【JavaEE】Synchronized原理、JUC以及线程安全的集合类手术刀剖析
文章目录
- 一、Synchronized 原理
-
- 1.synchronized的基本特点
- 2.synchronized典型的优化手段
-
- 2.1.锁膨胀/锁升级
- 2.2. 锁粗化
- 2.3.锁消除
- 二、JUC(java.util.concurrent)
-
- 1.Callable 接口
- 2.ReentrantLock
- 3.原子类
- 4.线程池
- 5.信号量 Semaphore
- 6.CountDownLatch
- 三、线程安全的集合类
-
- 1.多线程环境使用 ArrayList
- 2.多线程环境使用哈希表
- 3.相关面试题
- 四、最后
一、Synchronized 原理
1.synchronized的基本特点
以JDK1.8为例:
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁;
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁;
- 实现轻量级锁的时候大概率用到的自旋锁策略;
- 是一种不公平锁;
- 是一种可重入锁;
- 不是读写锁。
2.synchronized典型的优化手段
这些典型的优化手段都是编译器、操作系统、jvm、CPU相互配合完成的。
2.1.锁膨胀/锁升级
体现了synchronized能够“自适应”的能力。
加锁的工作过程如下:
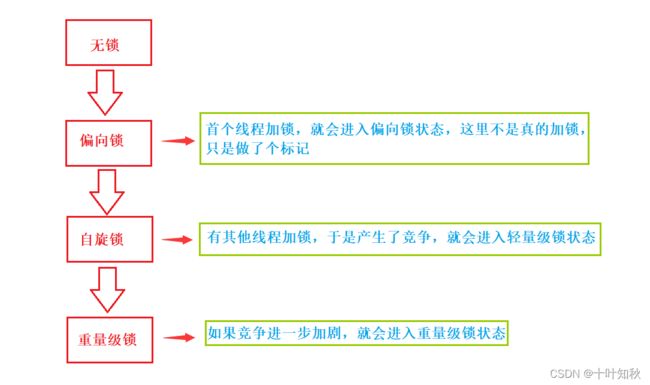
JVM 将 synchronized 锁分为 无锁、偏向锁、轻量级锁、重量级锁 状态。会根据情况,进行依次升级。
 下面详细讲解一下具体的过程:
下面详细讲解一下具体的过程:
(1) 偏向锁
第一个尝试加锁的线程, 优先进入偏向锁状态。
偏向锁不是真的 “加锁”, 只是给对象头中做一个 “偏向锁的标记”, 记录这个锁属于哪个线程。
如果后续没有其他线程来竞争该锁, 那么就不用进行其他同步操作了(避免了加锁解锁的开销)。
如果后续有其他线程来竞争该锁(刚才已经在锁对象中记录了当前锁属于哪个线程了, 很容易识别当前申请锁的线程是不是之前记录的线程), 那就取消原来的偏向锁状态, 进入一般的轻量级锁状态。
偏向锁本质上相当于 “延迟加锁” . 能不加锁就不加锁, 尽量来避免不必要的加锁开销。
但是该做的标记还是得做的, 否则无法区分何时需要真正加锁。
举个不恰当的例子:现在很多年轻人同居但不结婚,这个同居就如同我们之间做了一个标记一样,它的好处就是我们不用像结婚之后承担那么多东西,也可以很甜蜜的生活在一起。但是有一天,男方或者女方有其他的人在追,于是另外一方就希望赶紧结婚,将这段关系进行法律上的认证,让其他追求者死心。那么这个结婚过程就是偏向锁升级到轻量级锁的过程。
(2)轻量级锁
随着其他线程进入竞争, 偏向锁状态被消除, 进入轻量级锁状态(自适应的自旋锁)。
此处的轻量级锁就是通过 CAS 来实现:
- 通过 CAS 检查并更新一块内存 (比如 null => 该线程引用)
- 如果更新成功, 则认为加锁成功
- 如果更新失败, 则认为锁被占用, 继续自旋式的等待(并不放弃 CPU)
自旋操作是一直让 CPU 空转, 比较浪费 CPU 资源.
因此此处的自旋不会一直持续进行, 而是达到一定的时间/重试次数, 就不再自旋了.
也就是所谓的 “自适应”。
(3)重量级锁
如果竞争进一步激烈, 自旋不能快速获取到锁状态, 就会膨胀为重量级锁。
此处的重量级锁就是指用到内核提供的 mutex :
- 执行加锁操作, 先进入内核态;
- 在内核态判定当前锁是否已经被占用;
- 如果该锁没有占用, 则加锁成功, 并切换回用户态;
- 如果该锁被占用, 则加锁失败. 此时线程进入锁的等待队列, 挂起. 等待被操作系统唤醒;
- 经历了一系列的沧海桑田, 这个锁被其他线程释放了, 操作系统也想起了这个挂起的线程, 于是唤醒这个线程, 尝试重新获取锁。
2.2. 锁粗化
锁粗化对应的就是锁细化,这里的粗细指的是锁的粒度。
锁的粒度:加锁代码涉及到的范围,加锁代码的范围越大,认为锁的粒度越粗;范围越小,则认为粒度越细。

实际开发过程中, 使用细粒度锁, 是期望释放锁的时候其他线程能使用锁,但是实际上可能并没有其他线程来抢占这个锁. 这种情况 JVM 就会自动把锁粗化, 避免频繁申请释放锁。
那么到底锁的粒度粗好还是细好?
各有各的好,如果锁粒度比较细的话,多个线程之间的并发性就更高;如果锁粒度比较粗的话,加锁解锁的开销就更小。
我们编译器和JVM面对锁的粒度问题会有这样的一个优化,如果某个地方的代码粒度太细了,也就是进行频繁的加锁解锁,它就会进行优化,使锁的粒度变粗;如果两次加锁之间的间隔较大,中间隔的代码多,一般不会进行这个优化。
2.3.锁消除
我们有些代码是不用加锁的,但是我们也给上锁了,这个时候编译器就会检查发现这个加锁好像没什么必要,就直接把锁给去掉了。比如说,我们的代码里面只有一个线程,这个时候加锁就没有意义了,编译会把我们加的锁去掉。
二、JUC(java.util.concurrent)
这个包里面提供了大量应用于线程的一些工具类,供我们在不同需求上进行应用。
1.Callable 接口
callable是一个interface,同时也是一个创建线程的方式。它相当于把线程封装了一个 “返回值”,方便程序猿借助多线程的方式计算结果。而我们的Runnable虽然也可以创建线程,但是它不适合让线程计算出一个结果。
例如,创建一个线程,让这个线程计算出1+2+3+…+1000。如果此时基于Runnable来实现的话,就会比较麻烦。而callable就能解决Runnable不方便返回结果的这个问题。
(1)使用Runnable方法来实现。
- 创建一个类 Result , 包含一个 sum 表示最终结果, lock 表示线程同步使用的锁对象.
- main 方法中先创建 Result 实例, 然后创建一个线程 t. 在线程内部计算 1 + 2 + 3 + … + 1000.
- 主线程同时使用 wait 等待线程 t 计算结束. (注意, 如果执行到 wait 之前, 线程 t 已经计算完了, 就不必等待了).
- 当线程 t 计算完毕后, 通过 notify 唤醒主线程, 主线程再打印结果
public class Demo9 {
static class Result{
public int sum = 0;
public Object lock = new Object();
}
public static void main(String[] args) throws InterruptedException {
Result result = new Result();
Thread t = new Thread(){
@Override
public void run() {
int sum = 0;
for (int i = 0; i <= 1000 ; i++) {
sum+=i;
}
synchronized (result.lock){
result.sum = sum;
result.lock.notify();
}
}
};
t.start();
synchronized (result.lock){
while (result.sum == 0){
result.lock.wait();
}
System.out.println(result.sum);
}
}
}

可以看到, 上述代码需要一个辅助类 Result, 还需要使用一系列的加锁和 wait notify 操作, 代码复杂, 容易出错.
(2)使用Callable接口
- 创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型.
- 重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返回计算结果.
- 把 callable 实例使用 FutureTask 包装一下.
- 创建线程, 线程的构造方法传入 FutureTask . 此时新线程就会执行 FutureTask 内部的 Callable 的call 方法, 完成计算. 计算结果就放到了 FutureTask 对象中.
- 在主线程中调用 futureTask.get() 能够阻塞等待新线程计算完毕. 并获取到 FutureTask 中的结果
public class Demo10 {
public static void main(String[] args) {
//通过callable来描述一个任务
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <= 1000; i++) {
sum += i;
}
return sum;
}
};
//为了让线程执行callable中的任务,需要一个辅助类
FutureTask<Integer> task = new FutureTask<>(callable);
//创建线程,来完成这里的计算工作
Thread t = new Thread(task);
t.start();
// 如果线程的任务没有执行完呢, get 就会阻塞.
// 一直阻塞到, 任务完成了, 结果算出来了
try {
System.out.println(task.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
 可以看到, 使用 Callable 和 FutureTask 之后, 代码简化了很多, 也不必手动写线程同步代码了
可以看到, 使用 Callable 和 FutureTask 之后, 代码简化了很多, 也不必手动写线程同步代码了
这里解释一下callable与FutureTask :
- Callable 和 Runnable 相对, 都是描述一个 “任务”. Callable 描述的是带有返回值的任务;
- Runnable 描述的是不带返回值的任务;
- Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定.那么FutureTask负责这个等待结果出来的工作。
相关面试题:介绍下 Callable 是什么?
- Callable 是一个 interface . 相当于把线程封装了一个 “返回值”. 方便程序猿借助多线程的方式计算结果.
- Callable 和 Runnable 相对, 都是描述一个 “任务”. Callable 描述的是带有返回值的任务,
- Runnable 描述的是不带返回值的任务
- Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定,那么FutureTask负责这个等待结果出来的工作。
2.ReentrantLock
ReentrantLock是可重入锁,与synchronized一样。
ReentrantLock 的基本用法:
- lock(): 加锁, 如果获取不到锁就死等.
- trylock(超时时间): 加锁, 如果获取不到锁, 等待一定的时间之后就放弃加锁.
- unlock(): 解锁
ReentrantLock 和 synchronized 的区别:
- synchronized是一个关键字,背后的逻辑是JVM实现的,也就是用c++来写的;而ReentrantLock 是一个标准库中的类,背后的逻辑是Java代码写的。
- synchronized不需要手动释放锁,出了代码块,锁自然释放;ReentrantLock 必须手动释放锁,因此,使用ReentrantLock 要记得释放。
- synchronized如果竞争锁失败,就会阻塞等待;而ReentrantLock 锁竞争失败之后,除了会阻塞等待,还可以使用trylock操作,如果失败了就直接返回。
- synchronized是一个非公平锁;而ReentrantLock 提供了公平锁与非公平锁两种,在构造方法中,我们可以通过参数来指定当前是公平锁还是非公平锁。
- 基于synchronized衍生出来的等待机制,是wait与notify,功能相对有限, 每次唤醒的是一个随机等待的线程;而基于ReentrantLock 衍生出来的等待机制,是Condition类,功能会更丰富一些,可以更精确控制唤醒某个指定的线程。
那么我该如何选择这两个加锁工具呢?
- 锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便.
- 锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制加锁的行为, 而不是死等.
- 如果需要使用公平锁, 使用 ReentrantLock
但在我们的实际开发中,synchronized就够用了。
3.原子类
原子类内部用的是 CAS 实现,所以性能要比加锁实现 i++ 高很多。原子类有以下几个
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicLong
- AtomicReference
- AtomicStampedReference
这篇文章里面有原子类的介绍与用法:【JavaEE】常见锁策略与CAS手术刀剖析
4.线程池
这篇文章详细介绍了线程池:【JavaEE】多线程案例——定时器与线程池
5.信号量 Semaphore
信号量, 用来表示 “可用资源的个数”. 本质上就是一个计数器。
举个例子:
可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源.
当有车开进去的时候, 就相当于申请一个可用资源, 可用车位就 -1 (这个称为信号量的 P 操作)
当有车开出来的时候, 就相当于释放一个可用资源, 可用车位就 +1 (这个称为信号量的 V 操作)
如果计数器的值已经为 0 了, 还尝试申请资源, 就会阻塞等待, 直到有其他线程释放资源.
Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用。
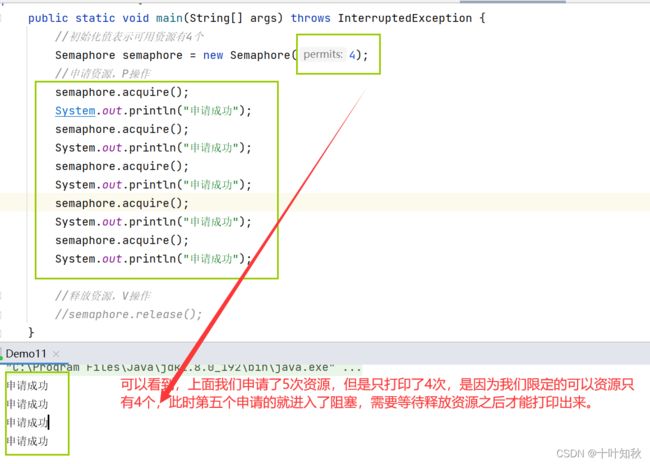
public class Demo11 {
public static void main(String[] args) throws InterruptedException {
//初始化值表示可用资源有4个
Semaphore semaphore = new Semaphore(4);
//申请资源,P操作
semaphore.acquire();
System.out.println("申请成功");
semaphore.acquire();
System.out.println("申请成功");
semaphore.acquire();
System.out.println("申请成功");
semaphore.acquire();
System.out.println("申请成功");
semaphore.acquire();
System.out.println("申请成功");
//释放资源,V操作
semaphore.release();
}
}
6.CountDownLatch
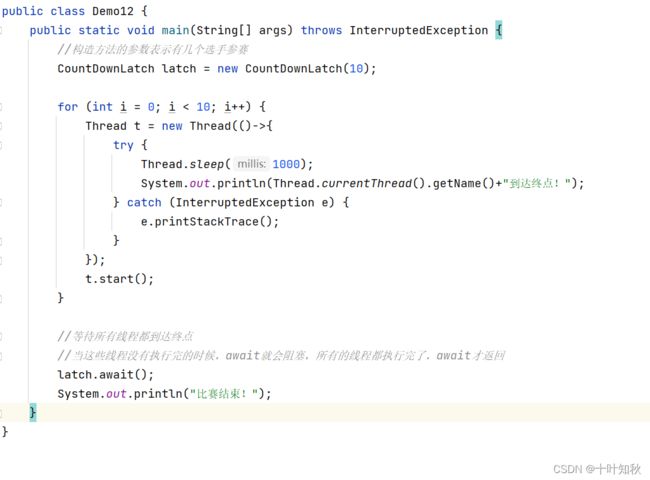
CountDownLatch表示同时等待 N 个任务执行结束。
在现实生活中,比如说我们下载电影,如果通过多线程下载的话就可以提高下载速度了。因为我们可以把一个文件拆分成多个部分,每个线程负责下载其中的一个部分,然后等到所有的线程都下载完成了,我们的电影才算下载完毕。
CountDownLatch里面我们提供了两个方法:
- countDown:给每个线程里面去调用,表示到达终点。
- await:给等待线程去调用,当所有的任务都到达终点了await就从阻塞队列中返回,表示任务完成。
下面举一个例子:跑步比赛,10个选手依次就位,枪一响同时出发,但是我们要等到所有选手都通过了终点线,才公布成绩。

三、线程安全的集合类
线程安全与线程不安全的类:
| 线程不安全 | 线程安全 |
|---|---|
| ArrayList | Vector (不推荐使用) |
| LinkedList | HashTable (不推荐使用) |
| HashMap | ConcurrentHashMap |
| TreeMap | StringBuffer |
| HashSet | String(特殊的) |
| TreeSet | |
| StringBuilder |
1.多线程环境使用 ArrayList
上面的表格里我们可以看到,ArrayList是一个线程不安全的类,那么我们在多线程的情况下该如何使用ArrayList呢?
我们有以下解决方案:
- 自己使用同步机制 (synchronized 或者 ReentrantLock)
- Collections.synchronizedList(new ArrayList):
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List;
synchronizedList 的关键操作上都带有 synchronized
(这里会把我们传进去的ArrayList加一层锁,这里不像第一种自己加锁灵活,因为我们有的方法涉及到线程安全就加锁,有些不涉及到就不用加锁,而这里的这个操作就会全加,那这跟volatile其实就差不多。这是一个选择,但不是特别好的选择) - 使用 CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器。
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素。
添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
优点:
在读多写少的场景下, 性能很高, 不需要加锁竞争.
缺点:
- 占用内存较多.
- 新写的数据不能被第一时间读取到
2.多线程环境使用哈希表
HashMap本身是线程不安全的,我们的解决方案有以下两种:
- HashTable
- ConcurrenHashMap
上面两种方式,我们不推荐使用HashTable,而是推荐使用ConcurrenHashMap。为什么呢?我们需要了解一下HashTable的内部构造,以及它与ConcurrenHashMap的区别。
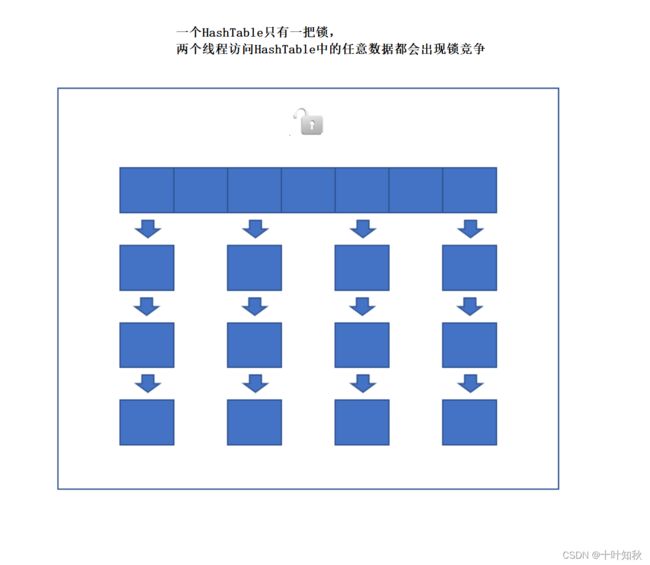
HashTable是如何保证线程安全的呢?
HashTable保证线程安全的方式是给关键方法加锁:
 这相当于直接针对 Hashtable 对象本身加锁.
这相当于直接针对 Hashtable 对象本身加锁.
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
- size 属性也是通过 synchronized 来控制同步, 也是比较慢的.
- 一旦触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低.
那么这里,我们的ConcurrenHashMap就能够解决这个问题。ConcurrenHashMap进行操作的时候,是针对这个元素所在的链表的头节点进行加锁的,如果两个线程操作的是针对两个不同的链表上的元素,那么没有线程安全的问题,不毕加锁。
由于在hash表中,链表的数目非常多,每个链表的长度是相对短的,因此可以保证锁冲突的概率就非常小了。
与上面的hashTable相比,这里的改动影响是非常大的。通过这样一个把大锁化小锁的,化整为零的过程,就可以巧妙的使我们的锁冲突大大降低。
总结:相比于 Hashtable 做出了一系列的改进和优化:
- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作进行加锁. 加锁的方式仍是是用 synchronized, 但是不是锁整个对象, 而是 “锁桶” (用每个链表的头结点作为锁对象), 大大降低了锁冲突的概率;
- 充分利用 CAS 特性. 比如 size 属性通过 CAS 来更新. 避免出现重量级锁的情况;
- 优化了扩容方式: 化整为零。
对于HashTable来说,只要这次的put触发了扩容,就会导致这次put操作非常卡顿。而对于ConcurrenHashMap来说:
- 发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去.
- 扩容期间, 新老数组同时存在.
- 后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小部分元素.搬完最后一个元素再把老数组销毁.
- 这个期间, 插入只往新数组加,查找需要同时查新数组和老数组
3.相关面试题
- ConcurrentHashMap的读是否要加锁,为什么?
读操作没有加锁. 目的是为了进一步降低锁冲突的概率. 为了保证读到刚修改的数据, 搭配了volatile 关键字。
- 介绍下 ConcurrentHashMap的锁分段技术?
这个是 Java1.7 中采取的技术. Java1.8 中已经不再使用了,简单的说就是把若干个哈希桶分成一个"段" (Segment), 针对每个段分别加锁,目的也是为了降低锁竞争的概率. 当两个线程访问的数据恰好在同一个段上的时候, 才触发锁竞争。
- ConcurrentHashMap在jdk1.8做了哪些优化?
取消了分段锁, 直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头结点对象作为锁对象)。将原来 数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式. 当链表较长的时候(大于等于8 个元素)就转换成红黑树。
- Hashtable和HashMap、ConcurrentHashMap 之间的区别?
HashMap: 线程不安全. key 允许为 null。
Hashtable: 线程安全. 使用 synchronized 锁 Hashtable 对象, 效率较低. key 不允许为 null。
ConcurrentHashMap: 线程安全. 使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用CAS 机制. 优化了扩容方式. key 不允许为 null。
四、最后
写完这篇文章,也算跌跌撞撞把多线程搞完了,其中由于学艺不精,必有不尽人意和讲不清楚的地方,但是整理这些文章的目的在于自己的复习用,对象针对的更多是自己,半点墨水没有,不敢说文章能给他人有些许启发,若是有一丁点,便是幸事;若难以启发,便权当自己以后回顾时用。