数据挖掘专栏三-Python-消费者人群画像信用智能评分
报告和代码都放gitthub上了,github仓库地址:https://github.com/gamblerInCoding/PortraitPython
文章目录
- 实验名称
- 数据集说明
-
- 数据集名称
- 数据集来源
- 数据集介绍
- 数据集字段说明
- 实验环境
- 实验步骤
- 实验过程
-
- 数据集探索
-
- 数据集获取和读入
- pandas读取数据性能优化
- 数据集基本信息
- 数据预处理
-
- 重复值处理
- 缺失值处理
- dask框架并行加速计算
- 基于dask框架和正则表达式的异常值处理
- 无用值处理
- 离群点处理-基于异常检测模型
- 数据校验
-
- 训练集-反应变量分布分析
- 训练集-解释变量分布分析
- 训练集和测试集数据分布一致性判断-基于对抗验证
- 训练集和测试集数据合并
- 对测试集和训练集进行分类-基于LightGBM算法模型
- 分类效果评价-基于ROC曲线的AUC值
- 数据集划分方法-基于LightGBM算法模型的概率结果
- 数据可视化探索
- 特征工程
-
- 特征创造-基于聚类算法
- 特征创造-基于实际场景
- 特征过滤
- 特征标准化
- XGBoost算法模型构建
-
- 数据集划分
- 模型初步建模
- 模型初步建模效果评估-LightGBM选取和随机选取测试集的比较
- 模型初步建模效果评估-样本数据量对结果的影响
- 使用Embedded嵌入法确定threshold参数
- 构建学习曲线调节参数
-
- n_estimators参数
- subsample参数
- learning_rate参数
- booster参数
- max_depth参数
- colsample_bytree参数
- 学习曲线调参效果分析
- 随机搜索优化参数-Randomized SearchCV
- 网格搜索优化参数-Grid SearchCV
- 网络调参效果分析
- 总结反思
实验名称
消费者人群画像-信用智能评分
数据集说明
数据集名称
消费者人群画像-信用智能评分数据集
数据集来源
https://www.datafountain.cn/competitions/337/datasets
数据集介绍
数据的原始来源是中国移动福建公司提供2018年某月份的样本数据(脱敏),包括客户的各类通信支出、欠费情况、出行情况、消费场所、社交、个人兴趣等丰富的多维度数据。该数据集包含了2个csv文件,train_dataset.csv文件和test_dataset.csv文件。其中train_dataset.csv文件是用来给我们提供训练机器学习算法模型的原始数据文件,包含了某月中各个用户的上网行为信息及其信用评价的分数。数据集大小为5.43MB。整个数据集有50000条记录,用户编码,用户实名制是否通过核实,用户年龄,是否大学生落户,是否黑名单落户,是否4G不健康客户,用户网龄,用户最近一次缴费距今时长,缴费用户最近一次缴费金额,用户近6个月平均消费话费,用户账单当月总费用,用户当月账户余额,缴费用户当前是否欠费缴费,用户话费敏感度等30个特征,其中信用分作为反应变量,其他29个特征作为解释变量,在解释特征中有一个用来标识不同用户上网行为记录的编码。每条记录都由这30个字段组成,代表着一名用户在该月的行为特征及其获得的信用分数。
数据集字段说明
数据集的字段说明如下表所示。
| 序号 | 字段名 | 含义 |
|---|---|---|
| 1 | 用户编码 | 数值 唯一性 |
| 2 | 用户实名制是否通过核实 | 1为是0为否 |
| 3 | 用户年龄 | 数值 |
| 4 | 是否大学生客户 | 1为是0为否 |
| 5 | 是否黑名单客户 | 1为是0为否 |
| 6 | 是否4G不健康客户 | 1为是0为否 |
| 7 | 用户网龄(月 | 数值 |
| 8 | 用户最近一次缴费距今时长(月) | 数值 |
| 9 | 缴费用户最近一次缴费金额(元) | 数值 |
| 10 | 用户近6个月平均消费话费(元) | 数值 |
| 11 | 用户账单当月总费用(元) | 数值 |
| 12 | 用户当月账户余额(元) | 数值 |
| 13 | 缴费用户当前是否欠费缴费 | 1为是0为否 |
| 14 | 用户话费敏感度 | 用户话费敏感度一级表示敏感等级最大 |
| 15 | 当月通话交往圈人数 | 数值 |
| 16 | 是否经常逛商场的人 | 1为是0为否 |
| 17 | 近三个月月均商场出现次数 | 数值 |
| 18 | 当月是否逛过福州仓山万达 | 1为是0为否 |
| 19 | 当月是否到过福州山姆会员店 | 1为是0为否 |
| 20 | 当月是否看电影 | 1为是0为否 |
| 21 | 当月是否景点游览 | 1为是0为否 |
| 22 | 当月是否体育场馆消费 | 1为是0为否 |
| 23 | 当月网购类应用使用次数 | 1为是0为否 |
| 24 | 当月物流快递类应用使用次数 | 数值 |
| 25 | 当月金融理财类应用使用总次数 | 数值 |
| 26 | 当月视频播放类应用使用次数 | 数值 |
| 27 | 当月飞机类应用使用次数 | 数值 |
| 28 | 当月火车类应用使用次数 | 数值 |
| 29 | 当月旅游资讯类应用使用次数 | 数值 |
| 30 | 信用分 | 数值 |
实验环境
操作系统:Windows 10
编译环境:Jupyter Notebook 5.6.0
语言:Python 3.7.9
科学库:Numpy 1.19.2
Pandas 1.3.4
Matplotlib 2.2.3
Seaborn 0.9.0
Sklearn 1.0.1
Scipy 1.6.2
Xgboost 1.4.2
Dask 2021.10.0
实验步骤

实验过程
数据集探索
数据集获取和读入
我在DataFountain平台上寻找到用于用户上网异常行为预测的数据集UEBA异常行为分析数据集,数据集来源网址:https://www.datafountain.cn/competitions/337/datasets。由于元素数据集的文件是csv文件,文件名是train_dataset.csv,另外由于该文件的编码是gbk,所以通过pandas库的read_csv方法读取原始数据到train_set中,编码参数使用read_csv这个方法的默认参数能直接将数据读取进来。
train_set = pd.read_csv('train_dataset.csv')
pandas读取数据性能优化
Pandas是进行机器学习算法的常见的库,我们使用Pandas可以进行快速读取数据、分析数据、构造特征。但Pandas在进行操作时候如果处理的好可以提高运行效率,降低代码运行时间和节省内存空间。在上一小节中,我们不加处理的直接使用read_csv方法读取了原始数据,读取进来的数据存进dataframe格式的数据。我们可以使用train_set.info()方法来查看该dataframe的信息,我们可以发现该dataframe使用了11.4MB的内存,但是我们的原始数据集train_dataset.csv总共才5.43MB。

我们从csv文件读取dataframe时,它文件的大小扩大了一倍,这个时候浪费了空间,这在工业界是不能接受的,一个10个TB的文件读进来需要耗费20个TB的存储空间。进一步观察train_set的信息可以发现该dataframe各个字段的数据类型,如果该字段的数据是数值类型的,对应的数据类型不是int64就是float64。但是64位的精度远远大于我们获得的原始数据集中的数据的精度,我们实际上并不需要使用这么大的精度来表示我们数据集中的数据精度。所以对于类似0-1判断的特征字段,不需要使用64位的数据类型。只需要使用8位或者16位的数据类型就性了,这个时候这个dataframe就能省下大量无用的内存空间。
所以我们应该指定每个数值类型字段的数据类型。比如说用户网龄可以指定数据类型为int32,用户年龄为int16,是否黑名单客户为int8,是否4g不健康客户为int8,是否大学生客户int8,用户实名制是否通过核实为int8等。

 我们可以看出指定字段数据精度后,数据集消耗的内存空间开销为5.1MB,已经比原始数据集train_dataset.csv的大小相比没指定字段数据精度之前数据集消耗的内存空间开销11.4MB,数据集消耗的内存空间压缩了55.26%,这个提升是十分巨大的。对于十几MB的数据集,这个效果可能并不显著。但是如果数据集的大小达到GB级别时,没有压缩的数据集可能压根都读取不进来。而且通过压缩数据集的大小也能提升dataframe读取数据的速度。
我们可以看出指定字段数据精度后,数据集消耗的内存空间开销为5.1MB,已经比原始数据集train_dataset.csv的大小相比没指定字段数据精度之前数据集消耗的内存空间开销11.4MB,数据集消耗的内存空间压缩了55.26%,这个提升是十分巨大的。对于十几MB的数据集,这个效果可能并不显著。但是如果数据集的大小达到GB级别时,没有压缩的数据集可能压根都读取不进来。而且通过压缩数据集的大小也能提升dataframe读取数据的速度。
数据集基本信息
Pandas库中提供了skew函数和kurt函数可以用来查看原始数据的偏度和峰度。偏度Skewness是描述数据分布形态的统计量,其描述的是某总体取值分布的对称性,简单来说就是数据的不对称程度。峰度Kurtosis是描述某变量所有取值分布形态陡缓程度的统计量,简单来说就是数据分布顶的尖锐程度。


由上面的结果我们可以看出信用分这个反应变量的字段数据的偏度是-0.863670,说明信用分在低分段会出现长尾巴,在低分段部份会出现很多数据偏低的极端值。相比于用户当月账户余额等字段来说,它的偏度的绝对值更接近0,说明它的形状更像正态分布。而它的峰度是0.551228,说明信用分的字段数据相比于正态分布更加尖锐。由于连续型变量类型的数据的峰度和偏度都过高,可能数据并不符合正态分布,所以应该要对连续型变量数据进行正态分布检验。
Pandas库中提供describe函数可以用来初步探寻数据集的特征,所以通过使用train_set.describe(),我们可以得出来数据集的基本特征。
 从结果中我们可以得到作为反应变量的用户信用智能评分的信用分数值是618.053060,最大值是719,最低值是422,50%的信用分数小于627。数据的分布符合用来训练机器学习模型的特征,不需要进行特征重采样,所以数据可以直接用来建立机器学习的算法模型。
从结果中我们可以得到作为反应变量的用户信用智能评分的信用分数值是618.053060,最大值是719,最低值是422,50%的信用分数小于627。数据的分布符合用来训练机器学习模型的特征,不需要进行特征重采样,所以数据可以直接用来建立机器学习的算法模型。
数据预处理
重复值处理
在数据集中,由于把用来唯一标识不同用户行为信息的用户编码特征删除掉了,所以可能出现某些条记录中所有特征的数据完全一样的情况,这将导致在后续的数据分析和建模的过程中产生异常,影响数据分析结论的可靠性和正确性,为了规避由于存在重复值而产生的问题,在数据预处理阶段也需要对重复值进行处理。通过model_train.duplicated()能找到当前model_train所有每个字段都一样的记录。
train_df[train_df.duplicated().values].index
缺失值处理
Pandas库中提供isnull函数可以用来生成所有数据的true/false矩阵。其中元素为空或者NA时对应元素就显示为true,否则显示为false。而sum函数可以用来获取所请求轴的值之和,所以通过调用train_set.isnull().sum(),我们可以得到原始数据集中每一个特征下的缺失值的个数之和。

我们通过观察得到的结果可以知道原始数据集每一列都不存在缺失值,我们不需要进行缺失值的处理,填补或者删除缺失值。
dask框架并行加速计算
dask是一种分布式集群系统,支持pandas、numpy、sklearn、xgboost等机器学习的科学库的主流api,由于python GIL的限制,运用多线程时,在同一时刻,只能有一个线程在执行,导致了运用多线程并不会使程序运行速度明显加快,反而由于线程之间的数据传输实现效果并不好。通常在调用模型进行计算时,能控制n_jobs参数为-1,就能使得在跑算法模型时成功调用所有cpu的核心。但是在对numpy和pandas这些科学库对象进行操作时不能控制调用所有cpu核心,这个时候使用dask框架就能加速计算,调用cpu的所有核心。
除此之外,dask具有延时计算的能力,它还能用于优化计算的动态任务调度和大数据集合,如并行数组、数据帧和列表,它能将NumPy、Pandas或Python迭代器等常见接口扩展到比内存大的环境或分布式环境,这些环境运行在动态任务调度程序之上。使得它能在本地处理它能处理的最大内存的能力。

基于dask框架和正则表达式的异常值处理
由于部份字段的数据是形式比较复杂的数值型数据。例如用户年龄字段对应的是1-120的正整数,如果该字段的数据是特殊字符或者是字符串,或者该年龄字段的数据不是1-120的正整数,则该字段就是异常值。所以这个时候如果字段出现异常值时不好直接观测到,这个时候检测异常值更好地办法是通过使用正则表达式对train_df(train_df是由上一节对应的dask读取的数据)对应字段的字符串进行模式匹配,判断是否有不符合条件的字符串存在。
对年龄格式进行模式匹配的正则表达式为:
(^([1-9]\d?|1[01]\d|140)$)
通过函数getlistmask函数能够得到用户年龄字段索引不符合正则表达式的字符串取值,其中先通过调用re包的compiled方法将正则表达式字符串转化为对象再进行模式匹配,能够比直接通过正则表达式字符串进行模式匹配具有更高的效率。
def getlistmask(li):
L=[]
mask=0
rule_age=r"(^([1-9]\d?|1[01]\d|140)$)"
compiled_rule=re.compile(rule_age)
lx = list(li)
for i in lx:
if compiled_rule.match((str)(i)) is not None:
mask=mask
else:
Mask=mask+1
L.append(i)
return L
调用getlistmask函数发现该字段的异常值数量为290,异常的用户年龄字段数据为0。

在统计数据异常值的时候我使用了dask计算框架。首先是导入原始数据,dask支持替换主流的pandas的API接口。
import dask.dataframe as dd
train_df = dd.read_csv('train_dataset.csv')
函数使用的是上面可以直接支持pandas的函数。下面的代码是在dask框架下执行函数的过程。delayed标签是将该计算任务放入计算图中,在dask框架下该任务就变成准备执行的状态,再调用compute命令,就能智能调度所有cpu的核心执行计算任务。
number_age_mk = delayed(getlistmaskip)(train_df['用户年龄'])
number_age_number = number_age_mk.compute()
print('年龄异常值:',number_age_number)
由于年龄描述的用户的现实特征,如果改变了用户的现实特征不合理,而且年龄为0的用户数量不多。所以直接将年龄为0的用户记录全部去除就行了。使用loc函数,里面的条件是年龄字段数据大于0。
model_train = model_train.loc[model_train['用户年龄']>0]
train_df = train_df.loc[train_df['用户年龄']>0]
无用值处理
通过观察数据发现,用户编码特征只是用来唯一标识不同的用户的一个主键,只为了用来区分不同的用户,并不具有实际意义。通过del可以直接删去model_train中的该字段的数据。
离群点处理-基于异常检测模型
根据下一节进行数据分布校验时可以知道一些连续型的特征字段的数据大致满足正态分布。在这种情况下如何检测连续型的特征字段的异常值,通常情况下我们是使用箱型图或者散点图观察数据点的分布情况,查看是否有一些数据点偏离集中的数据点。但是这种方法还是有一定缺陷的,在这里我建立了一种异常检测的数学模型。离群点的数值相对于正常点的数据的数值会发生巨大的变化,而数据数值发生了极大的变化可以使用那组数据的方差变大来表示。当我们原始数据分割成两组数据,此时两组数据的方差和应该是将原始数据任意划分成两组数据后的两组数据方差和中最小的。
以检测指标偏大值为例,在检测指标异常数值的过程中,我们首先先得到原始数据,然后调用numpy库提供的argsort函数得到升序排序后的原数组索引所在的位置的数组。然后按照原数组将数据集拆分成两组,计算两组数据的方差和。当两组数据的方差和取到最小值时说明此时两组数据内部的方差和是最小的,而两组数据之间的差异是非常大的。即偏高的那组数据是指标异常数值,偏低的那组数据是正常值。并在原始数据集里对相应的数据打上标签,即0或者1,1代表指标数据为异常值,0代表指标数据为正常值。
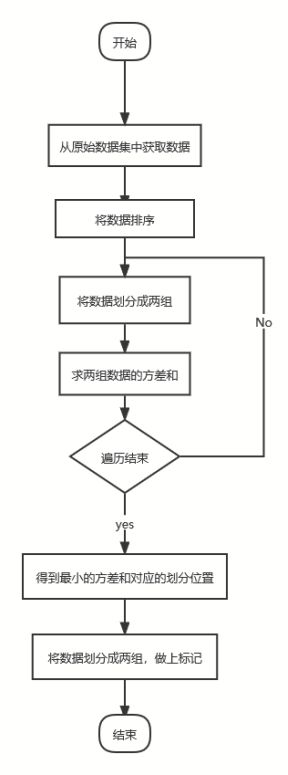
进行异常检测算法的代码如下所示。对数据进行排序可以使用numpy库中提供的argsort方法,argsort方法能将原数组进行排序,并返回排序后的原数组元素对应的索引。而求方差能直接调用numpy库的std方法。
arr = np.argsort(radio)
for g in range(1,len(arrg)):
sk = np.std(arrg[arr[0:g]])+np.std(arrg[arr[g:len(arr)]])
if(min>=sk):
min = sk;
minmark = g
result1=[]
数据校验
训练集-反应变量分布分析
通过观察数据信用分可能具有正态分布的特性,我对信用分的分布情况进行了正态分布的检验。通过代码作出信用分的正态分布曲线和对应的回归拟合的图像情况。通过以下代码可以做出信用分和置信度在0.5时,对应的正态分布拟合的曲线。这个分布较为合理,所以不需要对训练集数据进行重采样。
target.hist(bins=30,alpha = 0.5,ax = ax2)
target.plot(kind = 'kde', secondary_y=True,ax = ax2)

训练集-解释变量分布分析
我接下来对用户近6个月平均消费值,当月网购类应用使用次数,用户账单当月总费用等指标进行了正态分布分析。通过作出来的图,我们可以发现用户近6个月平均消费值和用户账单当月总费用所作出的条形图更接近于对应的正态分布曲线。而当月网购类应用使用次数的条形图低于对应的正态分布曲线图较多,说明它不能简单地看成正态分布。


训练集和测试集数据分布一致性判断-基于对抗验证
工业界有一个大家公认的看法,“数据和特征决定了机器学习项目的上限,而算法只是尽可能地逼近这个上限”。在实战中,特征工程几乎需要一半以上的时间,是很重要的一个部分。缺失值处理、异常值处理、数据标准化、不平衡等问题是比较明显地问题,但是还有一个问题需要特别注意-数据一致性。在本节中我使用了对抗验证的方法去检验训练集和测试集的数据分布是否一致。
对抗验证并不是一种评估模型效果的方法,而是一种用来确认测试集和训练集的分布是否变化的方法。它的思路是:构建一个分类器去分类测试集和训练集,如果模型能清楚分类测试集和训练集,说明测试集和训练集存在明显区别,否则反之。具体步骤如下:
1.测试集和训练集合并,同时新增标签‘Is_Test’去标记训练集样本为0,测试集样本为1。
2.构建分类器去训练混合后的数据集,可采用交叉验证的方式,拟合目标标签‘Is_Test’。
3.输出交叉验证中最优的AUC分数。AUC越大(越接近1),越说明训练集和测试集分布不一致。
训练集和测试集数据合并
test_dui = pd.read_csv('test_dataset.csv')
train_dui = pd.read_csv('train_dataset.csv')
del(train_dui['信用分'])
test_dui['Is_Test']=1
train_dui['Is_Test']=0
duikang = test_dui.append(train_dui)
duikang=duikang.reset_index()
del(duikang['index'])
对测试集和训练集进行分类-基于LightGBM算法模型
对测试集和训练集进行分类-基于LightGBM算法模型LightGBM和XGBoost一样是对GBDT的高效实现,原理上它和GBDT及XGBoost类似,都采用损失函数的负梯度作为当前决策树的残差近似值,去拟合新的决策树。LightGBM的算法参数的选择如下所示:


分类效果评价-基于ROC曲线的AUC值
如果我们用ROC曲线来评估分类器的分类质量,我们就可以通过计算AUC,即ROC曲线下的面积来评估分类器的质量,ROC的值越高说明分类器的效果越好。通常认为AUC值大于0.7时,LightGBM具有良好的分类效果,即训练集和测试集间的数据分布差异较大。
 由于在交叉验证折数确定的情况下,本问题中LightGBM算法得到的分类器的分类效果AUC均值的分类效果都大于0.7,说明本题提供的训练集和测试集数据分布情况有较大差别。
由于在交叉验证折数确定的情况下,本问题中LightGBM算法得到的分类器的分类效果AUC均值的分类效果都大于0.7,说明本题提供的训练集和测试集数据分布情况有较大差别。
数据集划分方法-基于LightGBM算法模型的概率结果
根据之前的结果我们可以分析出题目给的数据集的验证集和测试集的数据分布差距过大,如果直接随机选取数据进行交叉验证,在测试集上模型预测的效果将会过低,所以我们在跑模型算法之前应该要改变训练集和测试集的划分方法,不再使用交叉验证法划分测试集和训练集。当我们进行对抗验证时,模型预测样本是预测集的概率。概率越高,则说明和验证集越相似。所以我们选用训练集中和测试集样本越相似的样本作为模型挑参的测试集。
通过对抗验证中的模型,得到各个样本属于测试集的概率:
lgb_model.fit(df_adv.drop('Is_Test', axis=1), df_adv.loc[:, 'Is_Test'])
preds_adv = lgb_model.predict_proba(df_adv.drop('Is_Test', axis=1))[:, 1]
只需要训练样本的概率:
df_train_copy = train_dui.copy()
df_train_copy['is_test_prob'] = preds_adv[:len(train_dui)]
根据概率排序:
df_train_copy = df_train_copy.sort_values('is_test_prob').reset_index(drop=True)
将概率最大的20%作为测试集:
df_validation_2 = df_train_copy.iloc[int(0.8 * len(train_dui)):, ]
df_train_2 = df_train_copy.iloc[:int(0.8 * len(train_dui)), ]
结果导出:
df_validation_2.to_csv("model_test.csv")
df_train_2.to_csv("model_train.csv")
数据可视化探索
本部分内容页数过多就不放在这里了,在gitthub上有详细的过程。
特征工程
特征创造-基于聚类算法
在我看来,聚类算法的本质在于依据样本的特征将具有相类似特征的样本都尽量划到同一类里,而同时也能保证同一类里的样本都具有了非常类似的特征。聚类算法可以说是相当于把一堆无监督的数据打上标签的算法。所以聚类算法可以用来特征升维或者特征降维。在这个问题中,我对0-1的是否型变量进行特征创造。在不同维度上的数据将对应的单维度的字段特征进行数据相乘,相乘后的数据如果是1,代表原来的两条记录是在这几个特征字段的高维特征上是一样的,即高维特征对应的低维特征同时具备。这样生成的高维特征数据能代表很多低维数据特征字段并不具备的特征。进行特征创造的代码如下所示:

特征创造-基于实际场景
在本问题中根据有些关于欠费和账单的特征能进行符合实际生活场景的特征创造,生成新的特征。
对于缴费用户最近一次缴费金额和用户近6个月平均消费值这两个特征。我的理解是对于用户来说,如果用户缴纳的费用比用户账单金额高,说明该用户收入水平比较高足以付清该用户的账单。所以进行特征创造的时候可以使用缴费用户最近一次缴费金额减去用户近6个月平均消费值作为一个新的特征字段用来代表用户的收入水平支付当月消费的账单的能力,这个值是正数代表用户该月收入足以偿还当月的账单,这个值如果是负数代表用户该月的收入不足以偿还当月消费的账单。而且这个只越大代表用户偿还账单的能力越强,可以反映出该用户的信用情况是越好的。
上面的特征创造我们是基于用户的收入和花销间的关系,除此之外我们可以考虑用户的花销本身。如果用户的花销越来越小,说明用户违约的可能性也越来越小。基于次我考虑使用用户账单当月总费用减去用户近6个月平均消费值作为一个新的特征字段用来代表用户花销的变化情况。这个值越小代表用户的花销的变化情况是越来越小的。
进行特征创造的代码如下所示:
really_train['缴费金额是否能覆盖当月账单'] = really_train['缴费用户最近一次缴费金额(元)'] - really_train['用户近6个月平均消费值(元)']
really_train['当月账单是否超过平均消费额'] = really_train['用户账单当月总费用(元)'] - really_train['用户近6个月平均消费值(元)']
特征过滤
我们已经知道用户编码特征只是用来唯一标识不同的用户的一个主键,只用来区分不同的用户,并不具有实际意义。通过del可以直接删去really_train中的该字段的数据。
特征标准化
在本次机器学习的项目中构建的是XGBoost模型,该模型对于数据没有任何先验要求,不需要数据集具有任何特殊的结构,所以不需要对该数据集进行数据标准化。
XGBoost算法模型构建
数据集划分
我在之前的6.3节中探讨了训练集和测试集的数据分布,通过使用以LightGBM模型为基础的对抗验证方法,我们发现训练集和测试集之间的数据分布差距过大。所以我们在模型构建时不考虑使用随机选取测试集的方法,而是使用以LightGBM模型结果为基础的选取测试集的方法,即选择和测试集相似程度最高的20%的训练集中的数据作为调整参数的测试集。然后将信用分特征字段作为反应变量,除了信用分特征字段的其他字段作为解释变量。但是之前在进行对抗验证实现训练集和测试集的数据检验时,对于提取出来的数据删除了训练集的反应字段特征信用分,所以应该在之前的代码位置把信用分字段拼接回去,从而使得数据集不会发生字段缺失的错误。
train_dui = train_dui.join(add_train_dui)
然后对数据集进行划分,划分成训练集反应变量,训练集解释变量,测试集反应变量,测试集解释变量。
划分后各个数据集的形状如下:
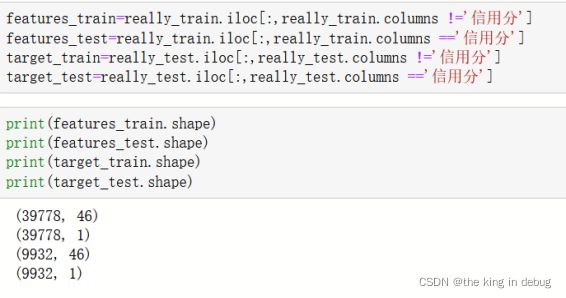
为了实现使用对抗验证方法处理数据集和使用交叉验证的方法处理数据集时对模型处理效果的比较。所以我还对模型同样进行了交叉验证。将数据集中的20%作为测试集,80%作为训练集。通过调用sklearn库中的model_selection提供的train_test_split函数来实现划分数据集的功能。此时所有的数据预处理已经进行完成,直接划分数据集就能保证测试集和训练集都经过了所有操作完全相同的数据预处理。将信用分字段作为目标变量,除了信用分字段的其他字段作为自变量。划分数据集的代码如下:
from sklearn.model_selection import train_test_split
qfeatures = jiaocha.iloc[:,jiaocha.columns !='信用分']
qtarget = jiaocha.iloc[:,jiaocha.columns =='信用分']
qfeatures_train,qfeatures_test,qtarget_train,qtarget_test=train_test_split(qfeatures,qtarget,test_size=0.20)print(features_train.shape)
模型初步建模
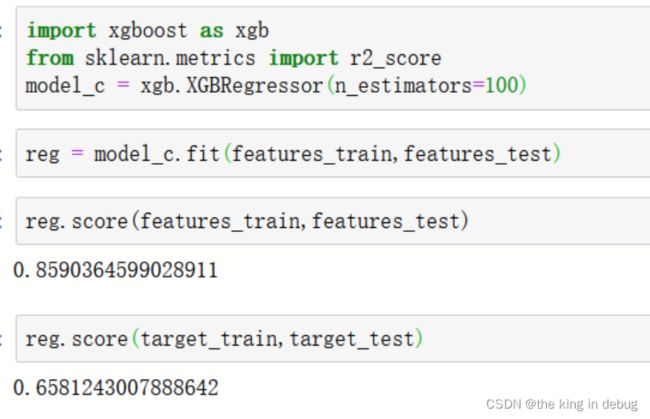
在建立XGBoost模型之前,需要进行导库的操作。首先,我们这个数据集是回归的数据集,因此需要在安装完XGBoost库后导入XGBRegressor类。然后设置n_estimators为100,其他参数都不设置使用默认的原始参数数据进行初步建模。
import xgboost as xgb
from sklearn.metrics import r2_score
model_c = xgb.XGBRegressor(n_estimators=100)
reg = model_c.fit(features_train,features_test)
reg.score(features_train,features_test)
reg.score(target_train,target_test)
XGBoost库提供了对应的方法plot_importance可以让我们查看训练好的模型的特征的重要性。因为原始特征有40多个,在这里我选择了在图中只显示重要性前10的特征。
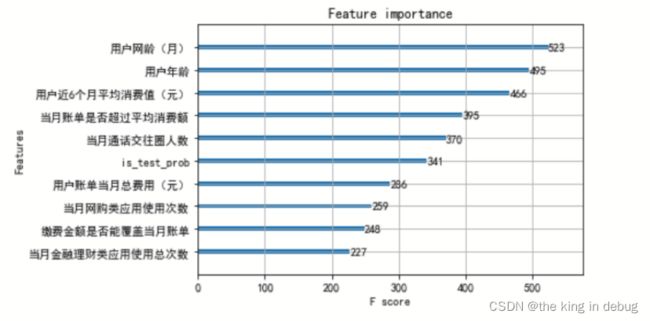 模型初步建模跑出的结果如下所示,在训练集上模型表现的效果比较好准确率为0.85,但是在测试集上模型的效果只有0.65,这说明模型针对预测集预测的效果可能会较差。
模型初步建模跑出的结果如下所示,在训练集上模型表现的效果比较好准确率为0.85,但是在测试集上模型的效果只有0.65,这说明模型针对预测集预测的效果可能会较差。
模型初步建模效果评估-LightGBM选取和随机选取测试集的比较
随机选取测试集并对测试集进行评价时只能评价模型针对一般情况下的泛化能力,并不能针对具体实际的案例场景,这种评价方式并不适合具体的案例场景。接下来我使用随机选取测试集的方式进行模型的初步构建并与之前进行对抗验证选取的测试集的方式进行对比,说明随机划分训练集和测试集针对模型的泛化能力的评价作用远远不如对抗验证划分测试集的效果显著。进行随机选取时建立的模型也是设置n_estimators为100。
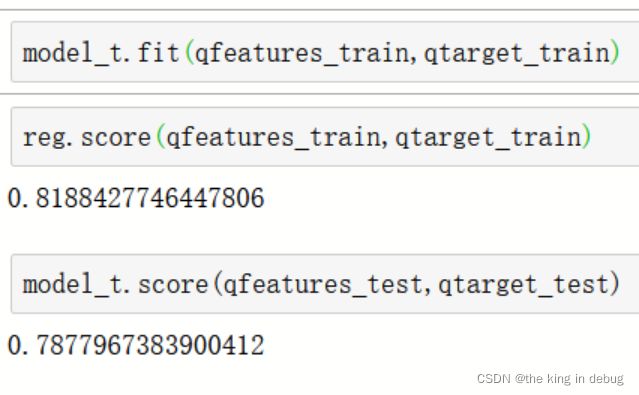
模型初步建模跑出的结果如下所示,在训练集上模型表现的效果一般准确率为0.81,但是在测试集上模型的效果居然比之前高很多有0.78。,说明模型针对不同案例场景的泛化能力是非常强悍的。这和之前使用对抗验证的方法对模型在训练集上的预测效果和在测试集上评估的模型泛化能力差别很大。对抗验证的模型在训练集上准确率有0.85,在测试集上只有0.65,说明模型的泛化能力是比较弱小的。这是因为本案例场景中的训练集和预测集数据分布差距过大。如果使用随机选取测试集后,这种数据分布的差距会被多次重复实验中和训练集分布一致的数据给稀释掉。
模型初步建模效果评估-样本数据量对结果的影响
在之前的节中我先初步建立了XGBoost模型,并探讨了随机选取测试集和使用LightGBM算法选取测试集对模型的预测效果和模型对于测试集上预测的泛化能力的影响。接下来我研究了训练集数据的选取对于模型效果的影响。我在训练集中选取了不同数量的训练数据来训练模型,观察模型的准确率是如何变化的。代码如下所示:
for i in range(5000,len(features_train),5000):
samples.append(i)
feat_train=features_train.iloc[:int(i),]
feat_test=features_test.iloc[:int(i),]
reg = model_c.fit(feat_train,feat_test)
xunlian.append(reg.score(feat_train,feat_test))
ceshi.append(reg.score(target_train,target_test))
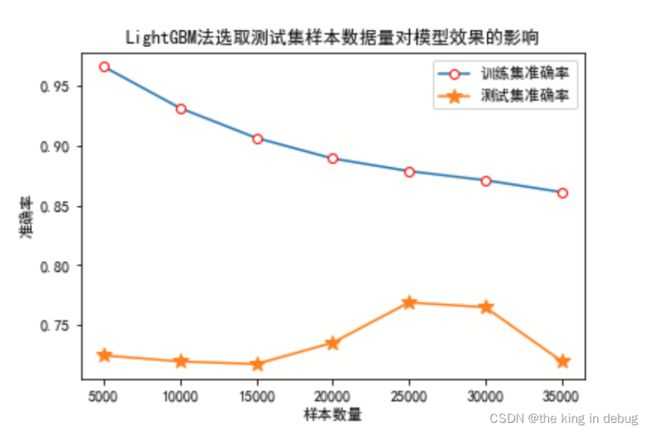
我们可以对使用LightGBM算法确定模型测试集的情况下的模型的训练集分数和测试集分数进行分析,发现随着样本数的提升,测试集的分数是先小幅度下降然后大幅度提升然后再下降,而训练集的分数在下降。测试集分数能大幅度提升说明了模型在随着样本数的提升,过拟合的程度在有所改善。测试集分数的下降可能是因为测试集数据分布特殊性导致的。
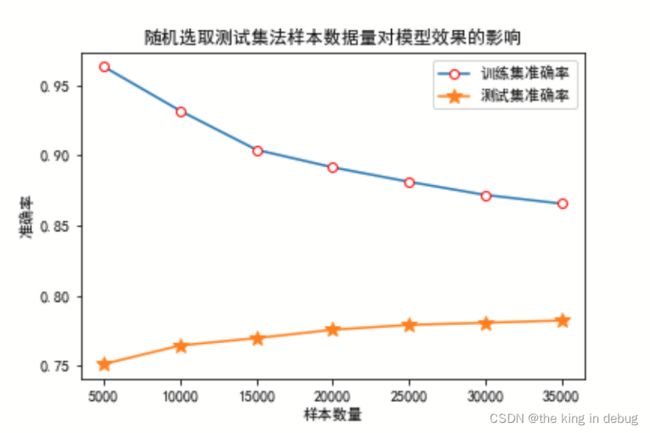
我作出了随机选取测试集法测试集分数和数据集大小的关系图,在这个图中随着样本数量的增加模型在测试集上的准确率是一直上升的,而此时训练集上的准确率是一直在下降的,这证实随着样本数量增加模型过拟合的现象是一直在减轻的。但是这只是一个模型泛化能力粗放的衡量标准。因为具体数据中的数据分布不确定,所以才会在图39中在测试集里准确率呈现出先下降后上升再下降的变化趋势。
使用Embedded嵌入法确定threshold参数
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。
对于如何选取合适的特征这个问题,传统的过滤法只能通过机械地分析原始数据集的数据分布特征,如方差来淘汰一些特征所含信息熵小的字段。而通过调用SelectFromModel方法能自动地在算法训练过程中选择出贡献大于阈值的特征进行模型训练。然后我们可以通过绘制学习曲线的方式来获得threshold对应的最佳参数。
通过使用SelectFromModel方法,我们能够实现使用Embedded嵌入法进行特征选择的功能,将原始特征按照特征的重要性重新选择新的特征。接下来直接使用新生成的特征就能进行XGBoost算法。
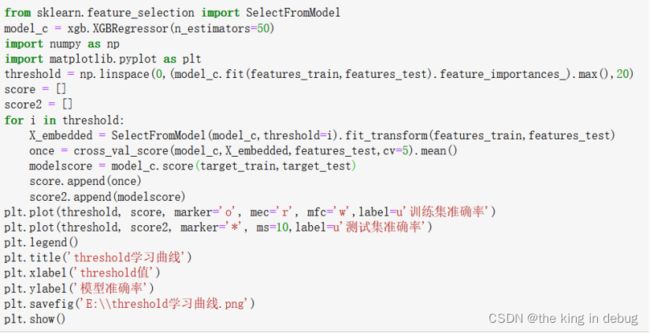
执行上述代码能够得到粗放的threshlod学习曲线图,如下图所示。但是由于模型准确率最高值位于取值区间的端点,所以应该在端点附近进一步作出细化的threshlod学习曲线图。

将上述学习曲线的范围缩小,作出细化的threshold学习曲线图如下所示。

通过上图绘制出的threshold的细化的学习曲线可以发现threshold的最佳取值应该是为0,即不进行特征选择的时候模型的预测效果是最好的。根据这个结果我们可以知道不应该使用Embedded进行特征选择等其他降维方法,因为使用降维方法后模型在训练集和预测集上的准确性反而会下降,每个特征都对于结果来讲是有意义的。
构建学习曲线调节参数
XGBoost本身的核心是基于梯度提升树实现的集成算法,整体来说可以有三个核心部分:集成算法本身,用于集成的弱评估器,以及应用中的其他过程。所以我们进行调参时应该也要关注这几方面。集成算法本身应该关注弱评估器的数量n_estimators、控制随机抽样的subsample、控制迭代数率的learning_rate等参数,而用于集成的弱评估器应该关注选择弱评估器的booster、目标函数objective、单棵树的max_depth、min_child_weight、colsample_bytree、控制正则化参数的gamma等。
n_estimators参数
n_estimators参数代表集成算法中弱评估器的数量,弱评估器的数量越多用来预测的效果就会越好。不过n_estimators参数设的太大,模型的学习能力会更强,这容易导致过拟合现象的发生,n_estimators参数设的太小,模型的学习能力较弱,容易导致欠拟合现象的发生。我们可以通过绘制学习曲线的方式来获得n_estimators对应的最佳参数。对n_estimators参数进行10到90,以10为间隔的方式进行初步调参的代码如下所示。其中随机种子参数设置为100。
n_estimators参数初步调参绘制出来的学习曲线如下所示。
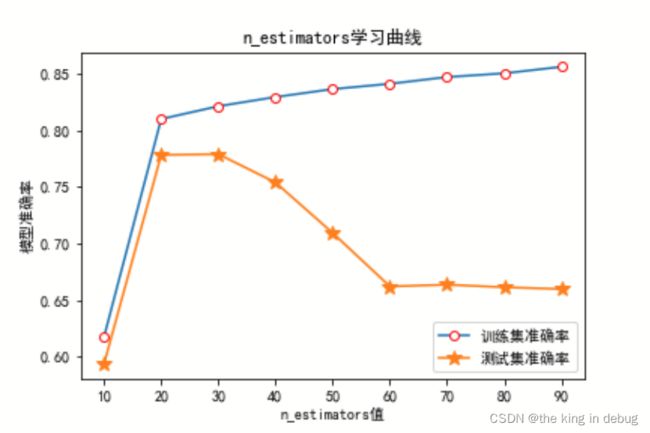
由图可知最佳的n_estimators取值应该在20附近。进下来对n_estimators参数进行10到20,以1为间隔的方式进行详细调参。
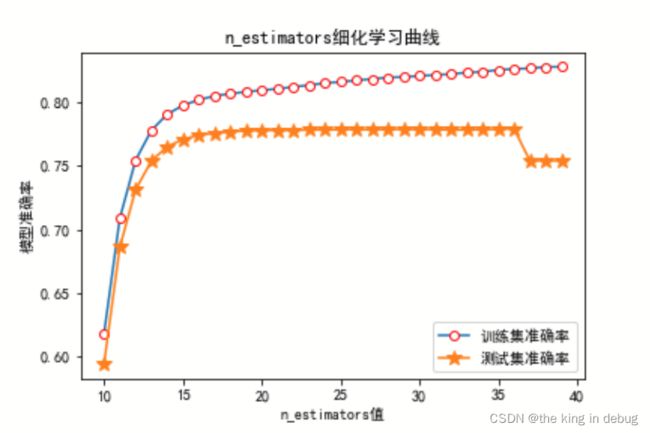 n_estimators详细调参的结果如下所示。
n_estimators详细调参的结果如下所示。
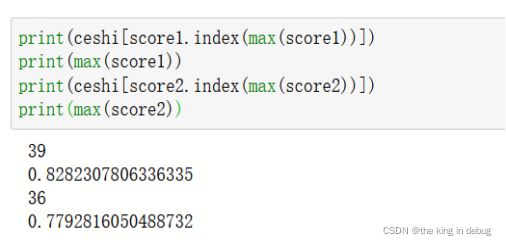
通过上图绘制出的n_estimators详细学习曲线和结果可以得到n_estimators最佳的取值是36。一方面n_estimators超过36以后模型的准确率在测试集上由断崖式下降。另一方面n_estimators不到36以前模型的准确率都在不断提升,而由于弱评估器的增加使得计算成本增加的速度不是特别快。所以n_estimators的最佳取值是36。
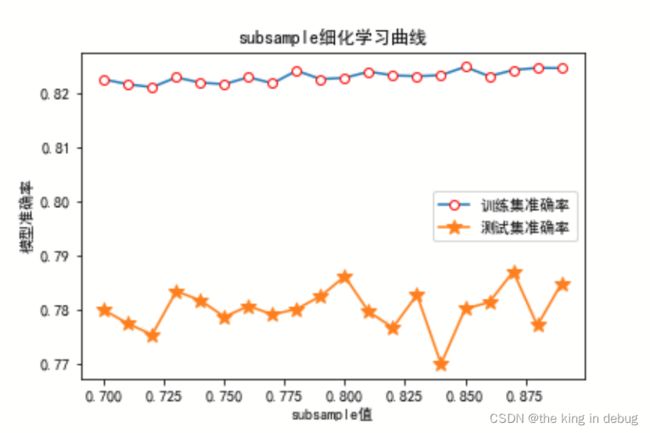
subsample参数
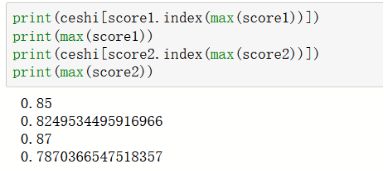
subsample参数代表随机抽样时抽取样本的比例。对模型来说,数据量越少模型学习越容易,学到的规则也会越具体越不适用于测试样本。所以subsample参数通常是在样本量本身很大的时候来调整和使用。我们可以通过绘制学习曲线的方式来获得subsample对应的最佳参数。对subsample参数进行0.1到1,以0.1为间隔的方式进行初步调参的代码如下所示。其中随机种子参数设置为100,n_estimators设置为36。


learning_rate参数
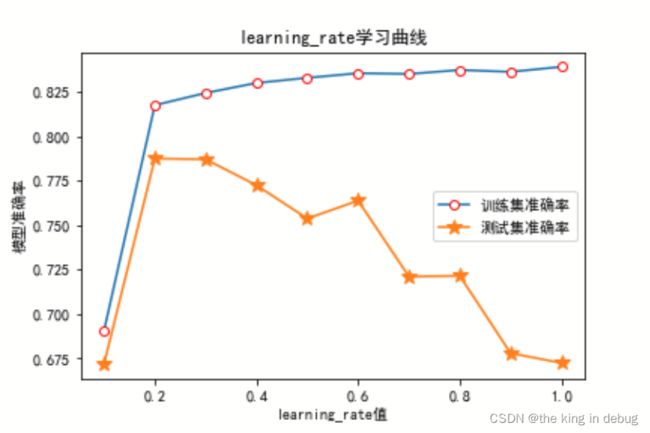
learing_rate参数代表集成算法中的学习率,又称为步长。以控制迭代速率,常用于防止过拟合。和逻辑回归类似,集成算法中的学习率越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳值。集成算法中的学习率越小,越有可能找到更精确的最佳值。但是更多的空间被留给了后面建立的弱评估器,但迭代速度会比较缓慢。对learing_rate参数进行0.1到1,以0.1为间隔的方式进行初步调参的代码如下所示。其中随机种子参数设置为100,n_estimators设置为36,subsample设置为0.87。



booster参数
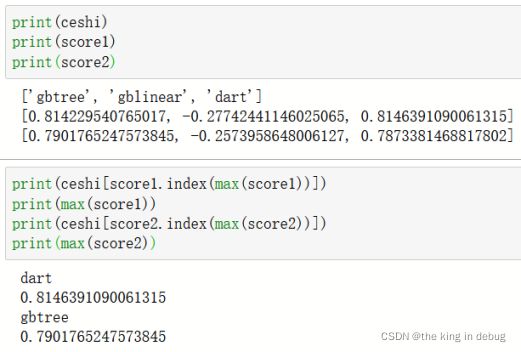
梯度提升算法中不只有梯度提升树,XGBoost算法作为梯度提升算法的进化,自然也不只有树模型一种弱评估器。在XGBoost算法中,除了树模型,我们还可以选用线性模型,比如线性回归,来进行集成。虽然主流的XGB依然是树模型,但我们也可以使用其他的模型。基于XGBoost算法的这种性质,我们有参数“booster"来控制我们究竟使用怎样的弱评估器。对booster参数调参的代码如下所示。其中随机种子参数设置为100,n_estimators设置为36,subsample设置为0.87,learning_rate设置为0.17。

max_depth参数
在上面我们研究了集成算法中对应集成过程的各个参数,接下来我们开始研究集成算法中带有的弱评估器本身的参数。max_depth是树模型中用得最广泛的剪枝参数,在高维度低样本量时非常有效。可以用来限制集成算法中每棵树模型的最大深度,超过设定深度的树枝全部剪掉。因为树模型多生长一层,对样本量的需求会增加一倍,所以树深度过于高时容易导致发生过拟合现象。实验中固定XGBooster的随机种子参数设置为100,n_estimators设置为36,subsample设置为0.87,learning_rate设置为0.17,booster设置为’gbtree’,obective设置为‘reg:linear’。对max_depth参数进行1到51,以10为间隔的方式进行初步调参的代码如下所示。




colsample_bytree参数
实验中固定XGBooster的随机种子参数设置为100,n_estimators设置为36,subsample设置为0.87,learning_rate设置为0.17,booster设置为’gbtree’,obective设置为‘reg:linear’,max_depth固定为6,min_samples_leaf固定为1,min_samples_leaf固定为1,gamma参数固定为28,min_child_weight固定为42。对colsample_bytree参数进行0.1到1,以0.1为间隔的方式进行初步调参的代码如下所示。

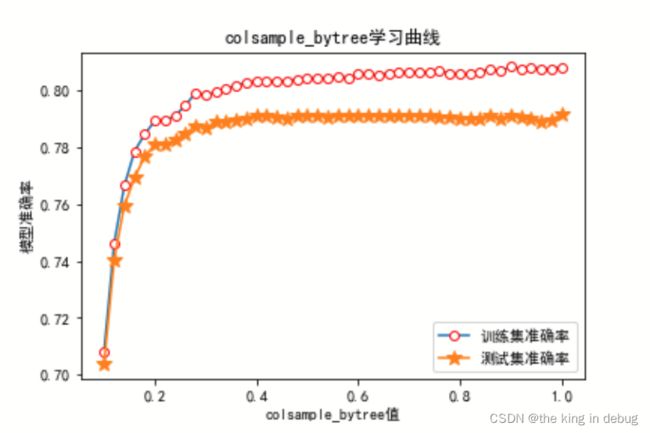

学习曲线调参效果分析
我们之前使用控制变量法按照顺序对模型的参数进下了一个个地调整,获得了模型的最优解所对应的模型各个参数,在测试集上模型最高的得分为0.7917518968980318。这个时候XGBoost模型各个参数如下表所示。

我对通过使用学习曲线法调参的过程进行了总结分析,对于调参过程,不同的参数对于模型准确率的影响是差别非常大的,有些参数对于模型的准确率影响微乎其微,有些参数可能模型默认的参数就是最适合的参数,而有些参数调参以后可能模型的准确率会发生巨大的变化。对于集成算法XGBoost来说,它的参数主要可以分为3类,一类参数是用来决定弱评估器本身的性质特征的参数,如max_depth,一类参数是用来决定弱评估器集成模型的过程的参数,如n_estimators,还有一类参数是用来控制算法模型过拟合的程度,如gamma。下面作出来的模型准确率随时间变化关系的折线图。
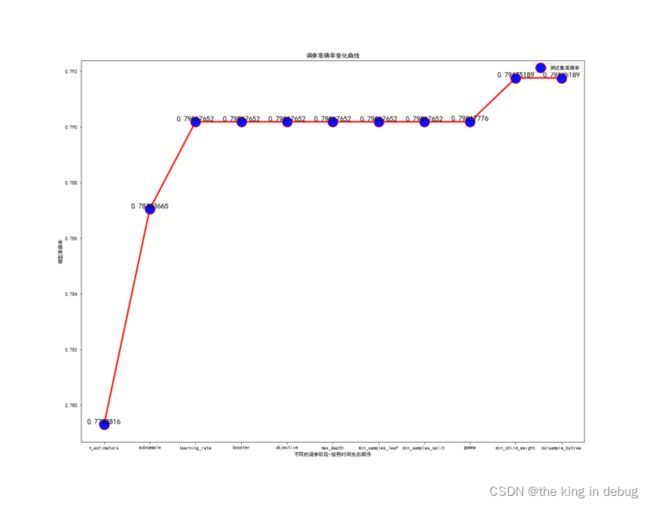
通过折线图我们可以看出来调整n_estimators、subsample等对应集成算法的过程的参数对于提升模型的准确率有很大的帮助。而调整对应弱评估器本身性质的参数,如max_depth等几乎不改变模型准确率,说明弱评估器本身默认的参数已经优化的足够好了,模型参数对应的模型准确率已经是最优的了。
随机搜索优化参数-Randomized SearchCV
在之前使用学习曲线调整参数中分别对各个参数进行遍历求解时,每个参数都是独立出来看的,考虑一个参数时就不考虑其他的参数了,这可以看作是逐步修正的固定变量法。这样求出来的每个参数在当前情况下是最优解,但是如果再考虑当前步骤之后的参数时可能就不是全局最优解了。所以同时遍历模型各个参数获得模型的最优解时更可靠的方法。首先我使用了随机搜索法来优化模型参数。


网格搜索优化参数-Grid SearchCV
使用随机搜索优化参数的效果并没有比使用控制变量法用学习曲线调整模型参数的效果好,这是十分正常的,因为随机搜索只是使用随机对分布取值,它大概率能逼近函数的最优解,而不能直接得到最优解。接下来我使用了网格搜索法来优化模型参数。


网络调参效果分析
随机搜索和网格搜索都没办法到达使用学习曲线单变量调整模型参数的模型效果的最优解,一方面随即搜索鉴于取参数方法的限制,没办法遍历到参数的每一个取值。另一方面网格搜索由于参数的数量过于大,还有笔记本性能的限制,我只取了部份参数和缩小参数的取值范围来进行网格搜索,这可能是网格搜索没达到最优解的一个原因。
除此之外,通过比较随机搜索和网格搜索,我们可以看出来。随机搜索只需要在15秒内就能实现在百万级参数选择组合上进行5重交叉验证,而网格搜索在45秒内只能进行81钟参数组合的2重交叉验证。但是随机搜索的准确率却比网格搜索的更高。这说明我们不一定非要使用网格搜索法进行验证,随机搜索法也是可以考虑使用的。
总结反思
在本次消费者人群画像-信用值智能评分的项目中,我先进行了正态分布检验和数据分布一致性检验,针对数据分布不一致的问题我通过使用LightGBM算法依据对抗验证的原理实现了数据集的重组,针对正态分布的问题,我建立了异常检测模型。在特征工程中我基于实际场景和聚类算法的原理进行了特征创造。在整个项目流程中,我完整地独立实现了一遍数据挖掘所需要的各个步骤,包括数据集获取,数据一致性检验,数据预处理,数据可视化,特征工程,建立模型,模型优化,模型评价,从而使得我对数据挖掘原理有了更深的理解。对于不同的数据集,要采取适合数据集特点的不同的数据预处理方法和算法模型才能更好地完成目标。通过这次消费者人群画像-信用值智能评分的项目,我对交叉验证、数据分布检验、特征工程和Embedded嵌入法和LightGBM算法以及XGBoost算法模型有了更深的理解和掌握。以及对如何通过使用学习曲线和网格搜索法来寻找最优参数有了更好的掌握。除此之外我对于如何进行模型融合有了初步的理解,在进行模型融合时,要对应用场景有着深刻的理解,自然地将模型融合在一起,而不是简单的堆砌模型。