C++程序员应了解的那些事(115)~类模板的分离式编译(类模板究竟要不要接口与实现分离)
目录
一、引言
二、类模板的分离式编译
模板分离式编译报错示例:“无法解析的外部符号”
无法解析的外部符号
模板分离式编译示例:(在源文件中显式声明要使用的模板实例类型)
三、类模板的一体化编译
四、我们该如何选择:类模板究竟要不要接口与实现分离
1. 类模板接口与实现分离的优点与缺点
2. 类模板接口与实现放在一起的优点与缺点
3. 你说了那么多,那我们的选择是…
五、拓展:为什么C++编译器不能支持对模板的分离式编译
六、扩展:C++类模板声明与实现分离的方法小结:
一、引言
只要是接触了 C++ 有一定时间的程序员,都会记住这么一个不成文的规定:
类模板的声明与实现最好放在同一个头文件中
这或许是来源于某次错误尝试的下意识的修改,又或许是简单搜索了下 C++ 类模板编译报错的原因,看到了满篇的诸如 “为什么 C++ 编译器不能支持对模板的分离式编译” 的博客,久而久之,就留下了这么一个印象。
那么实际上,如果你简单的记为 “C++ 编译器是不支持对模板的分离式编译的”,这样又有点以偏概全。那么,最准确的说法是什么呢?C++ 到底支不支持对模板的分离式编译的呢?让我来引用 《Data Structures And Algorithms Analysis In cpp》书中 1.6.5 节中的一段话:
Like regular classes, class templates can be implemented either entirely in theire declarations, or we can separate the interface from the implementation.
However, compiler support for separate compilation of templates historically has been weak and platform specific.
简单翻译下:
就像类一样,类模板是可以将其实现与声明放在一起的,或者也可以将接口与实现分离。
但是呢,编译器由于历史原因对于分离式编译的支持非常弱,并且因平台的不同支持力度有所不同。
那么接下来,在这一篇博客中,我们首先来探讨下为何类模板分离式编译会出错,以及我们会照着书上的例子,去解决分离式编译的报错问题;
然后,我们再来分析下,类模板究竟是分离式编译好,还是放在一个头文件中一起编译好。
二、类模板的分离式编译
在这一节中,我们就像编写一个普通的类一样,实现一个 MemoryCell 类的分离式编译,也就是将接口与实现分离,声明放到 MemoryCell.h 文件中,实现放到 MemoryCell.cpp 文件中,然后再编写一个 test.cpp 文件,看看编译会不会有问题。
模板分离式编译报错示例:“无法解析的外部符号”
Memory.h
#ifndef MEMORY_CELL_H
#define MEMORY_CELL_H
/**
* A class for simulating a memeory cell.
*/
template
class MemoryCell
{
public:
explicit MemoryCell(const Object & initialValue = Object{});
const Object & read() const;
void write(const Object & x);
private:
Object storedValue;
};
#endif
MemoryCell.cpp
#include "MemoryCell.h"
/**
* Construct the MemoryCell with initialValue.
*/
template
MemoryCell 可以看到,我们这里就像编写一个简单的类一样,将声明放到了 MemoryCell.h 中,并为 MemoryCell 这个类模板声明了构造、read 和 write 函数,接下来,我们继续写一个 test.cpp 用来调用 MemoryCell 类模板。
test.cpp
#include "MemoryCell.h"
#include
#include
using namespace std;
int main()
{
MemoryCell m1;
MemoryCell m2{ 3.14 };
m1.write(37);
m2.write(m2.read() * 2);
cout << m1.read() << endl;
cout << m2.read() << endl;
system("pause");
return 0;
}
test.cpp 中的内容非常简单,使用了 MemoryCell 和 MemoryCell 两种类型。接下来,让我们来编译一下它(环境是 VS 2017)。
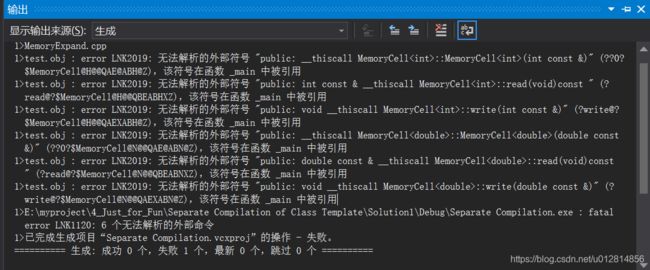
报错了,让我们来仔细看看报错信息。简单来说,就是在 test.obj 链接的时候,想要找到 MemoryCell
无法解析的外部符号
那让我们来仔细思考下,为什么会出现无法解析的外部符号的问题。
主要的问题就是,在我们 MemoryCell.cpp 文件中的代码并非实际上的函数,他们只是等待着扩展的模板而已。只有在 MemoryCell 模板被实例化了之后这些函数才会被扩展,也就是说,只有在调用的时候,成员函数模板才会被扩展开来。
那么问题的原因也就很清晰了,就是我们上面的代码,并没有类模板的实例化的过程。所以在编译器链接的时候,发现根本找不到 Memory
那么解决这个问题的方法也是很简单的,我们给它加上模板的实例化的代码就行了。
模板分离式编译示例:(解决方案:在源文件中显式声明要使用的模板实例类型)
让我们新增一个文件 MemoryExpand.cpp,在里面进行模板的实例化操作。
MemoryExpand.cpp
#include "MemoryCell.cpp"
template class MemoryCell;
template class MemoryCell;
尤其注意的是,这里包含的是 MemoryCell.cpp 文件。这下,我们就可以成功编译运行出来结果了:

为什么呢?我相信你一定有疑问,没事,我们一起来思考下。
就像我之前提到过的,实际上 MemoryCell.cpp 里面并不是实际上的函数,而是一个个模板。实际上你就可以将其认作是一个声明一样的东西,这里我们 #include MemoryCell.cpp 文件而不是 MemoryCell.h 头文件,是因为只有 MemoryCell.cpp 文件中有类模板实例化所需要的全部内容。MemoryCell.cpp 里面的模板,就像是万事俱备只欠东风一样,这个东风,就是类模板的实例化,让其全部活过来。
这样,我们就完成了类模板的接口与实现分离的分离式编译。最主要的就是要特别进行一下类模板的实例化操作,不然会出现找不到函数的问题。
或者我们可以直接这样修改:在源文件中显式声明要使用的模板实例类型
MemoryCell.cpp
......
template class MemoryCell;
template class MemoryCell;
三、类模板的一体化编译
相对应于分离式编译,我们也可以将类模板的接口与实现都放在一个头文件中,对比起来学习,或许效果更好,这里,就让我们试试。
MemoryCell.h
#ifndef MEMORY_CELL_H
#define MEMORY_CELL_H
/**
* A class for simulating a memeory cell.
*/
template
class MemoryCell
{
public:
explicit MemoryCell(const Object & initialValue = Object{});
const Object & read() const;
void write(const Object & x);
private:
Object storedValue;
};
/**
* Construct the MemoryCell with initialValue.
*/
template
MemoryCell test.cpp
#include "MemoryCell.h"
#include
#include
using namespace std;
int main()
{
MemoryCell m1;
MemoryCell m2{ 3.14 };
m1.write(37);
m2.write(m2.read() * 2);
cout << m1.read() << endl;
cout << m2.read() << endl;
system("pause");
return 0;
}
这两份代码编译是没有问题的,没有分离式编译,就没有那么复杂的链接问题。MemoryCell
可见,类模板将接口与实现放在头文件中进行编译,是非常简单并且不容易出错的。
四、我们该如何选择:类模板究竟要不要接口与实现分离
或许对于喜欢省事的朋友来说,管那么多干嘛,我只选择实现最简单的最不容易出错的,那么显然类模板的接口与实现放在一起是最好的选择。不过,我们还是严谨一些,认真分析一下优劣,这样能让我们的认知能够更加深刻一些。
1. 类模板接口与实现分离的优点与缺点
优点自然是逻辑清晰,不用多个每一个包含了类模板接口定义的源文件都包含一份实现的副本。而且就拿我们上面的例子来说,如果 MemoryCell 的实现发生了变化,也就是MemoryCell.cpp 文件有改动,那么需要重新编译的就只有 MemoryCellExpand.cpp 文件。相对来说耦合度有所降低。
缺点那就太明显,甚至有些许致命,C++ 编译器对于类模板的分离式编译支持不到位,跨平台兼容问题很大。甚至解决编译问题的方法,随着平台的不同有所不同。
2. 类模板接口与实现放在一起的优点与缺点
优点自然是简单不易错,不存在跨平台兼容问题。
缺点那就是在编译的时候,多份包含了类模板头文件定义的源文件会拥有重复的类模板成员函数实现的定义。不过正因为即使是类模板的实现也都是模板,不是类,所以这也不是很大的问题。
3. 你说了那么多,那我们的选择是…
其实我们只需要随着主流走就行。作为一个 C++ 程序员,STL 的地位毋庸置疑,STL 的类模板都是接口与实现放在一起的,我们随着主流走就可以。
五、拓展:为什么C++编译器不能支持对模板的分离式编译
首先,一个编译单元(translation unit)是指一个.cpp文件以及它所#include的所有.h文件,.h文件里的代码将会被扩展到包含它的.cpp文件里,然后编译器编译该.cpp文件为一个.obj文件(假定我们的平台是win32),后者拥有PE(Portable Executable,即windows可执行文件)文件格式,并且本身包含的就已经是二进制码,但是不一定能够执行,因为并不保证其中一定有main函数。当编译器将一个工程里的所有.cpp文件以分离的方式编译完毕后,再由连接器(linker)进行连接成为一个.exe文件。
举个例子:
//---------------test.h-------------------//
void f();//这里声明一个函数f
//---------------test.cpp--------------//
#include”test.h”
void f()
{
…//do something
} //这里实现出test.h中声明的f函数
//---------------main.cpp--------------//
#include”test.h”
int main()
{
f(); //调用f,f具有外部连接类型
}
在这个例子中,test. cpp和main.cpp各自被编译成不同的.obj文件(暂且命名为test.obj和main.obj),在main.cpp中,调用了f函数,然而当编译器编译main.cpp时,它所知道的仅仅是main.cpp中所包含的test.h文件中的一个关于void f();的声明,所以,编译器将这里的f看作外部连接类型,即认为它的函数实现代码在另一个.obj文件中,本例也就是test.obj,也就是说,main.obj中实际没有关于f函数的哪怕一行二进制代码,而这些代码实际存在于test.cpp所编译成的test.obj中。在main.obj中对f的调用只会生成一行call指令,像这样:
call f [C++中这个名字当然是经过mangling[处理]过的]
在编译时,这个call指令显然是错误的,因为main.obj中并无一行f的实现代码。那怎么办呢?这就是连接器的任务,连接器负责在其它的.obj中(本例为test.obj)寻找f的实现代码,找到以后将call f这个指令的调用地址换成实际的f的函数进入点地址。需要注意的是:连接器实际上将工程里的.obj“连接”成了一个.exe文件,而它最关键的任务就是上面说的,寻找一个外部连接符号在另一个.obj中的地址,然后替换原来的“虚假”地址。
这个过程如果说的更深入就是:
call f这行指令其实并不是这样的,它实际上是所谓的stub,也就是一个jmp 0xABCDEF。这个地址可能是任意的,然而关键是这个地址上有一行指令来进行真正的call f动作。也就是说,这个.obj文件里面所有对f的调用都jmp向同一个地址,在后者那儿才真正”call”f。这样做的好处就是连接器修改地址时只要对后者的call XXX地址作改动就行了。但是,连接器是如何找到f的实际地址的呢(在本例中这处于test.obj中),因为.obj与.exe的格式是一样的,在这样的文件中有一个符号导入表和符号导出表(import table和export table)其中将所有符号和它们的地址关联起来。这样连接器只要在test.obj的符号导出表中寻找符号f(当然C++对f作了mangling)的地址就行了,然后作一些偏移量处理后(因为是将两个.obj文件合并,当然地址会有一定的偏移,这个连接器清楚)写入main.obj中的符号导入表中f所占有的那一项即可。
这就是大概的过程。其中关键就是:
- 编译main.cpp时,编译器不知道f的实现,所以当碰到对它的调用时只是给出一个指示,指示连接器应该为它寻找f的实现体。这也就是说main.obj中没有关于f的任何一行二进制代码。
- 编译test.cpp时,编译器找到了f的实现。于是乎f的实现(二进制代码)出现在test.obj里。
- 连接时,连接器在test.obj中找到f的实现代码(二进制)的地址(通过符号导出表)。然后将main.obj中悬而未决的call XXX地址改成f实际的地址。完成。
然而对于模板,模板函数的代码其实并不能直接编译成二进制代码,其中要有一个“实例化”的过程。举个例子:
//----------main.cpp------//
template
void f(T t)
{}
int main()
{
…//do something
f(10); // call f 编译器在这里决定给f一个f的实例
…//do other thing
}
也就是说,如果你在main.cpp文件中没有调用过f,f也就得不到实例化,从而main.obj中也就没有关于f的任意一行二进制代码!如果你这样调用了:
f(10); // f得以实例化出来
f(10.0); // f得以实例化出来 这样main.obj中也就有了f
然而实例化要求编译器知道模板的定义,不是吗?看下面的例子(将模板的声明和实现分离):
/-------------test.h----------------//
template
class A
{
public:
void f(); // 这里只是个声明
};
//---------------test.cpp-------------//
#include”test.h”
template
void A::f() // 模板的实现
{
…//do something
}
//---------------main.cpp---------------//
#include”test.h”
int main()
{
A a;
a.f(); // #1
}
编译器在#1处并不知道A
关键是:在分离式编译的环境下,编译器编译某一个.cpp文件时并不知道另一个.cpp文件的存在,也不会去查找(当遇到未决符号时它会寄希望于连接器)。这种模式在没有模板的情况下运行良好,但遇到模板时就傻眼了,因为模板仅在需要的时候才会实例化出来,所以,当编译器只看到模板的声明时,它不能实例化该模板,只能创建一个具有外部连接的符号并期待连接器能够将符号的地址决议出来。然而当实现该模板的.cpp文件中没有用到模板的实例时,编译器懒得去实例化,所以,整个工程的.obj中就找不到一行模板实例的二进制代码,于是连接器也黔驴技穷了。
六、扩展:C++类模板声明与实现分离的方法小结:
- 方法一、当抽象体较为简单时,最好将声明与实现放在一起!
- 方法二、在头文件中编写模板声明,在源文件中编写模板实现,并在头文件的模板声明后包含该对应的源文件(建议使用.inl)!注意,该源文件中只能用些编写该模板的实现内容,不要有其他无关的源码实现。
/// \brief 2-D Matrix class.
template< class T >
class Matrix
{
//friend class Array;
friend class Vector;
friend class SubMatrix;
public:
Matrix();
Matrix(const int rows, const int columns);
Matrix(const int rows, const int columns, T init);
Matrix(string str);
Matrix(Matrix &m); // copy constructor
~Matrix();
void Clean();
...
};
#include "Matrix.inl" // Matrix.inl文件中是模板实现 inl文件介绍
inl文件是内联函数的源文件。内联函数通常在C++头文件中实现,但是当C++头文件中内联函数过多的情况下,我们想使头文件看起来简洁点,能不能像普通函数那样将内联函数声明和函数定义放在头文件和实现文件中呢?当然答案是肯定的,具体做法将是:将内联函数的具体实现放在inl文件中,然后在该头文件末尾使用#include引入该inl文件。
由于编译器等不支持将模板函数、模板类等放单独分开编译,但是有了inl文件,我们可以把声明放在头文件中,然后将具体实现放在inl文件中。
对于比较大的工程来说,出于管理方面的考虑,模板函数、模板类的声明一般放在一个或少数几个头文件中,然后将其定义部分放在inl文件中。这样可以让工程结构清晰、明了。
- 方法三、当模板声明与实现分离时,在源文件中显式声明要使用的模板实例类型
template class TestTemplate;
template class TestTemplate;