NoSQLBooster4MongoDB - 用SQL查询MongoDB
最好的MongoDB的客户端工具–NoSQLBooster。NoSQLBooster立志做“The Smartest IDE for MongoDB”。
使用 mb.runSQLQuery()方法,能把SQL语句翻译成MongoDB的查询语句.
借助适用于 MongoDB 的 NoSQLBooster,您可以针对 MongoDB 运行 SQL SELECT 查询。 SQL 支持包括函数、表达式、具有嵌套对象和数组的集合的聚合。 请参阅 NoSQLBooster for MongoDB 支持的 功能和 SQL 示例。
让我们看看如何在 SQL 中将 GROUP BY 子句与 SUM 函数一起使用。
而不是编写表示为类似 JSON 结构的 MongoDB 查询
db.employees.aggregate([
{
$group: {
_id: "$department",
total: { $sum: "$salary" }
},
}
])
您可以使用您可能已经知道的 SQL 查询 MongoDB。
mb.runSQLQuery(`
SELECT department, SUM(salary) AS total FROM employees GROUP BY department
`);
再来看一个比较复杂的SQL语句,看看NoSQLBooster是怎么翻译的:
等效的 MongoDB SQL查询:
select CITY as CITY_NAME, count(*) as COUNT_STORE, sum(AVGSCORE) as AVG_SCORE, sum(AVGPRICE) as AVG_PRICE
from
store_detail_info
where
CITY_NAME in ("上海", "北京", "广州")
group by
CITY_NAME
order by
COUNT_STORE desc
到 MongoDB Script:
db.store_detail_info.aggregate([{
$addFields: {
CITY_NAME: "$CITY"
}
}, {
$match: {
CITY_NAME: {
$in: ["上海", "北京", "广州"]
}
}
}, {
$group: {
_id: {
CITY_NAME: "$CITY_NAME"
},
COUNT_STORE: {
$sum: NumberInt(1)
},
AVG_SCORE: {
$sum: "$AVGSCORE"
},
AVG_PRICE: {
$sum: "$AVGPRICE"
}
}
}, {
$project: {
CITY_NAME: "$_id.CITY_NAME",
COUNT_STORE: "$COUNT_STORE",
AVG_SCORE: "$AVG_SCORE",
AVG_PRICE: "$AVG_PRICE"
}
}, {
$sort: {
COUNT_STORE: -1
}
}])
特性
- 通过 SQL 访问数据,包括 WHERE 过滤器、ORDER BY、GROUP BY、HAVING、DISTINCT、LIMIT
- SQL 函数(COUNT、SUM、MAX、MIN、AVG)
- SQL 函数(日期、字符串、转换)
- SQL Equi JOIN 和不相关子查询
- 聚合管道运算符作为 SQL 函数(dateToString、toUpper、split、substr …)
- 提供可以集成到您的脚本中的编程接口(mb.runSQLQuery)
- 关键字、MongoDB 集合名称、字段名称和 SQL 函数的自动完成
注意: MongoDB 本身不支持 SQL 功能。 SQL 查询经过验证并转换为 MongoDB 查询,并由 NoSQLBooster for MongoDB 执行。 可以在
console.log选项卡中查看等效的 MongoDB 查询。
应该提到的是,在左下角的“Samples”窗格中有一个关于 NoSQLBooster SQL Query for MongoDB 的教程。 通过本教程,您可以学习和理解如何使用 NoSQLBooster SQL Query for MongoDB。 更好的是,所有 SQL 函数都提供适当的代码片段和鼠标悬停信息并支持代码完成。

开始
例如,员工集合有以下字段,包括number、first_name、last_name、salary、department 和hire_date。
准备演示数据
将以下演示数据插入 MongoDB。 打开 shell 选项卡Ctrl-T并执行以下脚本以获取员工集合。
db.employees.insert([
{"number":1001,"last_name":"Smith","first_name":"John","salary":62000,"department":"sales", hire_date:ISODate("2016-01-02")},
{"number":1002,"last_name":"Anderson","first_name":"Jane","salary":57500,"department":"marketing", hire_date:ISODate("2013-11-09")},
{"number":1003,"last_name":"Everest","first_name":"Brad","salary":71000,"department":"sales", hire_date:ISODate("2017-02-03")},
{"number":1004,"last_name":"Horvath","first_name":"Jack","salary":42000,"department":"marketing", hire_date:ISODate("2017-06-01")},
])
选择所有字段
首先,单击员工集合,然后单击选项卡工具栏中的“SQL 查询选项卡”或使用Ctrl-Alt-T键盘快捷键。 自动为我们生成基本的“SELECT * from employees”! NoSQLBooster for MongoDB 还提供了一个“runSQLQuery”代码片段。 只需键入片段前缀“run”,然后按“tab”即可插入该片段。

只需单击执行按钮或使用“Ctrl-↵”键盘快捷键即可执行查询。This would produce the result, as shown below.
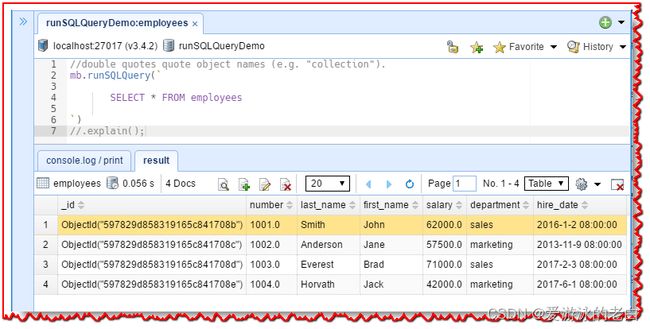
- NoSQLBooster for MongoDB 在结果树视图中提供就地编辑。 双击任何值或数组元素进行编辑。 按
Esc返回之前的值并退出编辑器。 - 如果您不想直接编辑结果,可以通过单击工具栏的锁定按钮使用**“只读”**模式。
选择单个字段和字段名称自动完成
让我们获取 employees 表中可用员工的 first_name、last_name 和 salary 字段,并按薪水降序对结果进行排序。
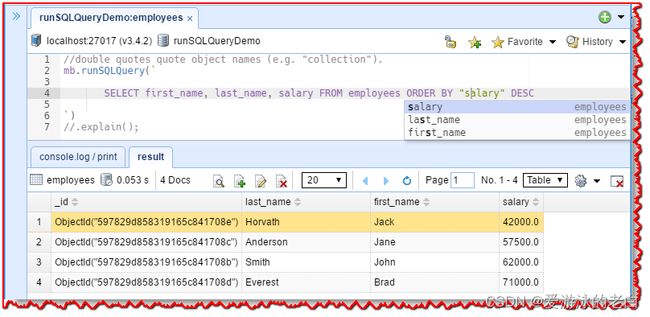
内置的SQL语言服务知道所有可能的补全、SQL函数、关键字、MongoDB集合名和字段名。当你打字时,智能提示就会弹出。你可以用Ctrl-Shift-Space手动触发它。开箱即用,Ctrl-Space, Alt-Space也是可以接受的触发器。
查看等效的 MongoDB 查询
如何显示等效的 MongoDB 查询?
- 方法一:开启Verbose Shell选项,Main Menu->Options -> Verbose Shell(setVerboseShell)
- 方法 2:单击编辑器工具栏右上角的**“Code”按钮**以显示等效的 MongoDB 查询。

如您所知,NoSQLBooster for MongoDB 支持mongoose-like fluent Query API,点击“Menu-> Options -> Translate SQL to MongoDB Shell Script”,点击“Translate SQL to NoSQLBooster for MongoDB Fluent API”。 重新执行脚本,等效的流畅 MongoDB 查询将显示在“console.log/print”选项卡中。

使用字符串和日期 SQL 函数
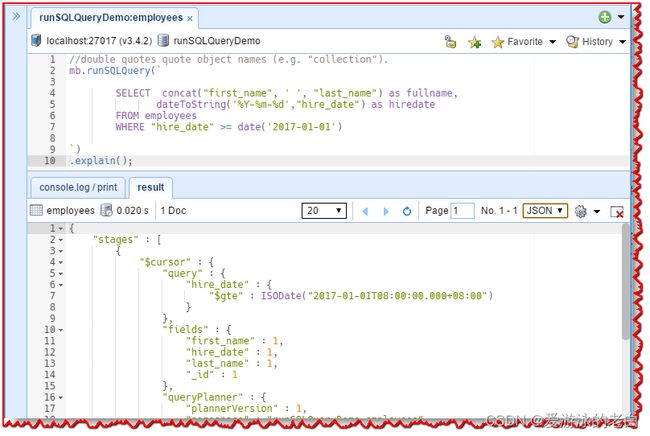
这次,我们要查找今年雇用的所有员工,并将 first_name 和 last_name 显示为全名。 请输入以下SQL语句并点击执行按钮:
SELECT concat("first_name", ' ', "last_name") as fullname,
dateToString('%Y-%m-%d',"hire_date") as hiredate
FROM employees
WHERE "hire_date" >= date('2017-01-01')
单击“console.log/print”选项卡以显示等效的 MongoDB 查询:
db.employees.aggregate(
[{
"$match": {
"hire_date": {
"$gte": ISODate("2017-01-01T08:00:00.000+08:00")
}
}
},
{
"$project": {
"fullname": {
"$concat": [
"$first_name",
" ",
"$last_name"
]
},
"hiredate": {
"$dateToString": {
"format": "%Y-%m-%d",
"date": "$hire_date"
}
}
}
}
])

让我们看看 concat 函数 concat(“first_name”, ’ ', “last_name”)。 concat 函数是一个 MongoDB 字符串聚合运算符。 通过将 SQL 函数映射到 MongoDB 运算符,NoSQLBooster for MongoDB 允许您在 SQL 语句中将所有 MongoDB 聚合运算符用作 SQL 函数。
// instead of writing
{ $concat: [ "$first_name", " ", "last_name" ] }
// we write,
concat("first_name", ' ', "last_name") //Double quotes quote field name, Single quotes are for strings
// or
concat(first_name, ' ', last_name) //allow to omit double quotes
- MongoDB 运算符和集合字段名称没有
$前缀。 - 双引号引用字段名。 单引号用于字符串。
- 除了 COUNT、SUM、MAX、MIN、AVG 之外,所有函数名称都区分大小写。
- 我们可以使用标准的 SQL 比较运算符:
=、!=、<>、<、<=、>= 或 >。
日期函数将字符串转换为 MongoDB 日期类型。 NoSQLBooster for MongoDB 使用 Moment.js 来解析日期字符串。 从字符串创建日期时,Moment.js 首先检查字符串是否与已知的 ISO 8601 格式匹配,然后 Moment.js 检查字符串是否与 RFC 2822 日期时间格式匹配,然后再返回 new Date(string) 如果找不到已知格式。
请参考Moment.js解析字符串文档查看所有支持的字符串格式。
# An ISO 8601 string requires a date part.
2013-02-08 # A calendar date part
#A time part can also be included, separated from the date part by a space or an uppercase T.
2013-02-08 09:30 # An hour and minute time part
2013-02-08 09:30:26 # An hour, minute, and second time part
#If a time part is included, an offset from UTC can also be included as +-HH:mm, +-HHmm, +-HH or Z.
2017-01-01T08:00:00.000+08:00
2013-02-08 09+07:00 # +-HH:mm
2013-02-08 09:30:26.123+07:00 # +-HH:mm
dateToString 是另一个 MongoDB 日期运算符,用于根据用户指定的格式将日期对象转换为字符串。 $dateToString 表达式具有以下语法:
{ $dateToString: { format: <formatString>, date: <dateExpression> } }
由于 SQL 函数不支持 JSON 对象参数,NoSQLBooster for MongoDB 将对象参数转换为普通参数列表。
dateToString('%Y-%m-%d',"hire_date") as hiredate
第一个参数是formatString,单引号,第二个参数是“Date Field”,双引号。
请点击此链接 了解有关 MongoDB 日期聚合运算符的更多信息。
一个日期范围的例子:
#----The equivalent MongoDB Query:----
#From SQL:
select * from my_events where dateTime >= date('2022-06-10T17:00:00.000Z') and dateTime <= date('2022-06-20T11:00:00.000Z')
#To MongoDB Script:
db.my_events.aggregate([{
$match: {
$and: [{
dateTime: {
$gte: ISODate("2022-06-10T17:00:00.000Z")
}
}, {
dateTime: {
$lte: ISODate("2022-06-20T11:00:00.000Z")
}
}]
}
}])
引用名称和字符串值
在 NoSQLBooster 中,我们遵循 ANSI SQL 标准。 单引号分隔字符串常量或日期/时间常量。 双引号分隔标识符,例如集合名称或列名称。 通常仅当您的标识符不符合简单标识符的规则时才需要这样做。
以下 SQL 语句从“employees”集合中的部门“sales”中选择所有客户:
SELECT * FROM employees WHERE department='sales';
等效的 MongoDB 查询
db.employees.find({
"department": "sales"
})
单引号用于字符串。 如果您将“sales”加双引号,MongoDB 的 NoSQLBooster 会将其视为列“sales”,而不是字符串“sales”。
SELECT * FROM employees WHERE department="sales";
SQL 生成了您可能不需要的以下 MongoDB 查询。
db.employees.aggregate(
[{
"$addFields": {
"__tmp_cond_1": {
"$eq": [
"$department",
"$sales"
]
}
}
},
{
"$match": {
"__tmp_cond_1": true
}
},
{
"$project": {
"__tmp_cond_1": 0
}
}
])
提示: 坚持使用单引号。
解释查询的数据
只需在 mb.runSQLQuery 的末尾添加一个新行“.explain()”,然后再次单击执行按钮。 它返回有关管道处理的信息。
查询特殊的 BSON 数据类型,UUID,BinData,DBRef …
要查询这些特定BSON数据类型的值,请像在MongoDB shell中那样写入这些值。所有MongoDB内置的数据类型函数都可用。
--date
SELECT * FROM collection WHERE date_field >= date("2018-02-09T00:00:00+08:00")
SELECT * FROM collection WHERE date_field >= ISODate("2018-02-09")
--number
SELECT * FROM collection WHERE int64_field >= NumberLong("3223123123122132992")
SELECT * FROM collection WHERE decimal_field = NumberDecimal("8989922322323232.12")
--Regular Expression
SELECT * FROM collection WHERE string_field = RegExp('query','i')
--binary
SELECT * FROM collection WHERE objectId_field = ObjectId("56034dae9b835b3ee6a52cb7")
SELECT * FROM collection WHERE binary_field = BinData(0,"X96v3g==")
SELECT * FROM collection WHERE md5_field = MD5("f65485ac0686409aabfa006f0c771fbb")
SELECT * FROM collection WHERE hex_field = HexData(0,"00112233445566778899aabbccddeeff")
--uuid
SELECT * FROM collection WHERE uuid_field = UUID("4ae5bfce-1dba-4776-80eb-17678822b94e")
SELECT * FROM collection WHERE luuid_field = LUUID("8c425c91-6a72-c25c-1c9d-3cfe237e7c92")
SELECT * FROM collection WHERE luuid_field = JSUUID("8c425c91-6a72-c25c-1c9d-3cfe237e7c92")
SELECT * FROM collection WHERE luuid_field = CSUUID("6a72c25c-5c91-8c42-927c-7e23fe3c9d1c")
SELECT * FROM collection WHERE luuid_field = PYUUID("5cc2726a-915c-428c-927c-7e23fe3c9d1c")
--timstamp
SELECT * FROM collection WHERE timestamp_field = Timestamp(1443057070, 1)
--symbol
SELECT * FROM collection WHERE symbol_field = Symbol('I am a symbol')
--dbref
SELECT * FROM collection WHERE dbref_field = DBRef("unicorns", ObjectId("55f23233edad44cb25b0d51a"))
--minkey maxkey
SELECT * FROM collection WHERE minkey_field = MinKey and maxkey_field = MaxKey
--array, array_field is [1, 2, '3']
SELECT * FROM collection WHERE array_field = [1,2,'3']
--object, object_field is { a : 1, b : {b1 : 2, b2 : "b2"}
SELECT * FROM collection WHERE object_field = toJS(a=1, b=toJS(b1=2, b2='b2'))
访问数组和嵌入式文档
支持嵌套文档(子文档)和数组,包括过滤器和表达式。 您可以使用带点的名称访问此类字段。
例如集合中的以下文档:
db.survey.insert([
{ _id: 1, results: [ { product: "abc", score: 10 }, { product: "xyz", score: 5 } ]},
{ _id: 2, results: [ { product: "abc", score: 8 }, { product: "xyz", score: 7 } ]},
{ _id: 3, results: [ { product: "abc", score: 7 }, { product: "xyz", score: 8 } ]}
])
“product”和“score”将分别作为 “results.product” 和 “results.score” 引用:
SELECT * FROM survey WHERE results.product = 'xyz' AND results.score >= 8;
或者
SELECT * FROM survey WHERE "results.product" = 'xyz' AND "results.score" >= 8;
与嵌入文档的元素匹配
elemMatch 查询条件 (score >=8) 将被翻译为 "score": { "$gte": 8 }。 这种语法更加简洁和表达。
-- Enter "elemMatch [Tab]", to trigger auto-complete
SELECT * FROM survey WHERE "results" =elemMatch(product='xyz', score >=8)
SQL 相等连接(多表关联查询)
假设 有 订单集合, 存储的测试数据 如下:
db.lookup_orders.insert([
{ "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2 },
{ "_id" : 2, "item" : "pecans", "price" : 20, "quantity" : 1 },
{ "_id" : 3 }
])
其中 item 对应 数据为 商品名称。
另外 一个 就是就是 商品库存集合 ,存储的测试数据 如下:
db.lookup_inventory.insert([
{ "_id" : 1, "sku" : "almonds", description: "product 1", "instock" : 120 },
{ "_id" : 2, "sku" : "bread", description: "product 2", "instock" : 80 },
{ "_id" : 3, "sku" : "cashews", description: "product 3", "instock" : 60 },
{ "_id" : 4, "sku" : "pecans", description: "product 4", "instock" : 70 },
{ "_id" : 5, "sku": null, description: "Incomplete" },
{ "_id" : 6 }
])
此集合中的 sku 数据等同于 订单 集合中的 商品名称。
在这种模式设计下,如果要查询订单表对应商品的库存情况,应如何写代码呢?
很明显这需要两个集合Join。
场景简单,不做赘述,直送答案 。其语句 如下:
#----The equivalent MongoDB Query:----
#From SQL:
SELECT * FROM lookup_orders
JOIN lookup_inventory ON lookup_orders.item=lookup_inventory.sku
#To MongoDB Script:
db.lookup_orders.aggregate([{
$lookup: {
from: "lookup_inventory",
localField: "item",
foreignField: "sku",
as: "lookup_inventory_docs"
}
}, {
$match: {
lookup_inventory_docs: {
$ne: []
}
}
}, {
$addFields: {
lookup_inventory_docs: {
$arrayElemAt: ["$lookup_inventory_docs", 0]
}
}
}, {
$replaceRoot: {
newRoot: {
$mergeObjects: ["$lookup_inventory_docs", "$$ROOT"]
}
}
}, {
$project: {
lookup_inventory_docs: 0
}
}])
“toJS”SQL 函数和命名参数
“toJS”辅助函数将命名参数和算术运算符转换为 JSON 对象,还将普通参数列表转换为数组。
toJS(k='v'); //result {k:'v'}
toJS(k="v"); //result {k:'$v'}, Double quotes quote object names
toJS(k=v); //result {k:'$v'}, without quote, v is a object name
toJS(k>5, k<=10); //result { "k": { "$gt": 5, "$lte": 10} }
toJS(a=1, b=toJS(b1=2, b2='b2')); //result {a : 1, b : {b1 : 2, b2 : "b2"}
toJS(1, 2,'3'); // result [1,2,'3'];
使用命名参数和“toJS”辅助函数,您可以查询复杂对象或将 JSON 对象参数传递给 SQL 函数。
--elemMatch, named parameter and Arithmetic operators
--cool stuff, (score>8, score<=10) will be translated as {"score": { "$gt": 8, "$lte": 10 }}
SELECT * FROM survey WHERE results =elemMatch(item='abc', score>8, score<=10)
--date timezone, named parameter
SELECT year(date="date", timezone='America/Chicago') as year FROM sales
--query object type value, object_field: { a : 1, b : {b1 : 2, b2 : "b2"}
SELECT * FROM collection WHERE object_field = toJS(a=1, b=toJS(b1=2, b2='b2'))
-- text search with full-text search options
SELECT * FROM article WHERE
$text = toJS($search='cake', $language='en', $caseSensitive=false, $diacriticSensitive=false)
SELECT literal(toJS(k>5, k<=10)) FROM collection
Mixed-use of SQL and Chainable Aggregation Pipeline
MongoDB的NoSQLBooster将SQL转换为MongoDB find/aggregate方法,该方法返回一个AggregateCursor。所有的MongoDB游标方法和MongoDB的NoSQLBooster扩展方法都可以调用。这还允许NoSQLBooster智能感知了解AggregateCursor的所有可链阶段方法。(sort, limit, match, project, unwind…)
mb.runSQLQuery(`
SELECT * FROM "survey" where type='ABC' and year(date) = 2018 ORDER BY "results.score" DESC
`)
.unwind('$tags')
.project("-_id") //alias select
.limit(1000)
The equivalent MongoDB Query is a bit longer.
db.survey.aggregate(
[
{
"$addFields" : {
"year(date)" : {
"$year" : "$date"
}
}
},
{
"$match" : {
"type" : "ABC",
"year(date)" : 2018
}
},
{
"$project" : {
"year(date)" : 0
}
},
{
"$sort" : {
"results.score" : -1
}
},
{
"$unwind" : "$tags"
},
{
"$project" : {
"_id" : 0
}
},
{
"$limit" : 1000
}
])
将 SQL 查询保存为 MongoDB 只读视图
您可以使用扩展方法“saveAsView”将 SQL 查询结果保存为 MongoDB 只读视图。
//double quotes quote object names (e.g. "collection"). Single quotes are for strings 'string'.
mb.runSQLQuery("
SELECT concat(first_name, ' ', last_name) as fullname,
dateToString('%Y-%m-%d',hire_date) as hiredate
FROM employees
WHERE hire_date >= date('2017-01-01')
").saveAsView("Employers_hired_after_2017", {dropIfExists:true}) //drop view if it exists.
您还可以使用 forEach 方法将 javascript 方法应用于每个文档。
mb.runSQLQuery("SELECT * FROM employees WHERE hire_date >= date('2017-01-01')")
.forEach(it=>{
//sendToMail(it)
});
SQL 片段
NoSQLBooster 包含许多 SQL 特定的代码片段以节省您的时间、日期范围、文本搜索、查询和数组、存在性检查、类型检查等。 您始终可以使用 Ctrl-Shift-Space 手动触发它。 开箱即用,Ctrl-Space、Alt-Space 是可接受的触发器。
SQL 日期范围片段
-- Enter "daterange [Tab]," then..., today, yesterday, lastNDays
SELECT * FROM collection WHERE
"|" >= date("2018-02-09T00:00:00+08:00") and "|" < date("2018-02-10T00:00:00+08:00")
文本搜索片段
-- Enter "text [Tab]", then...
SELECT * FROM collection WHERE $text = toJS($search='|')
-- Enter "textopt [Tab]", then...
-- with full-text search options
SELECT * FROM collection WHERE
$text = toJS($search='|', $language='en', $caseSensitive=false, $diacriticSensitive=false)
等效的 MongoDB 文本搜索
db.collection.find({
"$text": {
"$search": "|",
"$language": "en",
"$caseSensitive": false,
"$diacriticSensitive": false
}
})
查询数组($all 和 $elemMatch)片段
$elemMatch 运算符匹配包含数组字段的文档,该数组字段至少有一个元素匹配所有指定的查询条件。
- 与嵌入文档的元素匹配
elemMatch 查询条件 (quantity>2, quantity<=10) 将被翻译为 "quantity": { "$gt": 2, "$lte": 10 }。 这种语法更加简洁和表达。
-- Enter "elemem [Tab]", then...
SELECT * FROM survey WHERE "|" =elemMatch(product='abc', quantity>2, quantity<=10)
The equivalent MongoDB Query
db.survey.find({
"|": {
"$elemMatch": {
"product": "abc",
"quantity": {
"$gt": 2,
"$lte": 10
}
}
}
})
- 元素匹配
-- Enter "elem [Tab]", then...
SELECT * FROM survey WHERE "score" =elemMatch($gte=80, $lte=85)
The equivalent MongoDB Query
db.survey.find({
"score": {
"$elemMatch": {
"$gte": 80,
"$lte": 85
}
}
})
$all数组操作符选择字段值为包含所有指定元素的数组的文档。
-- Enter "all [Tab]", then...
SELECT * FROM survey WHERE "|" = toJS($all=['', ''])
存在检查和类型检查片段
- 存在检查 ($exists)
-- Enter "exists [Tab]", then...
SELECT * FROM collection WHERE "|" =$exists(TRUE)
-- Enter "nonExist [Tab]", then...
SELECT * FROM collection WHERE "|" = $exists(FALSE)
-- Enter "existAndIsNull [Tab]", then...
SELECT * FROM collection WHERE "|" = $exists(TRUE) and "|" IS NULL
-- Enter "existAndIsNotNull [Tab]", then...
SELECT * FROM collection WHERE "|" = $exists(TRUE) and "|" IS NOT NULL
- 按多种数据类型查询 ($type)
-- Enter "typeSearch [Tab]", then...
SELECT * FROM collection WHERE "|" = toJS($type=['double','int','string','bool','date','object','array','null'])
小技巧
如果你用的是免费版,禁止把翻译的Script来拷贝,该怎么办?!别着急,运行成功后,点击下面的"Console"标签就能看到所有的内容!入下图所示:

这样你就可以把翻译前后的内容拷贝粘贴了!
<<<<<<<<<<<< [完] >>>>>>>>>>>>