【YOLO】YOLOv5+Deep Sort 实现MOT评估(开源数据集+自定义数据集)
引言
YOLOv5+Deep Sort 实现目标跟踪,并利用MOTChallengeEvalKit实现多目标跟踪结果的评估。
YOLOv5+Deep Sort 实现目标跟踪可以参考笔者的【YOLOv5】yolov5目标识别+DeepSort目标追踪
实现步骤
1 安装MATLAB
安装MATLAB
MATLAB是一款商业数学软件,用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境,主要包括MATLAB和Simulink两大部分,可以进行矩阵运算、绘制函数和数据、实现算法、创建用户界面、连接其他编程语言的程序等,主要应用于工程计算、控制设计、信号处理与通讯、图像处理、信号检测、金融建模设计与分析等领域。
直接附上安装的参考链接:https://mp.weixin.qq.com/s/LAatgqNf55zpxzOYlpn8fg
2 必要的开源
- MOT评估工具:dendorferpatrick-MOTChallengeEvalKit
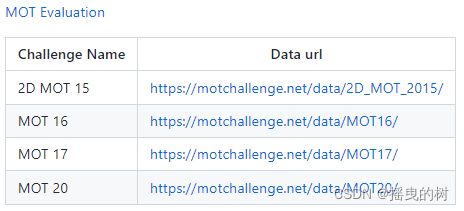
- 开源的评估数据库:例如MOT 17,其他链接如下
- Deep Sort目标跟踪:mikel-brostrom-Yolov5_DeepSort_Pytorch
- YOLOv5目标识别:ultralytics-yolov5
下载上述开源压缩包,进行解压,文件的部署如下:
-----------------------------------------------------------------------------------------------------------
# 1.准备数据集(树形框架)
|-MOTChallengeEvalKit(评估工具源码)# 源码1
|-MOT # 多目标评估
|-matlab_devkit
|-evalMOT.py # 评估主代码1
|-Evaluator.py # 评估主代码2
|-Metrics.py
|-MOT_metrics.py
|-MOTVisualization.py
|-Visualize.py
|-Yolov5_DeepSort_Pytorch(目标跟踪) # 源码2
|-deep_sort # 跟踪源码
|-yolov5 # 源码3:该文件夹是空的,需要把YOLOv5的源码项目放进去
|-Evaluation-MOTdata(开源数据库) # 笔者自定义的名称(用于存放开源数据库)
|-MOT16 # 开源数据集
|-MOT17
|-MOT20
-----------------------------------------------------------------------------------------------------------
3 环境部署
首先利用Anaconda创建新的环境,以优先满足YOLOv5的环境部署,特别是python的版本不能低于YOLOv5要求的下限。

conda create -n yolov5-6 python=3.7
conda activate yolov5-6 # 激活环境
3.1 MATLAB编译
笔者MATLAB的版本是:MATLAB R2021a
终端进入MATLAB的安装路径:D:\Program Files\Polyspace\R2021a\extern\engines\python 自定义的安装路径
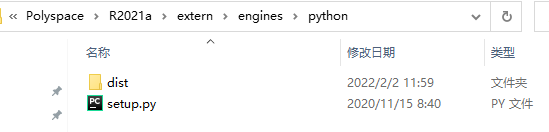
cd D:\Program Files\Polyspace\R2021a\extern\engines\python
# 执行如下指令
python setup.py build --build-base="builddir" install
python setup.py install --prefix="installdir"
python setup.py build --build-base="builddir" install --prefix="installdir"
python setup.py install --user
执行完上述指令之后,MATLAB的安装路径下新增文件如下:

打开MATLAB完成编译
打开评估工具源码项目文件,并将如下文件复制到MOT文件夹下面,这一步的复制操作十分重要,否则即使编译成功,评估也会失败。
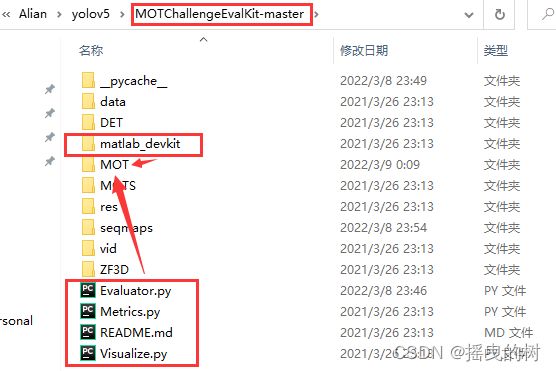
复制后MOT文件夹下的文件如下:

根据截图完成编译

若没有复制上述文件,则评估是会有如下的错误:

3.2 DeepSort +YOLOv5环境搭建
优先满足YOLOv5的环境部署,DeepSort没有特殊的要求,在运行时缺啥补啥
参考链接【YOLOv5】6.0环境搭建(不定时更新)
4 评估测试
测试上述所搭建的环境是否能在开源的MOT17实现评估
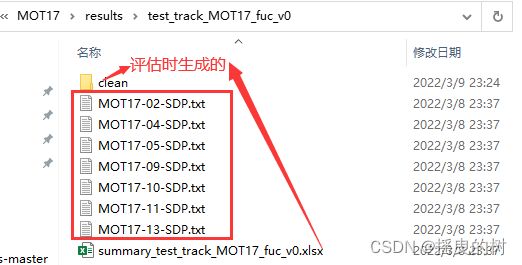
4.1 下载现成的跟踪结果
现成的跟踪结果笔者的参考链接:(python版 MOTChallengeEvalKit 评估工具运行,运行MOT评估工具)
链接:https://pan.baidu.com/s/1CkPse7rcx53qOEy8YlU6qw
提取码:rlwj
将下载的文件放入开源数据集中:
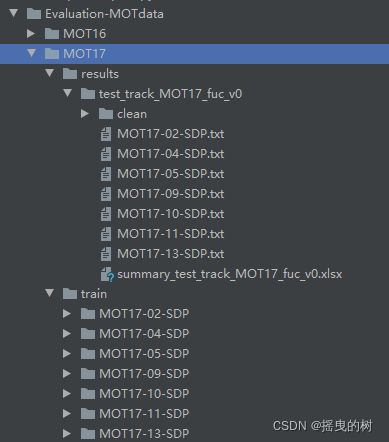
4.2 运行评估
(1)打开评估代码MOTChallengeEvalKit-master\MOT\evalMOT.py
修改配置如下:
if __name__ == "__main__":
eval = MOT_evaluator()
benchmark_name = "MOT17"
gt_dir = r"E:\Alian\yolov5\MOTChallengeEvalKit-master\MOT17" # GT
res_dir = r"E:\Alian\yolov5\MOTChallengeEvalKit-master\MOT17\results\test_track_MOT17_fuc_v0" # 跟踪结果
eval_mode = "train" # MOT17下的train模式,因为只有train才有GT
seqmaps_dir = r'E:\Alian\yolov5\MOTChallengeEvalKit-master\seqmaps'
eval.run(
benchmark_name = benchmark_name,
gt_dir = gt_dir,
res_dir = res_dir,
eval_mode = eval_mode,
seqmaps_dir=seqmaps_dir
)
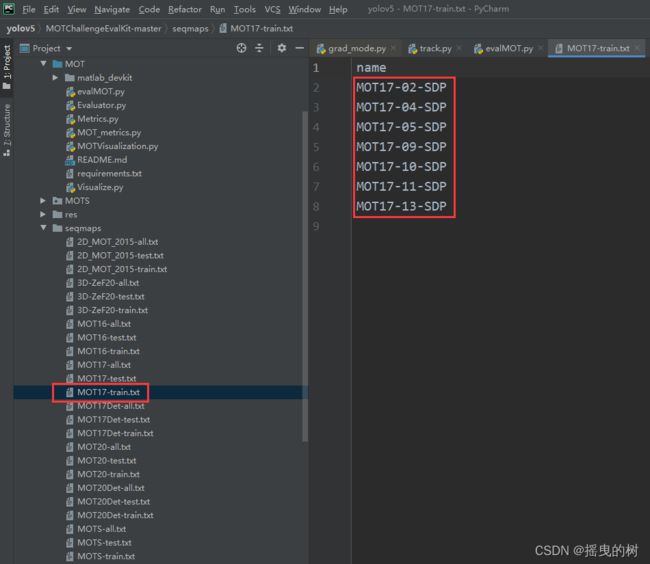
(2)打开MOTChallengeEvalKit-master\seqmaps\MOT17-train.txt
只保留下述的内容,多余的删除(因为只有下述文件的跟踪结果),检查基准、跟踪结果是否一一对应
评估基准

跟踪结果
终端执行命令,打印结果如下
python evalMOT.py

5 在自定义的数据下实现跟踪评估
5.1 修改评估代码

./MOT/evalMOT.py 修改如下
"""
2022.3.12
author:alian
实现跟踪结果的评估
"""
import sys, os
sys.path.append(os.path.abspath(os.getcwd()))
import math
from collections import defaultdict
from MOT_metrics import MOTMetrics
from Evaluator import Evaluator, run_metrics,My_Evaluator
import multiprocessing as mp
import pandas as pd
# 2、自定义数据集评估
class My_MOTevaluator(My_Evaluator): # 继承父类
def __init__(self):
super().__init__()
pass
def my_eval(self): # 重写评估函数
arguments = [] # 传入参数: 项目名称,跟踪结果文件列表,基准文件列表
for seq, res, gt in zip(self.sequences, self.tsfiles, self.gtfiles): # 评估路段的名称,跟踪结果文件,基准文件
arguments.append({"metricObject": MOTMetrics(seq), "args": {
"gtDataDir": os.path.join(os.path.dirname(gt),seq),
"sequence": str(seq),
"pred_file":res,
"gt_file": gt,
"benchmark_name": self.benchmark_name}})
try:
if self.MULTIPROCESSING:
p = mp.Pool(self.NR_CORES) # 实例化多进程并行池
print("Evaluating on {} cpu cores".format(self.NR_CORES))
# 计算每个序列的指标
processes = [p.apply_async(run_metrics, kwds=inp) for inp in arguments] # 得到多进程处理结果
self.results = [p.get() for p in processes] # 评估结果
p.close()
p.join()
else:
self.results = [run_metrics(**inp) for inp in arguments]
self.failed = False # 成功
except:
self.failed = True
raise Exception(" MATLAB evalutation failed " )
self.Overall_Results = MOTMetrics("OVERALL") # 定义评估指标矩阵的名称
return self.results,self.Overall_Results
./MOT/Evaluator.py
"""
2022.3.12
author:alian
"""
import sys, os
sys.path.append(os.getcwd())
import argparse
import traceback
import time
import pickle
import pandas as pd
import glob
from os import path
import numpy as np
class My_Evaluator(object): # 多目标跟踪评估器类
""" 评估器类运行每个序列的评估并计算基准的整体性能"""
def __init__(self):
pass
def run(self, benchmark_name=None, gt_dir=None, mot_dir=None,save_csv = None):
self.benchmark_name = benchmark_name # 项目名称
start_time = time.time()
self.gtfiles = glob.glob('%s/*_gt.txt'%gt_dir) # 基准文件gt.txt全路径
self.tsfiles = glob.glob('%s/*_mot.txt'%mot_dir) # 评估结果全路径
self.sequences = [os.path.split(x)[-1].split('_')[0] for x in self.gtfiles]
print('Found {} ground truth files and {} test files.'.format(len(self.gtfiles), len(self.tsfiles)))
# 设置多核处理
self.MULTIPROCESSING = True # 多处理
MAX_NR_CORES = 10 # 最大的处理量
if self.MULTIPROCESSING: self.NR_CORES = np.minimum(MAX_NR_CORES, len(self.tsfiles))
try:
""" 执行评估 """
self.results,self.Overall_Results = self.my_eval()
# 计算整体结果
results_attributes = self.Overall_Results.metrics.keys() # 评估指标(名称)
for attr in results_attributes:
""" 在所有序列上累积评估值 """
try:
self.Overall_Results.__dict__[attr] = sum(obj.__dict__[attr] for obj in self.results)
except:
pass
cache_attributes = self.Overall_Results.cache_dict.keys() # 缓存属性
for attr in cache_attributes:
""" accumulate cache values over all sequences """
try:
self.Overall_Results.__dict__[attr] = self.Overall_Results.cache_dict[attr]['func']([obj.__dict__[attr] for obj in self.results])
except:
pass
print("evaluation successful")
# 计算clearmot指标
for res in self.results:
res.compute_clearmot()
self.Overall_Results.compute_clearmot()
summary = self.accumulate_df(type="mail")
# 将评估果写入csv文件
summary.to_csv(save_csv)
except:pass
end_time=time.time()
self.duration = (end_time - start_time)/60.
# 收集评估错误
print("Evaluation Finished")
print("Your Results")
print(self.render_summary())
print("Successfully save results")
return self.Overall_Results, self.results
def my_eval(self): # 实际使用时重写
raise NotImplementedError
def accumulate_df(self, type = None):
""" create accumulated dataframe with all sequences """
summary = None
for k, res in enumerate(self.results):
res.to_dataframe(display_name = True, type=type)
if k == 0: summary = res.df
else:summary = pd.concat([summary,res.df])
summary = summary.sort_index()
self.Overall_Results.to_dataframe(display_name=True, type=type)
self.summary = pd.concat([summary,self.Overall_Results.df])
return self.summary
def render_summary( self, buf = None): # 终端打印评估指标
"""
Params:
summary : pd.DataFrame
Kwargs:
buf : StringIO-like, optional 写入缓存区
formatters : dict, optional(为单个指标定义自定义格式化程序的字典){'mota': '{:.2%}'.format}.MetricsHost.formatters
namemap : dict, optional {'num_false_positives': 'FP'}
Returns:
string
"""
output = self.summary.to_string(
buf=buf,
formatters=self.Overall_Results.formatters,
justify="left"
)
return output
def run_metrics( metricObject, args ):
""" Runs metric for individual sequences
Params:
-----
metricObject: metricObject that has computer_compute_metrics_per_sequence function
args: dictionary with args for evaluation function
"""
metricObject.compute_metrics_per_sequence(**args) # 计算每个序列的指标
return metricObject
if __name__ == "__main__":
Evaluator()
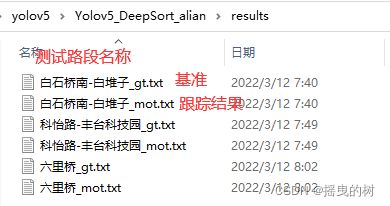
5.2 基准和评估结果准备
(1)基准文件:name_gt.txt

从左到右分别是:
1. frame: 第几帧图片
2. ID:也就是轨迹的ID,可以看出gt里边是按照轨迹的ID号进行排序的
3. bbox: 分别是左上角坐标和长宽
4. bbox: 分别是左上角坐标和长宽
5. bbox: 分别是左上角坐标和长宽
6. bbox: 分别是左上角坐标和长宽
7. bool类型:代表是否忽略:0代表忽略,1代表该目标被选
8. classes:目标的类别个数(开源的MOT数据集中:驾驶场景包括12个类别,7代表的是静止的人, 第8个类代表错检,9-11代表被遮挡的类别,如下图),自定数据集就根据自己的目标类别数
9. 最后一个代表目标运动时被其他目标包含、覆盖、边缘裁剪的情况,这里笔者将目标的置信度写入该列的值
(2)跟踪结果:name_mot.txt

从左到右分别是:
1. frame: 第几帧图片
2. ID:也就是轨迹的ID,可以看出gt里边是按照轨迹的ID号进行排序的
3. bbox: 分别是左上角坐标和长宽
4. bbox: 分别是左上角坐标和长宽
5. bbox: 分别是左上角坐标和长宽
6. bbox: 分别是左上角坐标和长宽
7. conf:目标置信度
8. MOT3D(x,y,z): 是在MOT3D(三维跟踪)中使用到的内容,这里关心的是MOT二维,所以都设置为-1
5.3 实现自定义数据集的MOT评估
打开./MOT/evalMOT.py 修改配置如下
if __name__ == "__main__":
# 自定义数据集评估
my_eval = My_MOTevaluator()
benchmark_name = "MOT北京地铁9号线"
gt_dir = r"E:\Alian\yolov5\Yolov5_DeepSort_alian\results" # GT
res_dir = r"E:\Alian\yolov5\Yolov5_DeepSort_alian\results" # 跟踪结果
my_eval.run(
benchmark_name=benchmark_name,
gt_dir=gt_dir,
mot_dir=res_dir,
save_csv='MOT北京地铁9号线.csv'
)
6 完整代码汇总
6.1 evalMOT.py
"""
2022.3.12
author:alian
实现跟踪结果的评估
"""
import sys, os
sys.path.append(os.path.abspath(os.getcwd()))
import math
from collections import defaultdict
from MOT_metrics import MOTMetrics
from Evaluator import Evaluator, run_metrics,My_Evaluator
import multiprocessing as mp
import pandas as pd
# 1、开源跟踪评估
class MOT_evaluator(Evaluator): # 继承父类
def __init__(self):
super().__init__()
self.type = "MOT"
def eval(self): # 重写评估函数
print("Check prediction files") # 检查评估文件
error_message = ""
for pred_file in self.tsfiles: # 遍历跟踪结果
print(pred_file)
df = pd.read_csv(pred_file, header=None, sep=",") # 默认用逗号隔开
if len(df.columns) == 1: # 若只有一列
f = open(pred_file, "r")
error_message+= "Submission %s not in correct form. Values in file must be comma separated.
Current form:
%s
%s
.........
" % (pred_file.split("/")[-1], f.readline(), f.readline())
raise Exception(error_message)
df.groupby([0,1]).size().head() # 根据帧序,ID对数据进行分组(取前5行)
count = df.groupby([0,1]).size().reset_index(name='count') # 将分组索引(帧序,ID)设置为列,则此时的列有:帧序,ID,计数
# 检查ID的独一性
if any(count["count"]>1):
doubleIDs = count.loc[count["count"]>1][[0,1]].values
error_message+= " Found duplicate ID/Frame pairs in sequence %s." % pred_file.split("/")[-1]
for id in doubleIDs:
double_values = df[((df[0] == id[0]) & (df[1] == id[1]))]
for row in double_values.values:
error_message += "
%s" % row
error_message+="
"
if error_message != "":
raise Exception(error_message)
print("Files are ok!") # 文件检查完毕!
arguments = [] # 传入参数:
for seq, res, gt in zip(self.sequences, self.tsfiles, self.gtfiles): # 基准名称,跟踪结果文件,基准文件
arguments.append({"metricObject": MOTMetrics(seq), "args": {
"gtDataDir": os.path.join(self.datadir,seq),
"sequence": str(seq),
"pred_file":res,
"gt_file": gt,
"benchmark_name": self.benchmark_name}})
try:
if self.MULTIPROCESSING:
p = mp.Pool(self.NR_CORES) # 实例化多进程并行池
print("Evaluating on {} cpu cores".format(self.NR_CORES))
# 计算每个序列的指标
processes = [p.apply_async(run_metrics, kwds=inp) for inp in arguments] # 得到多进程处理结果
self.results = [p.get() for p in processes] # 评估结果
p.close()
p.join()
else:
self.results = [run_metrics(**inp) for inp in arguments]
self.failed = False # 成功
except:
self.failed = True
raise Exception(" MATLAB evalutation failed " )
self.Overall_Results = MOTMetrics("OVERALL") # 定义评估指标矩阵的名称
return self.results,self.Overall_Results
# 2、自定义数据集评估
class My_MOTevaluator(My_Evaluator): # 继承父类
def __init__(self):
super().__init__()
pass
def my_eval(self): # 重写评估函数
arguments = [] # 传入参数: 项目名称,跟踪结果文件列表,基准文件列表
for seq, res, gt in zip(self.sequences, self.tsfiles, self.gtfiles): # 评估路段的名称,跟踪结果文件,基准文件
arguments.append({"metricObject": MOTMetrics(seq), "args": {
"gtDataDir": os.path.join(os.path.dirname(gt),seq),
"sequence": str(seq),
"pred_file":res,
"gt_file": gt,
"benchmark_name": self.benchmark_name}})
try:
if self.MULTIPROCESSING:
p = mp.Pool(self.NR_CORES) # 实例化多进程并行池
print("Evaluating on {} cpu cores".format(self.NR_CORES))
# 计算每个序列的指标
processes = [p.apply_async(run_metrics, kwds=inp) for inp in arguments] # 得到多进程处理结果
self.results = [p.get() for p in processes] # 评估结果
p.close()
p.join()
else:
self.results = [run_metrics(**inp) for inp in arguments]
self.failed = False # 成功
except:
self.failed = True
raise Exception(" MATLAB evalutation failed " )
self.Overall_Results = MOTMetrics("OVERALL") # 定义评估指标矩阵的名称
return self.results,self.Overall_Results
if __name__ == "__main__":
# 1 开源数据集跟踪评估
# benchmark_name = "MOT17"
# gt_dir = r"E:\Alian\yolov5\MOTChallengeEvalKit-master\MOT17" # GT
# res_dir = r"E:\Alian\yolov5\MOTChallengeEvalKit-master\MOT17\results\test_track_MOT17_fuc_v0" # 跟踪结果
# eval_mode = "train" # MOT17下的train模式,因为只有train才有GT
# seqmaps_dir = r'E:\Alian\yolov5\MOTChallengeEvalKit-master\seqmaps'
# eval.run(
# benchmark_name = benchmark_name,
# gt_dir=gt_dir,
# res_dir=res_dir,
# eval_mode=eval_mode,
# seqmaps_dir=seqmaps_dir
# )
# 2 自定义数据集评估
my_eval = My_MOTevaluator()
benchmark_name = "MOT北京地铁9号线"
gt_dir = r"E:\Alian\yolov5\Yolov5_DeepSort_alian\results" # GT
res_dir = r"E:\Alian\yolov5\Yolov5_DeepSort_alian\results" # 跟踪结果
my_eval.run(
benchmark_name=benchmark_name,
gt_dir=gt_dir,
mot_dir=res_dir,
save_csv='MOT北京地铁9号线.csv'
)
6.2 Evaluator.py
"""
2022.3.12
author:alian
"""
import sys, os
sys.path.append(os.getcwd())
import argparse
import traceback
import time
import pickle
import pandas as pd
import glob
from os import path
import numpy as np
class Evaluator(object): # 多目标跟踪评估器 类
""" 评估器类运行每个序列的评估并计算基准的整体性能"""
def __init__(self):
pass
def run(self, benchmark_name=None, gt_dir=None, res_dir=None, save_pkl=None, eval_mode="train", seqmaps_dir="seqmaps"):
"""
Params
benchmark_name: 基准名称,如 MOT17
gt_dir: directory of folders with gt data, including the c-files with sequences
res_dir: directory with result files
.txt
.txt
...
.txt
eval_mode:
seqmaps_dir:
seq_file: File name of file containing sequences, e.g. 'c10-train.txt'
save_pkl: path to output directory for final results
"""
start_time = time.time()
self.benchmark_gt_dir = gt_dir # 基准文件夹MOT17 'E:\\Alian\\yolov5\\Evaluation-MOTdata\\MOT17'
self.seq_file = "{}-{}.txt".format(benchmark_name, eval_mode) # MOT17-train.txt(序列)
res_dir = res_dir # 评估结果文件夹 'E:\\Alian\\yolov5\\Evaluation-MOTdata\\MOT17\\results\\test_track_MOT17_fuc_v0'
self.benchmark_name = benchmark_name # 基准名称'MOT17'
self.seqmaps_dir = seqmaps_dir # 序列文件夹(包含各数据集的序列)E:\Alian\yolov5\MOTChallengeEvalKit-master\seqmaps
self.mode = eval_mode # 'train'
self.datadir = os.path.join(gt_dir, self.mode) # E:\Alian\yolov5\Evaluation-MOTdata\MOT17\train
error_traceback = "" # 汇总错误信息
assert self.mode in ["train", "test", "all"], "mode: %s not valid " %self.mode
print("Evaluating Benchmark: %s" % self.benchmark_name)
# 处理评估 ======================================================
# 加载所有序列的列表 'E:\\Alian\\yolov5\\MOTChallengeEvalKit-master\\seqmaps\\MOT17-train.txt'
self.sequences = np.genfromtxt(os.path.join(self.seqmaps_dir, self.seq_file), dtype='str', skip_header=True)
self.gtfiles = [] # 基准文件gt.txt全路径
self.tsfiles = [] # 评估结果全路径
for seq in self.sequences:
gtf = os.path.join(self.benchmark_gt_dir, self.mode ,seq, 'gt/gt.txt') # gt.txt
if path.exists(gtf): self.gtfiles.append(gtf)
else: raise Exception("Ground Truth %s missing" % gtf) # 判断文件是否存在
tsf = os.path.join(res_dir, "%s.txt" % seq)
if path.exists(gtf): self.tsfiles.append(tsf)
else: raise Exception("Result file %s missing" % tsf)
print('Found {} ground truth files and {} test files.'.format(len(self.gtfiles), len(self.tsfiles)))
print(self.tsfiles) # 打印全部的评估结果文件路径
# 设置多核处理
self.MULTIPROCESSING = True # 多处理
MAX_NR_CORES = 10 # 最大的处理量
if self.MULTIPROCESSING: self.NR_CORES = np.minimum(MAX_NR_CORES, len(self.tsfiles))
try:
""" 执行评估 """
self.results,self.Overall_Results = self.eval()
# 计算整体结果
results_attributes = self.Overall_Results.metrics.keys() # 评估指标(名称)
for attr in results_attributes:
""" 在多进程上累积评估值 """
try:
self.Overall_Results.__dict__[attr] = sum(obj.__dict__[attr] for obj in self.results)
except:
pass
cache_attributes = self.Overall_Results.cache_dict.keys() # 缓存属性
for attr in cache_attributes:
""" accumulate cache values over all sequences """
try:
self.Overall_Results.__dict__[attr] = self.Overall_Results.cache_dict[attr]['func']([obj.__dict__[attr] for obj in self.results])
except:
pass
print("evaluation successful")
# 计算clearmot指标
for res in self.results:
res.compute_clearmot()
self.Overall_Results.compute_clearmot()
summary = self.accumulate_df(type="mail")
# 将评估果写入csv文件
self.summary.to_csv('summary.csv')
self.failed = False
except Exception as e:
print(str(traceback.format_exc()))
print ("
Evaluation failed!
")
error_traceback+= str(traceback.format_exc())
self.failed = True
self.summary = None
end_time=time.time()
self.duration = (end_time - start_time)/60.
# 收集评估错误
if self.failed:
startExc = error_traceback.split("" )
error_traceback = [m.split("")[0] for m in startExc[1:]]
error = ""
for err in error_traceback:
error += "Error: %s" % err
print( "Error Message", error)
self.error = error
print("ERROR %s" % error)
print ("Evaluation Finished")
print("Your Results")
print(self.render_summary())
if save_pkl: # 保存评估结果
self.Overall_Results.save_dict(os.path.join( save_pkl, "%s-%s-overall.pkl" % (self.benchmark_name, self.mode)))
for res in self.results:
res.save_dict(os.path.join( save_pkl, "%s-%s-%s.pkl" % (self.benchmark_name, self.mode, res.seqName)))
print("Successfully save results")
return self.Overall_Results, self.results
def eval(self): # 实际使用时重写
raise NotImplementedError
def accumulate_df(self, type = None):
""" create accumulated dataframe with all sequences """
summary = None
for k, res in enumerate(self.results):
res.to_dataframe(display_name = True, type=type)
if k == 0: summary = res.df
else: summary = pd.concat([summary,res.df])
summary = summary.sort_index()
self.Overall_Results.to_dataframe(display_name=True, type=type)
self.summary = pd.concat([summary,self.Overall_Results.df])
return self.summary
def render_summary( self, buf = None): # 终端打印评估指标
"""
Params:
summary : pd.DataFrame
Kwargs:
buf : StringIO-like, optional 写入缓存区
formatters : dict, optional(为单个指标定义自定义格式化程序的字典){'mota': '{:.2%}'.format}.MetricsHost.formatters
namemap : dict, optional {'num_false_positives': 'FP'}
Returns:
string
"""
output = self.summary.to_string(
buf=buf,
formatters=self.Overall_Results.formatters,
justify="left"
)
return output
class My_Evaluator(object): # 多目标跟踪评估器类
""" 评估器类运行每个序列的评估并计算基准的整体性能"""
def __init__(self):
pass
def run(self, benchmark_name=None, gt_dir=None, mot_dir=None,save_csv = None):
self.benchmark_name = benchmark_name # 项目名称
start_time = time.time()
self.gtfiles = glob.glob('%s/*_gt.txt'%gt_dir) # 基准文件gt.txt全路径
self.tsfiles = glob.glob('%s/*_mot.txt'%mot_dir) # 评估结果全路径
self.sequences = [os.path.split(x)[-1].split('_')[0] for x in self.gtfiles]
print('Found {} ground truth files and {} test files.'.format(len(self.gtfiles), len(self.tsfiles)))
# 设置多核处理
self.MULTIPROCESSING = True # 多处理
MAX_NR_CORES = 10 # 最大的处理量
if self.MULTIPROCESSING: self.NR_CORES = np.minimum(MAX_NR_CORES, len(self.tsfiles))
try:
""" 执行评估 """
self.results,self.Overall_Results = self.my_eval()
# 计算整体结果
results_attributes = self.Overall_Results.metrics.keys() # 评估指标(名称)
for attr in results_attributes:
""" 在所有序列上累积评估值 """
try:
self.Overall_Results.__dict__[attr] = sum(obj.__dict__[attr] for obj in self.results)
except:
pass
cache_attributes = self.Overall_Results.cache_dict.keys() # 缓存属性
for attr in cache_attributes:
""" accumulate cache values over all sequences """
try:
self.Overall_Results.__dict__[attr] = self.Overall_Results.cache_dict[attr]['func']([obj.__dict__[attr] for obj in self.results])
except:
pass
print("evaluation successful")
# 计算clearmot指标
for res in self.results:
res.compute_clearmot()
self.Overall_Results.compute_clearmot()
summary = self.accumulate_df(type="mail")
# 将评估果写入csv文件
summary.to_csv(save_csv)
except:pass
end_time=time.time()
self.duration = (end_time - start_time)/60.
# 收集评估错误
print("Evaluation Finished")
print("Your Results")
print(self.render_summary())
print("Successfully save results")
return self.Overall_Results, self.results
def my_eval(self): # 实际使用时重写
raise NotImplementedError
def accumulate_df(self, type = None):
""" create accumulated dataframe with all sequences """
summary = None
for k, res in enumerate(self.results):
res.to_dataframe(display_name = True, type=type)
if k == 0: summary = res.df
else:summary = pd.concat([summary,res.df])
summary = summary.sort_index()
self.Overall_Results.to_dataframe(display_name=True, type=type)
self.summary = pd.concat([summary,self.Overall_Results.df])
return self.summary
def render_summary( self, buf = None): # 终端打印评估指标
"""
Params:
summary : pd.DataFrame
Kwargs:
buf : StringIO-like, optional 写入缓存区
formatters : dict, optional(为单个指标定义自定义格式化程序的字典){'mota': '{:.2%}'.format}.MetricsHost.formatters
namemap : dict, optional {'num_false_positives': 'FP'}
Returns:
string
"""
output = self.summary.to_string(
buf=buf,
formatters=self.Overall_Results.formatters,
justify="left"
)
return output
def run_metrics( metricObject, args ):
""" Runs metric for individual sequences
Params:
-----
metricObject: metricObject that has computer_compute_metrics_per_sequence function
args: dictionary with args for evaluation function
"""
metricObject.compute_metrics_per_sequence(**args) # 计算每个序列的指标
return metricObject
if __name__ == "__main__":
Evaluator()