MySql优化——索引优化与查询优化(索引失效)
目录
1、概述
2、索引失效案例
2.1、全值匹配
2.2 最佳左前缀法则
2.3 主键插入顺序
2.4 计算、函数、类型转换(自动或手动)导致索引失效
2.5 类型转换导致索引失效
2.6 范围条件右边的列索引失效
2.7 不等于(!= 或者<>)索引失效
2.8 is null可以使用索引,is not null无法使用索引
2.9 like以通配符%开头索引失效
2.10 OR 前后存在非索引的列,索引失效
2.11 数据库和表的字符集统一使用utf8mb4
1、概述
都有哪些维度可以进行数据库调优? 简言之:
- 索引失效、没有充分利用到索引--索引建立
- 关联查询太多JOIN (设计缺陷或不得已的需求) --SQL优化
- 服务器调优及各个参数设置 (缓冲、线程数等)--调整my.cnf
- 数据过多--分库分表
关于数据库调优的知识点非常分散。不同的 DBMS,不同的公司,不同的职位,不同的项目遇到的问题都不尽相同。这里我们分为三个章节进行细致讲解。
虽然 SOL 查询优化的技术有很多,但是大方向上完全可以分成 物理查询优化(索引 )和 逻辑查询优化 两大块。
物理查询优化是通过 索引和 表连接方式 等技术来进行优化,这里重点需要掌握索引的使用。
逻辑查询优化就是通过 SQL 等价变换 提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高.
本文,我们主要讨论一下,索引失效的几种情况:
- 联合索引不满足最左前缀原则
- 主键的插入顺序非自增且无序,导致索引失效
- 索引字段 发生计算,函数,类型转换
- 范围条件的右边索引字段失效
- 不等于(!=) (<>) 导致索引失效
- is not null 导致索引失效
- LIKE %开头的模糊查询 ,导致索引失效
- OR 前后出现非索引字段,导致索引失效
- 字符集不一致,转换时导致索引失效
1、准备数据
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;SET GLOBAL log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#假如要删除
#drop function rand_string;
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#假如要删除
#drop function rand_num;
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_stu;
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
#删除某表的索引 存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
#执行存储过程
CALL proc_drop_index("dbname","tablename");
2、索引失效案例
MySQL中 提高性能 的一个最有效的方式是对数据表 设计合理的索引。索引提供了高效访问数据的方法,并且加快查询的速度,因此索引对查询的速度有着至关重要的影响。
- 使用索引可以 快速地定位 表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。
- 如果查询时没有使用索引,查询语句就会 扫描表中的所有记录。在数据量大的情况下,这样查询的速度会很慢
大多数情况下都(默认)采用 B+ 来构建索引。只是空间列类型的索引使用R-树,并且MEMORY表还支持 hash索引。
其实,用不用索引,最终都是优化器说了算。优化器是基于什么的优化器? 基于 cost开销(CostBaseOptimizer),它不是基于 规则(Rule-BasedOptimizer),也不是基于语义。怎么样开销小就怎么来。另外,SOL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系.
2.1、全值匹配
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHEREage=3 and classId=4:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd';建立索引前执行:(关注执行时间)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd';Empty set,1 warning (0.28 sec)
建立索引
我们可以通过Explain 看看 查询最终使用的是哪个索引
最终发现 查询优化器会选择覆盖查询条件最多的索引,因为,这样可以减少回表的概率
CREATEINDEX idx_age ON student(age);
CREATEINDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,name);![]()
2.2 最佳左前缀法则
在MySQL建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
举例1:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd';
此处没有用到索引,这点正好验证了最左前缀原则
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name = 'abcd'; 
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.`classId`=4 AND student.age=30 AND student.name = 'abcd'; 
再看看这个情况
SHOW INDEX FROM student;
DROP INDEX idx_age_classid ON student;
DROP INDEX idx_age ON student;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd';前面删除索引,只保留了联合索引:idx_age_classid_name
那么查询语句会用到该索引吗?key_len 等于多少?

结果发现 key_len =5 说明 索引只用到了 age (int(3)+null)=5
在 int(M) 中,M 的值跟 int(M) 所占多少存储空间并无任何关系。 int(3)、int(4)、int(8) 在磁盘上都是占用 4 btyes 的存储空间。说白了,除了显示给用户的方式有点不同外,int(M) 跟 int 数据类型是相同的。
其实联合索引 在底层查询的依据是,从左往右,先比较age,如果相同,再比较cassid,如果相同,再比较name。
结论: MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。如果查询条件中没有使用这些字段中第1个字段时,多列 (或联合)索引不会被使用。
2.3 主键插入顺序
对于一个使用 InnoDB 存储引整的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在 聚簇索引的叶子节点的。而记录又是存储在数据页中的,数据页和记录又是按照记录 主键值从小到大 的顺序进行排序,所以如果我们 插入 的记录的 主键值是依次增大 的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的 主键值忽大忽小的话,就比较麻烦了,假设某个数据页存储的记录已经满了,它存储的主键值在1~100之间:
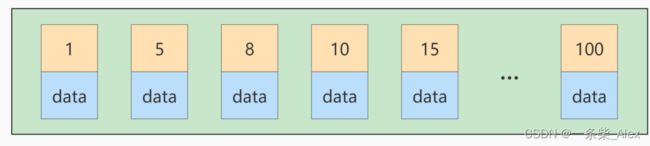
如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图:

可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录 移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗 !所以如果我们想尽量 避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了。 所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入 , 比如: person_info 表:
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
我们自定义的主键列 id 拥有 AUTO_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的 主键值。这样的主键占用空间小,顺序写入,减少页分裂。
2.4 计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
创建索引:
CREATE INDEX idx_name ON student(NAME);
上述第二条语句,就会导致索引失效
![]()
再举例:
student表的字段stuno上设置有索引
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
索引字段进行了计算,导致索引失效
![]()
再举例:
student表的字段name上设置有索引
同样,索引字段使用了函数,导致索引失效
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING(name, 1,3)='abc';2.5 类型转换导致索引失效
下列哪个sql语句可以用到索引。(假设name字段上设置有索引)
name =123 发生类型转换,导致索引失效
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
# 使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
2.6 范围条件右边的列索引失效
我们针对测试的是联合索引 idx_age_classid_name
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;

解决方案:
create index idx_age_name_classid on student(age,name,classid);

将范围查询条件放置语句最后:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =
'abc' AND student.classId>20 ;2.7 不等于(!= 或者<>)索引失效
2.8 is null可以使用索引,is not null无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;2.9 like以通配符%开头索引失效
拓展:Alibaba《Java开发手册》 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
2.10 OR 前后存在非索引的列,索引失效
前提: 含有 idx_age, idx_name 两个索引
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR NAME = 'Abel';![]()
2.11 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不 同的 字符集 进行比较前需要进行 转换 会造成索引失效。
一般性建议:
- 对于单列索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引。
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面.
总之,书写 SQL 语句时,尽量避免造成索引失效的情况