聊聊低代码海报平台的服务端架构设计
前面一篇文章,我分别从NodeJS框架选型、数据库选型、登录校验和单元测试、接口测试几个方面阐述了我们服务端选型的依据。本篇文章我会详细的为大家介绍服务端整体架构设计以及不同模块之间的关联关系。
在专栏的第一篇文章,我用这张图作为整体架构图为大家做了开篇介绍。这里同样复用这张图来展开说明:
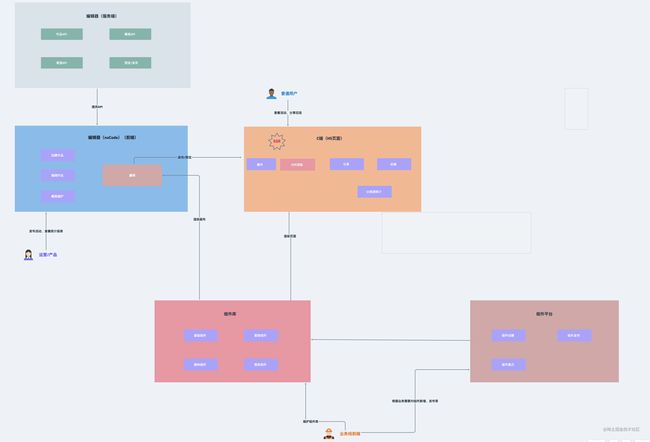
依赖服务端的有三部分:
- 编辑器(登录、活动、上传等工具类)
- 组件平台(组件列表、组件信息、组件新增、版本维护等)
- C端
编辑器服务端设计
首先是编辑器部分,也是整个系统的核心操作区。这部分主要涉及到用户的注册、登录,活动的创建、修改、预览和发布,图片、视频素材的上传等。
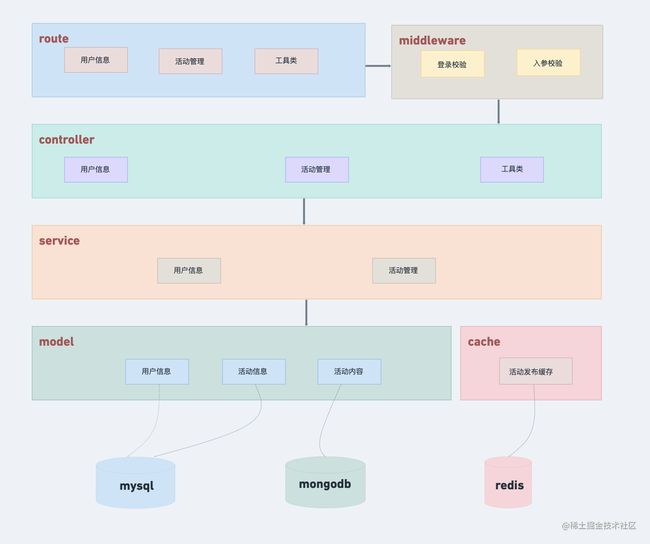
基本上划分为三部分:
- 用户信息
- 活动管理
- 工具类
整体代码设计也是标准的Restful API风格:从route开始,经过middleware对入参做前置校验,然后经由controller调度,最终由service与数据库做交互(一般都是通过ORM框架来做)
细分一下大致的接口: 用户信息相关
- 登录(和注册公用一个)post /users/login
- 获取用户信息 get /users/getUserInfo
- 修改用户信息 patch /users/updateUserInfo
活动相关
- 创建活动 post /activity/
- 复制活动 post /activity/copy/:id
- 查询单个活动信息 get /activity/:id
- 修改活动 patch /activity/:id
- 删除活动 delete /activity/:id
- 发布活动 post /activity/publish/:id
- 获取所有活动 get /activity/list
工具类
- 上传图片 post /utils/uploadImg
- 上传视频 post /utils/uploadVideo
了解了大概的接口,下面我们来着重看一下用户和活动的数据表设计。
数据表设计
数据表的设计在大型项目中是非常重要并且是很有意义的,提前确定字段的类型、含义以及表与表之间的关联关系。
在专栏的前几篇文章中,我们不止一次的提过:MySQL 是一个关系型数据库,是一种结构化的数据存储形式,适合存储活动信息和用户信息;MongoDB是一个非关系型数据库,适合存储文档类(一般是JSON)数据,这里对应就是活动内容对应的JSON数据。
用户
用户表相对比较简单,主要包含了用户名、密码、手机号、性别、用户头像:
| 列 | 类型 | 备注 |
|---|---|---|
| username | varchar | 用户名,唯一 |
| password | varchar | 密码 |
| phoneNumber | varchar | 手机号 |
| gender | int | 性别(1 男性, 2 女性, 0 保密) |
| avatar | varchar | 用户头像 |
const seq = require("../db/seq/seq");
const { STRING, DATE, BOOLEAN } = require("../db/seq/types");
const User = seq.define("user", {username: {type: STRING,allowNull: false,unique: "username",comment: "用户名",},password: {type: STRING,allowNull: false,comment: "密码",},phoneNumber: {type: STRING,allowNull: false,unique: "phoneNumber",comment: "手机号",},gender: {type: STRING,allowNull: false,defaultValue: 0,comment: "性别(1 男性,2 女性,0 保密)",},avatar: {type: STRING,comment: "头像(图片地址)",}
});
module.exports = User;
活动
活动表主要包含了活动标题、活动描述、内容id(和mongodb关联)、作者、封面、活动状态、最近一次发布时间:
| 列 | 类型 | 备注 |
|---|---|---|
| title | varchar | 标题 |
| desc | varchar | 描述 |
| contentId | varchar | 内容id,内容存储在mongodb中 |
| author | varchar | 作者 username,和用户表关联 |
| coverImg | varchar | 封面图片url |
| status | int | 状态:0 删除,1 未发布,2 发布,3 强制下线 |
| latestPublishAt | date | 最近一次发布的时间 |
const seq = require("../db/seq/seq");
const { STRING, DATE, BOOLEAN, INTEGER } = require("../db/seq/types");
const UserModel = require("./UserModel");
const Activity = seq.define("activity", {uuid: {type: STRING,allowNull: false,unique: "uuid",comment: "uuid",},title: {type: STRING,allowNull: false,comment: "标题",},desc: {type: STRING,comment: "描述",},contentId: {type: STRING,allowNull: false,unique: "contentId",comment: "内容 id ,内容存储在 mongodb 中",},author: {type: STRING,allowNull: false,comment: "作者 username",},coverImg: {type: STRING,comment: "封面图片 url",},status: {type: STRING,allowNull: false,defaultValue: 1,comment: "状态:0-删除,1-未发布,2-发布,3-强制下线",},latestPublishAt: {type: DATE,defaultValue: null,comment: "最后一次发布的时间",}
});
// 和 UserModel 建立关系
Activity.belongsTo(UserModel, {foreignKey: "author",targetKey: "username", // 对应 UserModel.username
});
module.exports = Activity;
上面的最后有看到活动表和用户表通过author和username做了关联。这样我们就可以通过用户名查到该用户创建的所有活动。
活动内容
活动内容主要就是:
- 页面用到的组件列表及其对应配置
- 页面整体属性(背景色、背景图片等)
- 页面整体的配置信息,主要是不同端的分享配置
{// 页面的组件列表components: [Object],// 页面的属性,如页面背景图片props: Object,// 配置信息,如微信分享配置setting: Object
}
const mongoose = require("../db/mongoose");
const contentSchema = mongoose.Schema({components: [Object],props: Object,setting: Object,},{timestamps: true,}
);
const ActivityContentModel = mongoose.model("activityContent", contentSchema);
module.exports = {ActivityContentModel
};
登录及用户信息
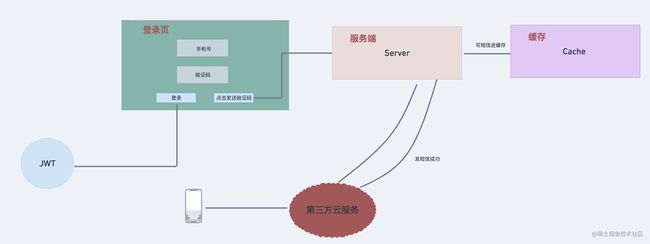
为了尽可能的方便用户,登录这里采用的是短信验证码的方式。首先是获取短信验证码,这里我们对接的是腾讯云短信(Short Message Service,SMS)服务。具体对接方式还是比较简单的。这里说几个注意事项。
首先短信服务是一个付费服务,可以理解为是向外暴露的接口,那么接口安全就很重要,一般是防刷为主。我们这里对验证码做了一道缓存,时间为2分钟,在这段时间内只会发送一次短信,再次点击发送短信验证码会提示“已发送短信,请勿频繁操作”。当然这是建立在短信已经发送成功的前提下,也就是第三方云服务给到的是发送成功的response。如果由于网络或其他原因,短信未能发送成功,这种情况下,也不会去做缓存,再次点击发送短信,短信也能够正常发送。
短信验证码收到后,下面就是通过手机号和验证码登录的逻辑了。首先会去缓存查询手机号对应的验证码与用户在页面中输入的验证码是否一致,如果不一致会提示相应提示。如果一致,下一步会去查询用户信息,用户信息可以查到的情况(表明该用户之前已注册),去更新登录时间以及返回登录成功信息,这里的成功信息是使用jwt.sign对用户信息userInfo进行加密处理。如果查询不到用户信息,表明该用户是平台新用户,会主动通过手机号创建一个新用户,也就是之前提到的登录/注册一体。同样也会使用jwt.sign对用户信息userInfo进行加密处理并返回。这样在ctx.header.authorization中就已经种下了token。在后续需要验证登录态的接口中再通过jwt.verify来验证token合法性就可以了。
有一点要注意的是:生成 token 时加了前缀
Bearer,验证时要把Bearer去掉,req.headers.authorization.split(" ")[1],不然会出现JsonWebTokenError: invalid token的错误,验证失败。
创建活动
上面讲了这么多,下面我将以活动相关的接口为例,带大家梳理一下从route开始,经过middleware对入参做前置校验,然后经由controller调度,最终由service与数据库做交互的整个流程。
本篇因为是偏项目整体服务端架构设计的,所以不会花太大篇幅去讲太具体的实现。
首先是路由route:
/**
* @description 活动相关路由
*/
const router = require("koa-router")();
// 中间件
const loginCheck = require("../middlewares/loginCheck");
const validator = require("../middlewares/validator");
const { activityInfoSchema } = require("../validator/activity");
// controller
const { createActivity } =
// 路由前缀
router.prefix("/activity");
// 创建活动
router.post("/", loginCheck, validator(activityInfoSchema), async (ctx) => {const { username } = ctx.userInfo;const { title, desc, content = {} } = ctx.request.body;const res = await createActivity(username, { title, desc }, content);ctx.body = res;
});
module.exports = router;
创建活动
创建活动对应的路由是/activity,首先第一个中间件是loginCheck:
const { jwtVerify } = require("../utils/jwt");
const { ErrorRes } = require("../res-model/index");
const { loginCheckFailInfo } = require("../res-model/failInfo/index");
module.exports = async function loginCheck(ctx, next) {const errRes = new ErrorRes(loginCheckFailInfo);const token = ctx.header.authorization;if (!token) {ctx.body = errRes;return;}let flag = true;try {const userInfo = await jwtVerify(token);delete userInfo.password;ctx.userInfo = userInfo;} catch (error) {flag = false;ctx.body = errRes;}if (flag) {await next();}
};
前面一节,我也提到了登录这里用的是jwt,在客户端与服务端通信的过程中,一般会把token信息放到HTTP 请求的头信息Authorization字段里面。
首先,我们会通过jwt.sign去对token进行加密。然后验证token时会从ctx.header.authorization中读取token,读取到的情况下再继续使用jwt.verify对token进行验证。
验证通过后才会继续走到下一个中间件。
可以看到这里在token不存在的情况下会抛出错误信息:
const errRes = new ErrorRes(loginCheckFailInfo);
这里的loginCheckFailInfo是预设的错误文案和code:
// 登录校验失败
loginCheckFailInfo: {errCode: -1,msg: "登录校验失败",
},
这种预先定义的错误文案和错误码在大型项目中是很有必要的,一方面对于response的格式有着统一的规范,另一方面错误信息的统一管理在后期项目的迭代和维护上也有着先天的便利性。
loginCheck通过后会继续走到validator中间件,这个主要是对入参数据格式做校验的。
数据校验是日常开发中的常见需求。在客户端进行数据校验可以有更好的交互体验,给予更清晰的反馈文案,并且提前预警,节省服务器端资源。而在服务器端,数据校验通常作为必备流程,来过滤不规范的请求数据。
对数据校验的需求衍生了非常多的校验工具,比如JS 的校验库JOi,python 的jsonschema 包。当面对多语言、多服务的业务需求,意味着同样的规则需要用不同语言的编写重复的校验规则,产生重复劳动,且在数据字段更新时候,所有服务都需要进行同步更新。由此,需要一种更为通用的数据校验方式。
JSON(JavaScript Object Notation)作为一种简单的数据交换格式被广泛应用。基于简单的数据类型可以表示各种结构化数据。 而JSON schema则是定义JSON数据的模式,即约束JSON数据有哪些字段、其值是如何表示的。JSON schema本身用JSON编写,且遵循一定规范,需要使用其他语言编写好的程序来解析与验证。
Javascript的json schema校验可以使用Ajv工具,支持浏览器端以及Node端,基本流程如下
- 引入
ajv包 new一个Ajv实例compile一个validate校验器- 使用校验器进行校验
这里贴一下活动的schema:
const activityInfoSchema = {type: "object",required: ["title"],properties: {title: {type: "string",maxLength: 255,},desc: {type: "string",maxLength: 255,},coverImg: {type: "string",maxLength: 255,},contentId: {type: "string",maxLength: 255,},content: {type: "object",properties: {_id: {type: "string",maxLength: 255,},components: {type: "array",},props: {type: "object",},setting: {type: "object",},},},},
};
入参校验也通过后,下一步就是执行controller中的createActivity:
async function createActivity(author, data = {}, content = {}) {const { title } = data;if (!title) {return new ErrorRes(createActivityFailInfo, "标题不能为空");}const uuid = uuidV4().slice(0, 4);try {const newActivity = await createActivityService({...data,author,uuid,},content);return new SuccessRes(newActivity);} catch (error) {return new ErrorRes(createActivityErrorFailInfo);}
}
这里主要是对title做了空值检查。
有一点要注意的是,在向service传值时,分为了两部分,其中一部分是活动的标题、作者等信息,另一部分则是活动的内容信息(包含使用的组件、整体背景、分享等配置信息)。这个与我们之前所说的是一致的:活动信息和用户信息存储在mydql;活动内容对应的JSON数据存储在mongodb。
接着看下createActivityService:
/**
* 创建活动
*
* @param {*} [data={}] 活动信息
* @param {*} [content={}] 活动内容
* @return {*}
*/
async function createActivityService(data = {}, content = {}) {// 创建活动内容 --- mongooseconst { components = [], props = {}, setting = {} } = content;const newContent = await ActivityContentModel.create({components,props,setting,});const { _id: contentId } = newContent;// 创建活动记录 --- mysqlconst newActivity = await ActivityModel.create({...data,contentId: contentId.toString(),});return newActivity.dataValues;
}
可以看到,先是创建活动内容,然后将生成的_id作为contentId和活动信息同时存到mysql中。
组件平台服务端设计
组件平台主要是以展示组件为主,涉及到的接口主要有:
- 组件新增 post /component
- 组件列表 get /component/list
- 单组件详情 get /component/:id
- 更新组件 patch /component/:id
- 删除组件 delete /component/:id
数据表设计
组件详情
| 列 | 类型 | 备注 |
|---|---|---|
| component_id | int | 组件id |
| version | varchar | 版本号 |
| description | varchar | 描述 |
| author | varchar | 组件作者 |
| coverImg | varchar | 组件封面 |
| config | varchar | 组件配置信息 |
| markdow | varchar | 组件文档描述 |
| create_time | date | 组件创建时间 |
| update_time | date | 组件更新时间 |
组件列表
| 列 | 类型 | 备注 |
|---|---|---|
| id | int | 唯一标识 |
| name | varchar | 组件名称 |
| create_time | date | 组件创建时间 |
| update_time | date | 组件更新时间 |
| frequency | int | 使用频率 |
| author | varchar | 组件作者 |
| status | int | 状态 |
整体代码设计也是标准的Restful API风格,相对也比较简单,这里就不再赘述了。
C端服务端设计
C端也就是我们最终的页面,这里先说下整体的设计思路:
- 根据page_id获取页面配置数据(页面整体配置、组件数据等)
- 判断活动时间及活动状态,决定展示逻辑
- 根据页面数据结合组件库渲染页面
这里其实关键点在于服务端渲染。
To C的营销H5页面的典型特点是:
- 流量大
- 交互相对简单(尤其是由搭建平台搭建的活动页面)
- 对于页面的首屏一般都有比较高的要求
那么为什么服务端渲染就比客户端渲染快呢?
我们分别来对比一下两者的DOM渲染过程。
客户端渲染

服务端渲染
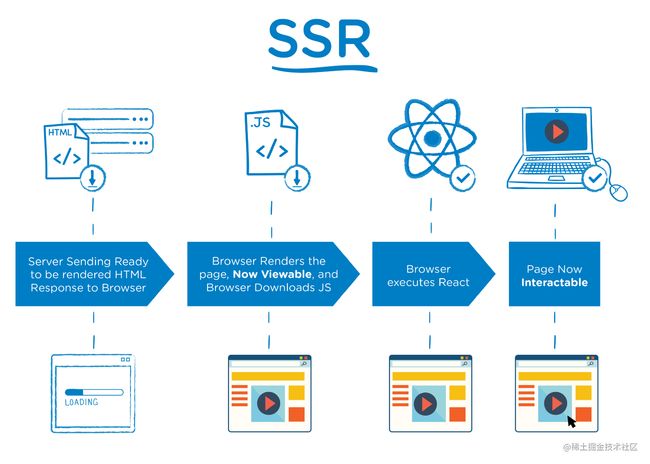
客户端渲染,需要先得到一个空的 HTML 页面(这个时候页面已经进入白屏)之后还需要经历:
- 请求并解析
JavaScript和CSS - 请求后端服务器获取数据
- 根据数据渲染页面
几个过程才可以看到最后的页面。
特别是在复杂应用中,由于需要加载 JavaScript 脚本,越是复杂的应用,需要加载的 JavaScript 脚本就越多、越大,这就会导致应用的首屏加载时间非常长,进而影响用户体验感。
相对于客户端渲染,服务端渲染在用户发出一次页面 url 请求之后,应用服务器返回的 html 字符串就是完备的计算好的,可以交给浏览器直接渲染,使得 DOM 的渲染不再受静态资源和 ajax 的限制。
聊了这么多可能对于服务端渲染的原理还不是很清楚,下面我就以Vue服务端渲染为例来简述一下其原理: 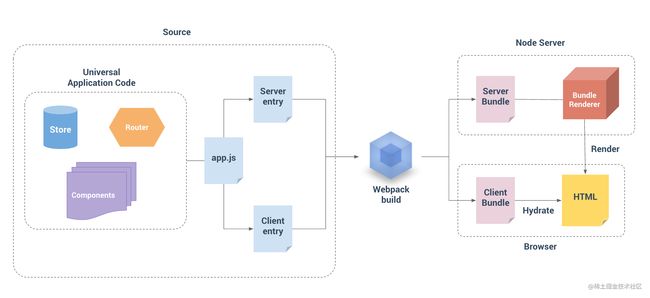
Source为我们的源代码区,即工程代码。
Universal Appliation Code和我们平时的客户端渲染的代码组织形式完全一致,因为渲染过程是在Node端,所以没有DOM和BOM对象,因此不要在beforeCreate和created生命周期钩子里做涉及DOM和BOM的操作。
比客户端渲染多出来的app.js、Server entry 、Client entry的主要作用为:
app.js分别给Server entry、Client entry暴露出createApp()方法,使得每个请求进来会生成新的app实例- 而
Server entry和Client entry分别会被webpack打包成vue-ssr-server-bundle.json和vue-ssr-client-manifest.json
Node端会根据webpack打包好的vue-ssr-server-bundle.json,通过调用createBundleRenderer生成renderer实例,再通过调用renderer.renderToString生成完备的html字符串。
Node端将render好的html字符串返回给Browser,同时Node端根据vue-ssr-client-manifest.json生成的js会和html字符串hydrate,完成客户端激活html,使得页面可交互。
最后
最近找到一个VUE的文档,它将VUE的各个知识点进行了总结,整理成了《Vue 开发必须知道的36个技巧》。内容比较详实,对各个知识点的讲解也十分到位。




有需要的小伙伴,可以点击下方卡片领取,无偿分享