Scala编程指南(快速入门)
概述
Scala用一种简洁的高级语言将面向对象和函数式编程结合在一起。传统业务开发, 领域模型设计(面向对象开发); 大数据开发 - 数据集计算模型-(函数式编程)。函数编程强调的是程序对数据的运行算能力。在面向对象计算数据的时候采取代码不动移动数据.在函数式编程计算的时候数据不动代码动。Scala是一门多范式的编程语言,同时支持面向对象和面向函数编程风格。它以一种优雅的方式解决现实问题。虽然它是强静态类型的编程语言,但是它强大的类型推断能力,使其看起来就像是一个动态编程语言一样。Scala语言最终会被翻译成java字节码文件,可以无缝的和JVM集成,并且可以使用Scala调用java的代码库。除了Scala编程语言自身的特性以外,目前比较流行的Spark计算框架也是使用Scala语言编写。Spark 和 Scala 能够紧密集成,例如 使用Scala语言操作大数据集合的时候,用户可以像是在操作本地数据集那样简单操作Spark上的分布式数据集-RDD(这个概念是Spark 批处理的核心术语),继而简化大数据集的处理难度,简化开发步骤。
编程查询指南:https://docs.scala-lang.org/tour/tour-of-scala.html
环境配置
下载对应的scala版本:https://www.scala-lang.org/download/2.11.12.html
Windows版本安装
- 点击
scala-2.11.12.msi双击msi文件安装 - 配置Scala的环境变量SCALA_HOME变量
SCALA_HOME=C:\Program Files (x86)\scala
PATH=C:\Program Files\Java\jdk1.8.0_161/bin;C:\Program Files (x86)\scala/bin;
- 打开Window窗口
C:\Users\Administrator>scala
Welcome to Scala 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161).
Type in expressions for evaluation. Or try :help.
scala>
CentOS安装
- 下载
scala-2.11.12.rpm - 安装配置Scala
[root@CentOS ~]# rpm -ivh scala-2.11.12.rpm
Preparing... ########################################### [100%]
1:scala ########################################### [100%]
[root@CentOS ~]# scala
Welcome to Scala 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171).
Type in expressions for evaluation. Or try :help.
scala>
IDEA集成Scala开发环境
在File>Setting>Plugins点击 install plugin from disk选项,选择 scala-intellij-bin-2018.2.11.zip安装成功后,重启IDEA。
变量
Scala是一种纯粹的面向对象编程的语言。Scala语言中没有原始数据类型,这一点和Java语言不同,在Scala中一切皆对象。以下是Scala语言中常见类型和类型间的继承关系。
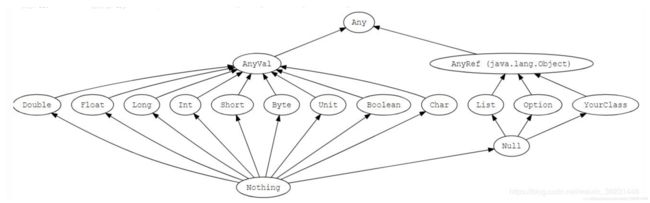
在Java中常见的基本类型在Scala中都被剔除了,Scala将值类型和引用类型分离。所有的数值变量类型都是 AnyVal的子类,这些变量的值都有字面值。对于一些对象类型的变量都是 AnyRef的子类。对于 AnyRef类下的变量(除String类型),一般不允许直接赋值字面量,都需要借助 new关键创建。
变量声明
Scala语言是一种可以做类型自动推断的强类型的编程语言。变量的类型可通过编译器在编译的时候推断出最终类型。因此Scala中声明一个变量主需要告知编译器该变量的值是常量还是变量,例如:例如声明一个变量使用var即可,如果声明的是一个常量使用val关键字。因此Scala中变量声明的语法如下:
var|val 变量名字[:类型]=变量值[:类型]
scala> var i:Int=1:Int
i: Int = 1
scala> var j=100:Byte
j: Byte = 100
scala> j=i
<console>:13: error: type mismatch;
found : Int
required: Byte
j=i
^
scala> var k=100
k: Int = 100
scala> k=1.0d
<console>:12: error: type mismatch;
found : Double(1.0)
required: Int
k=1.0d
^
Scala虽然可以做类型自动推断,类型一旦确定,不允许更改-强类型编程语言。
val表示声明常量。
scala> val i=123
i: Int = 123
scala> i=456
<console>:12: error: reassignment to val
i=456
^
总结:所有AnyVal类型的子类在声明字面值的时候,系统一般都可以自动推断出字面量类型,所以一般情况下可以省略类型的声明。
数值转换-√
数据类型兼容,且由小到大可以直接赋值。
scala> var b:Byte= 100
b: Byte = 100
scala> var i:Int = 12
i: Int = 12
scala> i=b
i: Int = 100
由大到小需要强转
scala> var b:Byte= 100
b: Byte = 100
scala> var i:Int = 12
i: Int = 12
scala> b=i
<console>:13: error: type mismatch;
found : Int
required: Byte
b=i
^
scala> b=i.asInstanceOf[Byte] # 类型强转
b: Byte = 100
scala> var f=1.0f
f: Float = 1.0
scala> var d=2.0d
d: Double = 2.0
scala> d=f
d: Double = 1.0
scala> f=d
<console>:13: error: type mismatch;
found : Double
required: Float
f=d
^
scala> f=d.asInstanceOf[Float]
f: Float = 1.0
注意能够实现数值转换的,要求类型必须是兼容的。
scala> var num="123"
num: String = 123
scala> var i:Int=100
i: Int = 100
scala> i=num
<console>:13: error: type mismatch;
found : String
required: Int
i=num
^
scala> i=num.asInstanceOf[Int]
java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Integer
at scala.runtime.BoxesRunTime.unboxToInt(BoxesRunTime.java:101)
... 32 elided
String转换为AnyVal类型-√
scala> var a="100.5"
a: String = 100.5
scala> var d=1.0D
d: Double = 1.0
scala> d=a.toDouble
d: Double = 100.5
用户可以调用toInt/toDouble/toFloat/toBoolean等将任意字符串类型转换为值类型
数组
Scala提供了简便的声明和使用数组的方式,例如声明一个Int类型的数组,则使用如下:
scala> var a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> var a=new Array[Int](5)
a: Array[Int] = Array(0, 0, 0, 0, 0)
获取数组的值
scala> var a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> a(1)
res0: Int = 2
scala> a(0)
res1: Int = 1
scala> a(0)= -1
scala> a
res3: Array[Int] = Array(-1, 2, 3, 4, 5)
scala> a.length
res4: Int = 5
scala> a.size
res5: Int = 5
遍历一个数组
scala> for(i <- 0 until a.length ) println(a(i))
-1
2
3
4
5
scala> a.foreach(item=> println(item)) //细化的
1
2
3
4
5
元组-√
由若干个指定类型的元素 合变量(变量的属性不可更改),称为元组类型。
scala> var a=(1,"zhangsan",true,18)
a: (Int, String, Boolean, Int) = (1,zhangsan,true,18)
scala> a = (2,"lisi",false,19)
a: (Int, String, Boolean, Int) = (2,lisi,false,19)
元组数据访问
scala> a
res1: (Int, String, Boolean, Int) = (2,lisi,false,19)
scala> a._1
res2: Int = 2
scala> a._2
res3: String = lisi
scala> a._2 = "wangwu"
<console>:12: error: reassignment to val
a._2 = "wangwu"
^
元组中元素都是只读的,一般有值类型和String类型构成。在Scala一个Tuple最多能够有22个成员。元组中的元素都是val类型不允许修改(只读),但是元组变量可以修改
Unit类型
Scala中将void作为保留关键字,使用Unit作为void替换品,在Scala中Unit表示什么也没有的对象。因此字面量()
scala> var u=()
u: Unit = ()
scala>
分支循环
if条件分支
语法
if(条件){
}else if(条件){
}
...
else{
}
var age=35
if(age<18){
print(s"你是少年,你的年龄:${age}")
}else if(age<30){
println(s"你是青年,你的年龄:${age}")
}else{
println(s"你是中年,你的年龄:${age}")
}
根据age参数计算msg的取值,可以看出在Scala语法中
if分支可以作为变量的赋值语句。可以将分支中返回的结果作为返回值,在利用分支做赋值的时候,不可以给return关键字,系统会自动将代码块最后一行的结果作为返回值。
var message= if(age<18){
println("======")
s"你是少年,你的年龄:${age}"
}else if(age<30){
println("++++++")
s"你是青年,你的年龄:${age}"
}else{
println("-----")
s"你是中年,你的年龄:${age}"
}
println(s"最终结果:$message")
while、do-while
while(条件){
//循环体
}
在scala中while和do-while没有continue和break关键字。
var i=5
while (i>0){
println(s"当前i的值:${i}")
i = i-1
}
println("~~~~~~~~~~~~~~~~~")
i=5
do{
println(s"当前i的值:${i}")
i = i-1
}while(i>0)
Breaks
Scala 语言中默认是没有 break 语句,但是在 Scala 2.8 版本后可以使用另外一种方式来实现 break 语句。当在循环中使用 break 语句,在执行到该语句时,就会中断代码块,程序直接跳出代码块。
scala> import scala.util.control.Breaks
import scala.util.control.Breaks
scala> var a=10
a: Int = 10
scala> var break=new Breaks
break: scala.util.control.Breaks = scala.util.control.Breaks@17eeaaf
scala> break.breakable({//代码块
| do{
| print("\t"+a)
| a -= 1
| if(a<=5){
| break.break()
| }
| }while(a>0)
| })
10 9 8 7 6
for循环-重点√
- 迭代遍历数组
scala> var array=Array(1,2,3,4)
array: Array[Int] = Array(1, 2, 3, 4)
scala> for(item <- array){print(item+"\t")}
1 2 3 4
- 通过下标遍历数组
scala> var array=Array(1,2,3,4)
array: Array[Int] = Array(1, 2, 3, 4)
scala> for(i <- 0 until array.length) {
| print(array(i))
| }
- for可使用多个循环因子
for(i <- 1 to 9){
for(j <- 1 to i){
print(s"$i * $j = "+(i*j)+"\t")
if(i==j) println()
}
}
scala> for(i <- 1 to 9;j <- 1 to i){
| print(s"${i}*${j} ="+i*j+"\t")
| if(i==j){
| println()
| }
| }
1*1 =1
2*1 =2 2*2 =4
3*1 =3 3*2 =6 3*3 =9
4*1 =4 4*2 =8 4*3 =12 4*4 =16
5*1 =5 5*2 =10 5*3 =15 5*4 =20 5*5 =25
6*1 =6 6*2 =12 6*3 =18 6*4 =24 6*5 =30 6*6 =36
7*1 =7 7*2 =14 7*3 =21 7*4 =28 7*5 =35 7*6 =42 7*7 =49
8*1 =8 8*2 =16 8*3 =24 8*4 =32 8*5 =40 8*6 =48 8*7 =56 8*8 =64
9*1 =9 9*2 =18 9*3 =27 9*4 =36 9*5 =45 9*6 =54 9*7 =63 9*8 =72 9*9 =81
- for和if的使用
scala> for(i<- 0 to 10;if(i%2==0)){
| print(i+"\t")
| }
0 2 4 6 8 10
- for和yield关键字实现元素的提取,创建子集(重点)
scala> var a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> var res=for(item<-a) yield item*item
res: Array[Int] = Array(1, 4, 9, 16, 25)
match-case(模式匹配)
在Scala中剔除java中switch-case语句,提供了match-case替代方案,该方案不仅仅可以按照值匹配,还可以按照类型、以及值得结构(数组匹配、元组匹配、case-class匹配等.).
- 值匹配
var a=Array(1,2,3)
var i=a(new Random().nextInt(3))
var res= i match {
case 1 => "one"
case 2 => "two"
case 3 => "three"
case default => null
}
println(res)
- 类型匹配
var a=Array(100,"张三",true,new Date())
var i=a(new Random().nextInt(4))
var res= i match {
case x:Int => s"age:${x}"
case x:String => s"name:${x}"
case x:Boolean => s"sex:${x}"
case _ => "啥都不是"
}
println(res)
注意
_表示默认匹配等价default关键字
√函数(方法)
函数声明
def 函数名(参数:参数类型,...):[返回值类型] = {
//方法实现
}
标准函数
def sum(x:Int,y:Int):Int = {
return x+y
}
或者
def sum02(x:Int,y:Int)= {
x+y
}
可以省略return关键字以及返回值类型,系统一般可以自动推断。将代码块最后一行作为返回值。
可变长参数
def sum03(values:Int*)= {
var total=0
for(i <-values){
total+=i
}
total
}
def sum04(values:Int*)= {
values.sum
}
注意:可变长参数必须放置在最后
命名参数
def sayHello(msg:String,name:String):Unit={
println(s"${msg}~ ${name}")
}
sayHello("hello","张三")
sayHello(name="张三",msg="hello")
参数默认值
def sayHello02(msg:String="哈喽",name:String):Unit={
println(s"${msg}~ ${name}")
}
def sayHello03(name:String,msg:String="哈喽"):Unit={
println(s"${msg}~ ${name}")
}
sayHello02(name="张三")
sayHello03("李四")
内嵌函数
def factorial(x:Int):Int={
def mulit(i:Int):Int={
if(i>1){
i*mulit(i-1)
}else{
1
}
}
mulit(x)
}
println(factorial(5))
√柯里化(Currying)
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术。
def sum02(x:Int,y:Int)= {
x+y
}
====
def sum04(x:Int)(y:Int):Int= {
x+y
}
scala> def sum04(x:Int)(y:Int):Int= {
| x+y
| }
sum04: (x: Int)(y: Int)Int
scala> sum04(1)(2)
res41: Int = 3
scala> var s=sum04(1)(_) # 部分应用函数
s: Int => Int = <function1>
scala> s(2)
res47: Int = 3
scala> var s2=sum04 _ #部分应用函数
s2: Int => (Int => Int) = <function1>
scala> s2(1)
res52: Int => Int = <function1>
scala> s2(1)(2)
res53: Int = 3
√匿名函数|方法
只有参数列表和返回值类型,没有方法名,通常使用匿名函数形式去声明一个函数式变量。
scala> var sum=(x:Int,y:Int)=> {x+y}
sum: (Int, Int) => Int = <function2>
scala> var multi=(x:Int,y:Int)=> {x*y}
multi: (Int, Int) => Int = <function2>
scala> println(sum(1,2)+" | "+multi(1,2))
3 | 2
def 关键字可以定义一个函数式变量。也可以声明一个标准方法。
def sum(x:Int,y:Int):Int = {
return x+y
}
def sum=(x:Int,y:Int)=>x+y
var sum=(x:Int,y:Int)=>x+y
var sum:(Int,Int)=> Int = (x,y)=> x+y
var sum = ((x,y)=> x+y):(Int,Int)=> Int
通过上述变换可以推导出 函数可以转换为变量,因此可以使用var或者val修饰函数式变量,又因为函数式变量是函数,所以可以使用def修饰。
def method(op:(Int,Int)=>Int)(x:Int,y:Int)={
op(x,y)
}
val result01 = method((x,y)=>x+y)(1,2)
val result02 = method((x,y)=>x*y)(1,2)
println(result01)
println(result02)
闭包
函数的返回值依赖于函数之外的参数。
var y=10
//变量y不处于其有效作用域时,函数还能够对变量进行访问
val add=(x:Int)=>{
x+y
}
//在add中有两个变量:x和y。其中的一个x是函数的形式参数,
//在add方法被调用时,x被赋予一个新的值。
// 然而,y不是形式参数,而是自由变量
println(add(5)) // 结果15
y=20
println(add(3)) // 结果23
Class & object
由于Scala没有静态方法和静态类,通过object去定义静态方法或者静态对象。当object和Class放在一个文件中时候称该object为当前Class的伴生对象。
单例类
单例类使用object修饰,所有声明在object中的方法都是静态方法,类似于Java中声明的工具类的作用。
object HelloUtil {
def sayHello(name:String):Unit={
println("hello~ "+name)
}
}
类
class User { //默认构造器
var id:Int=_
var name:String=_
var sex:Boolean=_
def this(id:Int,name:String,sex:Boolean){//扩展默认构造
this() //第一行必须写默认构造
this.id=id
this.name=name
this.sex=sex
}
}
必须要求在扩展构造方法的第一行显式调用this()-默认构造,其中
_表示参数赋值为默认值。这本质上是因为如上声明的类,等价声明了class User(){}类似使用this()调用构造器。
- def this(参数)定义扩展构造器
class User(var id:Int,var name:String,var sex:Boolean) { //默认构造器
var birthDay:Date=_
def this(id:Int,name:String,sex:Boolean,birthDay:Date){//扩展默认构造
this(id,name,sex)
this.birthDay=birthDay
}
}
使用该种方式声明构造类似于Java编程,但是要求在构造的第一行必须显示调用this方法。
- 类上声明(默认构造器)
一旦类上声明了参数,在使用this声明其他的构造器的时候,必须在第一行调用类上的构造器。
class User(var id:Int,var name:String,var age:Int) {//默认构造器
}
√伴生对象
如果类和object在一个scala源文件中,则称为object User 是class User的伴生对象,使用伴生对象可以方便的创建类的对象,只需要覆盖对应的apply方法,如下:
class User(id:Int,name:String,age:Int) {
override def toString: String = {
this.id+" "+this.name+" "+this.age
}
}
object User{
def apply(id: Int, name: String, age: Int): User = new User(id, name, age)
}
var user=User(1,"zhangsan",18)//等价 new User(1,"zhangsan",18)
这里可以理解apply是一个工厂方法,该方法的作用是生产User实例对象。
使用unapply方法能够将对象中的一些属性反解出来
class People(var id:Int, var name:String,var sex:Boolean) {
}
object People{
def apply(id: Int, name: String, sex: Boolean): People = {//工厂方法,当构建复杂类的时候
println("invoke apply")
new People(id, name, sex)
}
def unapply(people: People): Option[(Int, String, Boolean)] = {//将一个类的属性解码出来
if(people!=null){
Some((people.id,people.name,people.sex))
}else{
None
}
}
}
var people1=new People(1,"zhangsan",true)
var people2=People(1,"zhangsan",true)//People.apply(1,"zhangsan",true)
println(people1==people2)
var people3=People //类信息
var people4=People
println(people3==people4)
var People(id,name,sex)=people1//解码people1的数据给id/name/sex
println(s"${id}\t${name}\t${sex}")
注意一个伴生对象中只能有一个unapply方法,这不同于apply方法,因为apply方法可以有多个。
抽象类
abstract class Animal(name:String) {
def eat():Unit={
println("animal can eat...")
}
def sleep():String
}
Trait(接口)
trait Speakable {
def speek():Unit
}
trait Flyable{
def fly():Unit
}
√继承&实现
写一个Dog类继承Animal并且实现Speakable特质。
class Dog(name:String) extends Animal(name:String) with Speakable {
override def sleep(): String = {
"i'm a dog I sleep 8 hours"
}
override def speek(): Unit = {
println("wang wang ~~")
}
override def eat(): Unit = {
println("啃骨头")
}
}
object Dog{
def apply(name: String): Dog = new Dog(name)
}
Trait动态植入
假如说现在有一个Bird继承自Animal,在使用的时候会发现该类需要具备Flyable的功能,可以写法如下:
class Bird(name:String) extends Animal(name :String) {
override def sleep(): String = {
"bird is sleeping"
}
}
var b=new Bird("麻雀") with Flyable{
override def fly(): Unit = {
println("小鸟会飞!")
}
}
b.fly()
①在覆盖有实现的方法必须添加
overwrite;②一个类只能继承一个类with多个trait例如:Class A extends B with C with D{}
self
等价于this关键字,在this出现混淆的时候使用self给this关键字起别名。
class User {
self =>
var id:Int = _
var name:String = _
var age:Int = _
def this( id:Int, name:String, age:Int){
this()
self.id=id
self.name=name
self.age=age
}
}
- Trait强制混合
以下案例就是要求所有Flyable的子类必须实现Flyable接口。
abstract class Bird(name:String) {
self:Flyable=>
def eat():Unit={
println(s"animal ${name} can eat...")
}
def sleep():Unit
}
trait Flyable{
def fly():Unit
}
class FlyFish(name:String) extends Bird(name) with Flyable {
override def sleep(): Unit = {
println(s"${name} 会睡觉~")
}
override def fly(): Unit = {
println(s"${name} 会飞了~")
}
}
√Case class
case class就像常规类,case class适用于对不可变数据进行建模。
case class CaseUser(id:Int,name:String) {
def sayHi(): Unit ={//很少这么干!
println(this)
}
}
通常一般这样写
case class CaseUser(id:Int,name:String,sex:Boolean)
var uc1=new UserCase(1,"zhangsan")
var uc2=UserCase(1,"zhangsan")
与普通的class不同的是,CaseClass创建的对象 == 比较的是对象的内容,其次CaseClass的所有属性都是只读,不允许修改。通常用于只读数据的建模。可以简单的使用copy来实现两个对象间的值得传递
var caseUser1= CaseUser(1,"李四",false)
var caseUser2= new CaseUser(1,"李四",true)
println(caseUser1==caseUser2)//比较的是内容,因此返回值true 属性只读
var caseUser3=caseUser1.copy(name="王五")
println(caseUser3)
case class之间不存在继承关系。
可见性-了解
private
- 修饰属性、方法
class Student {
private var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
private def sayHello(): String ={
s"hello $name"
}
override def toString: String = {
s"$id\t$name"
}
}
object Student{
def main(args: Array[String]): Unit = {
val stu = new Student02(3,"zhaoliu")
stu.id=4
println(stu.sayHello())
println(stu)
}
}
该类内部和伴生对象可以访问,其他类均不可以访问。
- 修饰扩展构造
class Student {
var id:Int=_
var name:String=_
private def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
表示该扩展构造方法只能对伴生对象可见
- 修饰默认构造
class Student private {
var id:Int=_
var name:String=_
private def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
如果修饰类,伴生对象就用不了,例如
private class Student {
var id:Int=_
var name:String=_
private def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
protected
- 修饰属性、方法
class Student {
protected var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
protected def sayHello(): String ={
s"hello $name"
}
override def toString: String = {
s"$id\t$name"
}
}
针对 本类、以及伴生对象可见、子类可见
- 修饰扩展构造
class Student {
protected var id:Int=_
var name:String=_
protected def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
对本类以及该类的伴生对象可见、子类可见
- 修饰默认构造
class Student protected {
protected var id:Int=_
var name:String=_
protected def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
只能在该类/伴生/子类的内部可见,其他地方不可见
this限定
可以和private或者protected联合使用,可以讲可见性缩小为本类的内部,去除伴生对象。
class Student06 {
private[this] var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
private[this] def sayHello(): String ={
s"hello $name"
}
override def toString: String = {
s"$id\t$name"
}
}
包限定
class Student {
private[demo12] var id:Int=10
}
class SmallStudent05 extends Student05 {
def sayHello():Unit={
println(s"${id}")
}
}
当使用包限定的时候,就打破了private|protected的语义,全部以包为准
√final限定(掌握)
- 修饰类:最终类,不可以被继承
- 修饰方法:不能被覆盖
- 修饰属性:只能修饰val属性,不可以修饰局部变量(scala已经提供了val表示常量),当final修饰成员变量,属性不可以被遮盖。(
scala中只用val的成员变量才可以被覆盖)
class Animal {
final val name:String="动物"//必须是常量,才可以被子类覆盖,添加上final以后,允许遮盖
val age:Int=18
def eat():Unit={
}
}
class Parrot extends Animal {
override val age: Int = 20
override def eat(): Unit = super.eat()
}
object Parrot{
def main(args: Array[String]): Unit = {
val parrot = new Parrot
println(parrot.name)
println(parrot.age)
}
}
final和var连用没有任何意义。因为var不允许被遮盖。
√sealed-密封
Trait和class可以标记为 sealed,这意味着必须在同一个Scala源文件中声明所有子类型这样就确保了所有的子类型都是已知的。
//密封 编译器识别的关键字 所有已知子类必须和Message放在同一个源码文件中
sealed abstract class Message(context:String,msgType:String)
case class MSMMessage(name:String,msgType:String) extends Message(name,msgType)
case class EmailMessage(name:String,msgType:String,from:String) extends Message(name,msgType)
val messages1 = Array(new MSMMessage("你好", "msm"), new EmailMessage("hello", "email", "[email protected]"))
var msg=messages1(new Random().nextInt(2))
msg match {
case msg:MSMMessage => {
println(msg.name+"\t"+msg.msgType)
}
case email:EmailMessage =>{
println(email.name+"\t"+email.msgType+"\t"+email.from)
}
case _=>{
println("未知消息")
}
}
√lazy加载
Scala中使用关键字lazy来定义惰性变量,实现延迟加载(懒加载)。 惰性变量只能是不可变变量,并且只有在调用惰性变量时,才会去实例化这个变量。
def getName():String={
println("----getName-----")
"zhangsan"
}
lazy val name:String=getName()
println(name)
函数对象(lambda表达式)
函数式接口
事实上在Java 8中也引人了函数式接口,类似Scala中的函数式对象。例如在Java中定义一个函数式接口:
@FunctionalInterface
public interface GreetingService {
String sayHello(String name);
}
要求接口中只能有一个方法声明。只有函数式接口才可以使用lambda表达式做匿名类实现。
GreetingService gs=(String name) -> "hello "+ name;
String results = gs.sayHello("zhangsan");
System.out.println(results);
类似的这种写法在Java 8的集合stream编程中非常常见。例如
List<String> lines= Arrays.asList("this is a demo","good good study","day day up","come on baby");
lines.stream()
.flatMap(line->Arrays.asList(line.split(" ")).stream())
.forEach(word->System.out.print(word+" | "));
更多有关Java8 lambda信息请参考:https://howtodoinjava.com/java-8-tutorial/
Scala这门语言在lambda编程的灵活性上是java无法媲美的。因为Scala在声明函数式对象(等价java函数式接口)是非常轻松的。

例如以上案例的GreetingService如果使用Scala声明可以简写为如下:
val sayHello:(String)=>String = (name) => "hello ~"+name
println(sayHello("zhangsan"))
部分应用函数
在Scala中同样对所有的函数都可以理解为是一个函数对象。例如在Scala中可以将任意一个函数转变成对象。例如如下定义一个sum函数。
def sum(x:Int,y:Int):Int={
x+y
}
在Scala中可以尝试将一个函数转变成一个对象类型,如下:
scala> def sum(x:Int,y:Int):Int={
| x+y
| }
sum: (x: Int, y: Int)Int
scala> var sumFun = sum _
sumFun: (Int, Int) => Int = <function2>
scala> sumFun(1,2)
res0: Int = 3
通常将sumFun称为sum函数的部分应用函数,不难看出sumFun事实上是一个变量。该变量的类型是(Int, Int) => Int通常将该类型称为函数式对象。事实上以上的(Int, Int) => Int是Function2的变体形式。因为Scala最多支持Funtion0~22种形式变体。例如:
class SumFunction extends ((Int,Int)=>Int){
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
}
等价写法:
class SumFunction extends Function2[Int,Int,Int]{
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
}
scala> sumFun.isInstanceOf[(Int,Int)=>Int]
res2: Boolean = true
scala> sumFun.isInstanceOf[Function2[Int,Int,Int]]
res3: Boolean = true
isInstanceOf该方法等价于java中的instanceof关键字。用于判断类型。
PartitalFunction(偏函数)
偏函数主要适用于处理指定类型的参数数据,通常用于集合处理中。定义一个函数,而让它只接受和处理其参数定义域范围内的子集,对于这个参数范围外的参数则抛出异常,这样的函数就是偏函数(顾名思异就是这个函数只处理传入来的部分参数)。偏函数是个特质其的类型为PartialFunction[A,B],其中接收一个类型为A的参数,返回一个类型为B的结果。
val pf1=new PartialFunction[Any,Int] {
override def isDefinedAt(x: Any): Boolean = {
x.isInstanceOf[Int]
}
override def apply(v1: Any): Int = {
v1*2
}
}
val pf2:PartialFunction[Any,Int] = {case x:Int => x*2}
val a = Array(1,"a",2,"b",true,3)
//for(i<-a;if(i.isInstanceOf[Int])) yield i
a.collect(pf1)
a.collect(pf2) //偏函数变体写法
√隐式值注入/转换
隐式值
object CustomImplicits {
//声明隐式值
implicit val a:Int= 1
}
object TestImplicits {
def main(args: Array[String]): Unit = {
//引入隐式值
import CustomImplicits._
//获取上下文中的一个Int 隐式值,要求类型唯一,名字不允许和隐式变量一样
var b:Int= implicitly[Int]
print(s"b值:${b}")
}
}
implicit声明隐式值,implicitly获取隐式值,同种类型的隐式值只能存在一份!
隐式注入
object CustomImplicits {
//声明隐式值
implicit val a:Int= 1
implicit val msg:String="哈喽"
}
object TestImplicits {
def main(args: Array[String]): Unit = {
//引入隐式值
import CustomImplicits._
sayHello("张三")
sayHello("lisi")("Hello")
}
//柯里化
def sayHello(name:String)(implicit msg:String):Unit={
println(s"${msg} ~ ${name}")
}
}
要求上下文环境中,必须有一个String类型隐式值,系统会自动注入
隐式转换(把不兼容改为兼容)
object CustomImplicits {
//声明隐式转换
implicit def s2d(s:String):Date={
println("-------转换了------")
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
sdf.parse(s)
}
}
object TestImplicits {
def main(args: Array[String]): Unit = {
//引入隐式值
import CustomImplicits._
showMeTime(new Date())
// String --> Date
showMeTime("2018-12-13 10:30:00") //等价 showMeTime(s2d("2018-12-13 10:30:00"))
}
def showMeTime(date:Date):Unit={
println("北京时间:"+date.toLocaleString)
}
}
隐式增强(把不可能变成可能)
object CustomImplicits {
//声明隐式增强
implicit class PigImplicits(pig:Pig){
def fly():Unit={
println(s"${pig.name} 会飞了 !")
}
def speek():Unit={
println(s"${pig.name} mu mu~")
}
}
}
object TestImplicits {
def main(args: Array[String]): Unit = {
//引入隐式值
import CustomImplicits._
val pig1 = new Pig("猪坚强") with Flyable{
override def fly(): Unit = {
println(s"${name} 会飞 ~")
}
}
pig1.eat()
pig1.sleep()
pig1.fly() //自己飞方法
pig1.speek()//隐式增强
val pig = new Pig("佩奇")
pig.eat()
pig.sleep()
pig.fly()//隐式增强
pig.speek()//隐式增强
}
implicit val a:Int=100 //隐式变量
def sayHi(name:String)(implicit msg:String) //隐式注入
implicit def s2Int(str:String):Int={
Integer.parseInt(str) //不可以再掉隐式转换
}
implicit class PigImplicits(pig:Pig){ //隐式增强
def speak():Unit{
}
}
异常处理
- Java:区分已检查(必须处理)和未检查(可选)异常、捕获有顺序限制,由小->大
public class JavaExceptions {
public static void main(String[] args) {
try {
throw new IOException("我自己抛出的~");
} catch (IOException e) { //由精准--> 模糊
e.printStackTrace();
}catch (ArithmeticException e){
e.printStackTrace();
}
catch (Throwable e){
e.printStackTrace();
} finally {
System.out.println("最终执行");
}
}
}
- Scala:不区分已检查和未检查异常,捕获按照写case 进行匹配
object ScalaExceptions {
def main(args: Array[String]): Unit = {
try {
throw new IOException("我自己抛出的~")
}catch {
case e:ArithmeticException =>{
println("ArithmeticException")
e.printStackTrace()
}
case e: Throwable =>{
println("Throwable")
e.printStackTrace()
}
case e: IOException =>{
println("IOException")
e.printStackTrace()
}
} finally {
System.out.println("最终执行")
}
}
}
泛型[看懂]
<:上边界限定
//只能饲养Dog或者Dog的子类 上边界限定
def keepDog[T <: Dog](t:T):Unit={
println(t)
}
def main(args: Array[String]): Unit = {
val animal = new Animal("原始动物")
val dog = new Dog("大黄狗")
val smallDog = new SmallDog("小狗狗")
keepDog(dog)
keepDog(smallDog)
keepDog(animal)//错误
}
>:下边界限定
//只能饲养Dog或者Dog的父类 下边界限定 bug
def keepAnimal[T >: Dog](t:T):Unit={
println(t)
}
def main(args: Array[String]): Unit = {
val animal = new Animal("原始动物")
val dog = new Dog("大黄狗")
val smallDog = new SmallDog("小狗狗")
keepAnimal(dog)
keepAnimal(animal)
keepAnimal(smallDog)//本不应该成功!这里我们理解为是个Bug
}
//只允许是Dog或者Dog的父类
trait Keeper[T >: Dog] {
def keep(t:T):Unit={
println(t)
}
}
def main(args: Array[String]): Unit = {
val animal = new Animal("原始动物")
val dog = new Dog("大黄狗")
val smallDog = new SmallDog("小狗狗")
val k1= new Keeper[Dog] {
override def keep(t: Dog): Unit = {
println(t)
}
}
val k2= new Keeper[Animal] {
override def keep(t: Animal): Unit = {
println(t)
}
}
val k3= new Keeper[SmallDog] { //错误
override def keep(t: SmallDog): Unit = {
println(t)
}
}
}
<%视图限定
例如T <% U,要求上下文必须有一个隐式转换能够将T 转换为 U类型。
class SmallDog(name:String) extends Dog (name:String){
override def speek(): Unit = {
println(s"$name 小狗叫~")
}
}
//可以将T看做是小狗
def keeperSmallDog[T <% SmallDog](t:T):Unit={
t.speek()
}
object MyImlipcits {
//定义一个String -> SmallDog转换
implicit def s2sd(name:String):SmallDog={
new SmallDog(name)
}
}
def main(args: Array[String]): Unit = {
keeperSmallDog(new SmallDog("小花花"))
import MyImlipcits._
keeperSmallDog("佩奇")
}
T:A上下文绑定
表示上下文中环境中必须存在这种隐式值A[T]隐式值,否则程序编译出错.这样可以在上下文中还没有隐式值得时候确保方法能编译成功。
class Student[T] {
def showMessage(msg:T):Unit={
msg match {
case name:String => println("name:"+name)
case age:Int => println("age:"+age)
case _ => println("不知道")
}
}
}
//上下文中 必须得有 Student[T] 类型隐式值
def sayInformation[T:Student](t:T):Unit={
val stu = implicitly[Student[T]]//从上下文中获取一个隐式值
stu.showMessage(t)
}
def main(args: Array[String]): Unit = {
import MyImlipcits._
sayInformation("zhangsan")
sayInformation(18)
sayInformation(true)
}
object MyImlipcits {
implicit val stu1=new Student[String]
implicit val stu2=new Student[Int]
implicit val stu3=new Student[Boolean]
}
+A协变
//管理T或者T的子类
trait Manager[+T] {}
var m1=new Manager[Animal] {}
var m2=new Manager[Dog] {}
var m3=new Manager[SmallDog] {}
m1=m2
m2=m3
m2=m1//错误
将子类的泛型引用赋值给父类。Java不支持协变
-A逆变
//管理T或者T的父类
trait Manager[-T] {}
var m1=new Manager[Animal] {}
var m2=new Manager[Dog] {}
var m3=new Manager[SmallDog] {}
m1=m2//错误
m2=m3//错误
m2=m1
m3=m1
将父类的泛型引用赋值给子类。Java不支持协变
A不变
//管理T或者T的父类
trait Manager[T] {}
var m1=new Manager[Animal] {}
var m2=new Manager[Dog] {}
var m3=new Manager[SmallDog] {}
m1=m2//错误
m2=m3//错误
m2=m1//错误
m3=m1//错误
和Java相似,仅仅允许相同类型间赋值
集合/数组(重点)
Array-数组
//伴生对象创建数组
var a1=Array(1,2,3,5,4)
//创建长度为5的数组,所有值都是0
var a2=new Array[Int](5)
//获取长度
a1.length
a2.size
//修改
a1(1) = -1
a1.update(1,-2)
//遍历数组
for(i <- a1) println(i)
Range-区间
产生的是一个只读区间和数组类似,但是内容不可以修改。
//创建区间
var r1=new Range(0,10,3) //0 3 6 9
var r2=0.to(10).by(3)
var r3=0 until 10 by 3
//取值
r1(2) // 6
//r1(2) = 12 //错误
//遍历range
for(i<- r1) println(i)
//长度大小
r1.size
r1.length
Vector-坐标
//创建向量
var v1= Vector(1,2,3)
var v2= for(i <- 0 to 10 by 3) yield i
//取值
v1(0) //1
//不支持修改
//v1(2) = 12 //错误
//遍历Vector
for(i<- v1) println(i)
//长度大小
v1.size
v1.length
Iterator -游标
不可以根据下标读取,且只能遍历一次。
//创建一个游标
var it=Iterator(1,2,3)
//只可以被遍历一次
for(i<- it) println(i)
//计算大小.将集合清空
it.size
it.length
//判断是否为空
val flag= it.isEmpty
List-不可变集合
var l1=List(1,2,3,4,5) //使用伴生对象构建集合
//迭代遍历
for(i<- 0 until l1.size){
print(l1(i)+"\t")
}
println()
//操作位置元素 - 读取
var item0=l1(0) //获取第0个位置元素
val firstEle = l1.head //获取第0个元素
val lastEle = l1.last //获取最后一个
val tailList = l1.tail //除第一个元素以外其余元素
println(s"${item0}\t${firstEle}\t${lastEle}\t${tailList.mkString(",")}")
//判断元素是否存在
val isExists = l1.contains(5)
//高级方法
val newList1: List[Int] = l1.+:(-1) //-1,1,2,3,4,5
val newList2 = l1.::(-1) // -1,1,2,3,4,5
val newList3 = l1.:::(List(0, 0)) // 0,0,1,2,3,4,5
val newList4 = l1.++(Array(0, 0)) // 1,2,3,4,5,0,0
val newList5 = l1.++:(Array(0, 0)) //0,0,1,2,3,4,5
val newList6 = l1.:+(-1)//1,2,3,4,5,-1
// 初始值 跌倒变量 元素
val sum1 = l1./:(0)((sum, i) => sum+i)
// 初始值 元素 跌倒变量
val sum2 = l1.:\(0)((i, sum) => sum+i)
ListBuffer-可变集合
var l1=ListBuffer(1,2,3,4,5) //使用伴生对象构建集合
//迭代遍历
for(i<- 0 until l1.size){
print(l1(i)+"\t")
}
println()
//操作位置元素 - 可读可写
var item0=l1(0) //获取第0个位置元素
val firstEle = l1.head //获取第0个元素
val lastEle = l1.last //获取最后一个
val tailList = l1.tail //除第一个元素以外其余元素
println(s"${item0}\t${firstEle}\t${lastEle}\t${tailList.mkString(",")}")
//判断元素是否存在
val isExists = l1.contains(5)
//高级方法
val newList1: ListBuffer[Int] = l1.+:(-1) //-1,1,2,3,4,5
//val newList2 = l1.::(-1) // -1,1,2,3,4,5
//val newList3 = l1.:::(List(0, 0)) // 0,0,1,2,3,4,5
val newList4 = l1.++(Array(0, 0)) // 1,2,3,4,5,0,0
val newList5 = l1.++:(Array(0, 0)) //0,0,1,2,3,4,5
val newList6 = l1.:+(-1)//1,2,3,4,5,-1
// 初始值 跌倒变量 元素
val sum1 = l1./:(0)((sum, i) => sum+i)
// 初始值 元素 跌倒变量
val sum2 = l1.:\(0)((i, sum) => sum+i)
println(sum1 +"\t"+sum2)
//修改指定位置的值
l1(0) = -1
l1.update(1, 10) // -1,10,3,4,5
//删除、插入指定位置元素
l1.remove(0) // 10,3,4,5
l1.insert(0,0,-1) //0,-1,10,3,4,5
//移除指定元素
var newRemoveList1=l1.-(-1) // 并不改变l1本身数据 l1:0,-1,10,3,4,5 newRemoveList1:0,10,3,4,5
l1.-=(5) //删除元素,修改l1本身 l1:0,-1,10,3,4
Set-不可变
//创建集合 去重
var s=Set[Int](1,2,4,5,3)
//添加一个元素 产生新的集合Set,不会修改原始集合
s.+(6) //Set(5, 1, 6, 2, 3, 4)
//删除元素 产生新的集合Set,不会修改原始集合
s.-(5) // Set(1, 2, 3, 4)
//获取set大小
s.size
//添加一个集合 产生新的集合Set,不会修改原始集合
s.++(List(6,6,7)) //Set(5, 1, 6, 2, 7, 3, 4)
//判断元素是否存在
var isExists=s(5) //true s.contains(5)
isExists=s(7) //false
Set-可变
import scala.collection.mutable.Set
//创建集合 去重
var s=Set[Int](1,2,4,5,3)
//添加一个元素 产生新的集合Set,不会修改原始集合
s.+(6) //Set(5, 1, 6, 2, 3, 4)
//添加一个元素 产生新的集合Set,修改原始集合
s.add(6) //Set(5, 1, 6, 2, 3, 4)
//删除元素 产生新的集合Set,不会修改原始集合
s.-(5) // Set(1, 2, 3, 4)
//删除元素 产生新的集合Set,修改原始集合
s.remove(5) //Set(1, 2, 3, 4)
//获取set大小
s.size
//添加一个集合 产生新的集合Set,不会修改原始集合
s.++(List(6,6,7)) //Set(5, 1, 6, 2, 7, 3, 4)
//判断元素是否存在
var isExists=s(5) //true s.contains(5)
isExists=s(7) //false
HashMap-不可变
import scala.collection.immutable.HashMap
var hm= HashMap[String,String](("建设","001"),("招商","002"))
//添加一个元素,并不会修改原始的Map
hm.+(("农业","003"))
hm.+("民生"->"004")
//删除元数据,并不会修改原始的Map
hm.-("建设","招商")
//获取指定key的值
val value: Option[String] = hm.get("建设")
val sv1= value.get //该值必须存在
val sv2= value.getOrElse("啥也没有" )
val sv3=hm("建设")//直接取值
//判断key是否存在
hm.contains("建设")
//更新一个key,并不会修改原始的Map
hm.updated("建设","003")
//获取所有keys
val keys = hm.keys
val values = hm.values
//遍历一个Map
for(i<- hm.keys){
println(i+" "+hm.get(i).getOrElse(""))
}
//合并两个map
var hm2=HashMap[String,String]("工商"->"003",("建设","005"))
//在key出现重复的时候,使用t2覆盖t1的元素
hm.merged(hm2)((t1,t2)=> t2)
HashMap-可变
import scala.collection.mutable.HashMap
var hm= HashMap[String,String](("建设","001"),("招商","002"))
//添加一个元素,并不会修改原始的Map
hm.+(("农业","003"))
hm.+("民生"->"004")
//添加一个元素,修改原始的Map
hm.put("工商","005")
//删除元数据,并不会修改原始的Map
hm.-("建设","招商")
//删除元数据,修改原始的Map
hm.remove("建设")
//获取指定key的值
val value: Option[String] = hm.get("建设")
val sv1= value.get //该值必须存在
val sv2= value.getOrElse("啥也没有" )
//判断key是否存在
hm.contains("建设")
//更新一个key,并不会修改原始的Map
hm.updated("建设","003")
//获取所有keys
val keys = hm.keys
val values = hm.values
//遍历一个Map
for(i<- hm.keys){
println(i+" "+hm.get(i).getOrElse(""))
}
Java集合和Scala集合相互转换
import scala.collection.JavaConverters._
object TestJavaScalaCollection {
def main(args: Array[String]): Unit = {
val arrayList = new util.ArrayList[String]()
arrayList.add("hello")
arrayList.add("word")
for(i <- 0 until arrayList.size()){
println(arrayList.get(i))
}
val scalaList = arrayList.asScala
for(i<- scalaList){
println(i)
}
val javaList = scalaList.asJava
for(i <- 0 until javaList.size()){
println(javaList.get(i))
}
}
}
集合变换-算子
Scala集合提供了丰富的集合计算算子,用于实现集合/数组的计算,这些计算子一般针对于List、Array、Set、Map、Range、Vector、Iterator等实现集合变换,这里的变换并不会更改原始集合,仅仅通过一些算子产生新的集合。
排 序
- sorted
scala> var list=List(1,5,3,4,7,6)
list: List[Int] = List(1, 5, 3, 4, 7, 6)
scala> list.sorted # 敲击键盘tab键,会有方法的提示
def sorted[B >: Int](implicit ord: scala.math.Ordering[B]): List[Int]
scala> val sortedList = list.sorted
sortedList: List[Int] = List(1, 3, 4, 5, 6, 7)
scala> list.sorted
res7: List[Int] = List(1, 3, 4, 5, 6, 7)
因为系统已经提供了相应的隐式值
Ordering[Int],所以用户在使用的时候一般无需提供,如果用户需要自定义排序规则,用户可以自己提供参数。
scala> implicit val myOrder=new Ordering[Int]{ //降序排列
| override def compare(x: Int, y: Int): Int = {
| (x-y) * -1
| }
| }
myOrder: Ordering[Int] = $anon$1@1c510181
scala> list.sorted(myOrder)
res9: List[Int] = List(7, 6, 5, 4, 3, 1)
如果遇到了复杂排序,例如集合中存储的是一个User实例或者是一个元组,系统默认不会提供相应的隐式值。
scala> case class User(id:Int,name:String,salary:Double)
defined class User
scala> var userArray=Array(User(1,"zhangsan",1000),User(2,"lisi",1500),User(3,"wangwu",1200))
userArray: Array[User] = Array(User(1,zhangsan,1000.0), User(2,lisi,1500.0), User(3,wangwu,1200.0))
scala> userArray.sorted
def sorted[B >: User](implicit ord: scala.math.Ordering[B]): Array[User]
不难看出,如果想对userArray进行排序我们需要提供一个Ordering[User]的隐式值,由于系统仅仅提供了AnyVal类型的隐式值,并没有提供AnyRef的隐式值(这里的String类型除外),如果直接执行sorted,由于找不到一个Ordering[User]的隐式值,系统运行出错。
scala> userArray.sorted
<console>:14: error: No implicit Ordering defined for User.
userArray.sorted
用户必须自定义一个Ordering[User]隐式值,上述代码方可运行成功!
scala> implicit val userOrder=new Ordering[User]{
| override def compare(x: User, y: User): Int = {
| ( x.salary - y.salary).asInstanceOf[Int]
| }
| }
userOrder: Ordering[User] = $anon$1@64e08192
scala> userArray.sorted
res3: Array[User] = Array(User(1,zhangsan,1000.0), User(3,wangwu,1200.0), User(2,lisi,1500.0))
- sortBy
实现基于某个属性的排列,例如上例中user,我们可以指定id或者是salary排序,当然要求指定属性必须是AnyVal类型。
scala> var userArray=Array(User(1,"zhangsan",1000),User(2,"lisi",1500),User(3,"wangwu",1200))
userArray: Array[User] = Array(User(1,zhangsan,1000.0), User(2,lisi,1500.0), User(3,wangwu,1200.0))
scala> userArray.sortBy
def sortBy[B](f: User => B)(implicit ord: scala.math.Ordering[B]): Array[User]
①按照ID排列
scala> userArray.sortBy(user=>user.id)
res6: Array[User] = Array(User(3,wangwu,1200.0), User(2,lisi,1500.0), User(1,zhangsan,1000.0))
②按照薪资排
scala> userArray.sortBy(user=>user.salary)
res7: Array[User] = Array(User(1,zhangsan,1000.0), User(3,wangwu,1200.0), User(2,lisi,1500.0))
在案例①中我们希望按照ID的升序排列
scala> implicit val idOrder=new Ordering[Int]{
| override def compare(x: Int, y: Int): Int = {
| x-y
| }
| }
idOrder: Ordering[Int] = $anon$1@72e4f58f
scala> userArray.sortBy(user=>user.id)(idOrder) # 柯里化写法
res8: Array[User] = Array(User(1,zhangsan,1000.0), User(2,lisi,1500.0), User(3,wangwu,1200.0))
- sortWith
这种排序类似与sorted,会同时提供两个需要对比的对象,我们自己定义排序规则即可,无需提供隐式值。
scala> var userArray=Array(User(1,"zhangsan",1000),User(2,"lisi",1500),User(3,"wangwu",1200))
userArray: Array[User] = Array(User(1,zhangsan,1000.0), User(2,lisi,1500.0), User(3,wangwu,1200.0))
scala> userArray.sortWith
def sortWith(lt: (User, User) => Boolean): Array[User]
scala> userArray.sortWith((u1,u2)=>u1.salary >= u2.salary)
res9: Array[User] = Array(User(2,lisi,1500.0), User(3,wangwu,1200.0), User(1,zhangsan,1000.0))
scala> userArray.sortWith((u1,u2)=>u1.salary <= u2.salary)
res10: Array[User] = Array(User(1,zhangsan,1000.0), User(3,wangwu,1200.0), User(2,lisi,1500.0))
flatten
用于展开集合中的元素,主要作用于降维。
def flatten[B](implicit asTraversable: String => scala.collection.GenTraversableOnce[B]): List[B]
scala> var list=List(List("a","b","c"),List("d","e"))
list: List[List[String]] = List(List(a, b, c), List(d, e))
scala> list.flatten
res20: List[String] = List(a, b, c, d, e)
scala> var lines=List("hello word","ni hao")
lines: List[String] = List(hello word, ni hao)
scala> lines.flatten
res26: List[Char] = List(h, e, l, l, o, , w, o, r, d, n, i, , h, a, o)
scala> var lines=List("hello word","ni hao")
lines: List[String] = List(hello word, ni hao)
scala> lines.flatten(line => line.split("\\s+"))
res20: List[String] = List(hello, word, ni, hao)
√Map
该算子可以操作集合的每一个元素,并且对集合中的每一个元素做映射(转换)
scala> var list=List(1,2,4,5)
list: List[Int] = List(1, 2, 4, 5)
scala> list.map(i=> i*i)
res22: List[Int] = List(1, 4, 16, 25)
scala> var lines=List("hello word","ni hao")
lines: List[String] = List(hello word, ni hao)
scala> lines.flatten(line=>line.split("\\s+")).map(word=>(word,1))
res24: List[(String, Int)] = List((hello,1), (word,1), (ni,1), (hao,1))
√flatMap
对集合元素先进行转换,然后执行flatten展开降维。
scala> var lines=List("Hello World","good good study")
lines: List[String] = List(Hello World, good good study)
scala> lines.map(line=> line.split(" ")).flatten
res55: List[String] = List(Hello, World, good, good, study)
scala> lines.flatMap(line=> line.split("\\s+")) // lines.flatten(line=> line.split("\\s+"))
res56: List[String] = List(Hello, World, good, good, study)
√filter/filterNot
过滤掉集合中不满足条件的 元素
def filter(p: Int => Boolean): Array[Int] | def filterNot(p: Int => Boolean): Array[Int]
scala> var array=Array(1,2,4,6,5,7)
array: Array[Int] = Array(1, 2, 4, 6, 5, 7)
scala> array.filter
def filter(p: Int => Boolean): Array[Int]
scala> array.filterNot
def filterNot(p: Int => Boolean): Array[Int]
scala> array.filter(i => i%2==0)
res38: Array[Int] = Array(2, 4, 6)
scala> array.filterNot(i => i%2==0)
res39: Array[Int] = Array(1, 5, 7)
distinct
去除重复数据
def distinct: Array[Int]
scala> val list=List(1,2,2,3)
list: List[Int] = List(1, 2, 2, 3)
scala> list.distinct
res91: List[Int] = List(1, 2, 3)
reverse
翻转输出
def distinct: Array[Int]
scala> val list=List(1,2,2,3)
list: List[Int] = List(1, 2, 2, 3)
scala> list.sorted
res0: List[Int] = List(1, 2, 2, 3)
scala> list.sorted.reverse
res1: List[Int] = List(3, 2, 2, 1)
√groupBy
通常用于统计分析,将List或者Array转换为一个Map
def groupBy[K](f: String => K): scala.collection.immutable.Map[K,List[String]]
scala> var words=Array("hello","world","good","good","study")
words: Array[String] = Array(hello, world, good, good, study)
scala> words.groupBy(w=>w)
res8: scala.collection.immutable.Map[String,Array[String]] = Map(world -> Array(world), study -> Array(study), hello -> Array(hello), good -> Array(good, good))
scala> words.groupBy(w=>w).map(t=>(t._1,t._2.length))
res10: scala.collection.immutable.Map[String,Int] = Map(world -> 1, study -> 1, hello -> 1, good -> 2)
scala> words.groupBy(w=>w).map(t=>(t._1,t._2.length)).toList
res11: List[(String, Int)] = List((world,1), (study,1), (hello,1), (good,2))
scala> words.groupBy(w=>w).map(t=>(t._1,t._2.length)).toList.sortBy(t=>t._1)
res13: List[(String, Int)] = List((good,2), (hello,1), (study,1), (world,1))
scala> var emps=List("1,001,zhangsan,1000.0","2,002,lisi,1000.0","3,001,王五,800.0")
scala> case class Employee(id:Int,deptNo:String,name:String,salary:Double)
defined class Employee
scala> emps.map(_.split(",")).map(ts=>Employee(ts(0).toInt,ts(1),ts(2),ts(3).toDouble)).groupBy(emp=>emp.deptNo).map(t=>(t._1,t._2.map(e=>e.salary).sum))
res69: scala.collection.immutable.Map[String,Double] = Map(002 -> 1000.0, 001 -> 1800.0)
scala> emps.map(_.split(",")).map(ts=>Employee(ts(0).toInt,ts(1),ts(2),ts(3).toDouble)).groupBy(emp=>emp.deptNo).map(t=>(t._1,(for(e<- t._2) yield e.salary).sum)).toList.sortBy(t=>t._2).reverse
res1: List[(String, Double)] = List((001,1800.0), (002,1000.0))
max|min
计算最值
def max[B >: Int](implicit cmp: Ordering[B]): Int
def min[B >: Int](implicit cmp: Ordering[B]): Int
scala> list.max
res5: Int = 5
scala> list.min
res6: Int = 1
scala> list.sorted
res7: List[Int] = List(1, 2, 3, 4, 5)
scala> list.sorted.head
res8: Int = 1
scala> list.sorted.last
res9: Int = 5
maxBy|minBy
计算含有最大值或者最小值的记录,按照特定条件求最大或最小
def maxBy[B](f: ((Int, String, Int)) => B)(implicit cmp: Ordering[B]): (Int, String, Int)
def minBy[B](f: ((Int, String, Int)) => B)(implicit cmp: Ordering[B]): (Int, String, Int)
scala> var list=List((1,"zhangsan",28),(2,"lisi",20),(3,"wangwu",18))
list: List[(Int, String, Int)] = List((1,zhangsan,28), (2,lisi,20), (3,wangwu,18))
scala> list.maxBy(t=>t._3)
res12: (Int, String, Int) = (1,zhangsan,28)
scala> list.maxBy(t=>t._1)
res13: (Int, String, Int) = (3,wangwu,18)
scala> var emps=List("1,001,zhangsan,1000.0","2,002,lisi,1000.0","3,001,王五,800.0")
emps: List[String] = List(1,001,zhangsan,1000.0, 2,002,lisi,1000.0, 3,001,王五,800.0)
scala> emps.map(_.split(",")).map(w=>(w(1),w(3).toDouble)).groupBy(_._1).map(t=> t._2.maxBy(i=>i._2))
res62: scala.collection.immutable.Map[String,Double] = Map(002 -> 1000.0, 001 -> 1000.0)
scala> emps.map(line=>line.split(",")).map(ts=>(ts(1),ts(3).toDouble)).groupBy(_._1).map(_._2).map(_.maxBy(_._2))
res4: scala.collection.immutable.Iterable[(String, Double)] = List((002,1000.0), (001,1000.0))
√reduce|reduceLeft|reduceRight

def reduce[A1 >: Int](op: (A1, A1) => A1): A1
scala> var list=List(1,5,3,4,2)
list: List[Int] = List(1, 5, 3, 4, 2)
scala> list.reduce((v1,v2)=>v1+v2)
res7: Int = 15
scala> list.reduceLeft((v1,v2)=>v1+v2)
res8: Int = 15
scala> list.reduceRight((v1,v2)=>v1+v2)
res9: Int = 15
scala> list.reduceRight(_+_)
res17: Int = 15
如果集合为空(没有数据),系统报错
scala> var list=List[Int]()
list: List[Int] = List()
scala> list.reduce((v1,v2)=>v1+v2)
java.lang.UnsupportedOperationException: empty.reduceLeft
at scala.collection.LinearSeqOptimized$class.reduceLeft(LinearSeqOptimized.scala:137)
at scala.collection.immutable.List.reduceLeft(List.scala:84)
at scala.collection.TraversableOnce$class.reduce(TraversableOnce.scala:208)
at scala.collection.AbstractTraversable.reduce(Traversable.scala:104)
... 32 elided
√fold |foldLeft|foldRight

def fold[A1 >: Int](z: A1)(op: (A1, A1) => A1): A1
scala> var list=List(1,5,3,4,2)
list: List[Int] = List(1, 5, 3, 4, 2)
scala> list.fold(0)((z,v)=> z+v)
res12: Int = 15
scala> var list=List[Int]()
list: List[Int] = List()
scala> list.fold(0)((z,v)=> z+v)
res13: Int = 0
scala> list.fold(0)(_+_)
res19: Int = 15
√aggregate

def aggregate[B](z: => B)(seqop: (B, Int) => B,combop: (B, B) => B): B
scala> var list=List(1,5,3,4,2)
list: List[Int] = List(1, 5, 3, 4, 2)
scala> list.aggregate(0)((z,v)=>z+v,(b1,b2)=>b1+b2)
res29: Int = 15
scala> list.aggregate(0)(_+_,_+_)
res33: Int = 15
scala> var list=List[Int]()
list: List[Int] = List()
scala> list.aggregate(0)((z,v)=>z+v,(b1,b2)=>b1+b2)
res31: Int = 0
我们reduce和fold计算要求计算结果类型必须和集合元素类型一致,一般用于求和性质的计算。由于aggregate计算对类型无要求,因此可以使用aggregate完成更复杂的计算逻辑,例如:计算均值
scala> var list=List(1,5,3,4,2)
list: List[Int] = List(1, 5, 3, 4, 2)
scala> list.aggregate((0,0.0))((z,v)=>(z._1+1,z._2+v),(b1,b2)=> (b1._1+b2._1,b1._2+b2._2))
res34: (Int, Double) = (5,15.0)
按照部门计算员工平均薪资
scala> var emps=List("1,001,zhangsan,1000.0","2,002,lisi,1000.0","3,001,王五,800.0")
emps: List[String] = List(1,001,zhangsan,1000.0, 2,002,lisi,1000.0, 3,001,王五,800.0)
scala> emps.map(line=>line.split(",")).map(ts=>(ts(1),ts(3).toDouble)).groupBy(_._1).map(t=>(t._1,t._2.map(_._2))).map(t=>(t._1,t._2.aggregate((0,0.0))((z,v)=>(z._1+1,z._2+v),(b1,b2)=> (b1._1+b2._1,b1._2+b2._2)))).map(t=>(t._1,t._2._2/t._2._1))
res63: scala.collection.immutable.Map[String,Double] = Map(002 -> 1000.0, 001 -> 900.0)
group
可以对一维度数据进行升维度
def grouped(size: Int): Iterator[List[Int]]
scala> var list=List(1,5,3,4,2)
list: List[Int] = List(1, 5, 3, 4, 2)
scala> list.grouped(2)
res73: Iterator[List[Int]] = non-empty iterator
scala> list.grouped(2).toList
res74: List[List[Int]] = List(List(1, 5), List(3, 4), List(2))
zip
使用zip 命令可以将多个值绑定在一起,注意: 如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
scala> var list1=List(1,5,3,4,2)
list1: List[Int] = List(1, 5, 3, 4, 2)
scala> var list2=List("a","b","c")
list2: List[String] = List(a, b, c)
scala> list2.zip(list1)
res75: List[(String, Int)] = List((a,1), (b,5), (c,3))
scala> list1.zip(list2)
res76: List[(Int, String)] = List((1,a), (5,b), (3,c))
zipAll
如果其中一个元素的个数比较少,可以使用zipAll用默认的元素填充
scala> var list1=List(1,5)
list1: List[Int] = List(1, 5)
scala> var list2=List("a","b","c","d","e")
list2: List[String] = List(a, b, c, d, e)
scala> list1.zipAll(list2,100,"error")
res22: List[(Int, String)] = List((1,a), (5,b), (100,c), (100,d), (100,e))
zipWithIndex
给元素添加下标操作
scala> var list=List("a","b","c","d","e")
list: List[String] = List(a, b, c, d, e)
scala> list.zipWithIndex
res28: List[(String, Int)] = List((a,0), (b,1), (c,2), (d,3), (e,4))
unzip
将一个元组分解成多个一维度集合
scala> var v=List(("a",1),("b",2),("c",3))
v: List[(String, Int)] = List((a,1), (b,2), (c,3))
scala> v.unzip
res90: (List[String], List[Int]) = (List(a, b, c),List(1, 2, 3))
diff|intersect|union
计算差集合、交集、并集
scala> var v=List(1,2,3)
v: List[Int] = List(1, 2, 3)
scala> v.diff(List(2,3,5))
res54: List[Int] = List(1)
scala> var v=List(1,2,3,5)
v: List[Int] = List(1, 2, 3, 5)
scala> v.intersect(List(2,4,6))
res55: List[Int] = List(2)
scala> var v=List(1,2,3,5)
v: List[Int] = List(1, 2, 3, 5)
scala> v.union(List(2,4,6))
res56: List[Int] = List(1, 2, 3, 5, 2, 4, 6)
Sliding
滑动产生新的数组元素
scala> val list=List(1,2,3,4,5,6)
list: List[Int] = List(1, 2, 3, 4, 5, 6)
scala> list.sliding(3,3)
res0: Iterator[List[Int]] = non-empty iterator
scala> list.sliding(3,3).toList
res1: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6))
scala> list.sliding(3,1).toList
res2: List[List[Int]] = List(List(1, 2, 3), List(2, 3, 4), List(3, 4, 5), List(4, 5, 6))
slice
截取数组子集
scala> val list=List(1,2,3,4,5,6)
list: List[Int] = List(1, 2, 3, 4, 5, 6)
scala> list.slice(0,3)
res3: List[Int] = List(1, 2, 3)
scala> list.slice(3,5)
res5: List[Int] = List(4, 5)
案例剖析
① 有如下数组
var arrs=Array("this is a demo","good good study","day day up")
请统计字符出现的次数,并按照次数降序排列
scala> arrs.flatMap(_.split(" ")).groupBy(w=>w).map(t=>(t._1,t._2.size)).toList.sortBy(t=>t._2).reverse
res11: List[(String, Int)] = List((day,2), (good,2), (study,1), (a,1), (up,1), (is,1), (demo,1), (this,1))
②读取一个文本文件,计算字符出现的个数
var source=Source.fromFile("/Users/admin/IdeaProjects/20200203/scala-lang/src/main/resources/t_word")
var array=ListBuffer[String]()
val reader = source.bufferedReader()
var line = reader.readLine()
while(line!=null){
array+=line
line = reader.readLine()
}
array.flatMap(_.split(" "))
.map((_,1))
.groupBy(_._1)
.map(x=> (x._1,x._2.size))
.toList
.sortBy(_._2)
.reverse
.foreach(i=>println(i))
reader.close()
课程总结
在笔者看来,Scala这门编程语言和Java编程语言相比而言具有很多相似点,但是两种语言在实际的开发应用领域不太一样,这里并不是说谁比谁的运行效率高,而是对于开发人员而言,使用哪种语言解决问题的时候最方便。因此在小编看来,如果是纯粹的业务建模领域开发个人还是比较喜欢使用Java编程语言,因为封装做的比较清晰可读性强。但是如果大家做的是服务器端开发,尤其是数据的处理和分析领域,个人觉得像Scala语言比较好一些,因为这些语言提供了丰富的接口调用,尤其是在集合和网络编程领域上Scala有很多的应用场景,例如:Spark开发,推荐的编程语言就是Scala.
