Jenkins pipeline 共享库最佳实践
一、jenkins 共享库介绍
jenkins共享库主要的作用就是将pipeline的具体实现封装成方法,可以方便不同的Jenkinsfile调用,就像java里面的guava工具包,一次封装,到处使用
首先我们看看共享库的结构
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar官网这一套说的已经很清楚了,我主要讲讲我的理解,src目录主要存放具体的实现方法的类,vars目录所谓的全局共享变量,里面既可以写pipeline结构,又可以写具体实现方法,就像一个中间状态,而resouces目录放一些文件,配置等
二、jenkins 共享库最佳实践
网络上关于jenkins共享库的实践不多,哪怕是有梯子也找不到太多资料,我这边摸索后,整理出一套还算灵活的架构,希望能给需要的人带来帮助
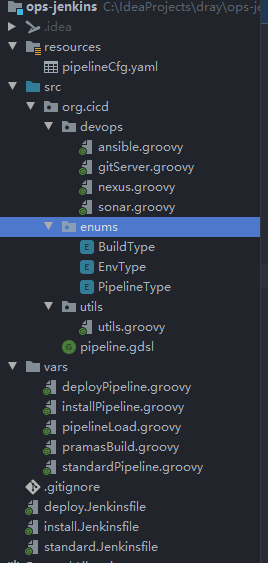
首先看看我的目录架构,后缀为Jenkinsfile的文件,就是我们常用的Jenkinsfile,只是我将其具体实现隐藏了起来,主要只是一个入口的最作用;vars目录最主要主要存放参数的封装组建方法和pipeline结构的拼接;devops目录存放每个步骤的具体实现;enums存放的一些枚举值;utils存放通用的方法;
以下是standard.Jenkinsfile的代码
import org.cicd.enums.PipelineType
@Library('jenkinslibs@dev') _
pipelineLoad PipelineType.STANDARD
jenkinslibs@dev指定了共享库的名称和分支,pipelineLoad PipelineType.STANDARD 意思是调用了pipelineLoad的call方法,参数为 PipelineType.STANDARD
以下为pipelineLoad.groovy的实现
import org.cicd.enums.PipelineType
import org.cicd.utils.utils
def call(pipelineType) {
def cfg_text = libraryResource("pipelineCfg.yaml") //从resource目录加载配置文件,解析为文本信息
def cfg = readYaml text: cfg_text //将读取的文本转化为map,需要安装Pipeline UtilitySteps Steps插件
def paramMap = pramasBuild(pipelineType,cfg) //封装参数化构建传递过来的参数
def utils = new utils()
pipeline {
agent any
//预加载工具信息,在全局工具配置的工具
tools {
jdk 'JDK_11'
maven 'M3'
git 'GIT'
nodejs 'NodeJS'
}
//可选参数
options {
skipDefaultCheckout() //删除隐式checkout scm语句
disableConcurrentBuilds() //禁止并行
timeout(time: 1, unit: 'HOURS') //流水线超时设置1h
timestamps()
}
stages {
stage("初始化步骤") {
steps {
script{
//具体步骤在其他文件中申明
switch (pipelineType) {
case PipelineType.STANDARD:
standardPipeline(paramMap)
break
case PipelineType.DEPLOY:
deployPipeline(paramMap)
break
case PipelineType.INSTALL:
installPipeline(paramMap)
break
}
}
}
}
}
//清理工作
post {
always {
script {
utils.clearSpace(["jar", "zip"], paramMap.get("ansible_src"))
}
}
}
}
}
return this接着我们看看standardPipeline.groovy,这里面定义了这条流水线需要执行的步骤
import org.cicd.devops.ansible
import org.cicd.devops.gitServer
import org.cicd.devops.nexus
import org.cicd.devops.sonar
def call(paramMap) {
def gitServer = new gitServer()
def sonar = new sonar()
def nexus = new nexus()
def ansible = new ansible()
//下载代码
stage("下载代码") { //阶段名称
script {
gitServer.checkOutCode(paramMap)
}
}
//代码扫描
stage("代码扫描") {
script {
sonar.sonarScan(paramMap)
}
}
//构建代码
stage("构建代码") {
script {
nexus.build(paramMap)
}
}
//部署
stage("部署代码") {
script {
ansible.deploy(paramMap)
}
}
}
return thisutils主要封装了通用的方法
package org.cicd.utils
import org.cicd.enums.*
/**
* 清理当前工程的目录
* @return
*/
def clearSpace(list=['jar','zip'],path) {
list.each {
sh "find ./ -type f -name *.$it | xargs rm -rf"
}
deleteFile("${path}/files/*")
}
/**
* 格式化输出
* @param value
* @param color
* @return
*/
def printMessage(value, color) {
def colors = ['groovy': "\033[40;31m >>>>>>>>>>>${value}<<<<<<<<<<< \033[0m",
'blue' : "\033[47;34m ${value} \033[0m",
'green' : "[1;32m>>>>>>>>>>${value}>>>>>>>>>>[m",
'green1': "\033[40;32m >>>>>>>>>>>${value}<<<<<<<<<<< \033[0m"]
ansiColor('xterm') {
println(colors[color])
}
}
/**
* 创建临时目录
* @return
*/
def initTmpDir(path) {
println("初始化临时目录")
sh """
if [ ! -d "${path}" ]; then
echo "创建文件夹"
mkdir -p "${path}"
fi
"""
}
/**
* 检查文件是否存在glob: 'script/*.sh'
* @param path
* @return
*/
def checkFileExist(path) {
def files = findFiles(glob: "${path}")
println("${files}")
if (null != files && files.length >= 1) {
return true
}
return false
}
/**
* 删除文件
* @param path
* @return
*/
def deleteFile(path) {
println("删除文件$path")
sh """
rm -rf ${path}
"""
}
def zipFile(path, fileName) {
zip dir: "${path}", glob: '', zipFile: "${fileName}"
}
给大家看看sonar的方法
package org.cicd.devops
import org.cicd.utils.utils
/**
* sonar扫描
* @param buildType
* @return
*/
def sonarScan(Map params) {
def utils = new utils()
utils.printMessage("代码扫描", "green")
withSonarQubeEnv('SonarQube') {
switch (params.get("build_type")) {
case "mvn":
//mvn
sh "mvn clean verify sonar:sonar -Dmaven.test.skip=true -Dsonar.projectKey=${params.get("artifact_id")} -Dsonar.projectName=${params.get("artifact_id")} "
break
case "npm":
def scannerHome = tool 'Sonar_Scanner'
sh """
${scannerHome}/bin/sonar-scanner -Dsonar.projectKey=${params.get("artifact_id")} \
-Dsonar.projectName=${params.get("artifact_id")} \
-Dsonar.sources=.
"""
break
}
}
}
将所有需要参数封装成·map是为了后续参数的变动扩展,在这套框架的基础上,如果想要添加新的流程是非常方便的事,只要在vars目录新建一个pipeline文件,定义上自己的具体步骤,调用实现方法即可。当然,这套实现可能存在不合理的地方,如有错误希望大家指定。
源码请参考码云:https://gitee.com/Dray/jenkinslib
或者最大的同性交友网站:https://github.com/rayduan/jenkins-lib.git
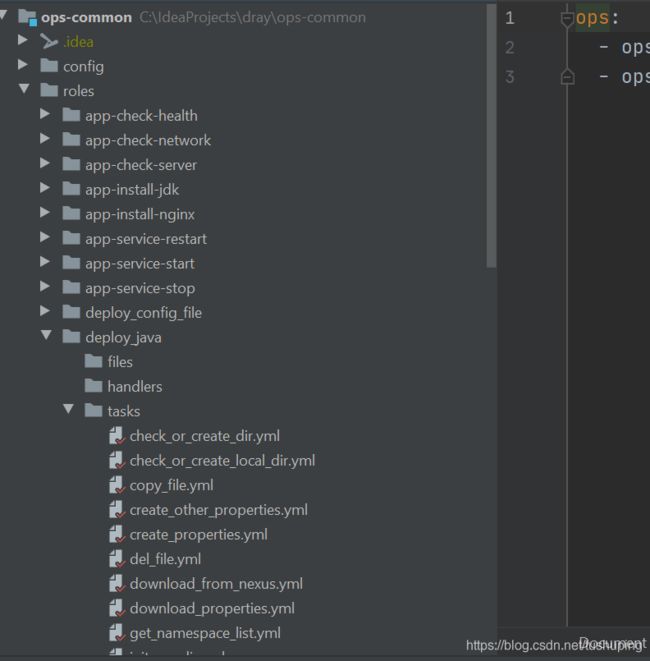
鉴于有小伙伴想要了解ansible playbook目录,结构如下图所示:

ansible 示例代码如下:https://gitee.com/Dray/ops-ansible.git