缓存击穿、缓存穿透、缓存雪崩搞清楚了吗?
解决缓存穿透问题
- 前言
- 正文
-
- 三种缓存问题介绍
- 解决缓存穿透
-
- 方案一:缓存空值
- 方案二:使用布隆过滤器
-
- 布隆过滤器作用是什么呢?
- 工作原理
- 误差
- 应用
- 解决缓存击穿问题
- 解决缓存雪崩问题
-
- 解决大量数据同时过期
- 解决Redis 故障宕机
- 总结
-
- 参考连接
前言
大家好,我是练习两年半的Java练习生,今天我们来讲一讲redis中常见的缓存问题
正文
三种缓存问题介绍
首先,我们先来缕一缕缓存穿透 、 缓存击穿、 缓存雪崩这三者到底有什么区别 ?
有时候我们看时就觉得自己会了,但回过头就忘了。今天就带大家来缕一缕
缓存雪崩
缓存雪崩是比较好理解的,就是在同一时间有大量的key值失效,导致大量请求打到数据库层面上。这跟真正的雪崩差不多。
大家可以想象真正的雪崩,必须是很多雪(key)同时脱落。


缓存击穿
缓存击穿 , 一个热点key失效,大量并发请求对其中进行访问,导致大量请求打到数据库上。
这个可以想象万军丛中,当很多人都攻击你的盾(热点key )时,突然这时候你的盾破了,你(数据库)就要被很多刀枪伺候了。

缓存穿透
缓存穿透,恶意攻击者通过请求Redis中本就不存在的key值,那么这种请求将直接打到数据库上,导致数据库压力变大。
这种情况就好比,你拿着盾,别人从背后偷袭你,你就防不胜防了

好啦,这下子我们妈妈再也不用担心我们弄混缓存穿透、缓存击穿、缓存雪崩问题了。接下来就让我们一起分析如何解决这三种问题吧!
解决缓存穿透
方案一:缓存空值
针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用。
看似很简单是不是?

但这样做的坏处是什么呢?
对,很明显,这样做是很浪费空间的,而且我们浪费的是我们宝贵的内存空间!
那有没有更好的方法呢?
肯定是有的,那就是在请求进入redis之前进行非法请求的过滤,比如校验ip、设置防火墙等等
但我们除了缓存空值这种方法之外,也有一种更高级的方法,能更好的过滤请求,就是接下要介绍的布隆过滤器
方案二:使用布隆过滤器
布隆过滤器作用是什么呢?
在请求进入redis之前,会先根据布隆过滤器判断数据库中是否有该数据,有才进入redis查询,没有的话就直接返回。存在误判情况!
查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。

工作原理
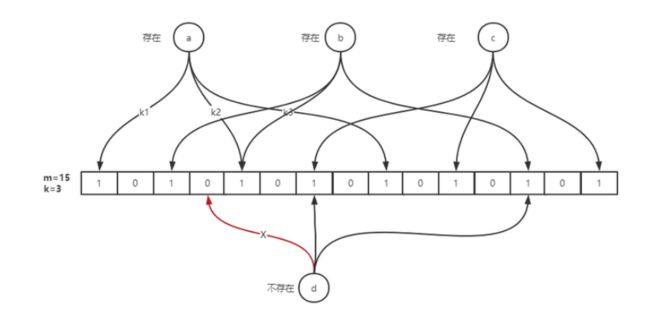
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点(offset),把它们置为 1。
检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。这就是布隆过滤器的基本思想。
误差
布隆过滤器可以 100% 判断元素不在集合中,但是当元素在集合中时可能存在误判,因为当元素非常多时散列函数产生的 k 位点可能会重复。
假设:
- 位数组长度 m
- 散列函数个数 k
- 预期元素数量 n
- 期望误差_ε_
在创建布隆过滤器时我们为了找到合适的 m 和 k , 可以根据预期元素数量 n 与 ε 来推导出最合适的 m 与 k 。(推到过程过于复杂,没看懂,想了解的见文末)
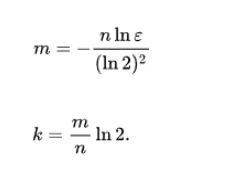
应用
在实践中,我们不用自己去实现,已经有可用的api。像java 中 Guava, Redisson 都已经实现了。
后面有机会向大家介绍。
解决缓存击穿问题
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
上面已经介绍过了,那么我们可以通过
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
面试官:那如何实现互斥锁呢?
互斥锁的实现可以利用我们redis中的SETNX命令。
解决缓存雪崩问题
通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存
当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
发生缓存雪崩有两个原因:
- 大量数据同时过期;
- Redis 故障宕机;
解决大量数据同时过期
- 均匀设置过期时间
我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。 - 互斥锁
如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存 - 双 key 策略
我们对缓存数据可以使用两个 key,一个是主 key,会设置过期时间,一个是备 key,不会设置过期
当业务线程访问不到「主 key 」的缓存数据时,就直接返回「备 key 」的缓存数据,然后在更新缓存的时候,同时更新「主 key 」和「备 key 」的数据。 - 后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
第一种方式,后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存
第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存
解决Redis 故障宕机
方法有以下几种:
- 服务熔断或请求限流机制;
因为 Redis 故障宕机而导致缓存雪崩问题时,我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力 - 构建 Redis 缓存高可靠集群;
服务熔断或请求限流机制是缓存雪崩发生后的应对方案,我们最好通过主从节点的方式构建 Redis 缓存高可靠集群。
总结
好啦,以上就是我们今天要介绍的全部内容,希望能帮助你搞清楚缓存穿透、缓存击穿、缓存雪崩。如果有什么问题,欢迎在评论区讨论,一起学习进步!

参考连接
https://xiaolincoding.com/redis/cluster/cache_problem.html#redis-%E6%95%85%E9%9A%9C%E5%AE%95%E6%9C%BA
https://en.wikipedia.org/wiki/Bloom_filter