Java多线程之JUC从入门到精通
1. 多线程 J.U.C
1.1 线程池
1.1.1 线程回顾
1)回顾线程创建方式
- 继承Thread
- 实现Runnable
2)线程的状态

-
NEW:刚刚创建,没做任何操作
Thread thread = new Thread(); System.out.println(thread.getState());
-
RUNNABLE:调用run,可以执行,但不代表一定在执行(RUNNING,READY)
thread.start(); System.out.println(thread.getState());
-
BLOCKED:抢不到锁
final byte[] lock = new byte[0]; new Thread(new Runnable() { public void run() { synchronized (lock){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); Thread thread2 = new Thread(new Runnable() { public void run() { synchronized (lock){ } } }); thread2.start(); Thread.sleep(1000); System.out.println(thread2.getState());
-
WAITING
Thread thread2 = new Thread(new Runnable() { public void run() { LockSupport.park(); } }); thread2.start(); Thread.sleep(500); System.out.println(thread2.getState()); LockSupport.unpark(thread2); Thread.sleep(500); System.out.println(thread2.getState()); -
TIMED_WAITING
Thread thread3 = new Thread(new Runnable() { public void run() { try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } } }); thread3.start(); Thread.sleep(500); System.out.println(thread3.getState()); -
TERMINATED
//等待1s后再来看 Thread.sleep(1000); System.out.println(thread.getState());
3)线程池
根据上面的状态,普通线程执行完,就会进入TERMINATED销毁掉,而线程池就是创建一个缓冲池存放线程,执行结束以后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等候下次任务来临,这使得线程池比手动创建线程有着更多的优势:
- 降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
- 提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行;
- 方便线程并发数的管控。因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM
- 节省cpu切换线程的时间成本(需要保持当前执行线程的现场,并恢复要执行线程的现场)。
- 提供更强大的功能,延时定时线程池。 (Timer vs ScheduledThreadPoolExecutor)
4)线程池体系( 查看:ScheduledThreadPoolExecutor,ForkJoinPool类图 )
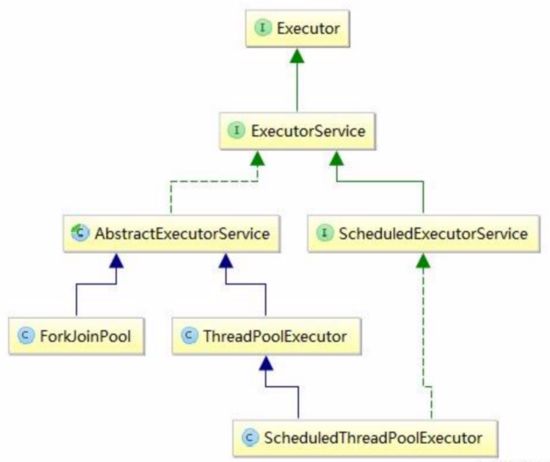
说明:
- 最常用的是ThreadPoolExecutor
- 调度用ScheduledThreadPoolExecutor
- 任务拆分合并用ForkJoinPool
- Executors是工具类,协助你创建线程池的
1.1.2 工作机制
1)线程池状态
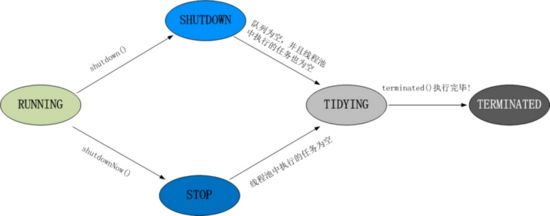
- RUNNING :初始化状态是RUNNING。线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0。RUNNING状态下,能够接收新任务,以及对已添加的任务进行处理。
-
SHUTDOWN:SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
//shutdown后不接受新任务,但是task1,仍然可以执行完成 ExecutorService poolExecutor = Executors.newFixedThreadPool(5); poolExecutor.execute(new Runnable() { public void run() { try { Thread.sleep(1000); System.out.println("finish task 1"); } catch (InterruptedException e) { e.printStackTrace(); } } }); poolExecutor.shutdown(); poolExecutor.execute(new Runnable() { public void run() { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }); System.out.println("ok"); -
STOP:不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。调用线程池的shutdownNow()接口时,线程池由(RUNNING 或 SHUTDOWN ) -> STOP
注意:容易引发不可预知的结果!运行中的任务也许还会打印,直到结束,因为调的是Thread.interrupt
//改为shutdownNow后,任务立马终止,sleep被打断,新任务无法提交,task1停止 poolExecutor.shutdownNow();
-
TIDYING:所有的任务已终止,队列中的”任务数量”为0,线程池会变为TIDYING。线程池变为TIDYING状态时,会执行钩子函数terminated(),可以通过重载terminated()函数来实现自定义行为
//自定义类,重写terminated方法 public class MyExecutorService extends ThreadPoolExecutor { public MyExecutorService(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueueworkQueue) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue); } @Override protected void terminated() { super.terminated(); System.out.println("terminated"); } //调用 shutdownNow, ternimated方法被调用打印 public static void main(String[] args) throws InterruptedException { MyExecutorService service = new MyExecutorService(1,2,10000,TimeUnit.SECONDS,new LinkedBlockingQueue (5)); service.shutdownNow(); } } - TERMINATED :线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED
2)结构说明
在线程池的编程模式下,任务是提交给整个线程池,而不是直接提交给某个线程,线程池在拿到任务后,就在内部协调空闲的线程,如果有,则将任务交给某个空闲的线程。一个线程同时只能执行一个任务,但可以同时向一个线程池提交多个任务。
(源码查看:两个集合,一个queue,一个hashset)

3)任务的提交
- 添加任务,如果线程池中线程数没达到coreSize,直接创建新线程执行
- 达到core,放入queue
- queue已满,未达到maxSize继续创建线程
- 达到maxSize,根据reject策略处理
- 超时后,线程被释放,下降到coreSize
1.1.3 源码剖析
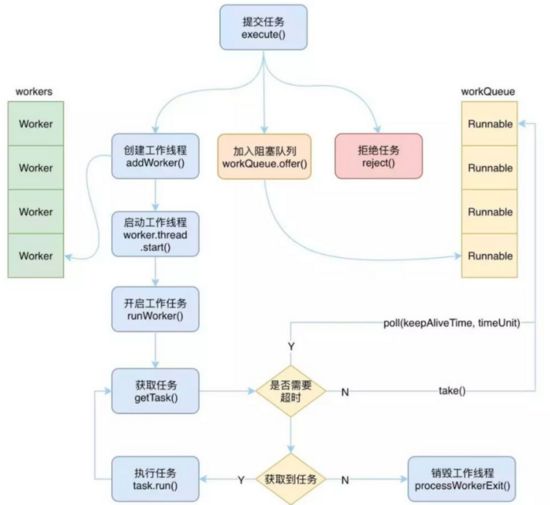
//任务提交阶段:(4个if条件路线)
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//判断工作数,如果小于coreSize,addWork,注意第二个参数core=true
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//否则,如果线程池还在运行,offer到队列
if (isRunning(c) && workQueue.offer(command)) {
//再检查一下状态
int recheck = ctl.get();
//如果线程池已经终止,直接移除任务,不再响应
if (! isRunning(recheck) && remove(command))
reject(command);
//否则,如果没有可用线程的话(比如coreSize=0),创建一个空work
//该work创建时不会给指派任务(为null),但是会被放入works集合,进而从队列获取任务去执行
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//队列也满,继续调addWork,但是注意,core=false,开启到maxSize的大门
//超出max的话,addWork会返回false,进入reject
else if (!addWorker(command, false))
reject(command);
}
//线程创建
private boolean addWorker(Runnable firstTask, boolean core) {
//第一步,计数判断,不符合条件打回false
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
for (;;) {
int wc = workerCountOf(c);
//判断线程数,注意这里!
//也就说明线程池的线程数是不可能设置任意大的。
//最大29位(CAPACITY=29位二进制)
//超出规定范围,返回false,表示不允许再开启新工作线程,创建worker失败!
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//第二步,创建新work放入线程集合works(一个HashSet)
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//符合条件,创建新的work并包装task
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
//加锁,workers是一个hashset,这里要保障线程安全性
mainLock.lock();
try {
//...
//在这里!!!
workers.add(w);
//...
workerAdded = true;
} finally {
mainLock.unlock();
}
if (workerAdded) {
//注意,只要是成功add了新的work,那么将该新work立即启动,任务得到执行
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
//任务获取与执行
//在worker执行runWorker()的时候,不停循环,先查看自己有没有携带Task,如果有,执行
while (task != null || (task = getTask()) != null)
//如果没用,会调用getTask,从队列获取任务
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// ...
int wc = workerCountOf(c);
// Are workers subject to culling? - 很形象,要不要乖乖的被“捕杀”?
//判断是不是要超时处理,重点!!!决定了当前线程要不要被释放
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//线程数超出max,并且上次循环中poll等待超时了,那么说明该线程已终止
//将线程队列数量原子性减
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//计数器做原子递减,递减成功后,返回null,for被中止
if (compareAndDecrementWorkerCount(c))
return null;
//递减失败,继续下一轮循环,直到成功
continue;
}
try {
//重点!!!
//如果线程可被释放,那就poll,释放的时间为:keepAliveTime
//否则,线程是不会被释放的,take一直被阻塞在这里,直到来了新任务继续工作
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
//到这里说明可被释放的线程等待超时,已经销毁,设置该标记,下次循环将线程数减少
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
1.1.4 Executors
以上构造函数比较多,为了方便使用,juc提供了一个Executors工具类,内部提供静态方法
1)newCachedThreadPool() : 弹性线程数
2)newFixedThreadPool(int nThreads) : 固定线程数
3)newSingleThreadExecutor() : 单一线程数
4)newScheduledThreadPool(int corePoolSize) : 可调度,常用于定时
1.1.5 经典面试
1)线程池是如何保证线程不被销毁的呢?
答案:如果队列中没有任务时,核心线程会一直阻塞在获取任务的方法,直到返回任务。而任务执行完后,又会进入下一轮 work.runWork()中循环
验证:秘密就藏在核心源码里 ThreadPoolExecutor.getTask()
//work.runWork():
while (task != null || (task = getTask()) != null)
//work.getTask():
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
2)那么线程池中的线程会处于什么状态?
答案:RUNNABLE,WAITING
验证:起一个线程池,放置一个任务sleep,debug查看结束前后的状态
//debug add watcher: ((ThreadPoolExecutor) poolExecutor).workers.iterator().next().thread.getState()
ThreadPoolExecutor poolExecutor = Executors.newFixedThreadPool(1);
poolExecutor.execute(new Runnable() {
public void run() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
System.out.println("ok");
3)核心线程与非核心线程有区别吗?
答案:没有。被销毁的线程和创建的先后无关。即便是第一个被创建的核心线程,仍然有可能被销毁
验证:看源码,每个work在runWork()的时候去getTask(),在getTask内部,并没有针对性的区分当前work是否是核心线程或者类似的标记。只要判断works数量超出core,就会调用poll(),否则take()
1.2 Fork/Join
1.2.1 概念
ForkJoin是由JDK1.7后提供多线并发处理框架。可以理解为一种特殊的线程池。
1.任务分割:Fork(分岔),先把大的任务分割成足够小的子任务,如果子任务比较大的话还要对子任务进行继续分割。
2.合并结果:join,分割后的子任务被多个线程执行后,再合并结果,得到最终的完整输出。
1.2.2 组成
- ForkJoinTask :主要提供fork和join两个方法用于任务拆分与合并;一般用子类 RecursiveAction(无返回值的任务)和RecursiveTask(需要返回值)来实现compute方法。

- ForkJoinPool :调度ForkJoinTask的线程池;
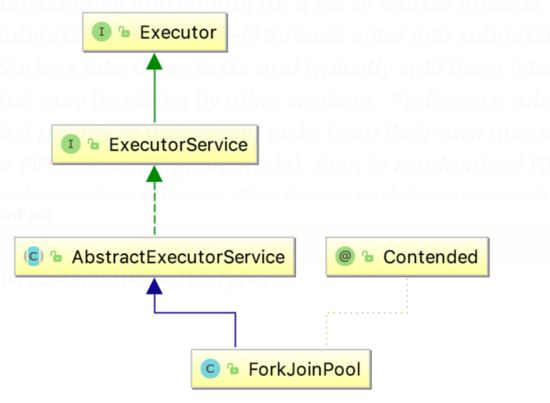
- ForkJoinWorkerThread :Thread的子类,存放于线程池中的工作线程(Worker);

- WorkQueue :任务队列,用于保存任务;
1.2.3 基本使用
一个典型的例子:计算1-1000的和
package com.itheima.thread;
import java.util.concurrent.*;
public class SumTask {
private static final Integer MAX = 100;
static class SubTask extends RecursiveTask {
// 子任务开始计算的值
private Integer start;
// 子任务结束计算的值
private Integer end;
public SubTask(Integer start , Integer end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if(end - start < MAX) {
//小于边界,开始计算
System.out.println("start = " + start + ";end = " + end);
Integer totalValue = 0;
for(int index = this.start ; index <= this.end ; index++) {
totalValue += index;
}
return totalValue;
}else {
//否则,中间劈开继续拆分
SubTask subTask1 = new SubTask(start, (start + end) / 2);
subTask1.fork();
SubTask subTask2 = new SubTask((start + end) / 2 + 1 , end);
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
Future taskFuture = pool.submit(new SubTask(1,1000));
try {
Integer result = taskFuture.get();
System.out.println("result = " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace(System.out);
}
}
}
1.2.4 设计思想
- 普通线程池内部有两个重要集合:工作线程集合(普通线程),和任务队列。
- ForkJoinPool也类似,线程集合里放的是特殊线程ForkJoinWorkerThread,任务队列里放的是特殊任务ForkJoinTask
- 不同之处在于,普通线程池只有一个队列。而ForkJoinPool的工作线程ForkJoinWorkerThread每个线程内都绑定一个双端队列。

- 在fork的时候,也就是任务拆分,将拆分的task会被当前线程放到自己的队列中。
- 如果有任务,那么线程优先从自己的队列里取任务执行,默认从队尾
- 当自己队列中执行完后,工作线程会跑到其他队列的队首偷任务来执行。 也就是所说的 “窃取”
1.2.5 注意点
使用ForkJoin将相同的计算任务通过多线程执行。但是在使用中需要注意:
- 注意任务切分的粒度,也就是fork的界限。并非越小越好
- 判断要不要使用ForkJoin。任务量不是太大的话,串行可能优于并行。因为多线程会涉及到上下文的切换
1.3 原子操作
1.3.1 概念
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为"不可被中断的一个或一系列操作" 。类比于数据库事务,redis的multi。
1.3.2 CAS
Compare And Set(或Compare And Swap),翻译过来就是比较并替换,CAS操作包含三个操作数——内存位置(V)、预期原值(A)、新值(B)。从第一视角来看,理解为:我认为位置 V 应该是 A,如果是A,则将 B 放到这个位置;否则,不要更改,只告诉我这个位置现在的值即可。所以cas内部一般伴随着while循环操作,不停的去尝试
juc中提供了Atomic开头的类,基于cas实现原子性操作,最基本的应用就是计数器
package com.itheima;
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicCounter {
private static AtomicInteger i = new AtomicInteger(0);
public int get(){
return i.get();
}
public void inc(){
i.incrementAndGet();
}
public static void main(String[] args) throws InterruptedException {
final AtomicCounter counter = new AtomicCounter();
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
public void run() {
counter.inc();
}
}).start();
}
Thread.sleep(3000);
//可以正确输出10
System.out.println(counter.i.get());
}
}
注:AtomicInteger源码。基于unsafe类cas思想实现,性能篇会讲到
1.3.3 atomic
上面展示了AtomicInteger,关于atomic包,还有很多其他类型:
-
基本类型
- AtomicBoolean:以原子更新的方式更新boolean;
- AtomicInteger:以原子更新的方式更新Integer;
- AtomicLong:以原子更新的方式更新Long;
-
引用类型
- AtomicReference : 原子更新引用类型
- AtomicReferenceFieldUpdater :原子更新引用类型的字段
- AtomicMarkableReference : 原子更新带有标志位的引用类型
-
数组
- AtomicIntegerArray:原子更新整型数组里的元素。
- AtomicLongArray:原子更新长整型数组里的元素。
- AtomicReferenceArray:原子更新引用类型数组里的元素。
-
字段
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型。
1.3.4 注意!
使用atomic要注意原子性的边界,把握不好会起不到应有的效果,原子性被破坏。
案例:原子性被破坏现象
package com.itheima;
import java.util.concurrent.atomic.AtomicInteger;
public class BadAtomic {
AtomicInteger i = new AtomicInteger(0);
static int j=0;
public void badInc(){
int k = i.incrementAndGet();
try {
Thread.sleep(new Random().nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
j=k;
}
public static void main(String[] args) throws InterruptedException {
BadAtomic atomic = new BadAtomic();
for (int i = 0; i < 10; i++) {
new Thread(()->{
atomic.badInc();
}).start();
}
Thread.sleep(3000);
System.out.println(atomic.j);
}
}
结果分析:
- 每次都不一样,总之不是10
- i是原子性的,没问题。但是再赋值,变成了两部操作,原子性被打破
- 在badInc上加synchronized,问题解决
1.4 AQS
1.4.1 概念
首先搞清楚,AbstractQueuedSynchronizer抽象的队列式同步器,是一个抽象类,这个类在java.util.concurrent.locks包。
除了java自带的synchronized关键字之外,jdk提供的另外一种锁机制。如果需要自己实现灵活的锁逻辑,可以考虑使用AQS,非常的便捷。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable
jdk中使用AQS的线程工具类很多,自旋锁、互斥锁、读锁写锁、信号量、通过类继承关系可以轻松查看,所以说,AQS是juc中很多类的基石。
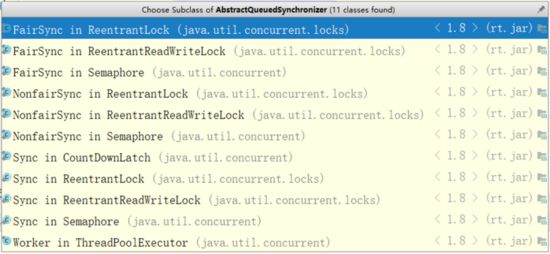
1.4.2 原理
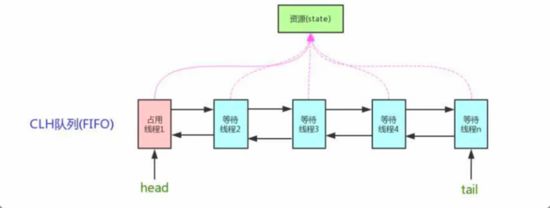
- state:状态,int类型的成员变量,当state>0时表示锁有人占着,当state = 0时表示释放了锁。
- 队列:拿不到锁的线程进队列。
1.4.3 源码
AQS使用了模板设计模式。只需要实现指定的锁获取方法即可,内部的机制AQS已帮你封装好。
(AQS源码idea中查看)
需要子类继承AQS,并实现的方法(protected):
protected boolean tryAcquire(int arg) //独占式获取同步状态 protected boolean tryRelease(int arg) //独占式释放同步状态 protected int tryAcquireShared(int arg) //共享式获取同步状态 protected boolean tryReleaseShared(int arg) //共享式释放同步状态
使用时,调用的是父类的方法(public)
public final void acquire(int arg) //独享锁获取 public final boolean release(int arg) //独享锁释放 public final void acquireShared(int arg) //共享锁获取 public final boolean releaseShared(int arg) //共享锁释放
源码分析
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
//可共享式获取锁,外部调用,模板模式
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
//需要实现的部分,空protected方法,被上面的对外方法所调用
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
//同理,锁的释放,模板模式
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
//独占式获取
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
//独占式释放
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
}
1.4.4 经典面试
一个阿里面试题:自己实现一个锁,最大允许指定数量的线程并行运作。其他排队等候
package com.itheima;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
public class MyLock extends AbstractQueuedSynchronizer {
public MyLock(int count){
setState(count);
}
@Override
protected int tryAcquireShared(int arg) {
//自旋,cas方式不停获取数量
for (; ; ) {
int current = getState();
int newCount = current - arg;
if (newCount < 0 || compareAndSetState(current, newCount)) {
return newCount;
}
}
}
@Override
protected boolean tryReleaseShared(int arg) {
for (; ; ) {
int current = getState();
int newState = current + arg;
if (compareAndSetState(current, newState)) {
return true;
}
}
}
public static void main(String[] args) {
final MyLock lock = new MyLock(3);
for (int i = 0; i < 30; i++) {
new Thread(new Runnable() {
public void run() {
lock.acquireShared(1);
try {
Thread.sleep(1000);
System.out.println("ok");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.releaseShared(1);
}
}
}).start();
}
}
}
验证结果:虽然30个一次性start,但是会每1s输出3个ok,达到了并发控制
1.5 并发容器
juc中还包含很多其他的并发容器(了解)
1.ConcurrentHashMap
对应:HashMap
目标:代替Hashtable、synchronizedMap,使用最多,源码篇会详细讲解
原理:JDK7中采用Segment分段锁,JDK8中采用CAS+synchronized
2.CopyOnWriteArrayList
对应:ArrayList
目标:代替Vector、synchronizedList
原理:高并发往往是读多写少的特性,读操作不加锁,而对写操作加Lock独享锁,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性。
查看源码:volatile array,lock加锁,数组复制
3.CopyOnWriteArraySet
对应:HashSet
目标:代替synchronizedSet
原理:与CopyOnWriteArrayList实现原理类似。
4.ConcurrentSkipListMap
对应:TreeMap
目标:代替synchronizedSortedMap(TreeMap)
原理:基于Skip list(跳表)来代替平衡树,按照分层key上下链接指针来实现。
附加:跳表
5.ConcurrentSkipListSet
对应:TreeSet
目标:代替synchronizedSortedSet(TreeSet)
原理:内部基于ConcurrentSkipListMap实现,原理一致
6.ConcurrentLinkedQueue
对应:LinkedList
对应:无界线程安全队列
原理:通过队首队尾指针,以及Node类元素的next实现FIFO队列
7.BlockingQueue
对应:Queue
特点:拓展了Queue,增加了可阻塞的插入和获取等操作
原理:通过ReentrantLock实现线程安全,通过Condition实现阻塞和唤醒
实现类:
- LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列
- ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列
- PriorityBlockingQueue:按优先级排序的队列