k8s知识点拾遗
目录:
- Headless和Service
- ClusterIP模式
- Headless模式
- Deployment
- 简述
- 更新Deployment
- 回退Deployment
- Deployment扩容
- 暂停和恢复Deployment
- 编写Deployment Spec
- DaemonSet
- 简介
- Kubernetes 的亲和性调度
- 分类
- nodeSelector
- nodeAffinity
- podAffinity
- 亲和性/反亲和性调度策略
- 污点(Taints)与容忍(tolerations)
- ConfigMap
- configmap创建
- 基于命令行
- 基于文件
- configmap使用
- 用作环境变量
- 用作命令行参数
- 使用volume将ConfigMap作为文件或目录直接挂载
- configmap创建
- Label选择器
- 基于相等性或不相等性
- 基于集合
Headless和Service
以ES集群部署为例子,elasticsearch-client是ClusterIP模式,elasticsearch-data是Headless模式
![]()
-
ClusterIP模式
# servers有两个endpoints kubectl describe svc elasticsearch-client -n ops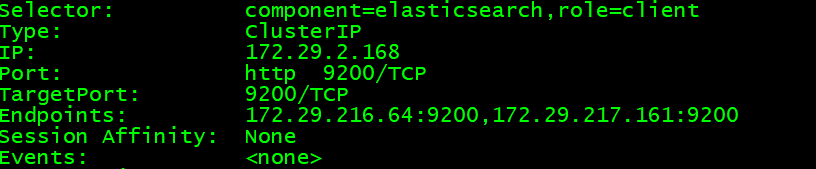
# DNS解析只解析ServerIp,然后由iptables决定最终访问哪一个Real Server nslookup elasticsearch-client.ops.svc.idc.cedu.cn
# 查看某台elasticsearch-client的 /etc/hosts文件,并没有发现DNS域名,只有主机名
-
Headless模式
Headless Service的对应的每一个Endpoints,即每一个Pod,都会有对应的DNS域名;这样Pod之间就可以互相访问. 对于一些集群类型的应用就可以解决互相之间身份识别的问题.
# servers有两个endpoints,但是ClusterIp等于None kubectl describe svc elasticsearch-data -n ops
# DNS解析出实际后端的endpoints地址,不再是server的地址 nslookup elasticsearch-data.ops.svc.idc.cedu.cn
# 查看某台elasticsearch-data的 /etc/hosts文件,发现coreDNS会生成每个pod的DNS域名
Deployment
-
简述
Deployment为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
比如定义一个简单的nginx应用:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 -
更新Deployment
注意: Deployment的rollout当且仅当Deployment的pod template(例如.spec.template)中的label更新或者镜像更改时被触发. 其他更新,例如扩容Deployment不会触发rollout.
rollout:nginx pod使用nginx:1.9.1的镜像来代替原来的nginx:1.7.9的镜像:
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 deployment "nginx-deployment" image updated # edit命令来编辑Deployment,修改 .spec.template.spec.containers[0].image ,将nginx:1.7.9 改写成nginx:1.9.1 $ kubectl edit deployment/nginx-deployment deployment "nginx-deployment" editedrollout:查看rollout的状态:
$ kubectl rollout status deployment/nginx-deployment Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment "nginx-deployment" successfully rolled out默认情况下,Max Surge=1,创建出超过预期数量的Pod. Max Unavailable=1,允许期望Pod中有一个处于Down状态.
在未来的Kuberentes版本中,将从1-1变成25%-25%例如,nginx的Deployment为例子:
a) 开始创建Deployment,创建了一个Replica Set(nginx-deployment-2035384211),并直接扩容到了3个replica.
b) 更新Deployment,创建一个新的Replica Set(nginx-deployment-1564180365),将它扩容到1个replica,然后缩容原先的Replica Set到2个replica,此时满足至少2个Pod是可用状态,同一时刻最多有4个Pod处于创建的状态. Max Surge=1:满足4个Pod处于创建状态;Max Unavailable=1,满足至少2个Pod是可用状态.
c) 使用相同的rolling update策略扩容新的Replica Set和缩容旧的Replica Set. 最终,将会在新的Replica Set中有3个可用的replica,旧的Replica Set的replica数目变成0.
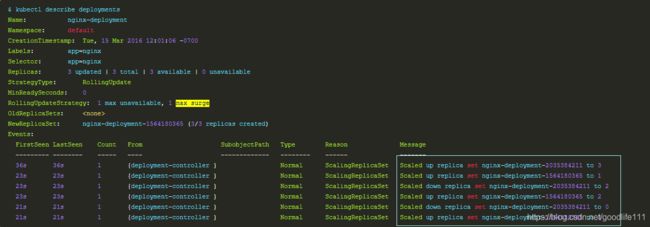
Rollover(多个rollout并行)Replica Set控制label匹配.spec.selector但是template跟.spec.template不匹配的Pod缩容. 最终,新的Replica Set将会扩容出.spec.replicas指定数目的Pod,旧的Replica Set会缩容到0.
如果你更新了一个的已存在并正在进行中的Deployment,每次更新Deployment都会创建一个新的Replica Set并扩容它,同时回滚之前扩容的Replica Set——将它添加到旧的Replica Set列表,开始缩容.
假如你创建了一个有5个niginx:1.7.9 replica的Deployment,但是当还只有3个nginx:1.7.9的replica创建出来的时候你就开始更新含有5个nginx:1.9.1 replica的Deployment. 在这种情况下,Deployment会立即杀掉已创建的3个nginx:1.7.9的Pod,并开始创建nginx:1.9.1的Pod. 它不会等到所有的3个nginx:1.7.9的Pod都创建完成后才开始改变航道.
-
回退Deployment
注意: 只要Deployment的rollout被触发就会创建一个revision,当且仅当Deployment的Pod template(如.spec.template)被更改,例如更新template中的label和容器镜像时,就会创建出一个新的revision.
其他的更新,比如扩容Deployment不会创建revision——因此我们可以很方便的手动或者自动扩容. 这意味着当你回退到历史revision只能是Deployment中的Pod template被修改的版本.
假设我们在更新Deployment的时候犯了一个拼写错误,将镜像的名字写成了nginx:1.91,而正确的名字应该是nginx:1.9.1:
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.91 deployment "nginx-deployment" image updatedRollout将会卡住:
$ kubectl rollout status deployments nginx-deployment Waiting for rollout to finish: 2 out of 3 new replicas have been updated...看下创建Pod,你会看到有两个新的呃Replica Set创建的Pod处于ImagePullBackOff状态,循环拉取镜像:
$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-70iae 1/1 Running 0 25s nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s nginx-deployment-3066724191-eocby 0/1 ImagePullBackOff 0 6s为了修复这个问题,我们需要回退到稳定的Deployment revision.
检查Deployment升级的历史记录
首先,检查下Deployment的revision:
# 创建Deployment的时候使用了—recored参数可以记录命令,可以很方便的查看每次revison的变化 $ kubectl rollout history deployment/nginx-deployment deployments "nginx-deployment": REVISION CHANGE-CAUSE 1 kubectl create -f docs/user-guide/nginx-deployment.yaml --record 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91查看单个revision的详细信息:
$ kubectl rollout history deployment/nginx-deployment --revision=2 deployments "nginx-deployment" revision 2 Labels: app=nginx pod-template-hash=1159050644 Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 Containers: nginx: Image: nginx:1.9.1 Port: 80/TCP QoS Tier: cpu: BestEffort memory: BestEffort Environment Variables:No volumes. 回退到历史版本:
# 回退到上个版本 $ kubectl rollout undo deployment/nginx-deployment deployment "nginx-deployment" rolled back # 使用 --revision参数指定某个历史版本 $ kubectl rollout undo deployment/nginx-deployment --to-revision=2 deployment "nginx-deployment" rolled back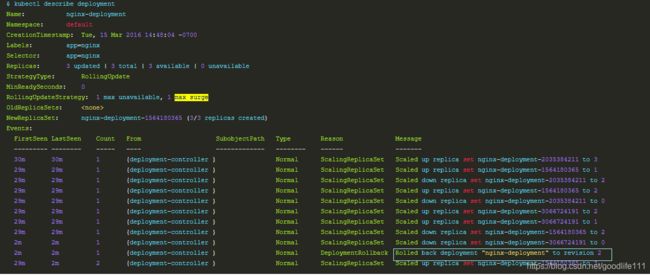
清理Policy设置.spec.revisonHistoryLimit项来指定deployment最多保留多少revison历史记录. 默认的会保留所有的revision;如果将该项设置为0,Deployment就不允许回退了.
-
Deployment扩容
你可以使用以下命令扩容Deployment:
$ kubectl scale deployment nginx-deployment --replicas 10 deployment "nginx-deployment" scaled假设你的集群中启用了horizontal pod autoscaling,你可以给Deployment设置一个autoscaler,基于当前Pod的CPU利用率选择最少和最多的Pod数:
$ kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80 deployment "nginx-deployment" autoscaled -
暂停和恢复Deployment
使用以下命令暂停Deployment:
$ kubectl rollout pause deployment/nginx-deployment deployment "nginx-deployment" paused然后更新Deplyment中的镜像:
$ kubectl set image deploy/nginx nginx=nginx:1.9.1 deployment "nginx-deployment" image updated恢复这个Deployment,观察完成更新的ReplicaSet已经创建出来了:
$ kubectl rollout resume deploy nginx deployment "nginx" resumed -
编写Deployment Spec
Pod Template :
- .spec.template 是 .spec中唯一要求的字段.
- .spec.template 是 pod template.
- .spec.template.spec.restartPolicy 可以设置为 Always , 如果不指定的话这就是默认配置.
Replicas:
- .spec.replicas 是可以选字段,指定期望的pod数量,默认是1.
Selector:
- .spec.selector是可选字段,用来指定 label selector ,圈定Deployment管理的pod范围.
策略:
- .spec.strategy 指定新的Pod替换旧的Pod的策略,默认为RollingUpdate.
- .spec.strategy.type==Recreate时,在创建出新的Pod之前会先杀掉所有已存在的Pod.
- .spec.strategy.type==RollingUpdate时,Deployment使用rolling update 的方式更新Pod. 你可以指定maxUnavailable 和maxSurge 来控制 rolling update 进程.
- .spec.strategy.rollingUpdate.maxUnavailable 是可选配置项,用来指定在升级过程中不可用Pod的最大数量. 例如,该值设置成30%,升级的所有时刻可以用的Pod数量至少是期望Pod数量的70%.
- .spec.strategy.rollingUpdate.maxSurge是可选配置项,用来指定可以超过期望的Pod数量的最大个数. 例如,该值设置成30%,升级的所有时刻所有的Pod数量和不会超过期望Pod数量的130%.
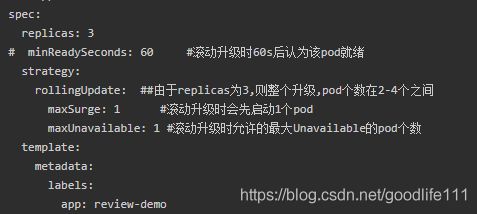
Progress Deadline Seconds - .spec.progressDeadlineSeconds 是可选配置项,用来指定在系统报告Deployment的failed progressing.
Min Ready Seconds
- .spec.minReadySeconds是一个可选配置项,用来指定没有任何容器crash的Pod并被认为是可用状态的最小秒数。默认是0.
Rollback To
- .spec.rollbackTo.revision是一个可选配置项,用来指定回退到的revision。默认是0,意味着回退到历史中最老的revision.
Revision History Limit
- .spec.revisionHistoryLimit 是一个可选配置项,用来指定可以保留的旧的ReplicaSet数量. 如果该值没有设置的话,默认所有旧的Replicaset或会被保留,将资源存储在etcd中.
DaemonSet
-
简介
DaemonSet保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括:
- 日志收集,比如fluentd,logstash等
- 系统监控,比如Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond等
- 系统程序,比如kube-proxy, kube-dns, glusterd, ceph等
使用Fluentd收集日志的例子:

Kubernetes 的亲和性调度
-
分类:
- nodeSelector:只调度到匹配指定label的Node上
- nodeAffinity:功能更丰富的Node选择器,比如支持集合操作
- podAffinity:调度到满足条件的Pod所在的Node上
-
nodeSelector
根据节点的 label 进行Pod调度
首先给Node打上标签:
$ kubectl label nodes 192.168.1.140 source=qikqiak node "192.168.1.140" labeled # 查看标签是否生效 kubectl get nodes --show-labels指定nodeSelector为disktype=ssd:

-
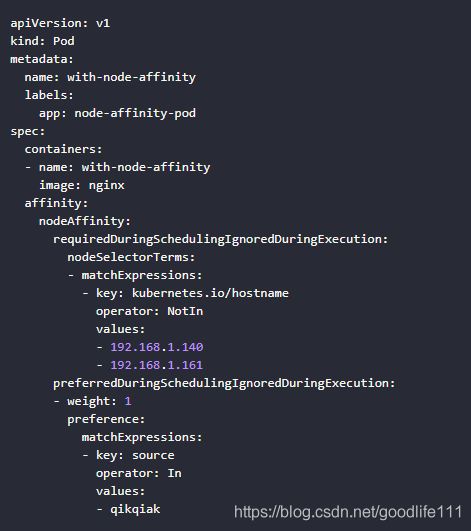
nodeAffinity示例
节点亲和性.
requiredDuringSchedulingIgnoredDuringExecution: 硬策略,必须满足,否则不断重试.
preferredDuringSchedulingIgnoredDuringExecution: 软策略,优先调度要求 POD 不能运行在140和161两个节点上,如果有个节点满足source=qikqiak的话就优先调度到这个节点上.
-
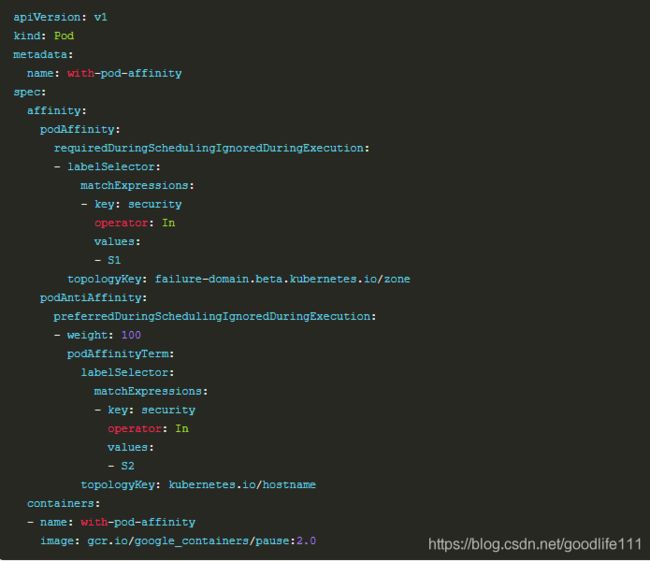
podAffinity示例
podAffinity基于Pod的标签来选择Node,仅调度到满足条件Pod所在的Node上,支持podAffinity(亲和性)和podAntiAffinity(非亲和性):
- 如果一个“Node所在Zone中包含至少一个带有security=S1标签且运行中的Pod”,那么可以调度到该Node
- 不调度到“包含至少一个带有security=S2标签且运行中Pod”的Node上
-
亲和性/反亲和性调度策略比较如下:
| 调度策略 | 匹配标签 | 操作符 | 括扑域支持 | 调度目标 |
|---|---|---|---|---|
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
| nodeAffinity | 主机 | In, NotIn, Exists, DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD同一拓扑域 |
| podAnitAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD不在同一拓扑域 |
-
污点(Taints)与容忍(tolerations)
如果不想要pod调度到某个节点,可以标记为"Taints":
$ kubectl taint nodes 192.168.1.40 key=value:NoSchedule node "192.168.1.40" tainted如果仍然希望某个 POD 调度到 taint 节点上,则必须在 Spec 中做出Toleration定义,才能调度到该节点:
tolerations: - key: "key" operator: "Equal" value: "value" # a) NoSchedule:POD 不会被调度到标记为 taints 节点 b) PreferNoSchedule:NoSchedule 的软策略版本 # c) NoExecute:该选项意味着一旦 Taint 生效,如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 effect: "NoSchedule"
configmap
ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。ConfigMap跟secret很类似,但它可以更方便地处理不包含敏感信息的字符串。
-
ConfigMap创建
从key-value字符串创建ConfigMap
$ kubectl create configmap special-config --from-literal=special.how=very configmap "special-config" created从文件创建Configmap key是文件名,value是文件内容
# cat kibana.yaml server.name: "kibana" server.host: "0" elasticsearch.hosts: [ "http://elasticsearch-client.ops.svc.idc.cedu.cn:9200" ] xpack.monitoring.ui.container.elasticsearch.enabled: true kubectl create configmap kibana-config --from-file=kibana.yaml -
Configmap使用
-
用作环境变量
首先创建ConfigMap:

然后以环境变量方式引用:

当pod运行结束后,它的输出会包括:

-
用作命令行参数
将ConfigMap用作命令行参数时,需要先把ConfigMap的数据保存在环境变量中,然后通过$ (VAR_NAME)的方式引用环境变量. 比如上面将configmap设置成环境变量,后续可以使用$(变量)来调用
-
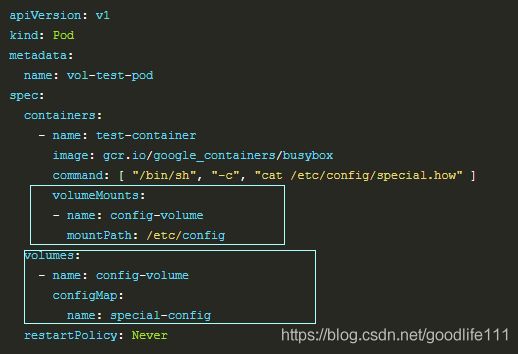
使用volume将ConfigMap作为文件或目录直接挂载 比如可以直接挂载容器应用的配置文件,而不用每次变更都重新生成镜像.
-
-
Label选择器
-
基于相等性或不相等性
基于相等性或者不相等性的条件允许用label的键或者值进行过滤. 匹配的对象必须满足所有指定的label约束. 有三种运算符:"="、"=="、"!="
# 选择所有键等于environment,值为production的资源. environment = production # 选择所有键为tier,值不等于frontend的资源;键不等于tier的label资源 tier != frontend -
基于集合
基于集合的label条件允许用一组值来过滤键. 支持三种操作符:in、notin、exists(仅针对key符号)
# 选择键值等于environment,value等于production或qa的资源 environment in (production, qa) # 选择键值等于tier,value不等于frontend或backend的资源 tier notin (frontend, backend) # 选择键值等于partition资源,不检查value等于什么 partition # 选择所有的键值不等于partitio资源,不检查value等于什么 !partitio -
service and RC基于相等性条件匹配
一个service针对的pods的集合是用label选择器来定义的. 类似的,一个replicationcontroller管理的pods的群体也是用label选择器来定义的.
对于这两种对象的Label选择器是用map定义在json或者yaml文件中的,并且只支持基于相等性的条件:
# json "selector": { "component" : "redis" } # yaml selector: component: redis这个选择器(分别是位于json或者yaml格式的)相等于 component=redis 或者 component in(redis).
-
较新的资源(如Job, Deployment, Replica Set, 和 Daemon Set,)支持基于集合的条件
selector: matchLabels: component: redis # matchLabels等于matchExpressions集合中的一个 matchExpressions: - {key: tier, operator: In, values: [cache]} - {key: environment, operator: NotIn, values: [dev]}
-