如何实现一套优雅的Baas查询语言?
Baas平台内,同一区块链底层接口数据可能会被应用在不同的业务场景下,因此需要进行筛选或者排序等操作。为满足此类需求,通常后端需要开发新的接口或增加新的字段以满足业务诉求。但随着需求业务不断变更,往往不可避免地导致接口的修改、新增,相应的接口文档和代码的维护成本也随之骤增。
为此,趣链BaaS在实践中总结了一套标准的客户端与服务端间自定义查询语法,使客户端能便捷对数据库进行分页与筛选,从而获取满足不同业务场景的数据,同时可保障服务端接口的可扩展性。
传统接口设计的痛点
用户使用过程中,列表可能存在大量的数据,以链列表为例,一旦用户需要对自己感兴趣的信息进行筛选搜索排序,则该数据接口需要输出供用户模糊查询链名、对链状态筛选、按照创建时间排序等能力。在此场景下,典型的接口设计做法可能是:
func getChainList(string name, int state, string time) {
if len(name) != 0 {
//追加SQL条件
}
if state(name) != 0 {
//追加SQL条件
}
if len(time) != 0 && time == "desc" {
//追加SQL条件
}
}
毫无疑问,随着业务的变更接口的参数越来越多,即便封装成一个对象也会不断膨胀,无法避免重复代码问题。
最佳实践方案
对于任何一个接口而言,搜索和筛选是非常基础的功能,系统期望能够有效地向客户端应用程序提供数据,因此必须以灵活的方式构建接口,支持快速响应查询操作。
为此,需要定义查询一套查询语言,支持灵活筛选所需的资源,一方面可供前端便捷调用并筛选出所需的资源,另一方面提升后端对接口的复用性,提升整个代码的复用率。实践中,我们选择基于FIQL(Flexible Item Query Language)部分规范来实现这套通用的API语言查询接口。之所以选择该语法,是因为其不仅语句简单易懂,且具有安全的URL编码字符,前端以及驱动开发者能够快速上手编写语句。
因此,趣链自定义接口查询语言具有如下优势:
A.丰富的查询功能: 支持模糊查询、范围查询、分页查询、排序及精确匹配,支持多个条件间进行灵活组合;
B.灵活兼容多种语言及数据库:通过解析器可将前端的语法解析成不同语言,通过SQL生成器能支持多种数据源,包括关系型数据库、非关系型数据库、文件系统等;
C.安全性保障:在设计生成器时,考虑到数据库结构泄漏及已存在的SQL注入等情况,采用对所有查询条件进行验证映射机制,避免恶意的查询对系统安全造成影响;
因此,通过基于FIQL的API接口查询语言,为用户提供一种灵活、高效、安全的查询工具。用户可通过这种工具快速、简单地查询所需的信息,实现更多功能。
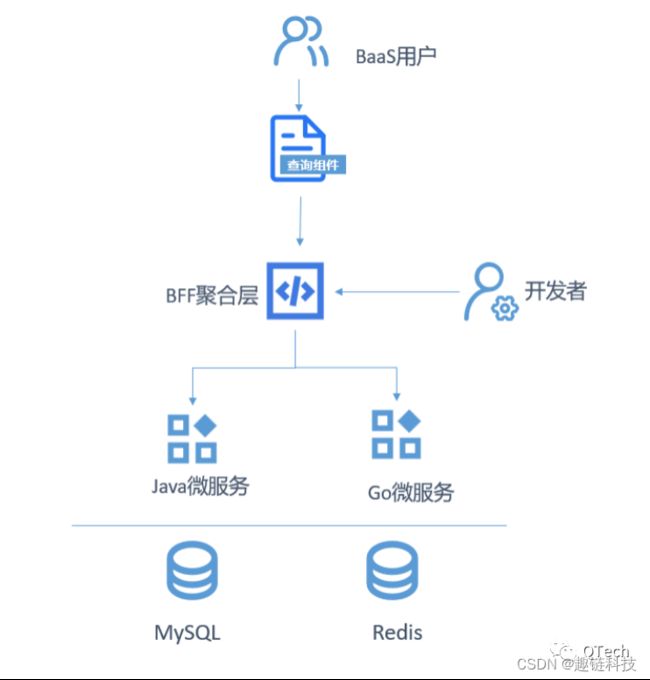
典型应用场景
统一处理BaaS资源列表数据
过去,由于BaaS平台内存在大量的资源列表且资源列表中存在关联的其他资源信息,用户需要在上述大量数据中筛选所需的资源信息。通过趣链BaaS自定义查询语言,前端不再需要通过请求多个API服务后渲染资源,而是通过统一的资源接口再由BFF层聚合多个微服务数据信息组合而成。BFF层解析自定义语法并根据不同的服务接口定义转为对应的接口入参,将请求定向发送至不同的微服务,待微服务返回后由BFF层统一聚合成对应的数据返回至前端。
提升标准驱动资源对接能力
在《一键部署区块链背后的秘密(上)》中,我们了解到趣链BaaS驱动由前端页面和后端组成,所有的资源操作通过透传接口直接与后端交互,而前端的页面的资源信息是通过Baas平台提供的接口查询的。
由于驱动页面是可以定制开发的,对于资源相关信息需要通过Baas平台提供的接口来查询,以创建联盟链过程为例,前端驱动页面存在较多的填写与选择逻辑。例如,在链名是否重复的判断中,需要选择节点部署的主机。虽然页面呈现出的效果不尽相同,但业务背后都是通过请求BaaS资源查询进行后续的逻辑处理。在平台驱动开发中,尽管平台可以提供单独的接口,但随着后续越来越多的驱动类型,可以想象如果都由平台单独来提供,那么API 将呈现爆炸的增长。另一方面,随着个人驱动开发者的加入,平台无法100%预测开发所需的接口,因此平台需要有一套通用的查询资源接口方案。
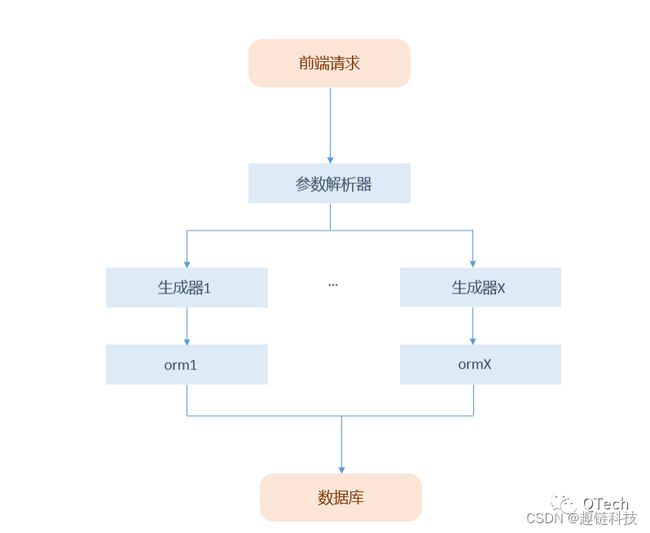
整体流程
1)前端通过Web请求携带请求参数start、size、filter、sort;
2)后端接收到请求后,解析器对filter与sort语法进行校验、解析、映射;
3)根据后端集成的不同orm,借助生成器转换;
4)执行orm将条件转为原生的sql执行;
实操案例
■设计统一的参数格式
type queryParmas {
int start
int size
string filter
string sort
}
我们希望接口参数能够保持一致,并且不随着接口查询字段的变更而增加或改编,因此我们需要友好且灵活的语法作为一个表达式,并且通过规范性的语法生成限制条件。
为此,我们将前端查询的的数据规范为四个参数start(起始页)、size(分页大小)、filter(查询条件)、sort(排序条件)并规定了格式,其中:
filter 用于过滤筛选返回参数内容,基本语法由字段<筛选关系>条件组成:
•查询状态1和3 state(1@3)
•模糊查询字段nickname#hyperchain#
•等于字段attributeordinary
sort用于对查询结果排序,由字段 顺序组成:
•时间顺序, create_time desc, id asc
■解析参数
当接收到前端请求后,我们通过统一的语法解析器工具,对所有的请求我们会将它处理成一个统一的预定义模型,它将解析所有查询的参数,构建成一个统一的中间查询模型,后端会对请求参数校验解析并过滤完成分页,过滤排序条件的提取如下:
假设一次http请求携带的参数如下
start=1&size=10&filter=namehyperchain,type(1@2)&sort=createTime desc
1)解析器先对 start 和 size 校验 ,若为空则设定为默认值;
2)将 sort=createTime desc 解析为排序列和排序关系;
3)对 filter 语法进行解析,对字符串分隔成 namehyperchain 和 type(1@2),再进行正则匹配是否符合格式,符合后通过正则捕获组提取字段、筛选关系和条件;

■列处理
上述方案会可能会存在以下问题
请求表的列名与前端耦合性强中,携带 filter 会暴露数据库的表结构;
无法对前端可筛选的内容做限制;
筛选的条件可能与数据库的数据不同,例如vaildatetrue 条件为true,数据库可能用 int表示;
因此针对上述问题,需另行引入一个基于列名的处理器:
type queryInfo {
start int
size int
order []Order
filter []Filter
mapping map[string]MappingFunc
}
type MappingFunc func(colum string,value string) (mappingC, mappingV string)
在生成 filter 数组时,会根据列名在 mapping 中执行相对应的 MappingFun,将对应的条件和值转为期望的数据,如果未在mapping中查找到对应的数据,则不会加入 filter 数组。
■orm框架生成
在项目中根据不同技术选型,可选用不同的orm框架,因此需要生成器将解析后的参数转换为相应的orm框架语法。
基于前面的查询模型,我们实现了不同的适配器,数据库的底层差异由orm框架自身来实现,而生成器只需要调用orm框架的方法将解析后的数据做为参数调用,在生成器中 start ,size 可以变更 limit(start - 1, size*start),filter解析后的语法直接转成对应where,in条件,同时可以在生成器中插入相关的业务逻辑,如鉴权参数组成的where 条件。
总结
在BaaS系统中,往往会频繁查询各类列表,通过上述实践方案,可显著减少前后端之间的沟通成本,不仅赋予了前端一定的灵活性,还可以提高接口的复用性,把后端从筛选分页的重复代码中释放出来,聚焦于更多核心业务的研发。