【C语言】你知道.c文件是如何变成.exe文件的吗
文章目录
从Hello World说起
1、翻译环境
1.1准备阶段
1.2预编译
1.2.1预编译
1.2.2查看生成文件
1.2.3比较
1.2.4扩展
1.3编译
1.3.1编译
1.3.2符号汇总
1.3.3和预编译的比较
1.4汇编
1.4.1汇编
1.4.2生成符号表
1.5链接
1.5.1关于段表
1.5.2合并段表
1.5.3符号表的合并和重定位
2.运行
3.多个.c文件的问题
3.1新增一个文件
3.2两个文件共同经历翻译环境
3.3错误示例
从Hello World说起
毫无疑问,“Hello World”对于程序员来说肯定是如雷贯耳。就是这样一个简单的程序,带领了无数的人进入了程序的世界。简单的事物背后往往又蕴涵着复杂的机制,如果我们深入思考--个简单的“Hello World”程序,就会发现很多问题看似很简单,但实际上我们并没有一个非常清晰的思路;或者在我们脑海里有着模糊的印象,但真正到某些细节的时候可能又模糊不清了。比如对于C语言编写的Hello World程序:
#include
int main()
{
printf("Hello World!");
return 0;
} 对于下面这些问题,你的脑子里能够马上反应出一个很清晰又很明确的答案吗?
· 程序为什么要被编译器编译了之后才可以运行?
· 编译器在把C语言程序转换成可以执行的机器码的过程中做了什么,怎么做的?
· 最后编译出来的可执行文件里面是什么?除了机器码还有什么?它们怎么存放的,怎么组织的?
· #include
是什么意思?把stdio.h包含进来意味着什么?C语言库又是什么?它怎么实现的?
如果上面的问题你都能回答出来,那么很遗憾,本文不是为你而准备的;但如果你有那么几个问题不明白,甚至从来没有想过一个Hello World可以引发这么多问题,而你又想了解它们,那么恭喜你,本文就是为你而准备的。
对于学过汇编语言的朋友们都知道,一个汇编程序要运行,需要经过编译(masm)、链接(link)、运行(run)这三步,比如下方,运行一个用汇编语言写好的打印HelloWorld的程序。在这里,原本的文件是1.ASM,masm操作生成了1.obj文件,link操作生成了1.exe文件。
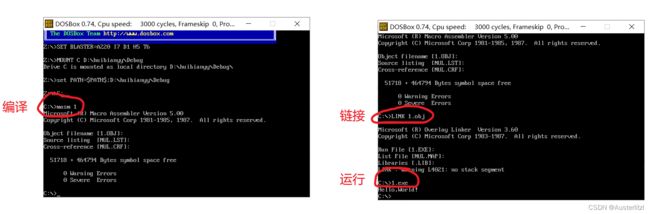
C语言也是类似,run一个.c文件要经过翻译环境和运行环境。经过翻译环境之后,生成了.exe这样的可执行文件,然后运行。
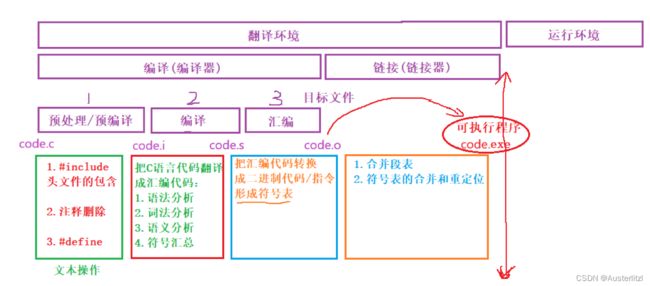
1、翻译环境
把一个.c(文本文件)翻译成.exe(可执行文件)的过程就是翻译环境,翻译环境内的过程,按照先后顺序又可以分为:预编译、编译、汇编、链接。如下图。在VS等环境下,我们无法观察到这个过程,因为这些环境将下列步骤省略了,但是在Linux环境下,我们可以用Linux指令观察到这些过程。

1.1准备阶段
要观察上述过程,得要有一个C语言文件,Linux环境下,使用nano编辑器编辑一个C语言的“Hello World” 文件。
首先,要创建一个code.c文件,在Linux环境下键入如下命令并回车:
nano code.c
这个命令的意思是:创建一个文件名为 code.c 的文件并用nano编辑器来编辑此文件。
然后进入如下界面,这就是nano编辑器打开code.c文件的状态:
然后写一个最简单的C语言程序,写完按“Ctrl+x”退出该编辑器,会提醒是否要保存,此时按“y”,代表yes,即保存的意思,最后让你取名文件名,由于之前已经起过了,这里直接按回车即可(这些过程省略,因为都是次要的,只做简单介绍):
执行完上述命令,就会退出编辑器,回到原界面,此时键入“ ls ” 并回车,可以看到当前文件夹下有code.c这个文件。( ls命令的意思是:查看当前文件夹下的文件。 在这里,当前文件夹名是“lesson1” ,可以看到,[ ] 最后的内容就是文件目录。)

到这里,准备阶段已经完成,目前已经有了一个C语言文件,且该文件里面的内容是打印一个“Hello World”。除此之外,什么都没有。
1.2预编译
1.2.1预编译
预编译阶段,键入下列命令并回车:
gcc -E code.c -o code.i
这个命令的意思是:预处理完成之后就停下来,预处理之后产生的结果都放在code.i文件中。(Linux环境下,gcc编译器 要另外下载,这里省略了gcc下载的过程 )
然后查看当前文件夹下的文件,键入 ls 并回车,得到下列结果,不难看出,增加了一个code.i 文件 :
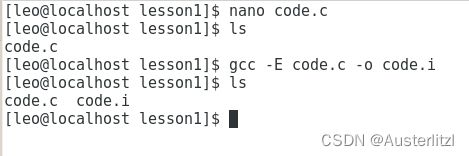
1.2.2查看生成文件
然后用文本编辑器查看文件,键入下列命令并回车,直接用nano查看:
nano code.i
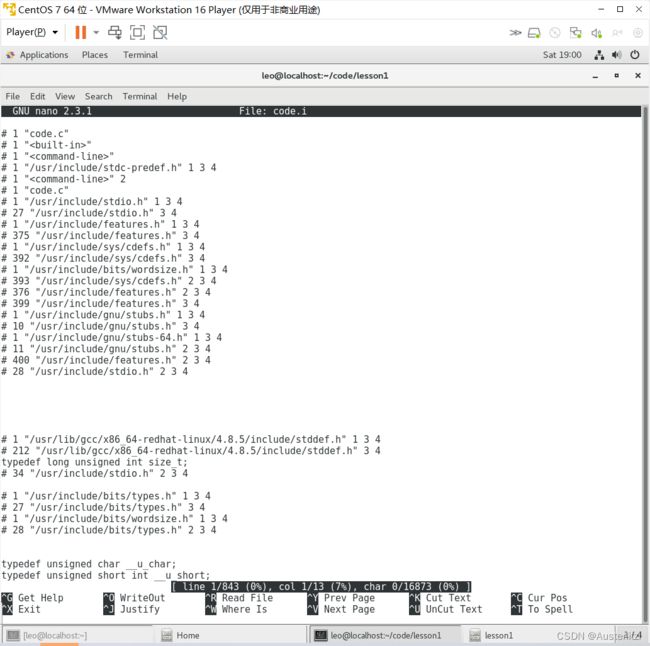
![]()
可以看到,最下方中间,黑色背景的那一行,显示“ Read 843 Lines”,这代表着,code.i文件有843行。
然后我们翻到最下方,可以看到我们写的C语言文件。但是此时发现,C语言文件少了一行“ #include
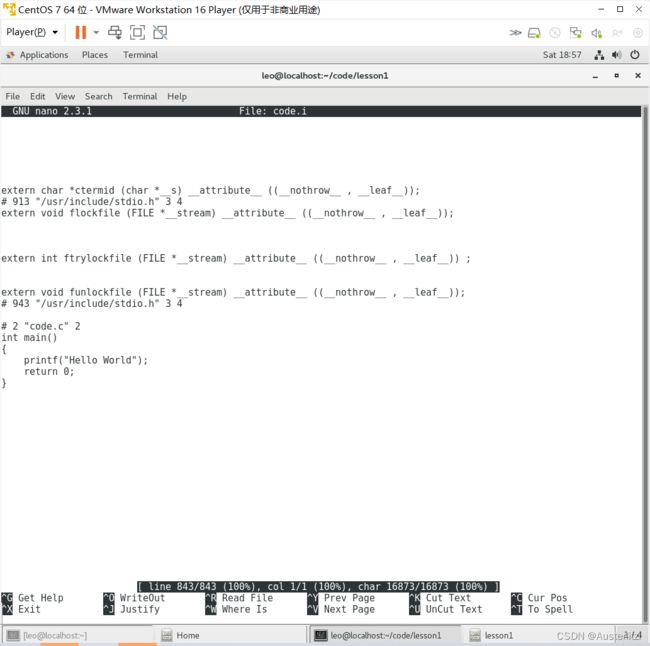
1.2.3比较
所以需要在linux环境下,打开头文件stdio.h,查看里面的内容,键入以下命令:
vim /usr/include/stdio.h
该命令的意思是:用vim编辑器打开stdio.h
![]()
打开头文件stdio.h之后,先按住shif,然后按下g ,跳转到文档最末尾,看到如下界面,观察右下角即可发现,stdio.h头文件包含了947行内容,将其和之前的code.i文件对比,发现确实是把stdio.h 里面的内容复制到C程序中 ,只不过去掉了注释,所以行数要少一些:

1.2.4扩展
其实宏定义的翻译也是在这个过程,我们可以通过下列程序看出,这里定义了两个宏,一个是将N定义为10,一个是定义类似于加法函数 :
经过预编译过程后,打开code.i文件,发现代码如下,预编译过程除了把头文件的内容包含进去,还把宏进行了翻译,从赋值给变量c的那一行替换后可以看出,我的本意是5*(3+5)*10,但是宏翻译之后是5*3+5*10,这就完美符合之前了解的知识:宏是直接替换,虽然运行起来比函数块,但是会出现一些意想不到的错误,所以尽量少用:
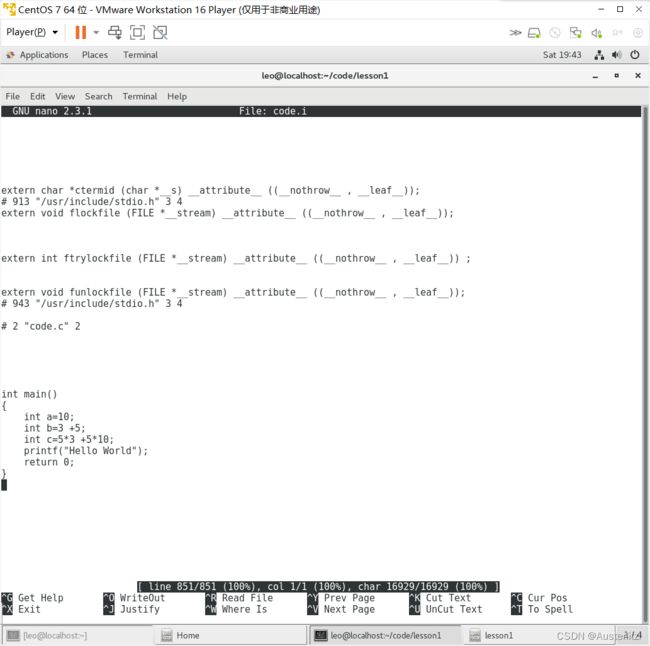
1.3编译
1.3.1编译
键入下列命令:
gcc -S code.i
该命令的意思是:编译完成之后就停下来,结果保存在code.s中。
然后键入ls ,回车,查看当前文件夹下的文件,发现多了一个code.s。

键入下列命令并回车:
nano code.s
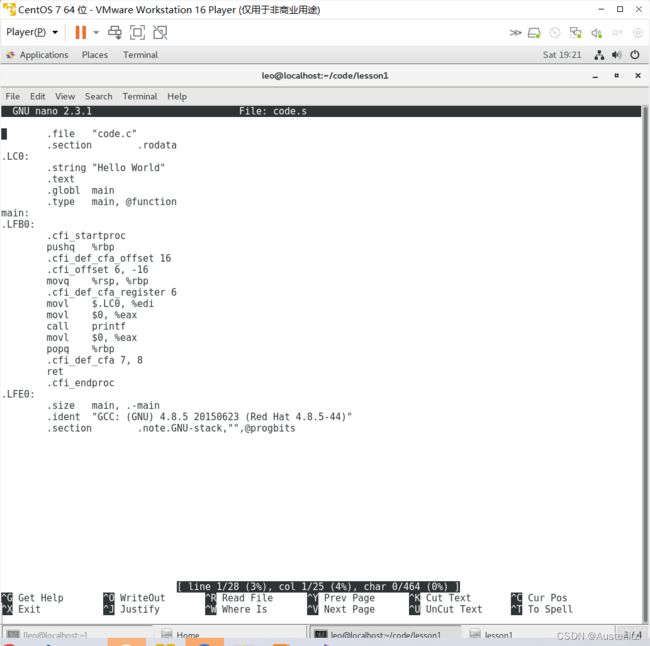
用nano文本编辑器打开code.s,发现是如下内容,学过汇编语言的朋友们一眼便能看出,这是汇编语言,所以,编译过程实际上就是把C语言代码翻译成汇编语言代码的过程,这个过程包含了 语法分析、词法分析 、语意分析、符号汇总。这几个过程:
1.3.2符号汇总
符号汇总的过程,实际上就是把代码中的全局变量名,全局函数名这些符号汇总起来。在汇编阶段是有用的,目前还体现不出来。
比如下方,左边有主函数main,函数Add,全局变量target,那么生成图中对应的符号表(实际上printf也会生成,但是这里只是简单介绍一下)。右边只有主函数main,生成的符号表也如图。

1.3.3和预编译的比较
那么,如何判断语法分析、词法分析 、语意分析、符号汇总等等过程,不是在预编译阶段完成的呢,我们可以把code.c文件故意改错,看看是否能够通过预编译过程:
在这里,我把定义了int类型的变量n,把一个未定义的m赋值给n,很明显,这里是错误的:

键入预编译命令发现,依然可以生成code.i文件,不会报错:

但是键入编译命令就会发现报错,并且提示错误信息,如下:

很明显,对源代码语法、词法等信息的检查分析,是在编译阶段的。
1.4汇编
1.4.1汇编
键入下列命令并回车:
gcc -c code.c
该命令的意思是:汇编完成之后停下来,结果保存到code.o文件中。
利用 ls 命令查看,当前文件夹中确实多了一个code.o 文件

键入下列命令并回车:
nano code.o
用nano编辑器打开code.o文件
发现跳出以下界面,这就汇编后的结果,把汇编指令翻译成二进制指令,我们是看不懂的,但是没关系,编译器可以看懂就可以:
1.4.2生成符号表
实际上,生成的code.o文件格式是elf,所以键入下列命令:
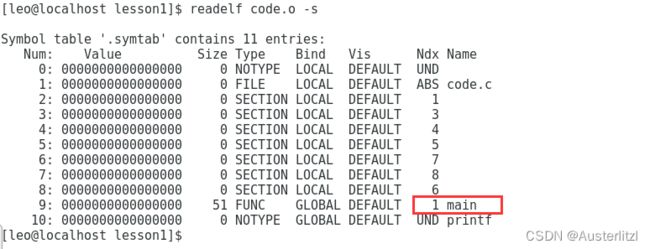
readelf code.o -s
上述命令的意思是,用elf的格式读code.o ,显示符号表段中的项。(因为ocde.o在文件里被划分为了一个一个的段)
可以看到下图所示,main函数名出现在最右侧,实际上生成的符号表是 “main函数+地址”。
如下,原本的符号汇总结果是红色框,在后面加上main函数的地址(绿色框),main函数的函数名和地址两个共同构成了符号表(蓝色框)。

另外,如果是像1.3.3里面,有多个全局变量,函数等等,生成的符号表就应该像下面这样:

1.5链接
键入以下命令并回车:
gcc code.c
这是链接的命令
然后利用 ls 命令查看,发现当前文件夹多了一个a.out的可执行文件(绿色的)。这就是链接后生成的可执行文件(注意,无论有多少个.o文件,最后只能生成一个a.out 文件)。在理解链接过程之前,要明白“段表”这个东西,因为链接过程要合并段表。

1.5.1关于段表
a.out是可执行文件,其格式是elf格式的,elf格式的文件有段表,段表其实就是文件存放不同的内容,分成不同的段。比如数据段、堆栈段、代码段等等(学过汇编的朋友应该比较熟悉)。

1.5.2合并段表
在1.4部分,生成的code.o文件也是elf格式的,同理,它也有段表。可是,在工程中,我们会创建多个.c文件,各自负责不同的功能,然后也会生成多个.o文件,但是,最后生成的a.out文件有且只有一个,那么在链接这一步,就要把所有.o文件的段表合并,a.out里的段表实际上就是所有.o文件的段表合并之后的结果。如下图,三个.o文件的段表合并成a.out文件的段表。(“Hello World”程序展示这一步不明显,下文有详细展示)

1.5.3符号表的合并和重定位
和上面同理,如果有多个.o文件,那么符号表也有多个,此时也需要合并符号表并放到a.out文件。重定位的过程实际上就是地址合并的过程。(后面会详细讲解此过程。)
2.运行
运行环境如何这里便不多赘述,因为不是本文的重点,可以注意下面几点。
1. 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2. 程序的执行便开始。接着便调用main函数。
3. 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
4. 终止程序。正常终止main函数;也有可能是意外终止。
Linux下键入下列命令,即可运行程序:
./a.out
从下面可以看出,是打印了“Hello World”的,只是缺少换行,所以看起来有点奇怪。
![]()
好了,到这里为止,文章开头提出的问题相信基本上都能回答啦!!当然我只是简单地介绍了一下,想要深入地理解这些内容,那么我推荐一本书——《程序员的自我修养—链接、装载与库》,里面有详细的介绍。
3.多个.c文件的问题
上述例子,只是讲了一个打印“Hello World”程序的例子,但是实际应用里面,不可能所有程序都只放在一个.c文件里面,所以这里补充一下有多个文件的情况。
3.1新增一个文件
在这里,就增加一个add.c文件,里面的内容是加法函数,那么现在有两个文件分别是add.c (左图) 、code.c(右图),并且code.c文件应用到了add.c文件的加法函数:
3.2两个文件共同经历翻译环境
如下,除了预编译阶段分开写,其他阶段都可以同时写,每一步都生成对应的文件。
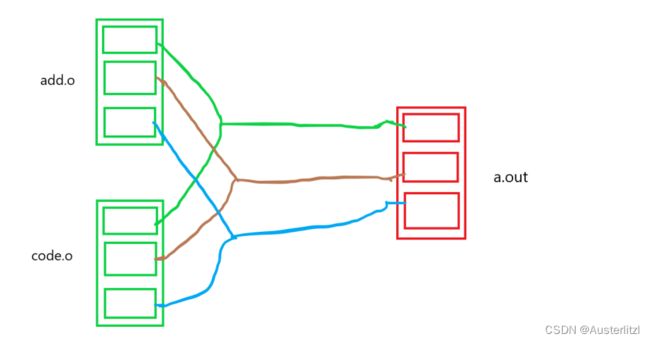
在链接这一步,两个文件要共同生成a.out文件,其中的段表和符号表都要合并。
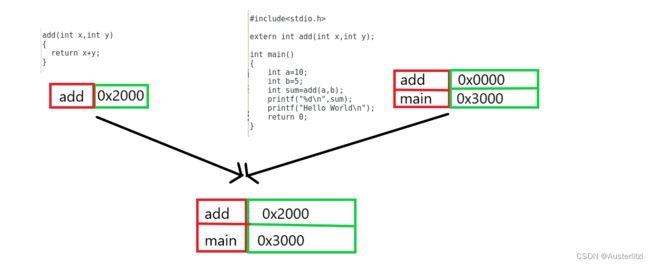
首先看符号表合并和重定位过程,由于有两个.o文件,所以有两个符号表,左边的符号表里只有add,并且其地址是有意义的。右边的符号表有add和main,但是,右边的程序内,add只是声明一下,实际上并不知道add函数的地址在哪里,所以右边符号表里add的地址是无意义的。合并的时候,发现有两个add,取地址有意义的(符号表的重定位),合并成一个;只有一个main,那么合并后的地址就是右边main的地址:
合并段表实际上和1.5.2一样,如下图:
运行程序得到下列结果,正确:

其过程简略地总结一下,类似于下图:

3.3错误示例
只链接一个文件。如下图,只链接了code.c ,此时提醒add未定义。必须两个文件同时链接才可以。
把add函数注释掉,但是声明不变,如下图,链接失败。同样的,找不到add函数。


最后总结一下,如下图,如果有什么疑问或者错误,欢迎在评论区讨论~