Java - 数据结构之 顺序表与链表
目录
1. 线性表
2. 顺序表
2.1 动态扩容
2.2 带参数的构造方法、
编辑
2.3 ArrayList 一些常用的方法
3. 链表
3.1 链表的不同结构
3.2 LinkedList相对于ArrayList的优缺点详解
4. 链表OJ题详解
❓什么是回文❓
找出中间结点
反转链表
前后遍历链表
总代码
1. 线性表
✍线性表是最基本、最简单、也是最常用的一种数据结构。线性表是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。线性表就像是用一根绳子将我们的数据串起来存储到我们的内存中,并且线性表有且仅有一个开始结点和终端结点,开始结点没有前驱元素的且只有一个后驱元素,终端结点没有后驱元素且只有一个前驱元素,其他的结点有且只有一个前驱元素和后驱元素。

线性表以顺序存储的结构就叫顺序表
线性表以链式存储的结构就叫链表
在java当中 ArrayList 这个类实现了动态类型的顺序表,LinkedList 这个类实现了链表,他们都继承与 List
2. 顺序表
✍顺序表是在计算机内存中以数组的形式保存的线性表,线性表的顺序存储是指用一组地址连续的存储单元依次存储线性表中的各个元素、使得线性表中在逻辑结构上相邻的数据元素存储在相邻的物理存储单元中,即通过数据元素物理存储的相邻关系来反映数据元素之间逻辑上的相邻关系,采用顺序存储的线性表通常称为顺序表。顺序表是将表中的结点依次存放在计算机内存中一组地址连续的存储单元中。
顺序表的每个元素在存储的地址是连续的,如果有一个整型数组,那每个元素之间的地址都相差4

2.1 动态扩容
数组是一个静态的顺序表,当我们创建一个数组时,给定一个大小,那么这个数组的大小时不能更改的了,例如我们定义一个可以存放十个整型的大小

如果你已经存放了十个元素,当你想要继续存储第十一个元素的时候必须要重新创建一个大小为11的数组,将原来的数组放入到新数组内然后对新数组进行添加元素
而我们的 ArrayList 是一个动态类型的顺序表,他可以进行动态的扩容 ,当我们的顺序表内元素放满后,如果想要添加新的元素他会动态扩容至原来大小的 1.5 倍
接下来让我们来看看他的底层是如何进行扩容的
首先我们创建一个 ArrayList 对象

当一个类实例化的一个对象后,那么他肯定是要调用他的构造方法的,我们先来看看他的构造方法
先来看看不带参数的构造方法

看到这俩个参数 elementData 和 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 后一脸懵逼,这俩是啥❓❓
先来看看 elementData

是一个Object 类型的数组,我们存放的元素就在这个数组当中。
再来看看 DEFAULTCAPACITY_EMPTY_ELEMENTDATA
![]()
DEFAULTCAPACITY_EMPTY_ELEMENTDATA 也是一个数组,指向的对象 {} 内没有任何东西,此时并没有给 elementData 分配内存。
❓问题来了,如果 elementData 并没有给他初始化大小那我们怎么放元素进去呢,或者说放元素进去会发生什么❓
我们调用 add方法来添加一个元素进去看看他会发生什么
![]()
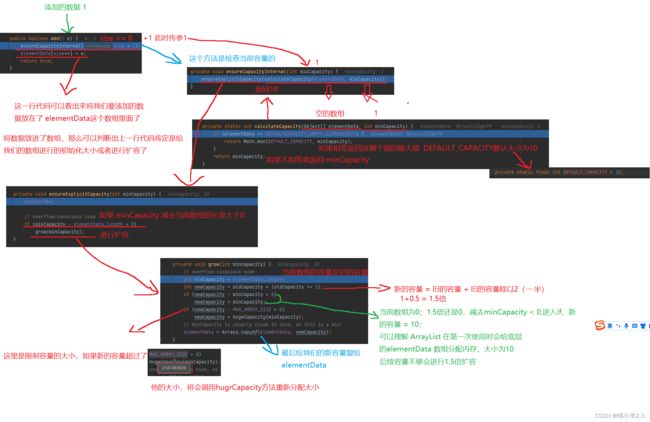
重点
① 第一次添加元素时默认分配大小为10的容量
② 如果容量不够,进行扩容时默认是1.5倍的扩容
③ 如果容量超出 MAX_ARRAY_SIZE,则会调用 hugeCapacity方法重新分配大小
2.2 带参数的构造方法、
第一个构造方法是创建新对象时可以让用户自定义初始化容量(参数 initialCapacity 为容量),如果大于0,初始化为用户指定的容量;等于0,初始化为空数组;小于0,抛出异常
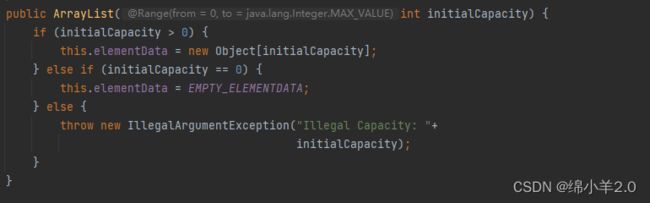
接下来看看这个构造方法,这个构造方法看上去是不是一头雾水
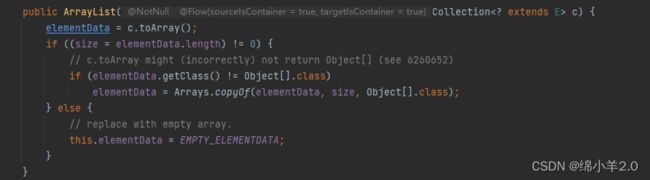
首先参数的意思是指我们的参数需要是 E 这个泛型参数或者是他的子类,并且实现了 Collection 这个接口,例如下面一串代码
LinkedList linkedList = new LinkedList<>();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
ArrayList arrayList = new ArrayList<>(linkedList);
System.out.println(arrayList); 首先我们创建了一个链表 LinkedList , LinkedList 是实现了 Collection 这个接口的,我们的泛型是 Integer 类型,传给下面的 ArrayList ,ArrayList 也是 Integer 类型的,此时参数合法,我们的 ArrayList 实例化的时候就会将 LinkedList 的成员元素添加到我们的 ArrayList 对象中
![]()
2.3 ArrayList 一些常用的方法
| 方法 | 解释 |
| boolean add(E e) | 将指定元素(e)追加到此列表的末尾 |
| void add(int index, E element) | 在此列表的指定位置(index)插入元素 |
| void clear() | 删除列表的所有元素 |
| boolean contains(Object o) | 在列表中查询是否有指定(o)的元素 |
| E get(int index) | 返回此列表指定位置(index)的元素 |
| int indexOf(Object o) | 返回此列表中第一次出现该元素(o)的位置,如果不包含此元素则返回-1 |
| int lastInedxOf(Object o) | 返回此列表中最后一次出现该元素(o)的位置,如果不包含此元素则返回-1 |
| boolean isEmpty() | 查询此列表是否为空(没有任何元素) |
| E remove(int index) | 删除此列表指定位置(index)的元素 |
| boolean remove(Object o) | 删除此列表第一次出现的指定元素,不存在返回false |
| protected void removeRange(int fromIndex, int toIndex) | 删除此列表所有索引在fromIndex (含) 和toIndex 之间的元素(左闭右开区间[ },不包含toIndex位置的元素) |
| E set(int index, E element) | 将此列表指定位置(index)元素替换成指定元素(element) |
| int size() | 返回此列表当前元素个数 |
ArrayList 重写了 toString 方法,使我们可以直接使用 println 打印 ArrayList 对象
3. 链表
✍链表相比于顺序表其实是类似的,链表也是基于线性表采用链式存储的方式实现的,顺序表的每个元素在内存地址上是相邻的,而我们的链表是由一个一个结点组成,每个结点中存了俩到三个值,使得他们每个结点是可以不相邻的,只需要他身上的钥匙门牌号就可以找到他下一个结点是谁。相比于顺序表,我们的链表在插入元素和删除元素时的时间复杂度是要比顺序表低的,并且ArrayList 的扩容会浪费一部分的空间,假如我们的容量是10000,当元素放满时,我需要再放一个元素,此时扩容1.5倍,容量为15000,那剩下的4999的空间岂不是浪费了,而我们的链表并没有固定的容量,你想添加一个他就多一个结点,想删除一个元素,那就少一个结点,相对于顺序表来说缺点是查找的速度较慢与顺序表,顺序表可以直接访问下标来查找元素。
3.1 链表的不同结构
链表每个结点最多有三个值,分别是 val(存储的数据),next(下一个结点的地址),prev(上一个结点的地址)。
链表还有很多种结构,让我们来画图看一下

足足八种结构,可能这时候你看到这么多的结构会觉得他很复杂,其实你只需要知道了这三个词到底是什么意思那八种结构也就易如反掌。

上图中俩个都是单向链表,你会发现除了开始结点外,其他结点是找不到他上一个结点是谁,双向链表除开始结点外,其他结点是可以通过 prev 存储的值找到他上一个结点是谁
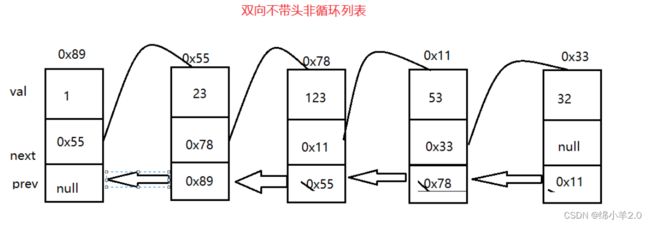
✍总结:
① 链表是不是循环可以通过终端结点的next值是否为 null 来判断,如果不是 null那么肯定就是指向了开始结点。
② 链表带不带头可以查看是不是有一个固定的结点指向我们的开始结点
③ 链表是单向还是双向可以查看除开始结点外其他结点是否都有 prev 值存储着我们上一个结点的地址。
3.2 LinkedList相对于ArrayList的优缺点详解
1. 插入元素的时间复杂度较低,插入时只需要修改next 的指向。

而顺序表需要将插入索引后的元素全部往后移动一格

2. 没有容量的概念,不会浪费空间
如上文所讲当容量的基数较大时,ArrayList 扩容多出的0.5倍会消耗很大的空间,当你不能全部利用完的时候空间就会被浪费掉,LinkedList 就没有扩容这一说,容量随着你的增加删除而变化。
3. LinkedList 访问元素时因为没有下标而不支持随机访问,顺序表可以通过下标的形式直接随机访问任意元素
✍总结:
ArrayList 更适用于频繁访问的场景
LinkedList 更适用于频繁插入和删除的场景
4. 链表OJ题详解
链表的回文结构_牛客题霸_牛客网
❓什么是回文❓
假设当前有n个元素,第1个元素和第n个元素相等,第二个元素个第n-1个元素相等......直到中间只剩一个元素时(奇数个) 或者中间没有元素(偶数个)时称为回文
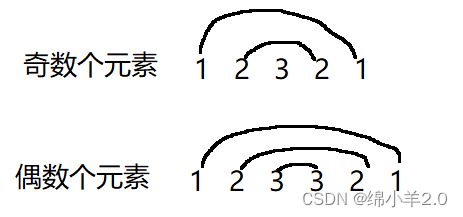
这道题的思路又是好几个小题,首先是找出中间结点,其次反转中间结点后的链表,最后使用双指针从前后遍历即可
链表的中间结点:力扣
反转链表:力扣
找出中间结点
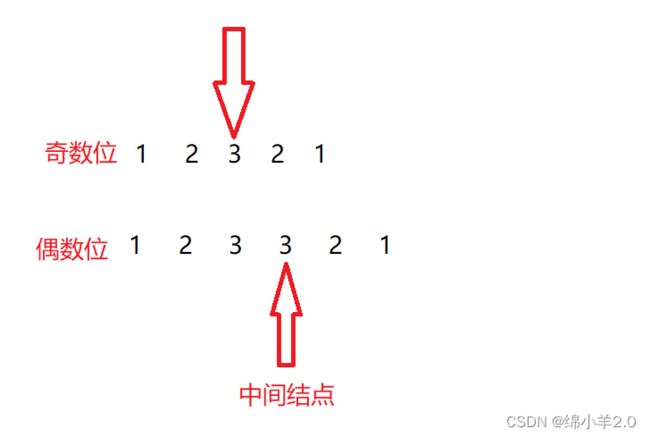
思路是快慢指针,定义俩个指针slow 和 fast,slow 走一步,fast 走俩布,当 fast 等于 null 时,为偶数个结点,当 fast.next 等于null 时,为奇数个结点
奇数个

偶数个
代码
while(fast != null && fast.next != null) { slow = slow.next; fast = fast.next.next; }
反转链表
我们只需要反转中间结点后的这一部分链表
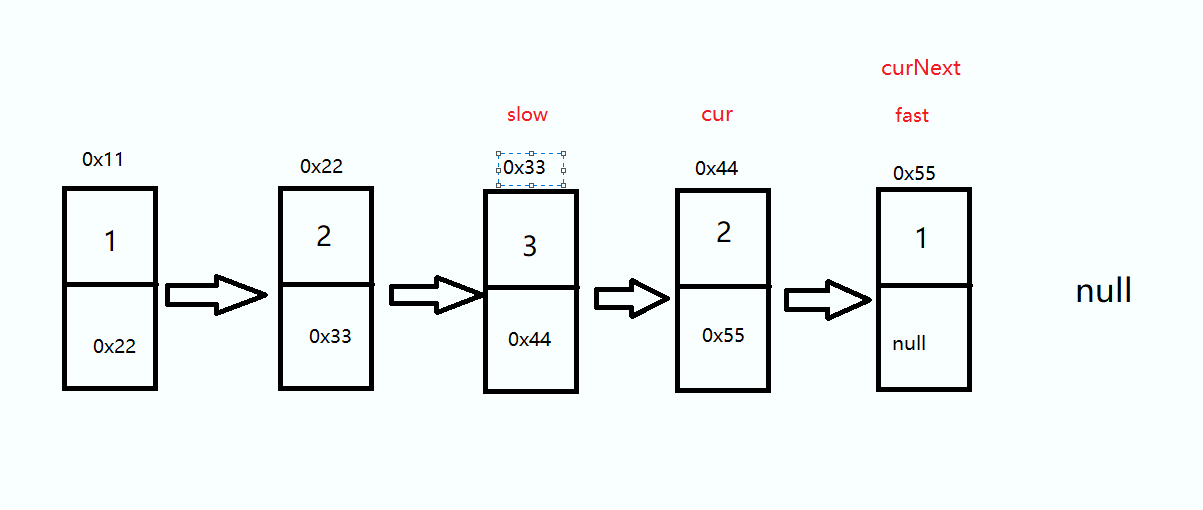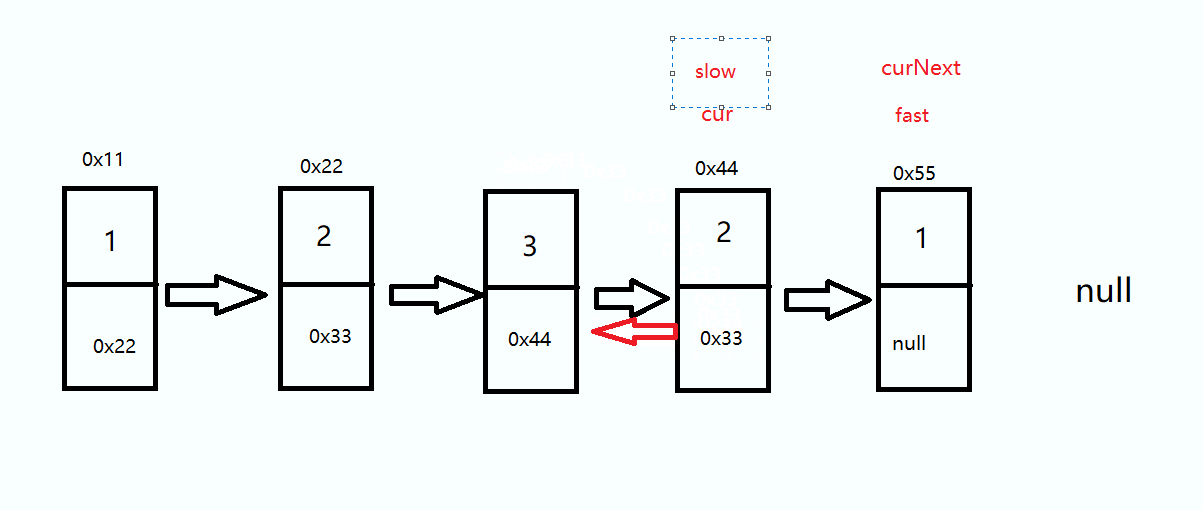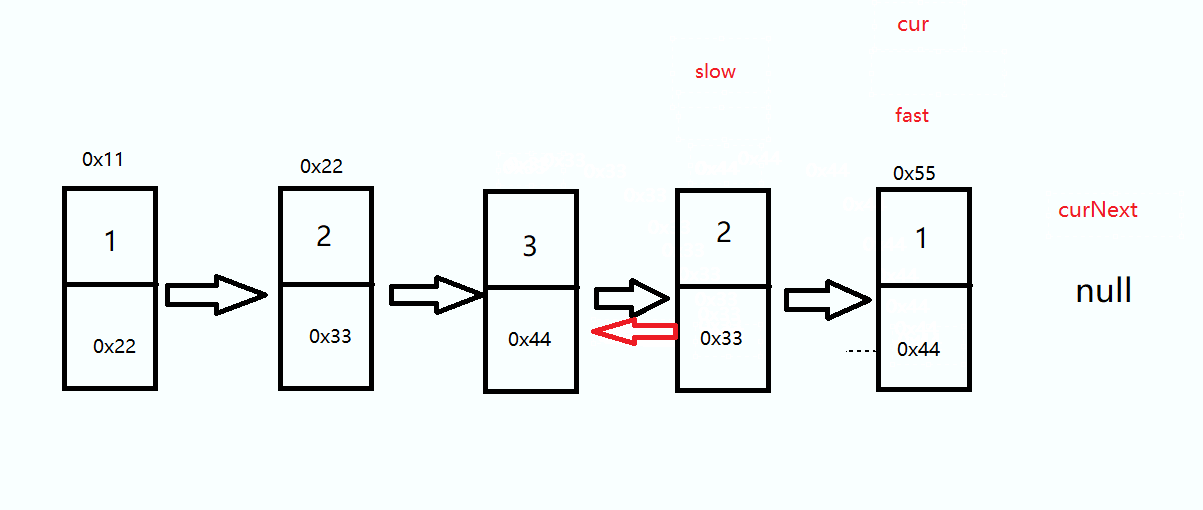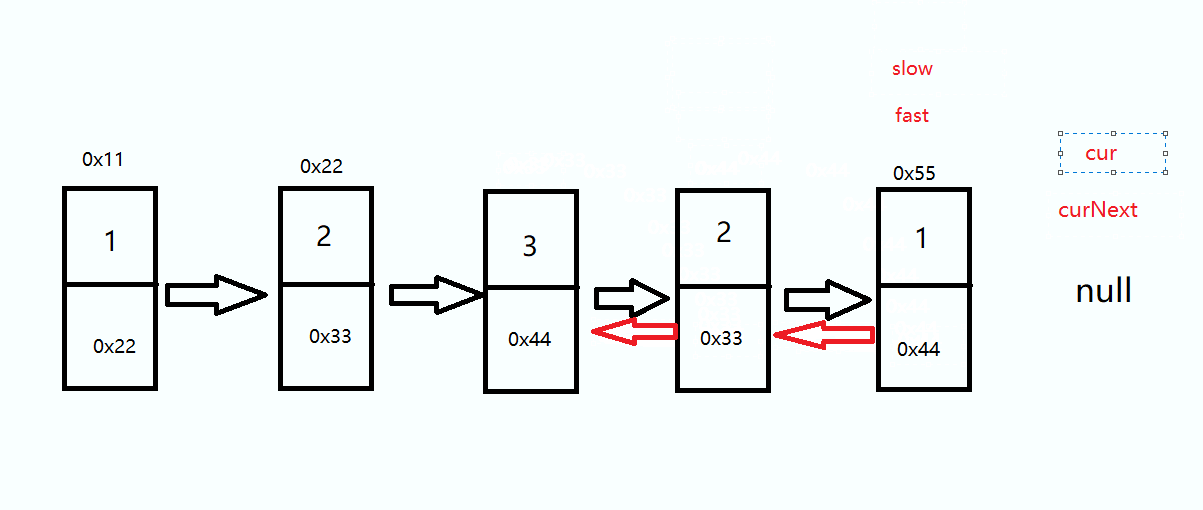
思路是定义三个指针 slow 、cur 、curNext,将 cur 的 next 指向 slow 直到 cur 为 null 时结束
这里不论奇数偶数都是一样的,走到cur 为null 时结束循环
代码
ListNode cur = slow.next; ListNode curNext = cur.next; while(cur != null) { curNext = cur.next; cur.next = slow; slow = cur; cur = curNext; }
前后遍历链表
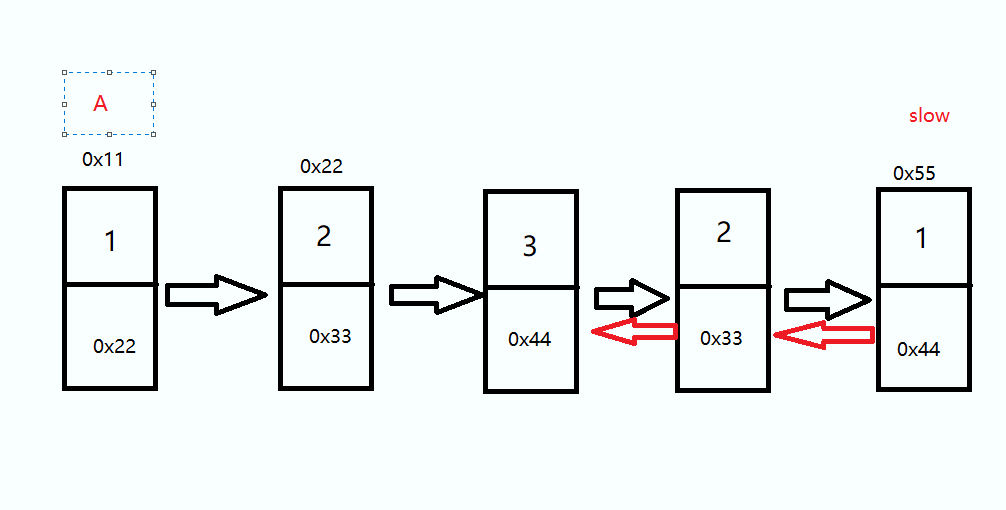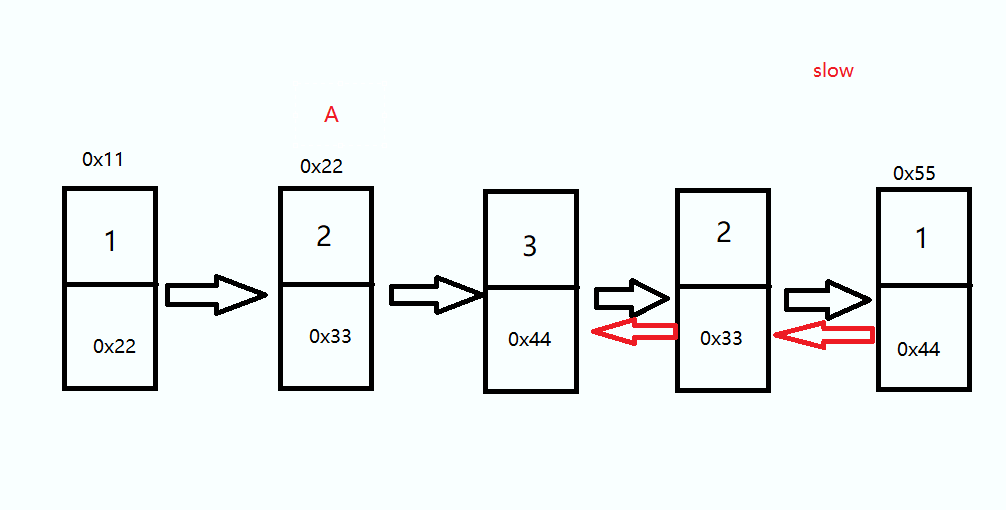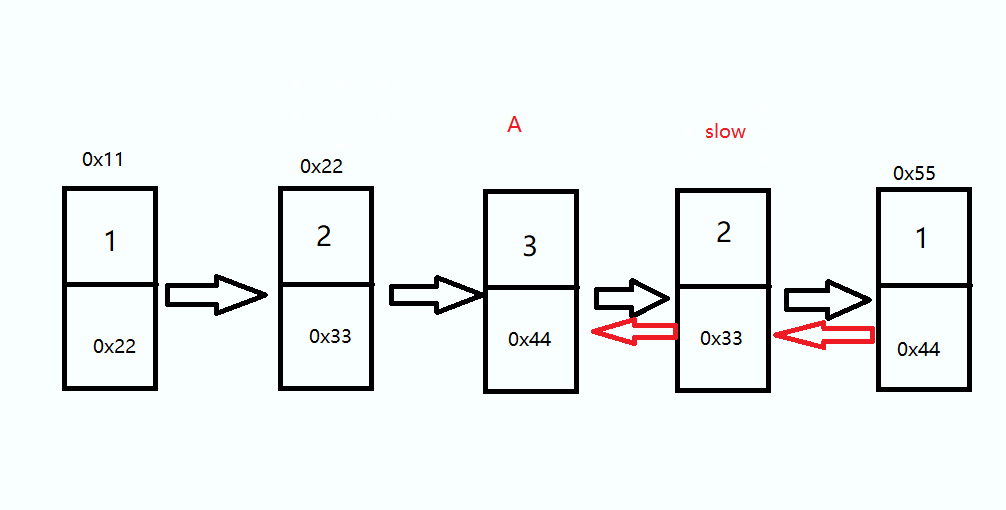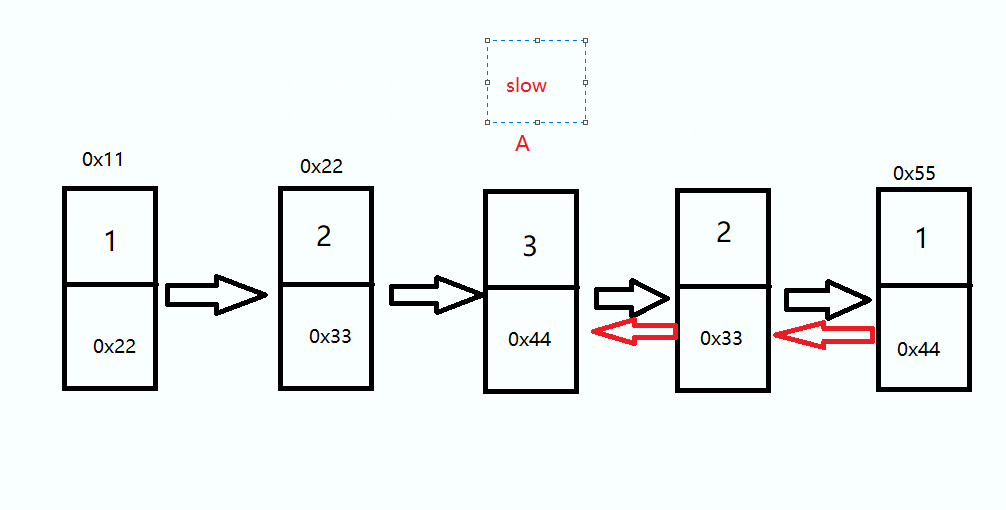
头结点 A 和 终端结点 slow 前后各走一步直到他俩相等,路途上如果 val 值不相等返回 false
如果是偶数个结点的情况下需要判断前指针 A 的 next 是否为 后指针 slow ,如果是那就返回 true

代码
while(slow != A) { if(slow.val != A.val) { return false; } if(A.next == slow) { return true; } slow = slow.next; A = A.next; } return false;
总代码
最后只需要加俩个判断
1. 当链表为 null 时,空的那肯定不是回文了,直接返回 false;
2. 当头结点的 next 为 null ,那代表着当前链表只有一个结点,一个结点的情况下也属于回文,直接返回 true;
代码
public boolean chkPalindrome(ListNode A) { if(A == null) { return false; } if(A.next == null) { return true; } ListNode slow = A; ListNode fast = A; while(fast != null && fast.next != null) { slow = slow.next; fast = fast.next.next; } ListNode cur = slow.next; ListNode curNext = cur.next; while(cur != null) { curNext = cur.next; cur.next = slow; slow = cur; cur = curNext; } while(slow != A) { if(slow.val != A.val) { return false; } if(A.next == slow) { return true; } slow = slow.next; A = A.next; } return false; }
我对于顺序表和链表的的了解就到这结束了,如有不足望指出
