Flink-Flink新闻数仓实时项目(新闻指标计算、Flink知识的练手小项目)
新闻实时项目
1 项目需求分析和架构设计
- 背景
某新闻网站每天会曝光很多新闻话题,当用户浏览网站的新闻时会产生大量的访问日志。为了更好的分析用户行为,并对舆情进行监控,现在需要实现一个新闻热搜实时分析系统。
- 需求
(1)采集搜狗新闻网站用户浏览日志信息。
(2)统计分析搜狗排名最高的前10名新闻话题。分组聚合后求前10
(3)统计分析每天哪些时段用户浏览新闻量最高。分组聚合后求max
(4)统计分析每天曝光搜狗新闻话题总量。
- 架构
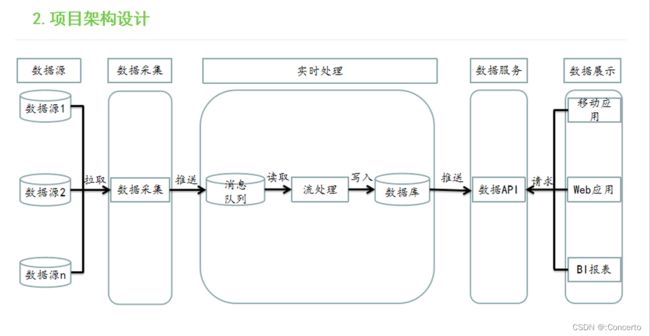
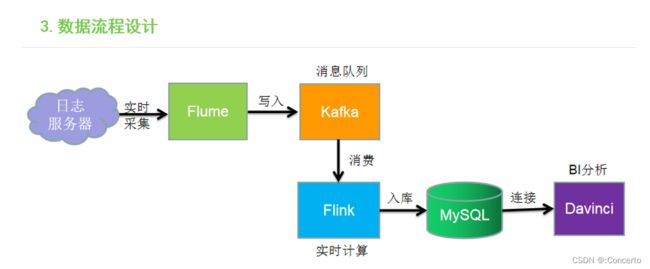
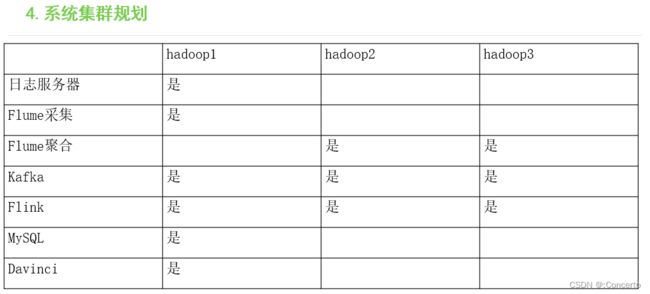

- 操作
- mysql建库
[root@hadoop1 ~]# mysql -h hadoop1 -u hive -phive
CREATE DATABASE `news` CHARACTER SET utf8 COLLATE utf8_general_ci;
- 建表
mysql> use news;
mysql> create table newscount(
-> name varchar(50) not null,
-> count int(11) not null
-> );
mysql> create table periodcount(
-> logtime varchar(50) not null,
-> count int(11) not null
-> );
2 项目步骤
2.1 统计话题访问量
- 代码
public class KafkaFlinkMySQL {
public static void main(String[] args) throws Exception {
//获取flink执行环境
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.getConfig().setAutoWatermarkInterval(200);
//配置kafka集群参数
Properties prop = new Properties();
prop.setProperty("bootstrap.servers","hadoop1:9092,hadoop2:9092,hadoop3:9092");
prop.setProperty("group.id","sougoulogs");
//读取kafka数据
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<String>("sougoulogs",new SimpleStringSchema(),prop);
DataStream<String> stream = senv.addSource(myConsumer);
//数据过滤
DataStream<String> filter = stream.filter((value)->value.split(",").length==6);
//统计新闻话题访问量
DataStream<Tuple2<String,Integer>> newsCounts = filter.flatMap(new lineSplitter())
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> t) throws Exception {
return t.f0;
}
}).sum(1);
newsCounts.print();
//数据入库MySQL
newsCounts.addSink(new MySQLSink());
//统计每个时段新闻话题访问量
DataStream<Tuple2<String,Integer>> periodCounts =filter.flatMap(new lineSplitter2())
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> t) throws Exception {
return t.f0;
}
}).sum(1);
periodCounts.addSink(new MySQLSink2());
//执行flink程序
senv.execute("KafkaFlinkMySQL");
}
public static final class lineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>>{
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] tokens = s.split(",");
collector.collect(new Tuple2<>(tokens[2],1));
}
}
public static final class lineSplitter2 implements FlatMapFunction<String, Tuple2<String,Integer>>{
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] tokens = s.split(",");
collector.collect(new Tuple2<>(tokens[0],1));
}
}
}
- mysql 配置
public class GlobalConfig {
public static final String DRIVER_CLASS="com.mysql.jdbc.Driver";
public static final String DB_URL="jdbc:mysql://hadoop1:3306/live?useUnicode=true&characterEncoding=UTF8&useSSL=false";
public static final String USER_MAME = "hive";
public static final String PASSWORD = "hive";
public static String AUDITINSERTSQL = "insert into auditcount (time,audit_type,province_code,count) VALUES (?,?,?,?) ON DUPLICATE KEY UPDATE time=VALUES(time),audit_type=VALUES(audit_type),province_code=VALUES(province_code),count=VALUES(count)";
}
- mysql自定义的MySQLSink
public class MySQLSink extends RichSinkFunction<Tuple2<String,Integer>> {
private Connection conn;
private PreparedStatement statement;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName(GlobalConfig.DRIVER_CLASS);
conn = DriverManager.getConnection(GlobalConfig.DB_URL,GlobalConfig.USER_MAME,GlobalConfig.PASSWORD);
}
//关闭资源来着
@Override
public void close() throws Exception {
if(statement !=null){
statement.close();
}
if(conn!=null){
conn.close();
}
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
try {
//去掉[]
String name = value.f0.replaceAll("[\\[\\]]", "");
int count = value.f1;
System.out.println("name="+name+":count="+count);
//指定sql
String sql = "select 1 from newscount " + " where name = '" + name + "'";
String updateSql = "update newscount set count = " + count + " where name = '" + name + "'";
String insertSql = "insert into newscount(name,count) values('" + name + "'," + count + ")";
statement = conn.prepareStatement(sql);
ResultSet rs = statement.executeQuery();
if (rs.next()) {
//如果查询有数据,那就更新
statement.executeUpdate(updateSql);
} else {
//如果查询没有数据,那就插入
statement.execute(insertSql);
}
//捕捉异常
}catch (Exception e){
e.printStackTrace();
}
}
}
- mysql自定义的MysqlSink2
public class MySQLSink2 extends RichSinkFunction<Tuple2<String,Integer>> {
private Connection conn;
private PreparedStatement statement;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName(GlobalConfig.DRIVER_CLASS);
conn = DriverManager.getConnection(GlobalConfig.DB_URL,GlobalConfig.USER_MAME,GlobalConfig.PASSWORD);
}
@Override
public void close() throws Exception {
if(statement !=null){
statement.close();
}
if(conn!=null){
conn.close();
}
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
try {
String logtime = value.f0;
int count = value.f1;
String sql = "select 1 from periodcount " + " where logtime = '" + logtime + "'";
String updateSql = "update periodcount set count = " + count + " where logtime = '" + logtime + "'";
String insertSql = "insert into periodcount(logtime,count) values('" + logtime + "'," + count + ")";
statement = conn.prepareStatement(sql);
ResultSet rs = statement.executeQuery();
if (rs.next()) {
//更新
statement.executeUpdate(updateSql);
} else {
//插入
statement.execute(insertSql);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
- 模拟数据输入
public class AnalogData {
/**
* 读取文件数据
* @param inputFile
*/
public static void readData(String inputFile,String outputFile) throws FileNotFoundException, UnsupportedEncodingException {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
String tmp = null;
try {
fis = new FileInputStream(inputFile);
isr = new InputStreamReader(fis,"GBK");
br = new BufferedReader(isr);
//计数器
int counter=1;
//按行读取文件数据
while ((tmp = br.readLine()) != null) {
//打印输出读取的数据
System.out.println("第"+counter+"行:"+tmp);
//数据写入文件
writeData(outputFile,tmp);
counter++;
//方便观察效果,控制数据参数速度
Thread.sleep(1000);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (isr != null) {
try {
isr.close();
} catch (IOException e1) {
}
}
}
}
/**
* 文件写入数据
* @param outputFile
* @param line
*/
public static void writeData(String outputFile, String line) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(outputFile, true)));
out.write("\n");
out.write(line);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 主方法
* @param args
*/
public static void main(String args[]){
String inputFile = args[0];
String outputFile = args[1];
try {
readData(inputFile,outputFile);
}catch(Exception e){
}
}
}
2.2 代码运行测试
- shell脚本
[hadoop@hadoop1 bin]$ vi common.sh
#!/bin/sh
env=$1
#切换到当前目录的父目录
home=$(cd `dirname $0`; cd ..; pwd)
bin_home=$home/bin
conf_home=$home/conf
logs_home=$home/logs
data_home=$home/data
lib_home=$home/lib
脚本授权
[hadoop@hadoop1 bin]$ chmod u+x sougou.sh
脚本执行
[hadoop@hadoop1 bin]$ ./sougou.sh src dest
- linux操作
启动MySQL服务
[root@hadoop1 ~]# service mysqld start
启动Zookeeper集群
[hadoop@hadoop1 zookeeper]$ bin/zkServer.sh start
[hadoop@hadoop2 zookeeper]$ bin/zkServer.sh start
[hadoop@hadoop3 zookeeper]$ bin/zkServer.sh start
启动Kafka集群
[hadoop@hadoop1 kafka]$ bin/kafka-server-start.sh config/server.properties
[hadoop@hadoop2 kafka]$ bin/kafka-server-start.sh config/server.properties
[hadoop@hadoop3 kafka]$ bin/kafka-server-start.sh config/server.properties
#创建topic
[hadoop@hadoop1 kafka]$ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic sogoulogs --replication-factor 3 --partitions 3
模拟产生数据
[hadoop@hadoop1 shell]$ bin/sougou.sh /home/hadoop/shell/data/sogou.log /home/hadoop/data/flume/logs/sogou.log
- flume配置
启动Flume聚合服务
[hadoop@hadoop2 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-kafka.properties -Dflume.root.logger=INFO,console
[hadoop@hadoop3 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-kafka.properties -Dflume.root.logger=INFO,console
启动Flume采集服务
[hadoop@hadoop1 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/taildir-file-selector-avro.properties -Dflume.root.logger=INFO,console
2.3 过程
flume采集,负载均衡到hadoop2以及hadoop3,然后写入kafka集群,flinkstream进行实时消费,最终落盘mysql,然后可视化展出
对Flink不是很熟的小伙伴,可以看下之前写的Flink文章,参照着知识点去看会比较方便点