Towards Deep Learning Models Resistant to Adversarial Attacks论文解读
1 简介
最近在计算机视觉[17,12]和自然语言处理[7]方面的突破将训练过的分类器带入center of security-critical systems。重要的例子包括自动驾驶汽车的视觉、人脸识别和恶意软件检测。这些发展使得机器学习的安全变得越来越重要。特别是,抵抗adversarially chosen inputs正成为一个关键的设计目标。虽然经过训练的模型往往能够非常有效地对benign输入进行分类,但最近的研究[2,28,22]表明,攻击者往往能够操纵输入从而使模型产生错误的输出。
这种现象在深层神经网络的背景下受到了特别的关注,现在关于这一主题的研究正在迅速增长[11,9,27,18,23,29]。视觉领域提出了一个特别突出的挑战:对输入图像进行非常小的更改,就可以以高置信度欺骗最先进的神经网络[28,21]。即使良性的例子被正确分类且变化对人眼来说是不可察觉的,这一点仍然成立。除了安全方面的影响,这种现象还表明,我们当前的模型没有学到underlying concepts in a robust manner。所有这些发现都提出了一个根本问题:
H o w c a n w e t r a i n d e e p n e u r a l n e t w o r k s t h a t a r e r o b u s t t o a d v e r s a r i a l i n p u t s ? How\ can\ we\ train\ deep\ neural\ networks\ that\ are\ robust\ to\ adversarial\ inputs\ ? How can we train deep neural networks that are robust to adversarial inputs ?
现在有大量的工作提出了各种对抗攻击和防御机制。包括defensive distillation[24,6]、feature squeezing[31,14]和其他几种对抗样本检测方法[5]。These works constitute important first steps in exploring the realm of possibilities here。They,however,do not offer a good understanding of the guarantees they provide。 We can never be certain that a given attack finds the “most adversarial” example in the context, or that a particular defense mechanism prevents the existence of some well-defined class of adversarial attacks。This makes it difficult to navigate the landscape of adversarial robustness or to fully evaluate the possible security implications.
在本文中,我们通过研究lens of robust optimization来探讨对抗鲁棒性。我们使用a natural saddle point(min-max) formulation 来 capture the notion of security against adversarial attacks in a principled manner。This formulation allows us to be precise about the type of security guarantee we would like to achieve, i.e., the broad class of attacks we want to be resistant to (in contrast to defending only against specific known attacks).The formulation also enables us to cast both attacks and defenses into a common theoretical framework, naturally encapsulating most prior work on adversarial examples. In particular, adversarial training directly corresponds to optimizing this saddle point problem. Similarly, prior methods for attacking neural networks correspond to specific algorithms for solving the underlying constrained optimization problem.
Equipped with this perspective, we make the following contributions.
为了可靠地抵御强大的对手攻击,网络需要比仅正确分类良性示例更大的容量。这表明,鞍点问题的稳健决策边界可能比简单分离良性数据点的决策边界复杂得多。
- 我们对这个saddle point formulation 的 optimization landscape进行了详细的实验研究。尽管其组成部分是non-convexity以及non-concavity的,但是我们发现其underlying优化问题是可处理的。特别地,我们提供了强有力的证据,证明first-order方法可以有效解决这个问题。We supplement these insights with ideas from real analysis to further motivate projected gradient descent (PGD) as a universal “first-order adversary”, i.e., the strongest attack utilizing the local first order information about the network.
- 我们探讨了网络结构对于adversarial robustness的影响并且发现model capacity起了重要作用。为了有效抵抗较强的对抗攻击,网络需要比仅能正确分类良性样本更大的capacity。这表明a robust decision boundary of the saddle point problem can be significantly more complicated than a decision boundary that simply separates the benign data points.
- 基于上述见解,我们在MNIST[19]和CIFAR10[16]上训练对于a wide range of adversarial attacks都具有鲁棒性的网络。我们的方法基于优化上面的saddle point formulation,并使用PGD作为可靠的first-order adversary。Our best MNIST model achieves an accuracy of more than 89% against the strongest adversaries in our test suite。特别地,我们的MNIST网络甚至对迭代白盒攻击都具有鲁棒性。我们的CIFAR10模型在对抗同一攻击者时的准确率为46%。此外,在较弱的黑盒和迁移攻击情况下,我们的MNIST和CIFAR10网络的准确率分别达到95%和64%以上(更详细的概述见表1和表2)。To the best of our knowledge, we are the first to achieve these levels of robustness on MNIST and CIFAR10 against such a broad set of attacks.
Overall, these findings suggest that secure neural networks are within reach. In order to further support this claim, we invite the community to attempt attacks against our MNIST and CIFAR10 networks in the form of a challenge. This will let us evaluate its robustness more accurately, and potentially lead to novel attack methods in the process. The complete code, along with the description of the challenge, is available at https://github.com/MadryLab/mnist_challenge and https://github.com/MadryLab/cifar10_challenge.
2 从优化视角看待对抗鲁棒性
Much of our discussion will revolve around an optimization view of adversarial robustness. This perspective not only captures the phenomena we want to study in a precise manner, but will also inform our investigations. To this end, let us consider a standard classification task with an underlying data distribution D \mathcal{D} D over pairs of examples x ∈ R d x\in\mathbb{R}^d x∈Rd and corresponding labels y ∈ [ k ] y\in[k] y∈[k]. We also assume that we are given a suitable loss function L ( θ , x , y ) L(\theta,x,y) L(θ,x,y), for instance the cross-entropy loss for a neural network. As usual, θ ∈ R p \theta\in\mathbb{R}^p θ∈Rp is the set of model parameters. Our goal then is to find model parameters θ \theta θ that minimize the risk E ( x , y ) ∼ D [ L ( x , y , θ ) ] \mathbb{E}_{(x,y)\sim\mathcal{D}}[L(x,y,\theta)] E(x,y)∼D[L(x,y,θ)]。
Empirical risk minimization (ERM) has been tremendously successful as a recipe for finding classifiers with small population risk. Unfortunately, ERM often does not yield models that are robust to adversarially crafted examples [2, 28]. Formally, there are efficient algorithms (“adversaries”) that take an example x x x belonging to class c 1 c_1 c1 as input and find examples x a d v x^{adv} xadv such that x a d v x^{adv} xadv is very close to x x x but the model incorrectly classifies x a d v x^{adv} xadv as belonging to class c 2 ≠ c 1 c_2\ne c_1 c2=c1.
In order to reliably train models that are robust to adversarial attacks, it is necessary to augment the ERM paradigm appropriately. Instead of resorting to methods that directly focus on improving the robustness to specific attacks, our approach is to first propose a concrete guarantee that an adversarially robust model should satisfy. We then adapt our training methods towards achieving this guarantee.
The first step towards such a guarantee is to specify an attack model, i.e., a precise definition of the attacks our models should be resistant to. For each data point x x x, we introduce a set of allowed perturbations S ⊆ R d \mathcal{S}\subseteq\mathbb{R}^d S⊆Rd that formalizes the manipulative power of the adversary. In image classification, we choose S \mathcal{S} S so that it captures perceptual similarity between images. For instance, the ℓ ∞ \ell_{\infty} ℓ∞-ball around x x x has recently been studied as a natural notion for adversarial perturbations [11]. While we focus on robustness against ℓ ∞ \ell_{\infty} ℓ∞-bounded attacks in this paper, we remark that more comprehensive notions of perceptual similarity are an important direction for future research.
Next, we modify the definition of population risk E D [ L ] \mathbb{E}_{\mathcal{D}}[L] ED[L] by incorporating the above adversary. Instead of feeding samples from the distribution D \mathcal{D} D directly into the loss L L L, we allow the adversary to perturb the input first. This gives rise to the following saddle point problem, which is our central object of study:
min θ ρ ( θ ) , where ρ ( θ ) = E ( x , y ) ∼ D [ max δ ∈ S L ( θ , x + δ , y ) ] ( 2.1 ) \min_{\theta}\rho(\theta),\quad \text{where}\quad\rho(\theta)=\mathbb{E}_{(x,y)\sim\mathcal{D}}[\max_{\delta\in\mathcal{S}}L(\theta,x+\delta,y)]\quad\quad\quad\quad\quad(2.1) θminρ(θ),whereρ(θ)=E(x,y)∼D[δ∈SmaxL(θ,x+δ,y)](2.1)
Formulations of this type (and their finite-sample counterparts) have a long history in robust optimization, going back to Wald [30]. It turns out that this formulation is also particularly useful in our context.
First, this formulation gives us a unifying perspective that encompasses much prior work on adversarial robustness. Our perspective stems from viewing the saddle point problem as the composition of an inner maximization problem and an outer minimization problem. Both of these problems have a natural interpretation in our context. The inner maximization problem aims to find an adversarial version of a given data point x that achieves a high loss. This is precisely the problem of attacking a given neural network. On the other hand, the goal of the outer minimization problem is to find model parameters so that the “adversarial loss” given by the inner attack problem is minimized. This is precisely the problem of training a robust classifier using adversarial training techniques.
Second, the saddle point problem specifies a clear goal that an ideal robust classifier should achieve, as well as a quantitative measure of its robustness. In particular, when the parameters θ \theta θ yield a (nearly) vanishing risk, the corresponding model is perfectly robust to attacks specified by our attack model.
Our paper investigates the structure of this saddle point problem in the context of deep neural networks. These investigations then lead us to training techniques that produce models with high resistance to a wide range of adversarial attacks. Before turning to our contributions, we briefly review prior work on adversarial examples and describe in more detail how it fits into the above formulation.
2.1 A Unified View on Attacks and Defenses
先前对于对抗样本的讨论主要集中在两个主要问题上:
- 我们如何产生较强的对抗样本,即那些能以高置信度欺骗模型并且扰动很小的对抗样本
- 我们如何训练模型使得攻击者很难根据这个模型生成对抗样本
Our perspective on the saddle point problem(2.1) gives answers to both these questions。从攻击者视角看,先前已经提出了攻击方法例如Fast Gradient Sign Method(FGSM)[11]以及它的各种变体[18]。FGSM是一种 ℓ ∞ \ell_{\infty} ℓ∞限定攻击并且通过如下方式计算对抗样本:
x + ϵ sign ( ∇ x L ( θ , x , y ) ) x+\epsilon\text{sign}(\nabla_xL(\theta,x,y)) x+ϵsign(∇xL(θ,x,y))
One can interpret this attack as a simple one-step scheme for maximizeing the inner part of the saddle point formulation。 A more powerful adversary is the multi-step variant, which is essentially projected gradient descent(PGD) on the negative loss function:
x t + 1 = ∏ x + S ( x t + α sign ( ∇ x L ( θ , x , y ) ) ) x^{t+1}=\prod_{x+\mathcal{S}}(x^t+\alpha\text{sign}(\nabla_xL(\theta,x,y))) xt+1=x+S∏(xt+αsign(∇xL(θ,x,y)))
Other methods like FGSM with random perturbation has also been proposed [29]。Clearly,all of these approaches can be viewed as specific attempts to solve the inner maximization problem in(2.1)
对于防御端,训练数据集通常加入由FGSM生成的对抗样本。这种方式直接follows from (2.1) when linearizing the inner maximization problem. To solve the simpilified robust optimization problem, we replace every training example with
3 Towards Universally Robust Networks
Current work on adversarial examples usually focuses on specific defensive mechanisms, or on attacks against such defenses. An important feature of formulation (2.1) is that attaining small adversarial loss gives a guarantee that no allowed attack will fool the network. By definition, no adversarial perturbations are possible because the loss is small for all perturbations allowed by our attack model. Hence, we now focus our attention on obtaining a good solution to (2.1).
不幸的是,while the overall guarantee provided by the saddle point problem is evidently useful,但我们不清楚是否能够在合理的时间内找到一个好的解决方案。解决鞍点问题(2.1)需要同时解决a non-convex outer minimization problem and a non-concave inner maximization problem。我们的主要贡献之一是证明,在实践中,我们终究可以解决鞍点问题。特别地,we now discuss an experimental exploration of the structure given by the non-concave inner problem。We argue that the loss landscape corresponding to this problem has a surprisingly tractable structure of local maxima. This structure also points towards projected gradient descent as the “ultimate” first-order adversary. Sections 4 and 5 then show that the resulting trained networks are indeed robust against a wide range of attacks, provided the networks are sufficiently large.
4 Network Capacity and Adversarial Robustness
成功解决解决等式2.1并不足够保证鲁棒并且准确分类。We need also argue that the value of the problem(i.e. the final los we achieve against adversarial examples) is small, thus providing guarantess for the performance of our classifier.In particular, achieving a very small value corresponds to a perfect classifier, which is robust to adversarial inputs.
For a fixed set S \mathcal{S} S of possible perturbations, the value of the problem is entirely dependent on the architecture of the classifier we are learning. Consequently, the architectural capacity of the model becomes a major factor affecting its overall performance. At a high level, classifiying examples in a robust way requires a stronger classifier, since the presence of adversarial examples changes the decision boundary of the problem to a more complicated one(图三给出了这种阐述):
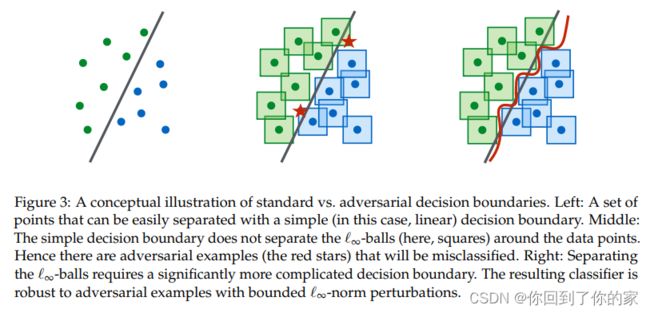
我们的实验证明了capacity is crucial for robustness,as well as for the ability to successfully train against strong adversaries。For the MNIST dataset,we consider a simple convolutional network and study how its behavior changes against different adversaries as we keep doubling the size of network (i.e. double the number of convolutional filters and the size of the fully connected layer). The initial network has a convolutional layer with 2 filters, followed by another convolutional layer with 4 filters, and a fully connected hidden layer with 64 units. Convolutional layers are followed by 2 × 2 2\times2 2×2 max-pooling layers and adversarial examples are constructed with ϵ = 0.3 \epsilon=0.3 ϵ=0.3. The results are in Figure 4.
For the CIFAR10 dataset, we used a ResNet model [13]. We performed data augmentation using random crops and flips, as well as per image standarization. To increase the capacity, we modified the network incorporating wider layers by a factor of 10. This results in a network with 5 residual units with (16, 160, 320, 640) filters each. This network can achieve an accuracy of 95.2% when trained with natural examples. Adversarial examples were constructed with ϵ = 8 \epsilon=8 ϵ=8. Results on capacity experiments appear in Figure 4.
我们观察到了如下现象:
- Capacity alone helps: 我们观察到了在训练中仅使用自然样本,如果增加网络capacity(apart from increasing accuracy on these examples),那么能够增加对于单步扰动的鲁棒性。This effect is greater when considering adversarial examples with small ϵ \epsilon ϵ。
- FGSM adversaries don’t increase robustness (for large ϵ \epsilon ϵ): 当在训练网络的过程中加入FGSM生成的对抗样本时,我们观察到网络过拟合于这些对抗样本。这种现象称为label leaking [18] and stems from the fact that the adversary produces a very restricted set of adversarial examples that the network can overfit to. These networks have poor performance on natural examples and don’t exhibit any kind of robustness against PGD adversaries. For the case of smaller ϵ \epsilon ϵ the loss is ofter linear enough in the ℓ ∞ \ell_{\infty} ℓ∞-ball around natural examples, that FGSM finds adversarial examples close to those found by PGD thus being a reasonable adversary to train against.
- Weak models may fail to learn non-trivial classifiers. In the case of small capacity networks, attempting to train against a strong adversary (PGD) prevents the network from learning anything meaningful. The network converges to always predicting a fixed class, even though it could converge to an accurate classifier through standard training. The small capacity of the network forces the training procedure to sacrifice performance on natural examples in order to provide any kind of robustness against adversarial inputs.
- The values of the saddle point problem decreases as we increase the capacity: Fixing an adversary model, and training against it, the value of (2.1) drops as capacity increases, indicating the the model can fit the adversarial examples increasingly well.
- More capacity and stronger adversaries decrease transferability: Either increasing the capacity of the network, or using a stronger method for the inner optimization problem reduces the effectiveness of transferred adversarial inputs. We validate this experimentally by observing that the correlation between gradients from the source and the transfer network, becomes less significant as capacity increases. We describe our experiments in Section B of the appendix.
5 实验:Adversarially Robust Deep Learning Models
Following the understanding of the problem we developed in previous sections, we can now apply our proposed approach to train robust classifiers. As our experiments so far demonstrated, we need to focus on two key elements:
- train a sufficiently high capacity network
- use the strongest possible adversary.
对于MNIST以及CIFAR10来说,the adversary of choice will be projected gradient descent (PGD) starting from a random perturbation around the natural example. This corresponds to our notion of a “complete” first-order adversary, an algorithm that can efficiently maximize the loss of an example using only first order information. Since we are training the model for multiple epochs, there is no benefit from restarting PGD multiple times per batch—a new start will be chosen the next time each example is encountered.