Linux内核PID管理
Linux内核PID管理
前言
了解Linux内核PID管理的目的是想了解:当kill掉一个进程之后,/proc/目录下对应的pid目录是否会立即消失。
proc/pid
proc是一个虚拟文件系统,文件系统在注册时都会注册属于该文件系统的文件操作函数(file operations)和节点操作函数(inode operations),而proc文件系统的根目录作为一个特殊的文件节点,在文件系统注册时,还为该节点注册了特定的file operations和inode operations,进程对应的pid目录便是通过该节点的file operations来创建的:
/*
* This is the root "inode" in the /proc tree..
*/
struct proc_dir_entry proc_root = {
.low_ino = PROC_ROOT_INO,
.namelen = 5,
.mode = S_IFDIR | S_IRUGO | S_IXUGO,
.nlink = 2,
.refcnt = REFCOUNT_INIT(1),
.proc_iops = &proc_root_inode_operations,
.proc_fops = &proc_root_operations,
.parent = &proc_root,
.subdir = RB_ROOT,
.name = "/proc",
};
/*
* The root /proc directory is special, as it has the
* directories. Thus we don't use the generic
* directory handling functions for that..
*/
static const struct file_operations proc_root_operations = {
.read = generic_read_dir,
.iterate_shared = proc_root_readdir,
.llseek = generic_file_llseek,
};
static int proc_fill_super(struct super_block *s, struct fs_context *fc)
{
......
pde_get(&proc_root);
root_inode = proc_get_inode(s, &proc_root);
if (!root_inode) {
pr_err("proc_fill_super: get root inode failed\n");
return -ENOMEM;
}
s->s_root = d_make_root(root_inode);
if (!s->s_root) {
pr_err("proc_fill_super: allocate dentry failed\n");
return -ENOMEM;
}
......
}
当对proc文件系统的根目录进行访问时,如ls命令显示/proc目录下的文件时,其调用栈如下(即通过系统调用getdents来获取/proc下所有但的目录项,每一个目录项对应于一个文件):
__arm64_sys_getdents64
ksys_getdents64
iterate_dir
proc_root_readdir
在/proc目录下的文件分为两种:通过proc_create等接口创建产生的文件,如cpuinfo;pid目录文件。
static int proc_root_readdir(struct file *file, struct dir_context *ctx)
{
if (ctx->pos < FIRST_PROCESS_ENTRY) {
int error = proc_readdir(file, ctx); //先读取普通的文件目录,如通过proc_create创建的cpuinfo等节点
if (unlikely(error <= 0))
return error;
ctx->pos = FIRST_PROCESS_ENTRY;
}
return proc_pid_readdir(file, ctx);//读取pid目录节点
}
通过proc_pid_readdir函数读取pid目录文件的过程为:通过next_tgid遍历系统中的进程;遍历的过程中调用proc_fill_cache将进程信息以目录项(dentry)的形式填入用户缓冲区。也就是说每一次读取/proc目录,都会执行proc_pid_readdir函数根据当前系统中的进程构建pid目录项,所以当/proc下没有某一个pid目录时,表示该pid对应的进程一定不在。
/* for the /proc/ directory itself, after non-process stuff has been done */
int proc_pid_readdir(struct file *file, struct dir_context *ctx)
{
struct tgid_iter iter;
struct pid_namespace *ns = proc_pid_ns(file_inode(file));
loff_t pos = ctx->pos;
if (pos >= PID_MAX_LIMIT + TGID_OFFSET)
return 0;
if (pos == TGID_OFFSET - 2) {
struct inode *inode = d_inode(ns->proc_self);
if (!dir_emit(ctx, "self", 4, inode->i_ino, DT_LNK))
return 0;
ctx->pos = pos = pos + 1;
}
if (pos == TGID_OFFSET - 1) {
struct inode *inode = d_inode(ns->proc_thread_self);
if (!dir_emit(ctx, "thread-self", 11, inode->i_ino, DT_LNK))
return 0;
ctx->pos = pos = pos + 1;
}
iter.tgid = pos - TGID_OFFSET;
iter.task = NULL;
for (iter = next_tgid(ns, iter);
iter.task;
iter.tgid += 1, iter = next_tgid(ns, iter)) {
char name[10 + 1];
unsigned int len;
cond_resched();
if (!has_pid_permissions(ns, iter.task, HIDEPID_INVISIBLE))
continue;
len = snprintf(name, sizeof(name), "%u", iter.tgid);
ctx->pos = iter.tgid + TGID_OFFSET;
if (!proc_fill_cache(file, ctx, name, len,
proc_pid_instantiate, iter.task, NULL)) {
put_task_struct(iter.task);
return 0;
}
}
ctx->pos = PID_MAX_LIMIT + TGID_OFFSET;
return 0;
}
pid管理
在kernel中,task_struct结构体记录了进程所持有的所有资源,而pid则是task_struct的标识。进程在fork或clone是会分配一个新的唯一的pid给新的进程。并且除了pid值之外,进程还包含其他id:tgid,线程组leader进程的pid,如果为单一线程,pid和tgid相同;pgid,进程组leader进程的pid;sid,会话组leader进程的pid。三者的关系是,一个进程可以包含多个线程,组成一个线程组;多个进程可以组成一个进程组;一个会话组又包含多个进程组。
为了实现虚拟化和pid管理,kernel中引入了pid namespace的概念,用于实现pid资源的隔离。
struct pid_namespace {
struct kref kref; //引用计数
struct idr idr; //基数树
struct rcu_head rcu;
unsigned int pid_allocated; //该namespace已经分配的pid数
struct task_struct *child_reaper; //该namespace的'init'进程,也就是第一个进程
struct kmem_cache *pid_cachep; //分配pid struct的cache
unsigned int level; //当前namespace的层级,当level为0时,为global namespace即init进程的namespace
struct pid_namespace *parent; //父pid namespace
.........
} __randomize_layout;
进程只能够看到同属于一个pid namespace的pid信息,因此不同pid namespace之间可以存在相同的pid number。此外,高层级的pid namespace在衍生出低层级的pid namespace时,低层级中分配的pid都会在高层级的pid namespace中进行映射,即高层级的pid namespace可以看到低层级pid namespace的信息。以一个映射图描述如下:
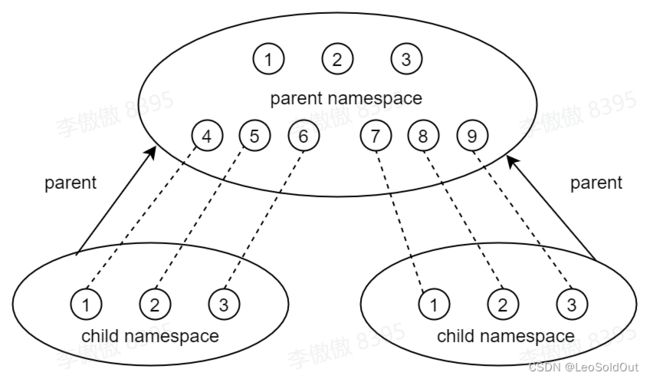
在同一个pid namespace中利用IDR(类似于基数树)对pid 进行管理用于pid的快速查找,其中,IDR节点中的key对应于pid number,value对应于pid struct ptr。
struct pid
{
refcount_t count; //引用计数
unsigned int level; //所属pid namespace的层级
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; //每种类型的pid的哈希表头
/* wait queue for pidfd notifications */
wait_queue_head_t wait_pidfd;
struct rcu_head rcu;
struct upid numbers[1]; //变长的数组,表示该pid在本层之上的各个层级中的pid映射
};
enum pid_type
{
PIDTYPE_PID, //进程pid
PIDTYPE_TGID, //线程组leader进程pid
PIDTYPE_PGID, //进程组leader进程pid
PIDTYPE_SID, //会话组leader进程pid
PIDTYPE_MAX,
};
/*
* struct upid is used to get the id of the struct pid, as it is
* seen in particular namespace. Later the struct pid is found with
* find_pid_ns() using the int nr and struct pid_namespace *ns.
*/
struct upid {
int nr; //在pid namespace中的pid number
struct pid_namespace *ns; //指向所属的pid namespace
}:
此外,pid number还存在于task_strcut结构体中:
struct task_struct {
......
pid_t pid; //指向进程描述符
pid_t tgid; //指向线程描述符
struct task_struct *group_leader; //主线程/进程组leader进程
/* PID/PID hash table linkage. */
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX]; //hash表节点,用于根据hash链表索引到task_struct
struct list_head thread_group;
struct list_head thread_node;
......
);
pid number,struct pid以及struct task_struct之间的关系图如下:
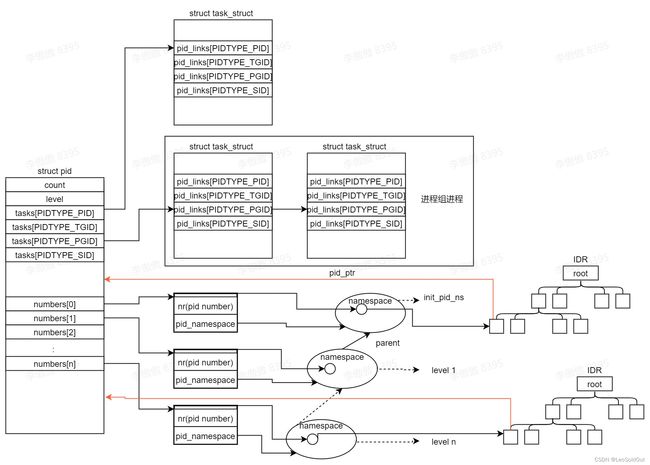
以struct pid的元素进行衍生:
- numbers
numbers数组代表了该pid struct在各个层级pid namespace的映射,numbers[level].pid_namespace指向其在第level层的namespace,numbers[level].nr表示其在第level层pid namespace的pid number。其中,顶层的pid namespace为init_pid_ns,是一个全局的pid namespace,task_struct结构体中的pid值就是指在init_pid_ns中的pid number。结合pid的分配过程来看:
//入参为pid_namespace表示在该pid_namespace中进行pid分配
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
int retval = -ENOMEM;
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
return ERR_PTR(retval);
tmp = ns;
pid->level = ns->level;
//遍历所有层级的pid namespace,并建立层级之间的pid映射关系
for (i = ns->level; i >= 0; i--) {
int pid_min = 1;
idr_preload(GFP_KERNEL);
spin_lock_irq(&pidmap_lock);
/*
* init really needs pid 1, but after reaching the maximum
* wrap back to RESERVED_PIDS
*/
if (idr_get_cursor(&tmp->idr) > RESERVED_PIDS)
pid_min = RESERVED_PIDS;
/*
* Store a null pointer so find_pid_ns does not find
* a partially initialized PID (see below).
*/
nr = idr_alloc_cyclic(&tmp->idr, NULL, pid_min,
pid_max, GFP_ATOMIC); //在idr树中查找一个可用的pid number,并将pid_ptr关联到NULL
spin_unlock_irq(&pidmap_lock);
idr_preload_end();
if (nr < 0) {
retval = (nr == -ENOSPC) ? -EAGAIN : nr;
goto out_free;
}
//pid->numbers是一个变长的数组,数组长度是在create_namespace的时候确定的,ns->pid_cachep缓冲区中结构体的大小就是已经确定好了数组长度的pid 结构缓冲区
pid->numbers[i].nr = nr; //设置当前层级的pid的映射
pid->numbers[i].ns = tmp; //设置当前层级的namespace
tmp = tmp->parent;
}
if (unlikely(is_child_reaper(pid))) {
if (pid_ns_prepare_proc(ns))
goto out_free;
}
get_pid_ns(ns); //增加namespace的引用计数
refcount_set(&pid->count, 1); //增加pid的引用计数
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]); //初始化pid->task hash表
init_waitqueue_head(&pid->wait_pidfd);
upid = pid->numbers + ns->level; //从当前level开始,初始化upid
spin_lock_irq(&pidmap_lock);
if (!(ns->pid_allocated & PIDNS_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
/* Make the PID visible to find_pid_ns. */
idr_replace(&upid->ns->idr, pid, upid->nr); //每一个层级的pid_ptr均指向当前的pid struct
upid->ns->pid_allocated++; //增加层级pid namespace的分配数
}
spin_unlock_irq(&pidmap_lock);
return pid;
............
}
前面提到,struct pid中的numbers是一个变长的数组,数组长度取决于pid namespace所在的level,而pid struct通过kmem_cache_alloc从pid namespace对应的cache中分配,该cache在pid namespace创建时进行初始化,使得每个pid struct中的numbers固定为level大小:
static struct pid_namespace *create_pid_namespace(struct user_namespace *user_ns,
struct pid_namespace *parent_pid_ns)
{
struct pid_namespace *ns;
unsigned int level = parent_pid_ns->level + 1; //新的namespace的level为父namespace的level + 1
struct ucounts *ucounts;
int err;
err = -EINVAL;
if (!in_userns(parent_pid_ns->user_ns, user_ns))
goto out;
err = -ENOSPC;
if (level > MAX_PID_NS_LEVEL)
goto out;
ucounts = inc_pid_namespaces(user_ns); //增加引用计数
if (!ucounts)
goto out;
err = -ENOMEM;
ns = kmem_cache_zalloc(pid_ns_cachep, GFP_KERNEL); //获取namespace结构体
if (ns == NULL)
goto out_dec;
idr_init(&ns->idr); //初始化基数树
//初始化pid struct分配缓冲区,pid struct的numbers是一个变长数组,数组长度为level,这里创建分配缓冲区的时候变设置了pid strcut的结构体大小,后续从该namespace中申请的pid struct中的numbers都有level个元素
ns->pid_cachep = create_pid_cachep(level);
if (ns->pid_cachep == NULL)
goto out_free_idr;
err = ns_alloc_inum(&ns->ns);
if (err)
goto out_free_idr;
ns->ns.ops = &pidns_operations;
kref_init(&ns->kref);
ns->level = level; //初始化namespace的level
ns->parent = get_pid_ns(parent_pid_ns); //设置父pid namespace
ns->user_ns = get_user_ns(user_ns);
ns->ucounts = ucounts;
ns->pid_allocated = PIDNS_ADDING;
INIT_WORK(&ns->proc_work, proc_cleanup_work);
return ns;
out_free_idr:
idr_destroy(&ns->idr);
kmem_cache_free(pid_ns_cachep, ns);
out_dec:
dec_pid_namespaces(ucounts);
out:
return ERR_PTR(err);
}
- tasks
pid struct中的tasks数组是一个hash链表数组,每一个数组元素指向一个hash链表的头,用于链接起同一类进程。可以用于根据pid struct找到对应的task_struct。加入到链表是在copy_process中:
static __latent_entropy struct task_struct *copy_process(
struct pid *pid,
int trace,
int node,
struct kernel_clone_args *args)
{
......
init_task_pid_links(p); //初始化task_struct的pid_links
if (likely(p->pid)) { //进程创建成功时
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid); //设置task_strcut的thread_pid,进程pid为pid
if (thread_group_leader(p)) { //如果创建的是一个进程
init_task_pid(p, PIDTYPE_TGID, pid); //设置task_struct的signal->pids[PIDTYPE_TGID],线程pid为pid
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));//设置task_struct的signal->pids[PIDTYPE_PGID]为进程组leader进程的pid
init_task_pid(p, PIDTYPE_SID, task_session(current));//设置task_struct的signal->pids[PIDTYPE_SID]为会话组leader进程的pid
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->shared_pending.signal = delayed.signal;
p->signal->tty = tty_kref_get(current->signal->tty);
/*
* Inherit has_child_subreaper flag under the same
* tasklist_lock with adding child to the process tree
* for propagate_has_child_subreaper optimization.
*/
p->signal->has_child_subreaper = p->real_parent->signal->has_child_subreaper ||
p->real_parent->signal->is_child_subreaper;
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_TGID); //将进程挂接到pid struct的PIDTYPE_TGID链表
attach_pid(p, PIDTYPE_PGID); //将进程挂接到pid struct的PIDTYPE_PGID链表
attach_pid(p, PIDTYPE_SID); //将进程挂接到pid struct的PIDTYPE_SID链表
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
refcount_inc(¤t->signal->sigcnt);
task_join_group_stop(p);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID); //将进程挂接到pid struct的PIDTYPE_PID链表
nr_threads++;
}
......
}
attach_pid的具体实现过程如下,其中pid->task数组为hash链表的头,task->pid_links中为链表节点:
void attach_pid(struct task_struct *task, enum pid_type type)
{
struct pid *pid = *task_pid_ptr(task, type);
hlist_add_head_rcu(&task->pid_links[type], &pid->tasks[type]);
}
static struct pid **task_pid_ptr(struct task_struct *task, enum pid_type type)
{
return (type == PIDTYPE_PID) ?
&task->thread_pid :
&task->signal->pids[type];
}
hash链表的示意图如下:

对应于struct pid和struct task_struct就是:

对于pid struct中的tasks[PIDTYPE_PID]和tasks[PIDTYPE_TPID]两个hash链表,理论上每个链表上只有本身的task_struct一个节点。对于tasks[PIDTYPE_PGID],如果该进程为进程组leader进程,则该链表上会挂接上所有属于该进程组的进程,而对于tasks[PIDTYPE_SID],如果该进程为会话组leader进程,则该链表将挂接上所有属于该会话组的进程。该数据结构可用于扫描所有属于同一个进程组/会话组的task_struct(即通过hlist_node地址和hlist_node在task_struct中偏移,得到指向task_struct的指针):
#define do_each_pid_task(pid, type, task) \
do { \
if ((pid) != NULL) \
hlist_for_each_entry_rcu((task), \
&(pid)->tasks[type], pid_links[type]) {
在了解了pid的管理架构之后,再回头看/proc目录下pid文件的查询过程next_tgid就会比较容易了。
进程退出
进程在退出时会调用do_exit->exit_notify,设置task->exit_state为EXIT_ZOMBIE。在父进程调用了wait系统调用时,会去回收退出进程的资源,其中就包括进程在各个pid namespace中的映射:
do_wait
do_wait_thread
wait_consider_task
wait_task_zombie
release_task
__exit_signal
__unhash_process
detach_pid
__change_pid
free_pid
void free_pid(struct pid *pid)
{
/* We can be called with write_lock_irq(&tasklist_lock) held */
int i;
unsigned long flags;
spin_lock_irqsave(&pidmap_lock, flags);
for (i = 0; i <= pid->level; i++) {
struct upid *upid = pid->numbers + i;
struct pid_namespace *ns = upid->ns;
switch (--ns->pid_allocated) {
case 2:
case 1:
/* When all that is left in the pid namespace
* is the reaper wake up the reaper. The reaper
* may be sleeping in zap_pid_ns_processes().
*/
wake_up_process(ns->child_reaper);
break;
case PIDNS_ADDING:
/* Handle a fork failure of the first process */
WARN_ON(ns->child_reaper);
ns->pid_allocated = 0;
/* fall through */
case 0:
schedule_work(&ns->proc_work);
break;
}
idr_remove(&ns->idr, upid->nr); //从idr中删除pid对应的节点
}
spin_unlock_irqrestore(&pidmap_lock, flags);
call_rcu(&pid->rcu, delayed_put_pid);
}
进程退出的实际过程待进一步分析。但是大致过程应该如此,这也是为什么当进程变成zombie进程之后,仍然能够在/proc中看到对应的pid目录,因为此时起task_struct以及struct pid等结构并没有被销毁,需要等父进程调用了wait系列函数,才能将该部分资源收回销毁。