通过构建可观测性进行故障治理
欢迎访问原文地址来阅读最新版本
转载请注明出处:https://www.kang.fun/observability
个人博客:kang.fun
1 可观测性
1.1 什么是可观测性
可观察性(observability)是指系统可以由其外部输出推断其其内部状态的程度。
— 「wikipedia - 可观测性」
在微服务架构盛行的当下,支撑一条业务所涉及的系统多、链路长,很多时候系统对我们来说就像一个黑盒,出现问题时,我们根本就无从下手。
所以我们需要一些手段来了解整个系统的内部运行情况,从而判断系统运行是否符合预期,建设系统的可观测性逐渐成为研发过程中必不可少的环节。
1.2 建设可观测性的价值
- 有利于故障排查
看清楚系统在做什么,才能分析系统行为是正确的还是错误的,通过清晰的运行情况展示,更容易定位错误出现在哪个服务,哪个流程,甚至哪一行代码。
- 有利于性能优化
通过统计分析系统每一步具体的调用过程,能够看出哪一步更容易出现问题,我们可以针对性的做出优化决策
- 有利于监控告警
当系统出现问题,我们肯定希望干系人能第一时间收到告警反馈,
- 有利于业务发展
通过统计分析用户行为,构建合理的目标用户画像,更容易的做出正确的业务战略决策。
对于系统参与人员,最头疼的就是系统故障,而故障响应是建立在使用可观测性系统构建的数据之上的。
1.3 如何建设系统的可观测性
OpenTelemetry组织提出了实现可观测性的三大支柱,分别是日志(Logs)、指标(Metrics)、链路追踪(Traces),该理论认为通过这三者我们可以了解系统的当前行为。
Logs
Metrics
Traces
日志 - Logs
日志是距离研发最近的增强系统可观测性的手段,查看日志能够帮助我们清楚了解系统的运行情况。可以说没有日志记录的系统,无异于“裸奔”。
缺点是,需要研发人员具备足够经验,了解日志打印的时机和日志输出的内容,才能保证日志全面、清晰、能够定位问题。
常用的日志管理方案是ELK,即Elastic Search + Logstash + Kibana,分别提供了对日志从采集、存储和可视化分析的成套方案。
指标 - Metrics
指标是指带有时间属性的统计值,比如硬件性能、访问量、订单金额,通常可以通过指标来判定系统情况、用户画像、业务KPI等等。
常用指标采集方式如Prometheus,他的特点是提供了完整的指标采集、指标存储、指标统计和监控告警能力,配合Grafana可轻松配置出监控大盘。
链路追踪 - Traces
微服务的特点是节点多且扁平,日志的视角是系统运行的记录,链路追踪的视角是事件流转的过程。通过记录跟踪数据,能够完整还原请求的调用链路,请求流过哪些节点、每个节点的请求状态、节点的处理耗时。有了这些信息,我们能够生成调用链路的可视化界面,并且非常容易的进行根因分析。
链路追踪最早可追溯到Google在 2010 年发表的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,其阐述了记录链路追踪的基本原理,包括记录、采样、存储等。根据这篇论文提供的思路,业界出现了CAT,ZIPKIN,SKYWALKING等成熟的全链路追踪产品,能够帮助我们查看同一条请求链路的调用过程、性能,以此进行故障定位、系统性能优化。
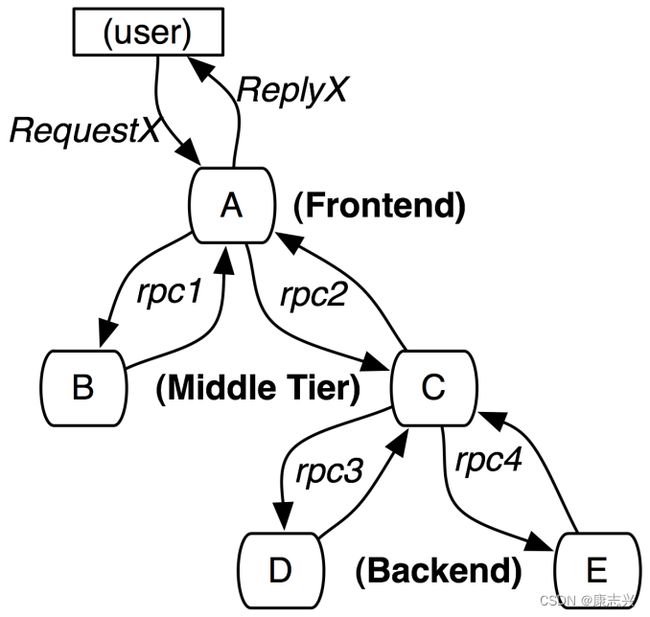
2 故障响应
在生产环境下,系统发生故障会对用户造成直接影响。而故障发生后,又经常出现排查问题困难的问题,这就需要通过上述“三大支柱”来建设故障响应机制。
一套完善的故障响应机制,应当具备以下能力:
- 故障发生能够及时发现
- 故障告警能够及时通知
- 可预见的故障,能够触发相关预案
2.1 故障响应机制
故障响应机制通常由这三个方面组成:
-
故障监控
故障出现时,监控系统能第一时间发现异常。这就需要对指标进行采集,并提供灵活的监控策略配置能力来对指标进行分析,判定其是否出现异常,从而发现系统故障。
监控范围不应仅仅聚焦在代码级别,不管是硬件性能、接口性能,还是业务异常,都需要作为我们的关注内容。
随着系统不断发展,监控的策略也可能发生变化。比如系统刚上线时,可能偶尔的波动不会造成任何影响,但随着业务发展,请求量的不断攀升,很可能导致原有的系统性能冗余慢慢降低。所以,监控策略应随系统演进而不断调整。
-
故障告警
告警策略要保证故障发生或者恢复,每一个干系人都能及时知晓。告警通知内容应具备可读性,并且能够准确的提供故障信息和故障原因。
相关人员发现告警后,应在查询问题、修复问题的同时,做好信息同步,帮助其他人了解故障处理进度。
-
故障恢复
每一个系统都应当有常见故障场景的预设处理方案,保证处理故障的人员能够最快速的解决问题,降低影响。
对于常见故障场景,最好能够提供自动降级甚至修复的机制,最大程度减少故障影响。
2.2 故障监控层次
-
资源监控
资源监控包括CPU、内存、硬盘、带宽、端口等硬件指标,常见的CPU飙高、磁盘I/O缓慢都应该发出报警。监控范围不限于系统应用本身,还包括依赖的中间价所在容器环境等。
这些都属于标准化指标,常规监控平台都提供了类似的能力。
-
系统监控
系统监控相对资源监控来说没有那么标准化,但很多指标也是通用的,比如平均响应时间、最大响应时间、TPS、TP99、慢SQL、GC情况等等。
-
业务监控
业务监控没有通用指标,需要系统相关人员通过系统业务特性进行配置,比如订单系统可以监控其单位时间内下单次数,如果突然减少说明可能订单模块出了问题,大量订单长时间未进行支付可能支付渠道出了问题。对于这类问题进行针对性的监控,才能保障系统7*24的可靠性。
2.3 故障后续处理
故障处理完成之后,还应当进行以下事项:
-
记录
提供对于类似故障的应对参考,并对后续系统建设提供决策依据。
-
排查
故障发生后,应当对系统进行整体排查,对于同类问题一并解决,并做出应急预案。
-
复盘
对于线上故障,应当做好复盘,原则是对事不对人,目的是减少同类故障的再次发生。
3 最后
对于软件系统,不应只是提供了各项业务功能,还应当具备处理异常情况的能力,这就需要不断构建可观察体系,并以此建设完善的故障响应机制,在安全生产的基础上不断演进,这样才建立了良性闭环。
参考:
-
https://www.splunk.com/en_us/data-insider/what-is-observability.html
-
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/papers/dapper-2010-1.pdf
-
https://opentelemetry.io/docs/concepts/observability-primer/#distributed-traces