06 Python高阶
上节分享了 Python 的基础编程知识,本节分享 Python 的高阶编程知识。
在开发测试框架的过程中,经常会碰见这样的困惑:
- 我仅仅想运行带着某些特定标签的测试用例,但是我不知道具体哪些用例带着这些标签,我该怎么做?
- 我想给我的每一个函数都增加个打印功能,但是我又不想改动函数本身,该怎么做?
- 我想让测试框架根据用户输入,做出不同的处理反应,但是我的输入不是一成不变的,我输入的参数多一些或者少一些,框架就报错了,该怎么办?
这些问题看起来是一个个不同的业务需求,但它们的背后,其实对应着 Python 语言中的一个个高阶编程技巧。
这些技巧,就好比是绝世武功中的内功心法和武功秘籍, 所谓“万丈高楼平地起”,掌握这些高阶技巧,有助开发出更优秀的测试框架。下面我们就一起来看一看,Python 中的这些内功心法有哪些?
表达式(List Comprehension)
俗话说“人生苦短,我用 Python”,Python 为了简化程序的代码行数做了很多努力,其中最经典的就是列表表达式。比如我有如下函数,用来输出一个单词中的所有字符:
def output_letter(letter):
l = []
for item in letter:
l.append(item)
return l
if __name__ == "__main__":
print(output_letter('kevin'))
#此方法的输出为:
['k', 'e', 'v', 'i', 'n]
Python 觉得这样写代码行数太多了,不优雅,于是有了如下的写法:
[expression for item in list]
对应于我们的函数就变成了:
def output_letter(letter):
return [l for l in letter]
if __name__ == "__main__":
print(output_letter('kevin'))
#此方法的输出为:
['k', 'e', 'v', 'i', 'n']
是不是瞬间少了很多代码,逻辑也更清晰?不仅如此,Python 还允许我们在列表表达式中进行判断。
[expression for item in list if xxx else yyy]
例如我有一个列表,里面包括多个字符,我希望返回那些包含字母 k 的字符。
def output_letter(letter):
return [l for l in letter if 'k' in l]
if __name__ == "__main__":
print(output_letter(['kevin', 'did', 'automation', 'well']))
列表表达式可以使我们的函数非常简洁易懂,并且减少代码量。
匿名函数(lambda)
除了列表表达式可以减少代码量以外,Python 中还提供了匿名函数,当你的函数逻辑非常少时,你无须再定义一个函数,可采用匿名函数来减少代码量。匿名函数的语法如下:
lambda arguments : expression
举例来说,我们有一个函数,用来得出列表中的每一个元素的平方,正常的写法是这样的:
def square(l):
square_list = []
for ele in l:
square_list.append(ele * ele)
return square_list
if __name__ == "__main__":
print(square([1, 2, 3, 4]))
匿名函数大大地减少了代码工作量,但是也会让代码的可读性降低,所以通常逻辑不复杂的函数,可以考虑使用匿名函数。
自省/反射(Reflection)
在编程中,自省是一种在运行时查找有关对象的信息的能力;而反射则更进一步,它使对象能够在运行时进行修改。自省和反射是 Python 中非常重要的概念,我们可以通过自省和反射来实现很多高级功能,例如动态查找待运行测试用例。自省最经典的用法就是查看对象类型。
1.type
#返回对象类型
type(obj)
比如:
>>> type(7)
<class 'int'>
>>> type(2.0)
<class 'float'>
>>> type(int)
<class 'type'>
type() 函数的返回值,我们称为类型对象,类型对象告诉我们参数属于哪种类对象实例。如上文所示,解释器便在告诉我们整数 7 属于 int 类,2.0 属于 float 类,而 int 属于类类型。
type() 常常跟函数isinstance() 配合使用,用来检测一个变量是否是我们需要的类型:
#下述例子判断给定的数字是否整型(int类)
x = 6
if isinstance(x, int):
print('I am int')
#你的逻辑
自省还有以下其他几种用法。
2.dir
dir() 可以用来获取当前模块的属性列表,也可以获取指定一个属性。
if __name__ == "__main__":
my_list = [1, 2, 3]
print(dir(my_list))
print(dir(my_list).__class__)
比如我们运行上述代码,则会有如下结果。
#第一个print返回
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
#第二个print返回
<class 'list'>
3. id
id() 函数返回对象的唯一标识符。
if __name__ == "__main__":
name = "kevin"
print(id(name))
#输出
140245720259120
4.inspect
inspect 模块提供了一些有用的函数帮助获取对象的信息,例如模块、类、方法、函数、回溯、帧对象,以及代码对象。
例如它可以帮助你检查类的内容,获取某个方法的源代码,取得并格式化某个函数的参数列表,或者获取你需要显示的回溯的详细信息。
inspect 有很多函数,我以一个实际例子为依托,介绍常用的几种。假设现在我们有个项目,它的文件结构是这样的:
testProject
--|tests
--|__init__.py
--|test1.py
--|test2.py
其中,test1.py 的内容如下:
import inspect
from tests.test2 import hello
class KevinTest():
def __init__(self):
print('i am kevin cai')
def say_hello(self, name):
hello()
return 'Hello {name}'.format(name=name)
test2.py 内容如下:
def hello():
print('hello from test2')
inspect.getmodulename
inspect.getmodulename(path) 用来获取指定路径下的 module 名。
# 在test1.py中新增如下代码。
if __name__ == "__main__":
#此打印语句输出test1。 即当前模块名是test1
print(inspect.getmodulename(__file__))
inspect.getmodule
inspect.getmodule(object) 用来返回 object 定义在哪个 module 中。
# 在test1.py中新增如下代码。
if __name__ == "__main__":
#此语句输出inspect.getfile
inspect.getfile(object) 用来返回 object 定义在哪个 file 中。
# 在test1.py中新增如下代码。
if __name__ == "__main__"
test = KevinTest()
#此语句输出/Users/kevin/automation/testProjectPython/tests/test1.py
print(inspect.getfile(test.say_hello))
inspect.getmembers
inspect.getmembers(object) 用来返回 object 的所有成员列表(为 (name, value) 的形式)。
# 在test1.py中新增如下代码。
if __name__ == "__main__":
test = KevinTest()
#此语句输出test里的所有是方法的成员变量。输出是一个列表
#[('__init__', >), ('say_hello', >)]
print(inspect.getmembers(test, inspect.ismethod))
闭包(closure)
闭包是一个概念,是指在能够读取其他函数内部变量的函数。这个定义比较抽象,我们来看一段代码:
def outer():
cheer = 'hello '
def inner(name):
return cheer + name
return inner
if __name__ == "__main__":
#输出hello kevin
print(outer()('kevin'))
以上代码的意思如下:我定义了一个外部函数 outer 和一个内部函数 inner;在外部函数 outer 内部,我又定义了一个局部变量 cheer(并给定初始值为hello);然后我在内部函数 inner 里引用了这个局部变量 cheer。最后 outer 函数的返回值是 inner 函数本身。
在本例的调用里,outer 函数接受了两个参数,第一个参数为空,第二个参数为 kevin。那么outer() 的返回值就是 inner。所以 outer()(‘kevin’) 的返回值就是 inner(‘kevin’)。
为了方便你理解,我贴出这个函数的运行过程:
- 当代码运行时,首先执行的是入口函数,即第 8 行代码,接着是第 10 行代码。
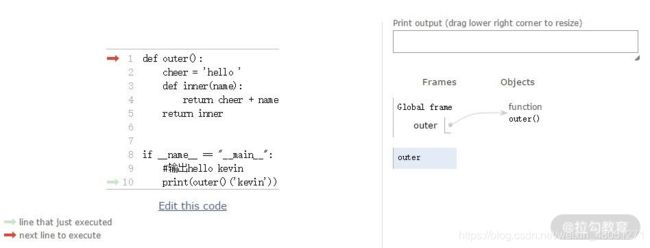
- 继续向后执行,就会进入到第 1 行代码,即 outer() 函数内部;接着第 2
行代码开始执行,变量cheer被定义,并且赋值为“hello”;接着第 3 行代码开始运行,需要注意的是,第 3
行代码执行完,并不会执行第 4 行代码,而是执行第 5 行代码。

- 第 5 行代码执行完毕后,outer() 函数的整个生命周期就已经结束了,继续往后执行:

可以看到,代码进入了 inner 函数内部,而且 inner 函数内部可以访问生命周期已经结束的 outer 函数的成员变量 cheer,这个就是闭包的魔力。
最后,inner 函数继续执行,outer 函数里定义的 cheer 被取出,并且连同 name 一起返回。我们就获得到了函数的最终结果“hello kevin”。

了解了闭包如何起作用的,我来总结下闭包的特点。
闭包的特点:
- 在一个外部函数里定义一个内部函数,且内部函数里包含对外部函数的访问(即使外部函数生命周期结束后,内部函数仍然可以访问外部函数变量);
- 外部函数的返回值是内部函数本身。
“闭包”这个概念非常重要,除了在 Python 中,闭包在 JavaScript、Go、PHP 等许多语言中都有广泛的应用。
而闭包在 Python 中的经典应用就是装饰器,而装饰器使 Python 代码能够夹带很多“私货”,下面我们就来看下装饰器的应用。
装饰器(decorator)
装饰器是闭包的一个经典应用。装饰器(decorator)在 python 中用来扩展原函数的功能,目的是在不改变原来函数代码的情况下,给函数增加新的功能。
1.实现装饰器
在我们的测试框架开发中,装饰器非常重要,它可以给函数添加 log 且不影响函数本身。
假设我们有一个函数 sum,作用是用来计算 N 个数字的和:
def sum(*kwargs):
total = 0
for ele in kwargs:
total = total + ele
return total
现在,我们加了需求,需要记录这个函数开始的时间和结束的时间。
正常情况下,我们的代码是这样的:
import time
def sum(*kwargs):
print('function start at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
total = 0
for ele in kwargs:
total = total + ele
print('function end at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
return total
if __name__ == "__main__":
print(sum(1,2,3,4))
后来,我们发现这个记录函数开始和结束时间的功能很好用,我们要求把这个功能加到每一个运行函数中去。
那么怎么办呢?难道要每一个函数都去加这样的代码吗? 这样一点也不符合我们在前几节说的代码规范原则。
所以我们来稍做改变,把计算的函数sum的函数单独抽取出来不变,把时间处理的语句另行定义函数处理。于是上面的函数,就变成了以下的样子:
import time
def sum(*kwargs):
total = 0
for ele in kwargs:
total = total + ele
return total
def record_time(*kwargs):
print('function start at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
total = sum(*kwargs)
print('function end at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
return total
if __name__ == "__main__":
sum(1,2,3,4)
以后我们再给函数加有关时间处理的功能,加到 record_time 里好了,而 sum 函数根本不用变。那这个函数还能更加简化吗?
结合我们刚刚讲过的闭包概念,我们用外函数和内函数来替换下:
record_time就相当于我刚刚讲的outer函数,wrapper函数就是inner函数,只不过我们的inner函数的入参是个函数,这样我们就实现了对函数本身功能的装饰。
import time
# 这个是外函数
def record_time(func):
def wrapper(*kwargs):
print('function start at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
total = func(*kwargs)
print('function end at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
return total
return wrapper
# 这个是我们真正的功能函数
def sum(*kwargs):
total = 0
for ele in kwargs:
total = total + ele
time.sleep(2)
return total
if __name__ == "__main__":
# 外函数,内函数,和功能函数一起,实现了不改变功能函数的前提下,给功能函数加功能的操作。
print(record_time(sum)(1,2,3,4))
运行一下,测试结果为:
function start at 2020-08-14 01:06:49
function end at 2020-08-14 01:06:49
10
假设我们的需求又变化啦,我们现在不统计函数的运行开始和结束时间了,改成统计函数的运行时长了,那么我们只需要改 record_time 这个函数就好了,而我们的功能函数 sum 就无须再改了,这样是不是方便了很多?
有了装饰器,我们可以在不改变原有函数代码的前提下,增加、改变原有函数的功能。这种方式也被称作“切面编程”,实际上,装饰器正是切面编程的最佳释例。
2.语法糖
不过你发现没,我们的调用仍然很麻烦,record_time(sum)(1,2,3,4)的调用方式,不容易让使用者理解我们这个函数是在做什么,于是 Python 中为了让大家写起来方便,给了装饰器一个语法糖,其用法如下:
@decorator
#对应我们的例子就是
@record_time
使用语法糖后,在调用函数时,我们就无须再写这个装饰器函数了,转而直接写我们的功能函数就可以了,于是我们的例子就变成了:
import time
def record_time(func):
print('function start at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
def wrapper(*kwargs):
return func(*kwargs)
print('function end at {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ))
return wrapper
#注意这一行,我们把record_time这个函数装饰到sum函数上。
@record_time
def sum(*kwargs):
total = 0
for ele in kwargs:
total = total + ele
return total
if __name__ == "__main__":
#注意此次无须再写record_time了,这样有利于大家把关注点放在功能函数本身。
print(sum(1,2,3,4))
有了装饰器,我们就可以做很多额外的工作,例如插入日志、做事务处理等,在后续再分享如何利用装饰器给测试用例打标签。
总结
本小节介绍了 Python 的一些常用高阶技巧,这些技巧有的是单纯地帮助减少代码量,有的可以动态地获取某些对象的属性并进行判断,有些则可以帮助扩展原本函数所有的功能。