概率论基础2
文章目录
- 多个random variable
-
- 条件下的multi random variable 分布和independence
- multi random variable continuous
- **2D normal distribution**
- two random variable independence
- muilti random variable conditional expectional value(discrete)
- multi random variable conditional expectional value(continued)
- moment
- covariance and Correlation
- conditional PDF
- variance
- Joint Distribution of Discrete and Continuous Random Variables
- CF(characteristic function)
- sum of random variables
-
- change of variable:two to one
- Law of Large Number(LLN)
- Central Limit Theorem(CLT)
- statistics
多个random variable
多个random variable是什么情况呢?假设我有2个random variable X和Y,假设Xa对应的是样本空间的1,Ya对应的是样本空间的-2,这个时候我们还有一个函数是g(X,Y)他代表2个变量X和Y的关系,比如g=xy,那么样本a对应的值为g=XY=1*-2=-2
可以看成2个抽象的event相交,2个抽象的event可以实例化成具体的event,X代表其中一个抽象的event中所有的具体的event,Y代表第二个抽象event中所有具体的event值,比如2个抽象的event同时具体化成eventi和eventj,分别由X和Y代表,f(Xi,Yi)就是这eventi和eventj相交的值
XY也可以是2个event,不过X和Y是分别统计这个event出现的频率,比如抛三次硬币,X是抛三次硬币H在上面的总数,最后X={3,2,2,2,1,1,1,0},Y是H在抛三次硬币的哪一个位子出现,Y={1,1,1,2,1,2,3,0}

相当于将样本空间的样本通过g(X,Y)映射到另一个值可以看为Z
例子假设我们抛2次色子,一共有36个结果(样本空间),此时我们X,Y可以看成样本空间中的样本经过运算后的数字(一个抽象event),比如X要求sum of two dice(假如2次抛出色子相加的值为2那么就是一个具体化的event,也是我们正真意义上的event可以记为X1),Y要求difference of two dice(假如2次抛出色子相减的值为2那么也是一个真正意义上的event,可以记为Y1),那么X和Y又各自组成了一集合(每个集合都是一个event组成),假设X=5,Y=3,这个时候X和Y是交集,此时样本空间中只有{4,1}和{1,4}满足,
多random variable下的期望值
首先单random variable的期望值为
- 离散
∑ g ( x i ) f ( x i ) \sum g(x_i)f(x_i) ∑g(xi)f(xi) - 连续
∫ g ( x ) f ( x ) d x \int g(x)f(x)dx ∫g(x)f(x)dx
其中g为样本的值,f为PMF
那么random variable变成二维的公式如下X范围{x1,x2,…,xn},Y的range为{y1,y2…ym}
∑ i = 1 n ∑ j = 1 m g ( x i , y i ) f ( x i , y j ) \sum_{i=1}^n\sum_{j=1}^mg(x_i,y_i)f(x_i,y_j) i=1∑nj=1∑mg(xi,yi)f(xi,yj)
其中X范围{x1,x2,…,xn},Y的range为{y1,y2…ym},且f代表Xi,Yi joint的PMF
比如我们的X的范围为1,2,Y的范围也是1,2,他们的PMF值如下
x=1 x=2 y = 1 0.4 0.1 y=2 0.1 0.4 且Z=XY,那么E(Z)的期望值为
∑ i = 1 n ∑ j = 1 m x i y i f ( x i , y j ) = 1 ∗ 1 ∗ 0.4 + 1 ∗ 2 ∗ 0.1 + 2 ∗ 1 ∗ 0.1 + 2 ∗ 2 ∗ 0.4 = 1.4 \sum_{i=1}^n\sum_{j=1}^mx_iy_if(x_i,y_j)=1*1*0.4+1*2*0.1+2*1*0.1+2*2*0.4=1.4 ∑i=1n∑j=1mxiyif(xi,yj)=1∗1∗0.4+1∗2∗0.1+2∗1∗0.1+2∗2∗0.4=1.4
例子2
还是抛色子的例子
我们抛2次色子,一共有36个结果(样本空间),此时我们X可以看成样本空间中的样本经过运算后的数字,Y也一样,比如X要求sum of two dice,Y要求difference of two dice,那么X和Y又各自组成了一集合,X={2,3,4,5,6,7,8,9,10,11,12},Y={0,1,2,3,4,5}
假设我们的变量是连续的期望值如下
E ( Z ) = ∫ − ∞ ∞ ∫ − ∞ ∞ g ( x , y ) f ( x , y ) d x d y E(Z)=\int_{-∞}^∞\int_{-∞}^∞g(x,y)f(x,y)dxdy E(Z)=∫−∞∞∫−∞∞g(x,y)f(x,y)dxdy
例子:假如我们的joint PMF f(x,y)=4xy,且样本X的范围为[0,1],Y的范围也是[0,1],Z=XY,那么
E ( Z ) = ∫ 0 1 ∫ 0 1 x y ∗ 4 x y d x d y = 4 9 E(Z)=\int_0^1\int_0^1xy*4xydxdy=\frac{4}{9} E(Z)=∫01∫01xy∗4xydxdy=94
我们要知道对于任意的(x,y), f(x,y) >=0 ,那么
∑ ( x , y ) ∈ R 2 f ( x , y ) = P ( ( X , Y ) ∈ R 2 ) = 1 \sum_{(x,y)∈R^2}f(x,y)=P((X,Y)∈R^2)=1 ∑(x,y)∈R2f(x,y)=P((X,Y)∈R2)=1
证明还是扔色子的例子,我们抛2次色子,一共有36个结果(样本空间),此时我们X可以看成样本空间中的样本经过运算后的数字,Y也一样,比如X要求sum of two dice,Y要求difference of two dice,那么X和Y又各自组成了一集合,X={2,3,4,5,6,7,8,9,10,11,12},Y={0,1,2,3,4,5},那么组成的新的集合和概率如下

这些概率相加正好等于1
我们一个event形成集合,这个集合中random variable为Y,假设这个event是连续抛2次,2次相减为0的概率,因为总共的样本空间为36,那么相减为0代表2次抛的一样,这只会出现6次,所以这个event的概率为6/36为1/6,恰好我们的2个event相交,Y不变,变X所相加的概率也是1/6,所以可以得出
f X ( x ) = P ( X = x ) = ∑ y ∈ R f X , Y ( x , y ) fX(x)=P(X=x)=\sum_{y∈R}fX,Y(x,y) fX(x)=P(X=x)=∑y∈RfX,Y(x,y)
条件下的multi random variable 分布和independence
先回顾law of total probabilities
我们由多个event{B1,B2,…,Bk},每一个event都代表一些样本空间的集合,这些event不相交,且正好将样本空间划分,假设还有一个evnetA,求A的概率为多少
P ( A ) = ∑ i = 1 k P ( A ∣ B i ) P ( B i ) P(A)=\sum_{i=1}^kP(A|B_i)P(B_i) P(A)=∑i=1kP(A∣Bi)P(Bi)
推论
∑ i = 1 k P ( A ∣ B i ) P ( B i ) = P ( A ∩ B 1 ) + P ( A ∩ B 2 ) + . . . + P ( A ∩ B n ) \sum_{i=1}^kP(A|B_i)P(B_i)=P(A∩B_1)+P(A∩B_2)+...+P(A∩B_n) ∑i=1kP(A∣Bi)P(Bi)=P(A∩B1)+P(A∩B2)+...+P(A∩Bn)
在multi random variable下的conditional PMF
假设X和Y都是一个event组
PX(X)和PY(Y)都是marginal PMFS
PXY(x,y)是joint PMF
那么
P ( Y = y j ∣ X = x k ) = P ( X = x k ∩ Y = y j ) P ( X = x k ) = P X Y ( x k , y j ) P X ( x k ) P(Y=y_j|X=x_k)=\frac{P(X=x_k ∩ Y=y_j)}{P(X=x_k)}=\frac{P_{XY}(x_k,y_j)}{PX(x_k)} P(Y=yj∣X=xk)=P(X=xk)P(X=xk∩Y=yj)=PX(xk)PXY(xk,yj)
上面的式子应该没啥问题,就是将假设X和Y这2个event组具体成event,其他的都一样
上述的式子还可以记为
P Y ∣ X ( y j ∣ x k ) = P X Y ( x k , y j ) P X ( x k ) P_{Y|X}(y_j|x_k)=\frac{P_{XY}(x_k,y_j)}{P_X(x_k)} PY∣X(yj∣xk)=PX(xk)PXY(xk,yj)
假设我们抛三次硬币,X是一个event,Y是一个event(不再是event组),假设X代表所有的H数量,Y代表H在第几个位子出现,得到X={3,2,2,2,1,1,1,0},Y={1,1,1,2,1,2,3,0},如下图
进一步算出他们的概率,我们把所有Y的可能标在X轴,所有X的可能标在Y轴,也就是joint PMF
multi random variable continuous
和连续相似,multi random variable就是一个样本空间的样本可以被同时映射到坐标轴中(x代表一个random variable,y代表一个random variable)

我们直到PDF是测量连续random variable概率变化的函数,我们用f(x)表示这个函数,f(x1)表示样本x1的概率,样本a到b之间的概率为 ∫ a b f ( x ) d x \int_a^bf(x)dx ∫abf(x)dx,对应的CDF也是 ∫ a b f ( x ) d x \int_a^bf(x)dx ∫abf(x)dx,因为CDF表示PDF函数值的变化,假如求出x1这个点的CDF,可以得到CDF F(x)= ∫ − ∞ x 1 f ( x ) d x \int_{-∞}^{x1} f(x)dx ∫−∞x1f(x)dx
上述是一维AKA就映射到1个random variable,假如映射到2个random variable呢?就变成一个二维
简单回顾后我们回到映射,当样本空间的样本映射到一个x轴y轴后(x轴一个random variable,y轴一个random variable),所以CDF是PDF的二阶导数为 F X Y ( x , y ) = ∫ − ∞ x ∫ − ∞ y f X Y ( u , v ) d v d u F_{XY}(x,y)=\int_{-∞}^x\int_{-∞}^yf_{XY}(u,v)dvdu FXY(x,y)=∫−∞x∫−∞yfXY(u,v)dvdu
此时CDF F X Y ( x , y ) = P ( X < = x , Y < = y ) F_{XY}(x,y)=P(X <=x,Y<=y) FXY(x,y)=P(X<=x,Y<=y)如下图

且
F X Y ( ∞ , ∞ ) = 1 F_{XY}(∞,∞)=1 FXY(∞,∞)=1,因为把所有的可能包含进去了概率就是1
因为我们知道在连续的样本空间里面,样本空间的值被映射到一个random variabe中,这个random variable也是连续的,所以在x轴和y轴上也是连续的(样本空间的值被映射到2个random variable上)
所以!假设样本空间映射后的2个random variable都在0到1之间,那么CDF
-
F X Y ( x , y ) = 1 F_{XY}(x,y)=1 FXY(x,y)=1 when x>1 and y>1
当x>=1或者y>=1,换句话说映射后的值都在2个random variable在范围之外,因为有效的值都在0<=x<=1,0<=y<=1之间,所以代表所有的可能,又CDF是PDF的导数换句话说就是求面积正好映射到的是一个矩形(X是一个randon variable Y是一个random variable,且X和Y的joint),所以就是1*1=1
-
F X Y ( x , y ) = x y F_{XY}(x,y)=xy FXY(x,y)=xy when x∈[0,1] and y∈[0,1]
同上当x∈[0,1]且y∈[0,1]之间CDF就是PDF的导数(求面积),那就是xy
-
F X Y ( x , y ) = y F_{XY}(x,y)=y FXY(x,y)=y when x>1 and y∈[0,1]
因为样本映射后到x大于1的地方,因为超出范围,超出范围就当1算,所以1*y=y
-
F X Y ( x , y ) = x F_{XY}(x,y)=x FXY(x,y)=x when x∈[0,1] and y>1
因为样本映射后到y大于1的地方,因为超出范围,超出范围就当1算,所以1*x=x
-
F X Y ( x , y ) = 0 F_{XY}(x,y)=0 FXY(x,y)=0 when x<0 or y<0
因为样本映射后到x或者y小于0的地方当0算,CDF求面积就是0 * x or 0 * y
因为我们已经知道了在2个random variable的情况下CDF和PDF的关系,所以PDF就是CDF的2阶导数,得到在uniform distribution(X∈[0,1],Y∈[0,1])下
P D F = 1 / 1 PDF=1/1 PDF=1/1 when x∈[0,1],y∈[0,1]
P D F = 0 PDF=0 PDF=0 other
从图像上看uniform distribution就是这样

marginal CDF
和离散一样就是对 对应的random variable x或者random variable y累加
比如我们的 F X ( x ) = F X Y ( x , ∞ ) = P ( X < = x , y = a n y ) F_X(x)=F_{XY}(x,∞)=P(X<=x,y=any) FX(x)=FXY(x,∞)=P(X<=x,y=any)
marginal PDF
就是对一个维度进行累加,但是怎么累加?积分…如下multi random variable PDF x(变y)
f X ( x ) = ∫ − ∞ ∞ f X Y ( x , y ) d y f_X(x)=\int_{-∞}^∞f_{XY}(x,y)dy fX(x)=∫−∞∞fXY(x,y)dy
2D normal distribution
我们还记得1d的时候正态分布的PDF公式是 f ( x ) = 1 2 Π σ e − 1 2 σ 2 ( x − μ ) 2 f(x)=\frac{1}{\sqrt{2Π}σ}e^{-\frac{1}{2σ^2}(x-μ)^2} f(x)=2Πσ1e−2σ21(x−μ)2,有一些复杂,当我们将其扩展到二维,也就是2个random variable的时候是什么情况
在2维的情况我们有
σ x σ_x σx stand dev in x
σ y σ_y σy stand dev in y
μ x μ_x μx mean in x
μ y μ_y μy mean in y
ρ ρ ρ 定义了相关性[-1,1]之间,假如X在增加Y的均值也在增加这个就是正相关,反之[-1,0]就是负相关,如下图
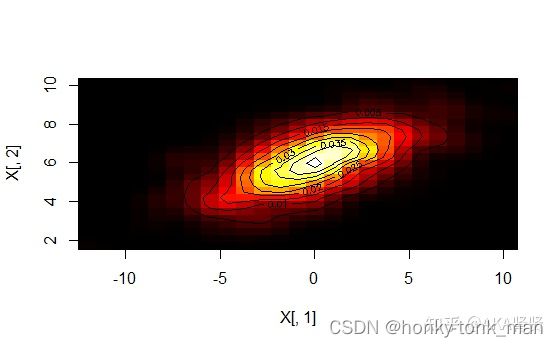
上图正相关,下图负相关

先记一下2d normal distribution可视化网站ucla写的
http://www.distributome.org/V3/calc/2D_BivariateNormalCalculator.html
question
假设我们有2个normal random vairaible X1 and X2, Z= 2X1 * X2,其Z也是normal distribute的,那么这个是否正确?
two random variable independence
前面我们讲了2个event independ的情况如下
P ( A , B ) = P ( A ) P ( B ) P(A , B)=P(A)P(B) P(A,B)=P(A)P(B)
P ( B ∣ A ) = P ( B ) P(B|A)=P(B) P(B∣A)=P(B)
它可以直接推广到multi random variable上,如下
if P(X∈A and Y∈ B )=P(X∈A)P(Y∈B)
A和B是任何event,则说明X和Y2个random variable independence
假如我们的PDF是这样的
f X Y ( x , y ) = 2 e − ( x + y ) f_{XY}(x,y)=2e^{-(x+y)} fXY(x,y)=2e−(x+y) when 0 < = y < = x < ∞ 0<=y<=x<∞ 0<=y<=x<∞
f X Y ( x , y ) = 0 f_{XY}(x,y)=0 fXY(x,y)=0 otherwise
x和y是绝对相关,因为x一定要比y大,假设x比y小,那么落到一个没有概率的地方(0),
因为 P ( A , B ) = P ( A ) P ( B ) P(A , B)=P(A)P(B) P(A,B)=P(A)P(B)所以换成PDF为 f X Y ( x . y ) = f X ( x ) f Y ( y ) f_{XY}(x.y)=f_X(x)f_Y(y) fXY(x.y)=fX(x)fY(y)
有了上述式子,假设我们X和Y是2个random variable且independence,所以
E ( X Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X Y ( x , y ) d x d y E(XY)=\int_{-∞}^∞\int_{-∞}^∞xyf_{XY}(x,y)dxdy E(XY)=∫−∞∞∫−∞∞xyfXY(x,y)dxdy因为上述的公式得到
E ( X Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X Y ( x , y ) d x d y = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X ( x ) f Y ( y ) d x d y E(XY)=\int_{-∞}^∞\int_{-∞}^∞xyf_{XY}(x,y)dxdy=\int_{-∞}^∞\int_{-∞}^∞xyf_X(x)f_Y(y)dxdy E(XY)=∫−∞∞∫−∞∞xyfXY(x,y)dxdy=∫−∞∞∫−∞∞xyfX(x)fY(y)dxdy然后对于这个式子我们可以变成2个一重积分相乘得到 ( ∫ − ∞ ∞ x f ( X ( x ) d x ) ) ( ∫ − ∞ ∞ y f Y ( y ) d y ) = E ( X ) E ( Y ) (\int_{-∞}^∞xf(_X(x)dx))(\int_{-∞}^∞yf_Y(y)dy)=E(X)E(Y) (∫−∞∞xf(X(x)dx))(∫−∞∞yfY(y)dy)=E(X)E(Y)
所以最终得到假如X和Y是2个independence的random variable则 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
我们知道Covariance的公式为
C o v ( X , Y ) = E ( ( X − u X ) ( Y − u Y ) ) = E ( X Y − X u Y − Y u X + u X u Y ) = E ( X Y ) − u X E ( Y ) − u Y E ( X ) + u X u Y = E ( X Y ) − u X u Y = E ( X Y ) − E ( X ) E ( Y ) − E ( Y ) E ( X ) + E ( X ) E ( Y ) = E ( X Y ) − E ( X ) E ( Y ) Cov(X,Y)=E((X-u_X)(Y-u_Y))=E(XY-Xu_Y-Yu_X+u_Xu_Y)=E(XY)-u_XE(Y)-u_YE(X)+u_Xu_Y=E(XY)-u_Xu_Y=E(XY)-E(X)E(Y)-E(Y)E(X)+E(X)E(Y)=E(XY)-E(X)E(Y) Cov(X,Y)=E((X−uX)(Y−uY))=E(XY−XuY−YuX+uXuY)=E(XY)−uXE(Y)−uYE(X)+uXuY=E(XY)−uXuY=E(XY)−E(X)E(Y)−E(Y)E(X)+E(X)E(Y)=E(XY)−E(X)E(Y),因为在random variable下期望值等于我们的mean
最后推广到independence得到
因为 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
所以 C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) = 0 Cov(X,Y)=E(XY)-E(X)E(Y)=0 Cov(X,Y)=E(XY)−E(X)E(Y)=0换句话说假如X和Y independence那么他们uncorrelated
muilti random variable conditional expectional value(discrete)
这个机械学习方向会经常用
PDF用于continue random variable (PDF用f()表示)
PMF用于离散的random variable (PMF用p()表示)
他们都是为了显示样本和概率之间的关系
CDF不管你离散还是连续都有CDF (CDF用F()表示)

假设我们抛三次硬币,X是一个event,Y是一个event(不再是event组),假设X代表所有的H数量,Y代表H在第几个位子出现,得到X={3,2,2,2,1,1,1,0},Y={1,1,1,2,1,2,3,0},如下图

进一步算出他们的概率,我们把所有Y的可能标在X轴,所有X的可能标在Y轴,也就是joint PMF

假设一个情况,我们抛三次硬币,发现只有一个H(此时X=1),求这个H出现在第三次抛硬币中(Y=3)的概率是多少,这个是明显的条件概率,公式如下
f Y ∣ X ( 3 ∣ 1 ) = P ( Y = 3 ∩ X = 1 ) P ( X = 1 ) = 1 8 3 8 = 1 3 f_{Y|X}(3|1)=\frac{P(Y=3∩X=1)}{P(X=1)}=\frac{\frac{1}{8}}{\frac{3}{8}}=\frac{1}{3} fY∣X(3∣1)=P(X=1)P(Y=3∩X=1)=8381=31
假设我们想求X=1的情况下Y的期望值呢?
我们要先把 f Y ∣ X ( 0 ∣ 1 ) f_{Y|X}(0|1) fY∣X(0∣1), f Y ∣ X ( 1 ∣ 1 ) f_{Y|X}(1|1) fY∣X(1∣1), f Y ∣ X ( 2 ∣ 1 ) f_{Y|X}(2|1) fY∣X(2∣1), f Y ∣ X ( 3 ∣ 1 ) f_{Y|X}(3|1) fY∣X(3∣1)的条件概率求出来,然分别乘以0,1,2,3,如下
f Y ∣ X ( 0 ∣ 1 ) = P ( Y = 0 ∩ X = 1 ) P ( X = 1 ) = 0 3 8 = 0 f_{Y|X}(0|1)=\frac{P(Y=0∩X=1)}{P(X=1)}=\frac{0}{\frac{3}{8}}=0 fY∣X(0∣1)=P(X=1)P(Y=0∩X=1)=830=0
f Y ∣ X ( 1 ∣ 1 ) = P ( Y = 1 ∩ X = 1 ) P ( X = 1 ) = 1 8 3 8 = 1 3 f_{Y|X}(1|1)=\frac{P(Y=1∩X=1)}{P(X=1)}=\frac{\frac{1}{8}}{\frac{3}{8}}=\frac{1}{3} fY∣X(1∣1)=P(X=1)P(Y=1∩X=1)=8381=31
f Y ∣ X ( 2 ∣ 1 ) = P ( Y = 2 ∩ X = 1 ) P ( X = 1 ) = 1 8 3 8 = 1 3 f_{Y|X}(2|1)=\frac{P(Y=2∩X=1)}{P(X=1)}=\frac{\frac{1}{8}}{\frac{3}{8}}=\frac{1}{3} fY∣X(2∣1)=P(X=1)P(Y=2∩X=1)=8381=31
f Y ∣ X ( 3 ∣ 1 ) = P ( Y = 3 ∩ X = 1 ) P ( X = 1 ) = 1 8 3 8 = 1 3 f_{Y|X}(3|1)=\frac{P(Y=3∩X=1)}{P(X=1)}=\frac{\frac{1}{8}}{\frac{3}{8}}=\frac{1}{3} fY∣X(3∣1)=P(X=1)P(Y=3∩X=1)=8381=31
E ( Y ∣ X = 1 ) = 0 ∗ f Y ∣ X ( 0 ∣ 1 ) + 1 ∗ f Y ∣ X ( 1 ∣ 1 ) + 2 ∗ f Y ∣ X ( 2 ∣ 1 ) + 3 ∗ f Y ∣ X ( 3 ∣ 1 ) = 0 ∗ 0 + 1 ∗ 1 3 + 2 ∗ 1 3 + 3 ∗ 1 3 = 2 E(Y|X=1)=0*f_{Y|X}(0|1)+1*f_{Y|X}(1|1)+2*f_{Y|X}(2|1)+3*f_{Y|X}(3|1)=0*0+1*\frac{1}{3}+2*\frac{1}{3}+3*\frac{1}{3}=2 E(Y∣X=1)=0∗fY∣X(0∣1)+1∗fY∣X(1∣1)+2∗fY∣X(2∣1)+3∗fY∣X(3∣1)=0∗0+1∗31+2∗31+3∗31=2
所以muilti random variable conditional expectation的公式为
E ( Y ∣ X = x ) = ∑ j = 1 m y j f Y ∣ X ( y j ∣ x ) E(Y|X=x)=\sum_{j=1}^my_jf_{Y|X}(y_j|x) E(Y∣X=x)=∑j=1myjfY∣X(yj∣x)其中x为常量
multi random variable conditional expectional value(continued)
one random variable expectional value
首先我们的expectional value就是概率的值乘以样本,这样推广到continueal就是
E ( x ) = ∫ − ∞ ∞ x f x ( t ) d t E(x)=\int_{-∞}^{∞}xf_x(t)dt E(x)=∫−∞∞xfx(t)dt
上述的公式就非常的好理解, f X ( t ) 是 P D F f_X(t)是PDF fX(t)是PDF
假设不是x是(不是样本空间的样本)是一个映射,映射到random variable那么就如下
E ( g ( X ) ) = ∫ − ∞ ∞ g ( t ) f X ( t ) d t E(g(X))=\int_{-∞}^∞g(t)f_X(t)dt E(g(X))=∫−∞∞g(t)fX(t)dt
假设我们是多个random variable
E ( g ( X , Y ) ) = ∫ − ∞ ∞ ∫ − ∞ ∞ g ( u , v ) f X , Y ( u , v ) d u d v E(g(X,Y))=\int_{-∞}^∞\int_{-∞}^∞g(u,v)f_{X,Y}(u,v)dudv E(g(X,Y))=∫−∞∞∫−∞∞g(u,v)fX,Y(u,v)dudv
假设期望值是线性的则如下
E ( a X + b Y ) = a E ( X ) + b E ( Y ) E(aX+bY)=aE(X)+bE(Y) E(aX+bY)=aE(X)+bE(Y)
推论如下所示
E ( a X + b Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ ( a u + b v ) f X Y ( u , v ) d u d v = E(aX+bY)=\int_{-∞}^∞\int_{-∞}^∞(au+bv)f_{XY}(u,v)dudv= E(aX+bY)=∫−∞∞∫−∞∞(au+bv)fXY(u,v)dudv=
∫ − ∞ ∞ ∫ − ∞ ∞ a u f X Y ( u , v ) d u d v + ∫ − ∞ ∞ ∫ − ∞ ∞ b v f X Y ( u , v ) d u d v \int_{-∞}^∞\int_{-∞}^∞auf_{XY}(u,v)dudv+\int_{-∞}^∞\int_{-∞}^∞bvf_{XY}(u,v)dudv ∫−∞∞∫−∞∞aufXY(u,v)dudv+∫−∞∞∫−∞∞bvfXY(u,v)dudv
此时分别看2个积分公式发现外部的积分上下限和dv是不是相当于对dv进行marginal,所以
a ∫ − ∞ ∞ u f X ( u ) d u + b ∫ − ∞ ∞ v f Y ( v ) d v = a E ( X ) + b E ( Y ) a\int_{-∞}^∞uf_X(u)du+b\int_{-∞}^∞vf_Y(v)dv=aE(X)+bE(Y) a∫−∞∞ufX(u)du+b∫−∞∞vfY(v)dv=aE(X)+bE(Y)
moment
PS这里插一个小知识叫做moment(矩),一阶距是期望值,2阶矩是方差,公式如下
K t h M o m e n t : E ( X k ) K^{th}Moment:E(X^k) KthMoment:E(Xk)
he nth moment of a distribution about the mean is given by E ( ( X − u ) k ) E((X-u)^k) E((X−u)k)
高阶矩的目的是去测量一个分布的重尾程度,或者说概率 p(x)是否随着值x的增大急速地减少。
我们知道 V a r [ X ] = E [ X 2 ] − E [ X ] 2 Var[X]=E[X^2]-E[X]^2 Var[X]=E[X2]−E[X]2,关于这个的推论去看关于Var的章节,有详细推论,套用到这里我们可以得知 V a r [ X ] = E [ X 2 ] − E [ X ] 2 = m 2 − ( m 1 ) 2 Var[X]=E[X^2]-E[X]^2=m_2-(m_1)^2 Var[X]=E[X2]−E[X]2=m2−(m1)2
m 3 m_3 m3是描述一个distribution的asymmetric,假设 m 3 = 0 m_3=0 m3=0说明分布是symmetric也就是对称的,如果 m 3 < 0 m_3<0 m3<0说明distribution是不对称且顶点向右偏(顶点左边的分布缓,顶点右边的分布陡峭), m 3 > 0 m_3>0 m3>0说明顶点向左偏
moment generation function(MGF)
假设X是random variable,t是MGF中的变量如下
M X ( t ) = E ( e t x ) = ∑ X e t x f x ( x ) M_X(t)=E(e^{tx})=\sum_Xe^{tx}f_x(x) MX(t)=E(etx)=∑Xetxfx(x)或者 ∫ − ∞ ∞ e t x f X ( x ) d x \int_{-∞}^∞e^{tx}f_X(x)dx ∫−∞∞etxfX(x)dx
t是一个辅助变量,MGF的存在是为了让我们计算n阶moment更加的方便,X是random variable,x是random variable X中的变量
那么MGF和moment有啥具体关系呢?这里用到 e t x e^{tx} etx的泰勒公式,我们带入泰勒公式后再将泰勒公式带入E()中,最后对其求一阶导数,最后得到一阶moment,二阶导数得到二阶moment,以此类推,MGF还是要比直接算n阶moment要简单的多,再具体请看这里
假设random variable X和random variable Y是independent的那么
E [ X Y ] = E [ X ] E [ Y ] E[XY]=E[X]E[Y] E[XY]=E[X]E[Y]
推论如下
因为X和Y independent,所以 E [ X Y ] = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X , Y ( x , y ) d x d y = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X ( x ) f Y ( y ) d x d y = ∫ − ∞ ∞ x f X ( x ) d x ∫ − ∞ ∞ y f Y ( y ) d y = E [ X ] E [ Y ] E[XY]=\int_{-∞}^∞\int_{-∞}^∞xyf_{X,Y}(x,y)dxdy=\int_{-∞}^∞\int_{-∞}^∞xyf_X(x)f_Y(y)dxdy=\int_{-∞}^∞xf_X(x)dx\int_{-∞}^∞yf_Y(y)dy=E[X]E[Y] E[XY]=∫−∞∞∫−∞∞xyfX,Y(x,y)dxdy=∫−∞∞∫−∞∞xyfX(x)fY(y)dxdy=∫−∞∞xfX(x)dx∫−∞∞yfY(y)dy=E[X]E[Y]
那么同样X和Yindependece,且Z=X+Y,那么
M Y ( t ) = E [ e t Z ] = E [ e t ( X + Y ) ] = E [ e t X e t Y ] = E [ e t X ] E [ e t Y ] = M X [ t ] M Y [ t ] M_Y(t)=E[e^{tZ}]=E[e^{t(X+Y)}]=E[e^{tX}e^{tY}]=E[e^{tX}]E[e^{tY}]=M_X[t]M_Y[t] MY(t)=E[etZ]=E[et(X+Y)]=E[etXetY]=E[etX]E[etY]=MX[t]MY[t]
covariance and Correlation
covariance和correlation是描述2个random variable随着一个variable变化另一个变化情况的,这里请会议二阶正态分布中的rho也就是2个random variable的正相关和负相关
先给出covariance的公式 C o v ( X , Y ) = E ( ( X − u X ) ( Y − u Y ) ) Cov(X,Y)=E((X-u_X)(Y-u_Y)) Cov(X,Y)=E((X−uX)(Y−uY))
u X u_X uX和 u Y u_Y uY指的是mean(中值) of two random variable ,换句话说我们的样本是一个正态分布那么mean就是最中间的那个值(当然样本要经过排序)
假设正相关(随着X的增长Y也在增长),且X> u X u_X uX,那么Y> u Y u_Y uY所以最终期望值内的值为正,假设X< u X u_X uX,那么Y< u Y u_Y uY所以最终期望值内的值为正
假设负相关(随着X的增长Y减少),且X> u X u_X uX,那么Y< u Y u_Y uY所以最终期望值内的值为负,假设X< u X u_X uX,那么Y> u Y u_Y uY所以最终期望值内的值为负
假设2个random variable independence那么
COV(X,Y)=0,推论如下
假设2个random variable independence那么 f X , Y ( x , y ) = f X ( x ) f Y ( y ) f_{X,Y}(x,y)=f_X(x)f_Y(y) fX,Y(x,y)=fX(x)fY(y)所以
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) Cov(X,Y)=E(XY)-E(X)E(Y) Cov(X,Y)=E(XY)−E(X)E(Y)其中 E ( X Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X , Y ( x , y ) d x d y E(XY)=\int_{-∞}^∞\int_{-∞}^∞xyf_{X,Y}(x,y)dxdy E(XY)=∫−∞∞∫−∞∞xyfX,Y(x,y)dxdy因为 f X , Y ( x , y ) = f X ( x ) f Y ( y ) f_{X,Y}(x,y)=f_X(x)f_Y(y) fX,Y(x,y)=fX(x)fY(y)所以 E ( X Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ x y f X ( x ) f Y ( y ) d x d y = ∫ − ∞ ∞ x f X ( x ) d x ∫ − ∞ ∞ y f Y ( y ) d y = E ( X ) E ( Y ) E(XY)=\int_{-∞}^∞\int_{-∞}^∞xyf_X(x)f_Y(y)dxdy=\int_{-∞}^∞xf_X(x)dx\int_{-∞}^∞yf_Y(y)dy=E(X)E(Y) E(XY)=∫−∞∞∫−∞∞xyfX(x)fY(y)dxdy=∫−∞∞xfX(x)dx∫−∞∞yfY(y)dy=E(X)E(Y)
所以当random variable X和Y independent所以 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y),且 C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) = 0 Cov(X,Y)=E(XY)-E(X)E(Y)=0 Cov(X,Y)=E(XY)−E(X)E(Y)=0
但是当 C o v ( X , Y ) = 0 Cov(X,Y)=0 Cov(X,Y)=0不代表一定independent
当2个random variable X和Y 的Cov为0,代表2个random variable没有线性关系(我们用线性回归也不好预测其后续结果)
假设a是一常数,我们球random variable X和a的cov为0,公式是如下
C o v ( X , a ) = E ( ( X − u x ) ( a − a ) ) = 0 Cov(X,a)= E((X-u_x)(a-a))=0 Cov(X,a)=E((X−ux)(a−a))=0
假设我们有2个random variable,求这2个randoom variable分别经过线性函数后的covariance,如下
C o v ( a X + b , c Y + d ) = E ( ( a X + b − E ( a X + b ) ) ( c Y + d − E ( c Y + d ) ) ) = E ( ( a X + b − a u x − b ) ( c Y + d − c u y − d ) ) = a c E ( ( X − u x ) ( Y − u y ) ) = a c C o v ( X , Y ) Cov(aX+b, cY+d)=E((aX+b-E(aX+b))(cY+d-E(cY+d)))=E((aX+b-au_x-b)(cY+d-cu_y-d))=acE((X-u_x)(Y-u_y))=acCov(X,Y) Cov(aX+b,cY+d)=E((aX+b−E(aX+b))(cY+d−E(cY+d)))=E((aX+b−aux−b)(cY+d−cuy−d))=acE((X−ux)(Y−uy))=acCov(X,Y)
因为 E ( a X + b ) = E ( a X ) + E ( b ) = a E ( X ) + b E(aX+b)=E(aX)+E(b)=aE(X)+b E(aX+b)=E(aX)+E(b)=aE(X)+b
我们知道 C o v ( X , Y ) = E ( ( X − u X ) ( Y − u Y ) ) Cov(X,Y)=E((X-u_X)(Y-u_Y)) Cov(X,Y)=E((X−uX)(Y−uY))可推 C o v ( X , Y ) = E ( X Y − X u Y − Y u X + u X u Y ) = E ( X Y ) − E ( X u Y ) − E ( Y u X ) + E ( u X u Y ) = E ( X Y ) − u Y E ( X ) − u X E ( Y ) + E ( u X u Y ) = E ( X Y ) − E ( Y ) E ( X ) − E ( X ) E ( Y ) + E ( u X u Y ) = E ( X Y ) − E ( Y ) E ( X ) Cov(X,Y)=E(XY-Xu_Y-Yu_X+u_Xu_Y)=E(XY)-E(Xu_Y)-E(Yu_X)+E(u_Xu_Y)=E(XY)-u_YE(X)-u_XE(Y)+E(u_Xu_Y)=E(XY)-E(Y)E(X)-E(X)E(Y)+E(u_Xu_Y)=E(XY)-E(Y)E(X) Cov(X,Y)=E(XY−XuY−YuX+uXuY)=E(XY)−E(XuY)−E(YuX)+E(uXuY)=E(XY)−uYE(X)−uXE(Y)+E(uXuY)=E(XY)−E(Y)E(X)−E(X)E(Y)+E(uXuY)=E(XY)−E(Y)E(X)
假设我们有一个PDF f X , Y ( x , y ) = 1 2 f_{X,Y}(x,y)=\frac{1}{2} fX,Y(x,y)=21 when x =3, y=4, f X , Y ( x , y ) = 1 3 f_{X,Y}(x,y)=\frac{1}{3} fX,Y(x,y)=31 when x =3,y=6, f X , Y ( x , y ) = 1 6 f_{X,Y}(x,y)=\frac{1}{6} fX,Y(x,y)=61 when x =5,y=6, f X , Y ( x , y ) = 0 f_{X,Y}(x,y)=0 fX,Y(x,y)=0 when other得到以下
E ( X ) = 3 ∗ 1 2 + 3 ∗ 1 3 + 5 ∗ 1 6 + 0 = 10 3 E(X)=3*\frac{1}{2}+3*\frac{1}{3}+5*\frac{1}{6}+0=\frac{10}{3} E(X)=3∗21+3∗31+5∗61+0=310
E ( Y ) = 4 ∗ 1 2 + 6 ∗ 1 3 + 6 ∗ 1 6 + 0 = 5 E(Y)=4*\frac{1}{2}+6*\frac{1}{3}+6*\frac{1}{6}+0=5 E(Y)=4∗21+6∗31+6∗61+0=5
E X ( Y ) = 3 ∗ 4 ∗ 1 2 + 3 ∗ 6 ∗ 1 3 + 5 ∗ 6 ∗ 1 6 + 0 = 17 EX(Y)=3*4*\frac{1}{2}+3*6*\frac{1}{3}+5*6*\frac{1}{6}+0=17 EX(Y)=3∗4∗21+3∗6∗31+5∗6∗61+0=17
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) = 1 3 > 0 Cov(X,Y)=E(XY)-E(X)E(Y)=\frac{1}{3}>0 Cov(X,Y)=E(XY)−E(X)E(Y)=31>0
但是我们的covariance非常的难判断,但是我们可以用方差去进行标准化,则得到correlation公式如下
ρ = C o v ( X , Y ) V a r ( X ) V a r ( Y ) = C o v ( X , Y ) σ X σ Y ρ=\frac{Cov(X,Y)}{\sqrt{Var(X)Var(Y)}}=\frac{Cov(X,Y)}{{σ_Xσ_Y}} ρ=Var(X)Var(Y)Cov(X,Y)=σXσYCov(X,Y),因为Var就是variance方差
为什么说covariance好判断?因为ρ总是在-1到1之间,0到1代表正相关,0到-1代表负相关
且 ρ X Y = 0 = > C o v ( X , Y ) = 0 ρ_{XY}=0=>Cov(X,Y)=0 ρXY=0=>Cov(X,Y)=0
corelation只表示一个线性关系,假如概率分布是一个指数样的,我们correlation就不合适了
I n d e p e n d e n t = > u n c o r r e l a t i o n Independent=>uncorrelation Independent=>uncorrelation BUT u n c o r r e l a t i o n uncorrelation uncorrelation not => I n d e p e n d e n t Independent Independent
关于covariance matrix,这个在机器学习中用的非常多
conditional PDF
首先我们都知道2个event A,B
P ( A ∣ B ) = P ( A , B ) P ( B ) P(A|B)=\frac{P(A,B)}{P(B)} P(A∣B)=P(B)P(A,B)图形如下

告诉了我们B happen,那么A happen的概率是多少
我们知道了在离散的情况下,multiple random variable的conditional PMF公式如下
P Y ∣ X ( y j ∣ x k ) = P X Y ( x k , y . j ) P X ( x k ) = J o i n t m a r g i n a l P_{Y|X}(y_j|x_k)=\frac{P_{XY}(x_k,y.j)}{P_X(x_k)}=\frac{Joint}{marginal} PY∣X(yj∣xk)=PX(xk)PXY(xk,y.j)=marginalJoint
关于marginal,还有conditional PMF的例子看上面,这里都是回顾
值得注意的是conditional PMFs are just another type of PMF,啥意思?我们的conditional PMFs比如 P X ∣ Y ( x ∣ 1 ) P_{X|Y}(x|1) PX∣Y(x∣1)是另一种PMF,我们通过 P X ∣ Y ( x ∣ y ) P_{X|Y}(x|y) PX∣Y(x∣y)可以画出一个二维图,当X等于1的时候意味着就只有一行,此时我们可以标准化将这一行根据概率分割(相加为1),比如我原本的multi random variable如下
然后取 P X ∣ Y ( x ∣ 1 ) P_{X|Y}(x|1) PX∣Y(x∣1)的那一行,再标准化如下


在连续的世界中公式和离散一样,都是 c o n d i t i o n a l = j o i n t m a r g i n a l conditional=\frac{joint}{marginal} conditional=marginaljoint,所以连续的PDF公式如下和离散PMF一样
f Y ∣ X ( y ∣ x ) = f X Y ( x , y ) f X ( x ) f_{Y|X}(y|x)=\frac{f_{XY}(x,y)}{f_X{(x)}} fY∣X(y∣x)=fX(x)fXY(x,y)
if X and Y are independent then f X Y ( x , y ) = f X ( x ) f Y ( y ) = f Y ∣ X ( y ∣ x ) f X ( x ) = > f Y ∣ X ( y ∣ x ) = f Y ( y ) f_{XY}(x,y)=f_X(x)f_Y(y)=f_{Y|X}(y|x)f_X(x)=>f_{Y|X}(y|x)=f_Y(y) fXY(x,y)=fX(x)fY(y)=fY∣X(y∣x)fX(x)=>fY∣X(y∣x)=fY(y)这里和离散没有什么不同
真实例子:bayes decision rule
贝叶斯决策理论是模式识别(Pattern-classification)里面重要的概率统计方法之一,首先解释几个名词
- prior probability
就是我们一些意外事件发生之前的概率,假设我们从布袋拿球,布袋中一共由3个黄球,2个红球,那么取出红球的概率是 P ( p i c k _ r e d ) = 2 5 P(pick\_red)=\frac{2}{5} P(pick_red)=52,这个是prior概率,但是当我们已经取出一个黄球了,那么取出红球的概率还能是 2 5 \frac{2}{5} 52吗?- likelihood probability
此时我们应该想到概率论中有一个叫做condition probability的东西,所以这个时候我们表达式应该这样 P ( p i c k r e d ∣ p i c k _ y e l l o w ) P(pick_red|pick\_yellow) P(pickred∣pick_yellow),并且她也叫作likelihood probability- 贝叶斯公式如下
P ( A ∣ B ) P ( B ) = P ( A , B ) = P ( B , A ) = P ( A ) P ( B ∣ A ) − > P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B)P(B)=P(A,B)=P(B,A)=P(A)P(B|A)->P(A|B)=\frac{P(A)P(B|A)}{P(B)} P(A∣B)P(B)=P(A,B)=P(B,A)=P(A)P(B∣A)−>P(A∣B)=P(B)P(A)P(B∣A)
其中 P ( A ∣ B ) P(A|B) P(A∣B)是posterior, P ( A ) P(A) P(A)是prior, P ( B ∣ A ) P(B|A) P(B∣A)是likelihood此时根据贝叶斯决策得到,假如我们要识别狗和猫,X是我们待识别的样本,那么决定为狗
P ( 狗 ∣ X ) > P ( 猫 ∣ X ) − − − > > > f X ( x ∣ 狗 ) P ( 狗 ) P ( X ) > f X ( x ∣ 猫 ) P ( 猫 ) P ( X ) P(狗|X)>P(猫|X)--->>>\frac{f_X(x|狗)P(狗)}{P(X)}>\frac{f_X(x|猫)P(猫)}{P(X)} P(狗∣X)>P(猫∣X)−−−>>>P(X)fX(x∣狗)P(狗)>P(X)fX(x∣猫)P(猫)
决定为猫那么
P ( 猫 ∣ X ) > P ( 狗 ∣ X ) − − − > > > 与上同理 P(猫|X)>P(狗|X)--->>>与上同理 P(猫∣X)>P(狗∣X)−−−>>>与上同理假如 P ( 猫 ) = P ( 狗 ) = 1 2 P(猫)=P(狗)=\frac{1}{2} P(猫)=P(狗)=21,那么我们只能看likelihood,比谁的大(在给定的X)
variance
variance就是标准差的平方,也就是方差,离散情况太简单就不说了,直接说连续情况,公式如下
V a r ( x ) = ∫ − ∞ ∞ ( x − E ( x ) ) 2 f x ( X ) d x Var(x)=\int_{-∞}^∞(x-E(x))^2f_x(X)dx Var(x)=∫−∞∞(x−E(x))2fx(X)dx
E(x)可以看成mean, f x ( x ) f_x(x) fx(x)可以看成PDF
2个random variable如下
V a r ( X , Y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ ( x − E ( x ) ) 2 f x , y ( X , Y ) d x d y Var(X,Y)=\int_{-∞}^∞\int_{-∞}^∞(x-E(x))^2f_{x,y}(X,Y)dxdy Var(X,Y)=∫−∞∞∫−∞∞(x−E(x))2fx,y(X,Y)dxdy
conditional variance
V a r ( X ∣ Y = y ) = ∫ − ∞ ∞ ( x − E ( X ∣ Y = y ) ) 2 f X ∣ Y ( x ∣ y ) d x Var(X|Y=y)=\int_{-∞}^∞(x-E(X|Y=y))^2f_{X|Y}(x|y)dx Var(X∣Y=y)=∫−∞∞(x−E(X∣Y=y))2fX∣Y(x∣y)dx
因为是y固定,而x在变,所以是x的积分
首先E(X)可以看成mean,那么我们可以得到
V a r [ X ] = E [ ( X − E [ X ] ) 2 ] Var[X]=E[(X-E[X])^2] Var[X]=E[(X−E[X])2]
因为 E [ ( X − E [ X ] ) 2 ] = ∫ − ∞ ∞ ( x − E ( x ) ) 2 f x ( X ) d x E[(X-E[X])^2]=\int_{-∞}^∞(x-E(x))^2f_x(X)dx E[(X−E[X])2]=∫−∞∞(x−E(x))2fx(X)dx
进一步推论
V a r [ X ] = E [ ( X − E [ X ] ) 2 ] = E [ X 2 − 2 X E [ X ] + E [ X ] 2 ] Var[X]=E[(X-E[X])^2]=E[X^2-2XE[X]+E[X]^2] Var[X]=E[(X−E[X])2]=E[X2−2XE[X]+E[X]2]此时我们令 E [ X ] = u E[X]=u E[X]=u则 E [ X 2 − 2 X E [ X ] + E [ X ] 2 ] = E [ X 2 − 2 X u + u 2 ] = E [ X 2 ] − 2 u E [ X ] + u 2 = E [ X 2 ] − 2 u 2 + u 2 = E [ X 2 ] − u 2 = E [ X 2 ] − E [ X ] 2 E[X^2-2XE[X]+E[X]^2]=E[X^2-2Xu+u^2]=E[X^2]-2uE[X]+u^2=E[X^2]-2u^2+u^2=E[X^2]-u^2=E[X^2]-E[X]^2 E[X2−2XE[X]+E[X]2]=E[X2−2Xu+u2]=E[X2]−2uE[X]+u2=E[X2]−2u2+u2=E[X2]−u2=E[X2]−E[X]2
所以…
V a r [ X ] = E [ X 2 ] − E [ X ] 2 Var[X]=E[X^2]-E[X]^2 Var[X]=E[X2]−E[X]2
因为 E [ x ] = m e a n = μ E[x]=mean=\mu E[x]=mean=μ,所以 V a r [ X ] = E [ X 2 ] − μ 2 = σ 2 Var[X]=E[X^2]-\mu^2=\sigma^2 Var[X]=E[X2]−μ2=σ2,因为 σ \sigma σ是标准差,var是方差
进一步假设random variable X的所有sample相加除以n(aka平均数aka X ˉ \bar{X} Xˉ),那么 V a r [ X ˉ ] = V a r [ X 1 + X 2 + . . . + X n n ] = 1 n V a r [ X 1 + . . . + X n ] = 1 n ( V a r [ X 1 ] + V a r [ X 2 ] + . . . + V a r [ X n ] ) = σ 2 n = E [ X ˉ 2 ] − μ 2 Var[\bar{X}]=Var[\frac{X1+X2+...+Xn}{n}]=\frac{1}{n}Var[X1+...+Xn]=\frac{1}{n}(Var[X1]+Var[X2]+...+Var[Xn])=\frac{\sigma^2}{n}=E[\bar{X}^2]-\mu^2 Var[Xˉ]=Var[nX1+X2+...+Xn]=n1Var[X1+...+Xn]=n1(Var[X1]+Var[X2]+...+Var[Xn])=nσ2=E[Xˉ2]−μ2
Joint Distribution of Discrete and Continuous Random Variables
顾名思义就是我们的概率模型中有离散random variables也有连续random variables
定义如下
假设d为离散的random variable,c为连续的random variable,他们定义在一个相同的概率空间中,样本空间中的w,可以映射到d(w),c(w),那么joint pmf和joint pdf是多少?
啥意思?就是我们样本空间Ω中的样本通过某种映射(某种函数之类的东西)映射成1,2,3,4,5这种离散的样本统称为w给d,同样 样本空间Ω中的样本通过某种映射(某种函数之类的东西)映射成一个连续的样本给c
其实单独的joint discrete and continued pdf和pmf是dosen’t make sense的,但是他们的marginal pdf,marginal condition是make sense的
CF(characteristic function)
CF是一个复杂的方程,这个方程彻底的识别了一个random variable的分布,一些random variable没有MGF,但是每一个random variable都有CF
sum of random variables
假设我们有多个random variable,我们想把多个random variable相加,为什么相加?多个random variable相加意义就是形成一个新的randon variable,假设我们有一个random vairable表示1月份所有天数,盈亏情况(x轴是return百分比,y轴是这个return百分比发生的频率),因为有1月就有2月,3月…12月,所以我们可以有12个random variable,年度统计的时候我们要将这12个月的情况都相加,所以此时我们需要用到sum of random variable
假设X1是random variable1,X2是random variable2…Xn是random variablen那么
s u m : X 1 + X 2 + . . . + X N = S n = ∑ i = 1 N X i sum:X_1+X_2+...+X_N=S_n=\sum_{i=1}^NX_i sum:X1+X2+...+XN=Sn=∑i=1NXi
M e a n : 1 n ∑ i = 1 N X i = M n Mean:\frac{1}{n}\sum_{i=1}^NX_i=M_n Mean:n1∑i=1NXi=Mn
E ( S N ) = E ( X 1 + X 2 + . . . + X n ) = E ( X 1 ) + E ( X 2 ) + . . . + E ( X n ) = ∑ i = 1 n E ( X i ) E(S_N)=E(X_1+X_2+...+X_n)=E(X_1)+E(X_2)+...+E(X_n)=\sum_{i=1}^nE(X_i) E(SN)=E(X1+X2+...+Xn)=E(X1)+E(X2)+...+E(Xn)=∑i=1nE(Xi)
E ( M n ) = 1 n ∑ i = 1 n E ( X i ) E(M_n)=\frac{1}{n}\sum_{i=1}^nE(X_i) E(Mn)=n1∑i=1nE(Xi)
V a r ( S n ) = E ( S n 2 ) − ( E ( S n ) ) 2 Var(S_n)=E(S_n^2)-(E(S_n))^2 Var(Sn)=E(Sn2)−(E(Sn))2
variance有些奇怪,这里我们推论一下
E ( S n 2 ) = E ( ( X 1 + X 2 + . . . + X n ) ( X 1 + X 2 + . . . + X n ) ) = ∑ i = 1 n ∑ j = 1 n E ( X i X j ) E(S_n^2)=E((X_1+X_2+...+X_n)(X_1+X_2+...+X_n))=\sum_{i=1}^n\sum_{j=1}^nE(X_iX_j) E(Sn2)=E((X1+X2+...+Xn)(X1+X2+...+Xn))=∑i=1n∑j=1nE(XiXj)
( E ( S n ) ) 2 = ( E ( X 1 ) + . . . + E ( X n ) ) 2 (E(S_n))^2=(E(X_1)+...+E(X_n))^2 (E(Sn))2=(E(X1)+...+E(Xn))2
所以
V a r ( S n ) = E ( S n 2 ) − ( E ( S n ) ) 2 = ∑ i = 1 n ∑ j = 1 n ( E ( X i X j ) − E ( X i ) E ( X j ) ) = ∑ i = 1 n ∑ j = 1 n C o v ( X i , X j ) Var(S_n)=E(S_n^2)-(E(S_n))^2=\sum_{i=1}^n\sum_{j=1}^n(E(X_iX_j)-E(X_i)E(X_j))=\sum_{i=1}^n\sum_{j=1}^nCov(X_i,X_j) Var(Sn)=E(Sn2)−(E(Sn))2=∑i=1n∑j=1n(E(XiXj)−E(Xi)E(Xj))=∑i=1n∑j=1nCov(Xi,Xj)
我们知道一个random X的normal distribution要这样表达 X X X~ N ( μ x , ( σ x ) 2 ) N(μ_x,(σ_x)^2) N(μx,(σx)2),其中μ代表mean,σ代表标准差,那么我们有2个independent的random variable X和Y,分别由 X X X~ N ( μ x , ( σ x ) 2 ) N(μ_x,(σ_x)^2) N(μx,(σx)2) , Y Y Y~ N ( μ y , ( σ y ) 2 ) N(μ_y,(σ_y)^2) N(μy,(σy)2),此时由一个Z=aX+bY,那么Z也是normal distribution的,记为 Z Z Z~ N ( a μ x + b μ y , a 2 σ x 2 + b 2 σ y 2 ) N(aμ_x+bμ_y,a^2σx^2+b^2σy^2) N(aμx+bμy,a2σx2+b2σy2),假如更多个independence 的random variable这是可以推广的假设X1,…Xn是independent的那么 Z = ∑ a i X i Z=\sum a_iX_i Z=∑aiXi~ N ( ∑ i a i μ i , ∑ ( a i ) 2 ( σ i ) 2 ) N(\sum_ia_iμ_i,\sum (a_i)^2(σ_i)^2) N(∑iaiμi,∑(ai)2(σi)2)
怎么推论呢?如下
假设我们有2个random variable X和Y independence,Z=aX+bY
设Z的MGF为 M Z ( t ) = M a X + b Y ( t ) = E ( e t ( a X + b Y ) ) = E ( e a t X e b t Y ) M_Z(t)=M_{aX+bY}(t)=E(e^{t(aX+bY)})=E(e^{atX}e^{btY}) MZ(t)=MaX+bY(t)=E(et(aX+bY))=E(eatXebtY)
因为X和Y independence则
原式= E ( e a t X ) E ( e b t Y ) = M X ( a t ) M Y ( b t ) = M X ( t ) E(e^{atX})E(e^{btY})=M_X(at)M_Y(bt)=M_X(t) E(eatX)E(ebtY)=MX(at)MY(bt)=MX(t)
因为X和Y是normal distribute的所以
原式= e a μ 1 t + σ 1 2 ( a t ) 2 2 e b μ 2 t + σ 2 2 ( b t ) 2 2 = e t ( a μ 1 + b μ 2 ) + t 2 2 ( a 2 σ 1 2 + b 2 σ 2 2 ) e^{aμ_1t+\frac{σ_1^2(at)^2}{2}}e^{bμ_2t+\frac{σ_2^2(bt)^2}{2}}=e^{t(aμ_1+bμ_2)+\frac{t^2}{2}(a^2σ_1^2+b^2σ_2^2)} eaμ1t+2σ12(at)2ebμ2t+2σ22(bt)2=et(aμ1+bμ2)+2t2(a2σ12+b2σ22)
此时Z可以看成 Z Z Z~ N ( a μ 1 + b μ 2 , a 2 σ 1 2 + b 2 σ 2 2 ) N(aμ_1+bμ_2,a^2σ_1^2+b^2σ_2^2) N(aμ1+bμ2,a2σ12+b2σ22),此时Z也是正态分布的
假设X为正态分布,那么其PDF为
PDF= 1 σ 2 Π e − 1 2 ( x − μ σ ) 2 \frac{1}{σ\sqrt{2Π}}e^{-\frac{1}{2}(\frac{x-μ}{σ})^2} σ2Π1e−21(σx−μ)2
对应的MGF为
MGF= e μ t + σ 2 t 2 2 e^{μt+\frac{σ^2t^2}{2}} eμt+2σ2t2
change of variable:two to one
假设我们有2个random variableX和Y,此时我们有一个新的random variable Z等于g(x,y)
我们已知X和Y的joint PDF f X , Y ( x , y ) f_{X,Y}(x,y) fX,Y(x,y),求Z的PDF f Z ( z ) f_Z(z) fZ(z)
例如:我们有2个random variableX和Y,X~EXPO(lambda),Y ~ EXPO(lanbda),所以X和Y是independence,此时我们有一个新的random variable Z等于g(x,y),
g(z,y)=MAX(X,Y)
我们可以先求Z的CDF,如下
F Z ( 3 ) = P ( Z < = 3 ) = P ( M A X ( X , Y ) < = 3 ) = P ( X < = 3 , Y < = 3 ) F_Z(3)=P(Z<=3)=P(MAX(X,Y)<=3)=P(X<=3,Y<=3) FZ(3)=P(Z<=3)=P(MAX(X,Y)<=3)=P(X<=3,Y<=3)因为indpendent
原式= P ( X < = 3 ) P ( Y < = 3 ) P(X<=3)P(Y<=3) P(X<=3)P(Y<=3)
因为X和Y都是指数分布,所以其PDF为,当x>0时 f X ( x ) = λ e − λ x f_X(x)=λe^{-λx} fX(x)=λe−λx,other f X ( x ) = 0 f_X(x)=0 fX(x)=0,然后其对应的CDF是 F X ( u ) = 1 − e − λ u F_X(u)=1-e^{-λu} FX(u)=1−e−λu,when u >0
所以原式= ( 1 − e − 3 λ ) 2 (1-e^{-3λ})^2 (1−e−3λ)2,最后先对λ求导再带入3即可
Law of Large Number(LLN)
假设我们有N个Random variable X 1 . . . X m X_1...X_m X1...Xm 且他们是independent,且 E ( X i ) = u E(X_i)=u E(Xi)=u, v a r ( X i ) = σ 2 var(X_i)=\sigma^2 var(Xi)=σ2 ,i为1到m之间任意一个数
那么我们可以得到,假如
S = X 1 + . . . + X m S=X_1+...+X_m S=X1+...+Xm
sample mean(SM)= X 1 + . . . + X m m \frac{X_1+...+X_m}{m} mX1+...+Xm
得
E ( S ) = m u E(S)=mu E(S)=mu
这个好理解因为independent所以 E ( X 1 + X 2 + . . . + X n ) = E ( X 1 ) + E ( X 2 ) + . . . + E ( X n ) E(X_1+X_2+...+X_n)=E(X_1)+E(X_2)+...+E(X_n) E(X1+X2+...+Xn)=E(X1)+E(X2)+...+E(Xn)
v a r ( S ) = V a r ( X 1 ) + V a r ( X 2 ) + . . . + V a r ( X n ) = m σ 2 var(S)=Var(X_1)+Var(X_2)+...+Var(X_n)=m\sigma^2 var(S)=Var(X1)+Var(X2)+...+Var(Xn)=mσ2
E ( S M ) = m u m = u E(SM)=\frac{mu}{m}=u E(SM)=mmu=u
V a r ( S M ) = 1 m 2 ( V a r ( X 1 ) + . . . + V a r ( X m ) ) = m σ 2 m 2 = σ 2 m Var(SM)=\frac{1}{m^2}(Var(X_1)+...+Var(X_m))=\frac{m\sigma^2}{m^2}=\frac{\sigma^2}{m} Var(SM)=m21(Var(X1)+...+Var(Xm))=m2mσ2=mσ2
因为 V a r ( a X ) = E ( ( a X ) 2 ) − E ( a X ) 2 = a 2 E ( X 2 ) − a 2 E ( X ) 2 = a 2 ( E ( X 2 ) − E ( X ) 2 ) = a 2 V a r ( X ) Var(aX)=E((aX)^2)-E(aX)^2=a^2E(X^2)-a^2E(X)^2=a^2(E(X^2)-E(X)^2)=a^2Var(X) Var(aX)=E((aX)2)−E(aX)2=a2E(X2)−a2E(X)2=a2(E(X2)−E(X)2)=a2Var(X)
Central Limit Theorem(CLT)
if X1…Xn independent并且这些random variable是independent and identically distributed(都是同一个分布,且independent)
当S=X1+…+Xm时,m趋于无穷,则S是一个正态分布 N ( m u , m σ 2 ) N(mu,m\sigma^2) N(mu,mσ2),其中E(Xi)=u,Var(Xi)= σ 2 \sigma^2 σ2
假设X1…Xn的期望值和方差都相等,且X1=0
既然是正态分布,那么我们就要求其中的mean和方差,所以如下
u = E [ S n ] = E [ X 1 + X 2 + . . . + X n ] = E [ X 1 ] + E [ X 2 ] + . . . + E [ X n ] = n E [ X 1 ] u=E[S_n]=E[X_1+X_2+...+X_n]=E[X_1]+E[X_2]+...+E[X_n]=nE[X_1] u=E[Sn]=E[X1+X2+...+Xn]=E[X1]+E[X2]+...+E[Xn]=nE[X1]
σ = V a r [ S n ] = V a r [ X 1 + X 2 + . . . + X n ] = V a r [ X 1 + X 2 + . . . + X n ] = ( V a r [ X 1 ] + V a r [ X 2 ] + . . . + V a r [ X n ] ) = n V a r [ X 1 ] \sigma=Var[S_n]=Var[{X_1+X_2+...+X_n}]=Var[X_1+X_2+...+X_n]=(Var[X_1]+Var[X_2]+...+Var[X_n])=nVar[X_1] σ=Var[Sn]=Var[X1+X2+...+Xn]=Var[X1+X2+...+Xn]=(Var[X1]+Var[X2]+...+Var[Xn])=nVar[X1]
我们还可以对random variable求平均数,如 X ˉ = X 1 + X 2 + . . . + X n n \bar{X}=\frac{X_1+X_2+...+X_n}{n} Xˉ=nX1+X2+...+Xn,然后对 X ˉ \bar{X} Xˉ求mean和 σ \sigma σ(为了求normal distribution),如下
u = E [ X ˉ n ] = E [ S n n ] = n E [ X 1 ] n = E [ X 1 ] u=E[\bar{X}_n]=E[\frac{S_n}{n}]=\frac{nE[X_1]}{n}=E[X_1] u=E[Xˉn]=E[nSn]=nnE[X1]=E[X1]
σ 2 = V a r [ X n ˉ ] = V a r [ S n n ] = 1 n 2 V a r [ S n ] = 1 n 2 n V a r [ X 1 ] = V a r [ X 1 ] n \sigma^2=Var[\bar{X_n}]=Var[\frac{S_n}{n}]=\frac{1}{n^2}Var[S_n]=\frac{1}{n^2}nVar[X_1]=\frac{Var[X_1]}{n} σ2=Var[Xnˉ]=Var[nSn]=n21Var[Sn]=n21nVar[X1]=nVar[X1]
σ = S D [ X ˉ ] = S D [ X 1 ] n \sigma=SD[\bar{X}]=\frac{SD[X_1]}{\sqrt{n}} σ=SD[Xˉ]=nSD[X1]
当我们n趋于无穷,意思是random variable越来越多, σ = 0 \sigma=0 σ=0,意味着样本无穷大,样本平均值的方差趋于0,而mean等于E[X1]
random variable 的方差等于0代表,random variable是一个常量,random variable是一个常量说明不管random variable的X是多少,都等于一个常数结果,这个常数就是 E [ X 1 ] E[X_1] E[X1]
statistics
statistics其实和概率论没有多大的区别,很多概念相通
3