剑指 Offer 07. 重建二叉树
剑指 Offer 07. 重建二叉树
难度: m i d d l e \color{orange}{middle} middle
题目描述
输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。
假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
示例 1:
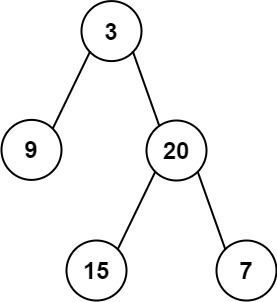
Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]
示例 2:
Input: preorder = [-1], inorder = [-1]
Output: [-1]
限制:
0 < = 节点个数 < = 5000 0 <= 节点个数 <= 5000 0<=节点个数<=5000
注意 :本题与主站 105 题重复:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
算法
(dfs)
二叉树前序遍历的顺序为:
-
先遍历根节点;
-
随后递归地遍历左子树;
-
最后递归地遍历右子树。
二叉树中序遍历的顺序为:
-
先递归地遍历左子树;
-
随后遍历根节点;
-
最后递归地遍历右子树。
在「递归」地遍历某个子树的过程中,我们也是将这颗子树看成一颗全新的树,按照上述的顺序进行遍历。挖掘「前序遍历」和「中序遍历」的性质,我们就可以得出本题的做法。
对于任意一颗树而言,前序遍历的形式总是
[ 根节点, [左子树的前序遍历结果], [右子树的前序遍历结果] ]
即根节点总是前序遍历中的第一个节点。而中序遍历的形式总是
[ [左子树的中序遍历结果], 根节点, [右子树的中序遍历结果] ]
只要我们在中序遍历中定位到根节点,那么我们就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们就可以对应到前序遍历的结果中,对上述形式中的所有左右括号进行定位。
这样以来,我们就知道了左子树的前序遍历和中序遍历结果,以及右子树的前序遍历和中序遍历结果,我们就可以递归地对构造出左子树和右子树,再将这两颗子树接到根节点的左右位置。
细节
在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。在此后构造二叉树的过程中,我们就只需要 O ( 1 ) O(1) O(1) 的时间对根节点进行定位了。
复杂度分析
-
时间复杂度: O ( n ) O(n) O(n),其中 n n n 是树中的节点个数。
-
空间复杂度 : O ( n ) O(n) O(n)
C++ 代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
unordered_map<int, int> hash;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n = preorder.size();
for (int i = 0; i < n; i ++)
hash[inorder[i]] = i;
return dfs(preorder, 0, n - 1, inorder, 0, n - 1);
}
TreeNode* dfs(vector<int>& preorder, int pl, int pr, vector<int>& inorder, int il, int ir)
{
if (pl > pr) return nullptr;
auto root = new TreeNode(preorder[pl]);
int k = hash[root->val];
auto left = dfs(preorder, pl + 1, pl + k - il, inorder, il, k - 1);
auto right = dfs(preorder,pl + 1 + k - il, pr, inorder, k + 1, ir);
root->left = left, root->right = right;
return root;
}
};