums[0],nums[1]);
for(int i=2;i<nums.size()-1;i++){
dp1[i]=max(dp1[i-2]+nums[i],dp1[i-1]);
}
//不考虑首元素
vector<int> dp2(nums.size()-1,0);
dp2[0]=nums[1];
dp2[1]=max(nums[1],nums[2]);
for(int i=2;i<nums.size()-1;i++){
dp2[i]=max(dp2[i-2]+nums[i+1],dp2[i-1]);//注意这种dp的定义下这里的nums是错位的
}
return max(dp1.back(),dp2.back());
}
};
337. 打家劫舍 III
刚开始想的是用层序遍历,每一层相当于一个屋子,前后相邻屋子不能一起打劫,但是这种想法是有问题的,一层的节点不一定全部要打劫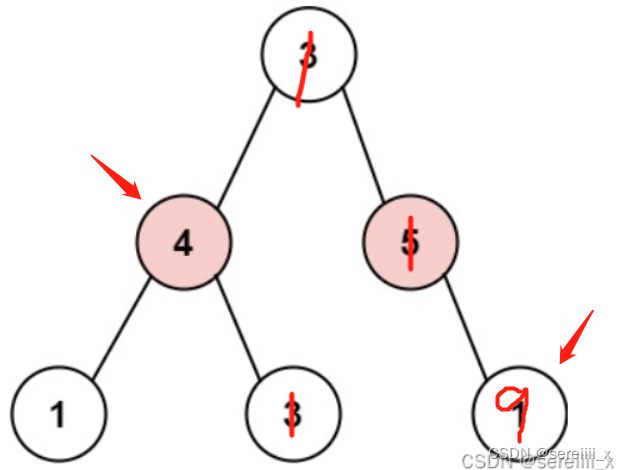
class Solution {
public:
int rob(TreeNode* root) {
//层次遍历,相邻屋子不能一起打劫
vector<int> result=robTree(root);
return max(result[0],result[1]);
}
//返回长度为2的vector数组:0为不偷,1为偷
vector<int> robTree(TreeNode* cur){
if(cur==NULL) return {0,0};
vector<int> left=robTree(cur->left);
vector<int> right=robTree(cur->right);
int val1=cur->val+left[0]+right[0];//当前节点偷
int val2=max(left[0],left[1])+max(right[0],right[1]);//当前节点不偷
return {val2,val1};
}
};
121. 买卖股票的最佳时机
用二维数组来表示每一天的股票持有或者不持有所得最高现金
dp[i][0]:持有股票,相当于记录了1-i天中的股票最低价
dp[i][1]:不持有股票,相当于记录了1-i天中的最高利润class Solution {
public:
int maxProfit(vector<int>& prices) {
int len=prices.size();
vector<vector<int>> dp(len,vector<int>(2));//有len个二维数组
dp[0][0]=-prices[0];//持有股票
dp[0][1]=0;//不持有股票
for(int i=1;i<len;i++){
dp[i][0]=max(dp[i-1][0],-prices[i]);
dp[i][1]=max(prices[i]+dp[i-1][0],dp[i-1][1]);//不持有股票,相当于卖出
}
return dp[len-1][1];
}
};
122.买卖股票的最佳时机II
dp[i - 1][1] - prices[i]:表示买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格。只有昨天不持有股票,今天才可以买入class Solution {
public:
int maxProfit(vector<int>& prices) {
int len=prices.size();
vector<vector<int>> dp(len,vector<int>(2));//有len个二维数组
dp[0][0]=-prices[0];//持有股票
dp[0][1]=0;//不持有股票
for(int i=1;i<len;i++){
dp[i][0]=max(dp[i-1][0],dp[i-1][1]-prices[i]);//持有股票
dp[i][1]=max(prices[i]+dp[i-1][0],dp[i-1][1]);//不持有股票,相当于卖出
}
return dp[len-1][1];
}
};
123.买卖股票的最佳时机III
class Solution {
public:
int maxProfit(vector<int>& prices) {
// 1-第一次持有股票
// 2-第一次不持有股票
// 3-第二次持有股票
// 4-第二次不持有股票
int len=prices.size();
if(len==0) return 0;
vector<vector<int>> dp(len,vector<int>(5,0));
dp[0][1]=-prices[0];
dp[0][3]=-prices[0];
for(int i=1;i<len;i++){
dp[i][1]=max(dp[i-1][1],-prices[i]);//前期已经买入或者在第i天买入
dp[i][2]=max(dp[i-1][2],dp[i-1][1]+prices[i]);//前期已经卖出或者在第i天卖出
dp[i][3]=max(dp[i-1][3],dp[i-1][2]-prices[i]);//前期已经买入或者在第i天买入第二股,那么上一个状态一定是第一次不持有股票
dp[i][4]=max(dp[i-1][4],dp[i-1][3]+prices[i]);//前期已经卖出或者在第i天卖出
}
return dp[len-1][4];
}
};
188.买卖股票的最佳时机IV
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
//1第一次持股,2第一次不持股,3第二次持股,4第二次不持股,i(奇数)第(i+1)/2次持股
int len=prices.size();
vector<vector<int>> dp(len,vector<int>(2*k+1,0));
for(int i=1;i<2*k+1;i++){
if(i%2==1){
dp[0][i]=-prices[0];//初始化,在第0天就持股的最大金额
}
}
for(int i=1;i<len;i++){
for(int j=1;j<2*k+1;j++){
if(j%2==1){
//持股
dp[i][j]=max(dp[i-1][j-1]-prices[i],dp[i-1][j]);
}
else{//不持股
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1]+prices[i]);
}
}
}
return dp[len-1][2*k];
}
};
309.最佳买卖股票时机含冷冻期
踩坑记录:max只能比较两个数,所以三个数的比较需要使用max嵌套class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
if (n == 0) return 0;
vector<vector<int>> dp(n, vector<int>(4, 0));
dp[0][0] -= prices[0]; // 持股票
for (int i = 1; i < n; i++) {
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
dp[i][2] = dp[i - 1][0] + prices[i];
dp[i][3] = dp[i - 1][2];
}
return max(dp[n - 1][3],max(dp[n - 1][1], dp[n - 1][2]));
}
};
714.买卖股票的最佳时机含手续费
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
//0持有股票,1不持有
int len = prices.size();
if(len==0) return 0;
vector<vector<int>> dp(len,vector<int>(2,0));
dp[0][0]=-prices[0];
for(int i=1;i<len;i++){
dp[i][0]=max(dp[i-1][0],dp[i-1][1]-prices[i]);
dp[i][1]=max(dp[i-1][1],dp[i-1][0]+prices[i]-fee);//减掉手续费
}
return dp[len-1][1];
}
};
300.最长递增子序列
dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度
位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
if(nums.size()<=1) return nums.size();
vector<int> dp(nums.size(),1);
int result=0;
for(int i=1;i<nums.size();i++){
for(int j=0;j<i;j++){
if(nums[i]>nums[j]){
dp[i]=max(dp[i],dp[j]+1);
}
}
if(dp[i]>result) result=dp[i];
}
return result;
}
};
674. 最长连续递增序列
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
vector<int> dp(nums.size(),1);
dp[0]=1;
int result=1;
for(int i=1;i<nums.size();i++){
if(nums[i]>nums[i-1]){
dp[i]=dp[i-1]+1;
}
if(result<dp[i]) result=dp[i];
}
return result;
}
};
718. 最长重复子数组
dp[i][j]:以i结尾的nums1和以j结尾的nums2的最长公共子数组长度
这里的子数组是连续的class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
// dp[i][j]:以i结尾的nums1和以j结尾的nums2的最长公共子数组长度
vector<vector<int>> dp(nums1.size(),vector<int>(nums2.size(),0));
int result=0;
// 要对第一行,第一列经行初始化
// 初始化里面如果出现了相等的数,那result记得初始化为1
for (int i = 0; i < nums1.size(); i++){
if (nums1[i] == nums2[0]){
dp[i][0] = 1;
result=1;
}
}
for (int j = 0; j < nums2.size(); j++) {
if (nums1[0] == nums2[j]){
dp[0][j] = 1;
result=1;
}
}
for(int i=1;i<nums1.size();i++){
for(int j=1;j<nums2.size();j++){
if(nums1[i]==nums2[j]){
dp[i][j]=dp[i-1][j-1]+1;
}
if(dp[i][j]>result) result=dp[i][j];
}
}
return result;
}
};
1143.最长公共子序列
和上一题区别在于这里不一定连续class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
//dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
vector<vector<int>> dp(text1.size()+1,vector<int>(text2.size()+1,0));
int result=0;
for(int i=1;i<=text1.size();i++){
for(int j=1;j<=text2.size();j++){
if(text1[i-1]==text2[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}
else{//不相等的话字符串倒退一个取最大值
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
if(dp[i][j]>result) result=dp[i][j];
}
}
return result;
}
};
1035.不相交的线
和1143是一个道理,其实就是求最长公共子序列class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
//dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j]
vector<vector<int>> dp(nums1.size()+1,vector<int>(nums2.size()+1,0));
int result=0;
for(int i=1;i<=nums1.size();i++){
for(int j=1;j<=nums2.size();j++){
if(nums1[i-1]==nums2[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}
else{//不相等的话字符串倒退一个取最大值
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[nums1.size()][nums2.size()];
}
};
53. 最大子数组和
dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
所以最大子数组不一定是以最后一个元素为结尾,可能在中间出现class Solution {
public:
int maxSubArray(vector<int>& nums) {
// dp[i]:包括下标i(以nums[i]为结尾)的最大连续子序列和为dp[i]。
vector<int> dp(nums.size(),0);
dp[0]=nums[0];
int result=dp[0];
for(int i=1;i<nums.size();i++){
dp[i]=max(dp[i-1]+nums[i],nums[i]);
if(dp[i]>result) result=dp[i];
}
return result;
}
};
392. 判断子序列
实际就是求求最长公共子序列长度
将1143的代码搬过来再做长度判断就可以AC了
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。class Solution {
public:
bool isSubsequence(string s, string t) {
if(s.size()>t.size()) return false;
//可以转换成求最长公共子序列长度
// dp[i][j]:长度为[0, i-1]的字符串s与长度为[0, j-1]的字符串t的最长公共子序列为dp[i][j]
vector<vector<int>> dp(s.size()+1,vector<int>(t.size()+1,0));
int result=0;
for(int i=1;i<=s.size();i++){
for(int j=1;j<=t.size();j++){
if(s[i-1]==t[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}
else{
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
if(dp[i][j]>result) result=dp[i][j];
}
}
if(result==s.size()) return true;
else return false;
}
};
dp[i][j] = dp[i][j - 1]相当于删除了t[j-1],这里的删除可以理解成跳过了t[j-1]class Solution {
public:
bool isSubsequence(string s, string t) {
if(s.size()>t.size()) return false;
//可以转换成求最长公共子序列长度
// dp[i][j]:长度为[0, i-1]的字符串s与长度为[0, j-1]的字符串t的最长公共子序列为dp[i][j]
vector<vector<int>> dp(s.size()+1,vector<int>(t.size()+1,0));
int result=0;
for(int i=1;i<=s.size();i++){
for(int j=1;j<=t.size();j++){
if(s[i-1]==t[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}
else{
dp[i][j]=dp[i][j-1];//这里只对t进行删除
}
if(dp[i][j]>result) result=dp[i][j];
}
}
if(result==s.size()) return true;
else return false;
}
};
115. 不同的子序列
只在s中进行删除操作
需要理解 dp[i][j]=dp[i-1][j] 表示不用s[i-1]去匹配
注意位数那里还是需要加判断,不然会溢出,跟之前做过的一道题类似
[c++]-uint8_t,uint16_t,uint32_t,uint64_t代表含义及其标准定义
INT_MAX和INT_MIN的定义及使用(含溢出问题)class Solution {
public:
int numDistinct(string s, string t) {
if(s.size()<t.size()) return 0;
// dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
//初始化
for(int i=0;i<=s.size();i++) dp[i][0]=1;
for(int i=1;i<=t.size();i++) dp[0][i]=0;
for(int i=1;i<=s.size();i++){
for(int j=1;j<=t.size();j++){
if(s[i-1]==t[j-1]&&dp[i-1][j-1]+dp[i-1][j]<INT_MAX){
dp[i][j]=dp[i-1][j-1]+dp[i-1][j];
}
else dp[i][j]=dp[i-1][j];//不用s[i-1]去匹配
}
}
return dp[s.size()][t.size()];
}
};
583. 两个字符串的删除操作
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
dp[i][j]=min(dp[i-1][j]+1,dp[i][j-1]+1):看下面的图,比如sea和ea达到相等,删除一个元素(dp[i][j-1]);se和eat达到相等需要删除3个元素,那么当循环到最右下角时,a和t不相等,那么sea和ea达到相等,再删掉不相等的t就可以达到相等,同理删掉a也是这样,再取最小值就行

class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for(int i=0;i<=word1.size();i++) dp[i][0]=i;
for(int i=0;i<=word2.size();i++) dp[0][i]=i;
for(int i=1;i<=word1.size();i++){
for(int j=1;j<=word2.size();j++){
if(word1[i-1]==word2[j-1]){
dp[i][j]=dp[i-1][j-1];//不做任何删除操作
}
else{
dp[i][j]=min(dp[i-1][j]+1,dp[i][j-1]+1);//删除word1[i - 1]或word2[j - 1]
}
}
}
return dp[word1.size()][word2.size()];
}
};
72. 编辑距离
添加元素可以理解为删除另一个元素,删除元素就是dp[i-1][j]或者dp[i][j-1],替换就是dp[i - 1][j - 1] + 1class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for(int i=0;i<=word1.size();i++) dp[i][0]=i;
for(int i=0;i<=word2.size();i++) dp[0][i]=i;
for(int i=1;i<=word1.size();i++){
for(int j=1;j<=word2.size();j++){
if(word1[i-1]==word2[j-1]){
dp[i][j]=dp[i-1][j-1];//不做任何删除操作
}
else{
dp[i][j]=min(dp[i-1][j],min(dp[i][j-1],dp[i-1][j-1]))+1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
编辑距离总结篇
647. 回文子串
class Solution {
public:
int countSubstrings(string s) {
// dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result=0;
for(int i=s.size()-1;i>=0;i--){
for(int j=i;j<s.size();j++){
if(s[i]==s[j]){
if(j-i<=1){//一个或两个长度大小的字符串
dp[i][j]=true;
result++;
}
else{
if(dp[i+1][j-1]){//这里的if可以和else合并
dp[i][j]=true;
result++;
}
}
}
}
}
return result;
}
};
516.最长回文子序列
和647题的区别在于这题不一定是连续的class Solution {
public:
int longestPalindromeSubseq(string s) {
// dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j]。
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for(int i=0;i<s.size();i++) dp[i][i]=1;
for(int i=s.size()-1;i>=0;i--){
for(int j=i+1;j<s.size();j++){
if(s[i]==s[j]){
dp[i][j]=dp[i+1][j-1]+2;
}
else dp[i][j]=max(dp[i+1][j],dp[i][j-1]);
}
}
return dp[0][s.size()-1];
}
};