python爬虫数据采集_入门数据采集,python爬虫常见的数据采集与保存、
本文介绍两种方式来实现python爬虫获取数据,并将python获取的数据保存到文件中。
一、第一种方式:
主要通过爬取百度官网页面数据,将数据保存到文件baidu.html中,程序运行完打开文件baidu.html查看效果。具体代码中有详细的代码解释,相信刚入门的你也能看懂~~
说明一下我的代码环境是python3.7,本地环境是python2.x的可能需要改部分代码,用python3.x环境的没问题。
代码如下:
# -*- coding: utf-8 -*-import urllib.request
import urllib
# 1网址url--百度
url= ‘http://www.baidu.com‘# 2创建request请求对象
request=urllib.request.Request(url)
#3发送请求获取结果
response=urllib.request.urlopen(request)
htmldata=response.read()
#4、设置编码方式
htmldata= htmldata.decode(‘utf-8‘)
#5、打印结果
print (htmldata)
#6、打印爬去网页的各类信息
print ("response的类型:",type(response))
print ("请求的url:",response.geturl())
print ("响应的信息:",response.info())
print ("状态码:",response.getcode())
#7、爬取数据保存到文件
fileOb= open(‘baidu.html‘,‘w‘,encoding=‘utf-8‘) #打开一个文件,没有就新建一个
fileOb.write(htmldata)
fileOb.close()
在open()方法中如果没有设置编码encoding=‘utf-8‘,会报错,原因如下:
在windows下面,新文件的默认编码是gbk,这样的话,python解释器会用gbk编码去解析我们的网络数据流html,
然而html此时已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。
设置encoding=‘utf-8‘,打开文件时就按照utf-8格式编码,则顺利运行。
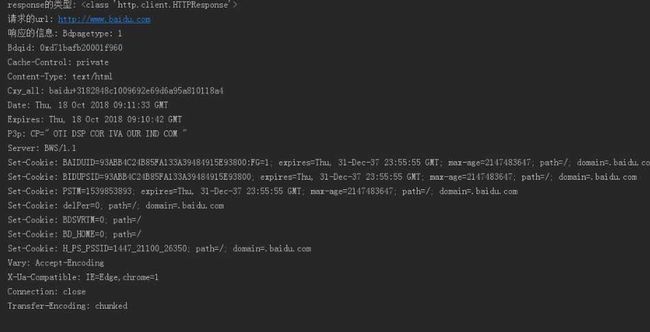
运行结果:
部分截图如下:截取的是第六步中的网页各类信息,第五步打印的数据过多,也已经保存到文件baidu.html中了,所以没有截取。
二、第二种方式:添加特殊情景的处理器
代码如下:
# -*- coding: utf-8 -*-import urllib.request, http.cookiejar
#1、网址url --百度
url= ‘http://www.baidu.com‘#2、创建cookie容器
cj=http.cookiejar.CookieJar()
handle=urllib.request.HTTPCookieProcessor(cj)
#3、创建1个opener
opener=urllib.request.build_opener(handle)
#4、给urllib.request安装opener
urllib.request.install_opener(opener)
#5、使用带有cookie的urllib.request访问网页,发送请求返回结果
response=urllib.request.urlopen(url)
htmldata=response.read()
#6、设置编码方式
data= htmldata.decode("utf-8")
#7、打印结果
print (data)
#8、打印爬去网页的各类信息
print ("response的类型:",type(response))
print ("请求的url:",response.geturl())
print ("响应的信息:",response.info())
print ("状态码:",response.getcode())
#9、爬取数据保存到文件
fileOb= open(‘baiduCookie.html‘,‘w‘,encoding=‘utf-8‘) #打开一个文件,没有就新建一个
fileOb.write(data)
fileOb.close()
原文:https://www.cnblogs.com/jiguangdongtaiip/p/13582909.html