微信小程序 | 基于ChatGPT实现电影推荐小程序
文章目录
-
- ** 效果预览 **
-
- 1、根据电影明星推荐
- 2、根据兴趣标签推荐
- 3、根据电影名推荐
- 一、需求背景
- 二、项目原理及架构
-
- 2.1 实现原理
-
- (1)根据用户的兴趣标签
- (2)根据关联类似主题的题材
- (3)根据特定的电影明星
- 2.2 技术架构
- 2.3 技术栈
- 三、项目功能的实现
-
- 3.1 小程序端设计与实现
- 3.2 数据后端设计与实现
- 3.3 数据智能获取功能设计与实现
- 四、推荐阅读
** 效果预览 **
1、根据电影明星推荐
2、根据兴趣标签推荐
3、根据电影名推荐
一、需求背景
在我们日常想看电影的时候,经常会遇到一些问题:
1. 闲来无事想看个电影,打开电影列表,感觉都是看过的,一下子不知道该如何去发现新大陆?
2. 喜欢某个演员,想看与他风格类似的电影,可惜电影网站的影片推荐总是那么不尽人意!
3. 在不同的电影网站,填入自己的感兴趣的标签,结果推荐出来的电影题材并不是自己想要的效果!
既然说起推荐系统,这就刚好踩中了我那研究三年推荐系统的读研苦逼时光了。稍微介绍一下时下主流的推荐系统的架构和算法:

这里的大数据推荐系统体系仅为简单的架构模型,其中涉及到更多的计算任务和调度数据流等细节均已省略 【有兴趣的友友可关注后续栏目更新—
带你手把手从零实现推荐系统】
在如此庞大的数据体量和计算引擎的支持下,现如今的推荐系统仍然没有以完美的姿态来解决用户的冷启动问题,所以说时下,推荐系统在学术界的研究已经达到了一种登峰造极的状态,你我都知道可能多引入一些高性能的模型去加强,多跑几轮模型去调参优化,从而实现更美丽的推荐效果!这样我们可能可以得到一篇优秀的论文!但是在工业应用领域,对于推荐算法的优化,新投入的算力跟人工成本,通常并不会由于更准推荐效果从而产生更丰厚的营收,可以说投入跟产出完全不成正比!这对于时下资本退却的互联网来说,这是最要命的!
于是乎,我们可以转换一下思路,有没有什么模型和算法可以实现推荐效果最优化,不惧怕因为用户数据量少而导致的冷启动问题 ------ 那么这个时候ChatGPT获取可以申请一战,他有超海量的全人类用户数据、连续产生内容及记忆理解上下文功能!
好那么,基于此,让我们来用ChatGPT做一个电影推荐小程序! 做一个可以满住你的任意无理要求的电影小程序。
二、项目原理及架构
2.1 实现原理
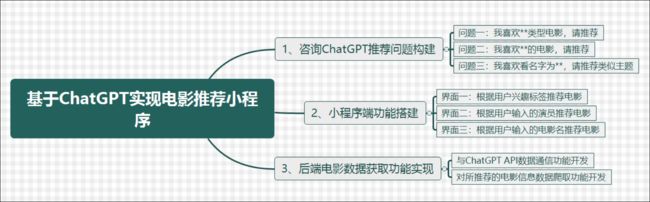
1. 要利用上ChatGPT的推荐功能,首先构造好目标明确的问题是成功的关键。
2. 在获取到GPT的推荐数据之后,我们需要将推荐结果中的电影内容获取并展示在小程序端,这里我们需要采用Python爬虫对豆瓣电影网进行爬取!
这里我们构造了三类推荐类目: 兴趣标签、电影主题、电影明星
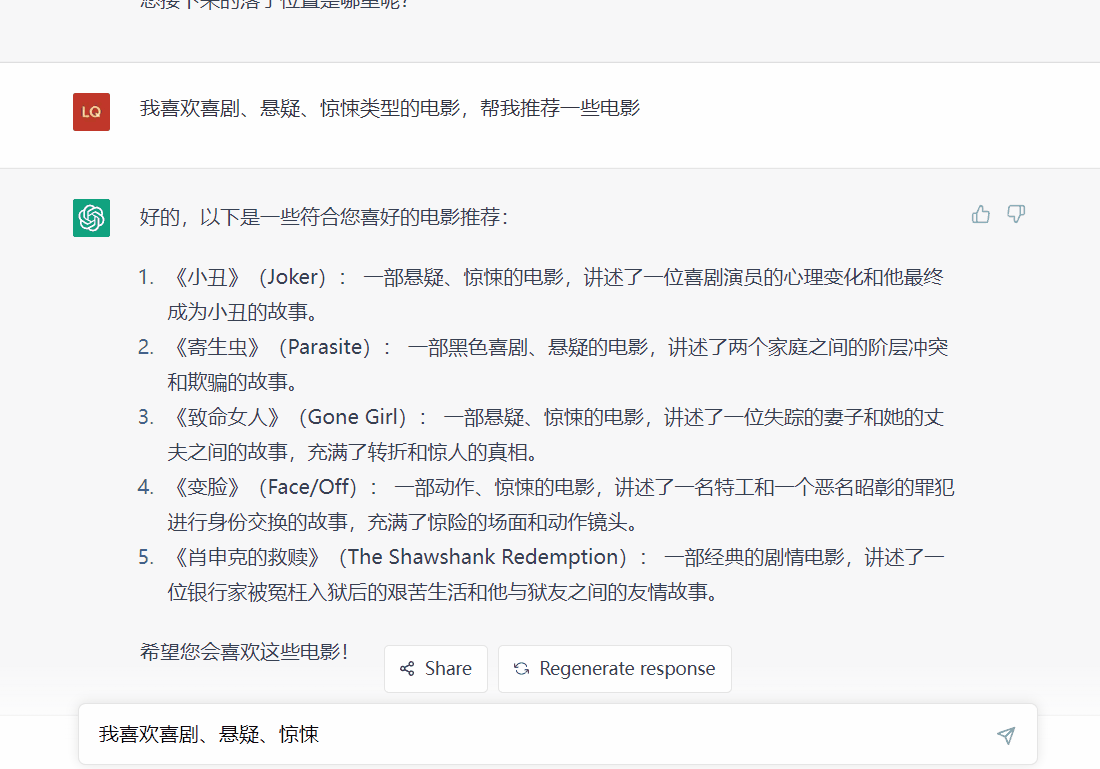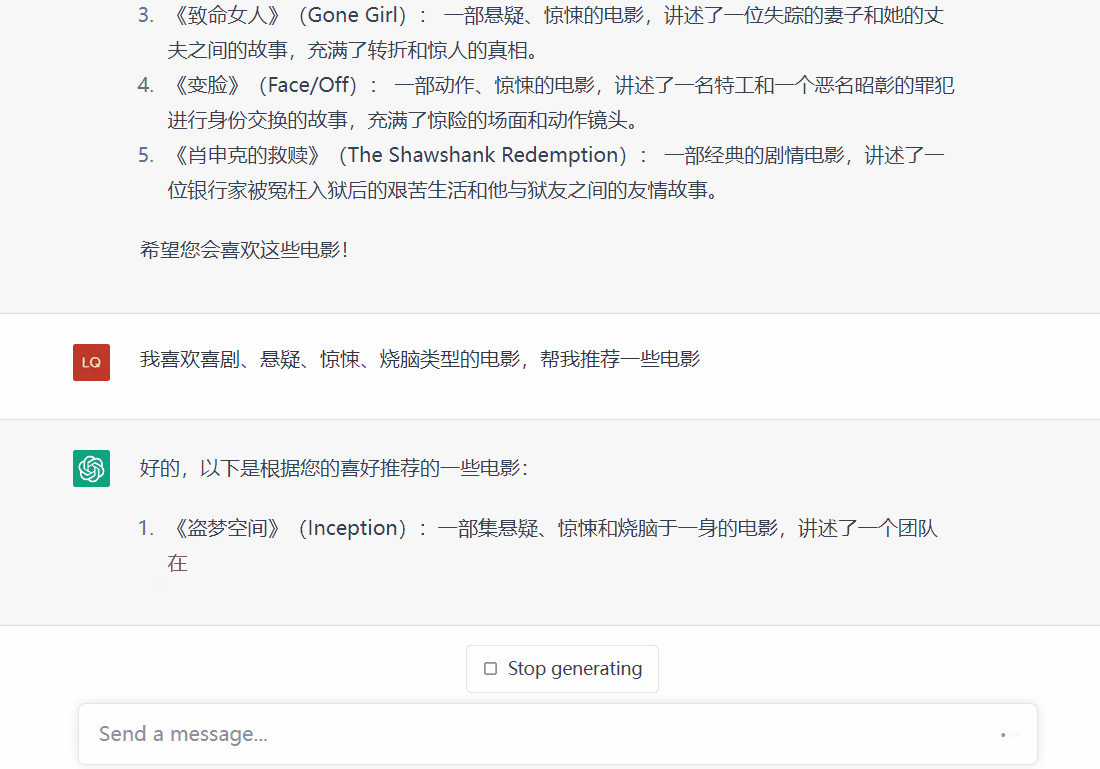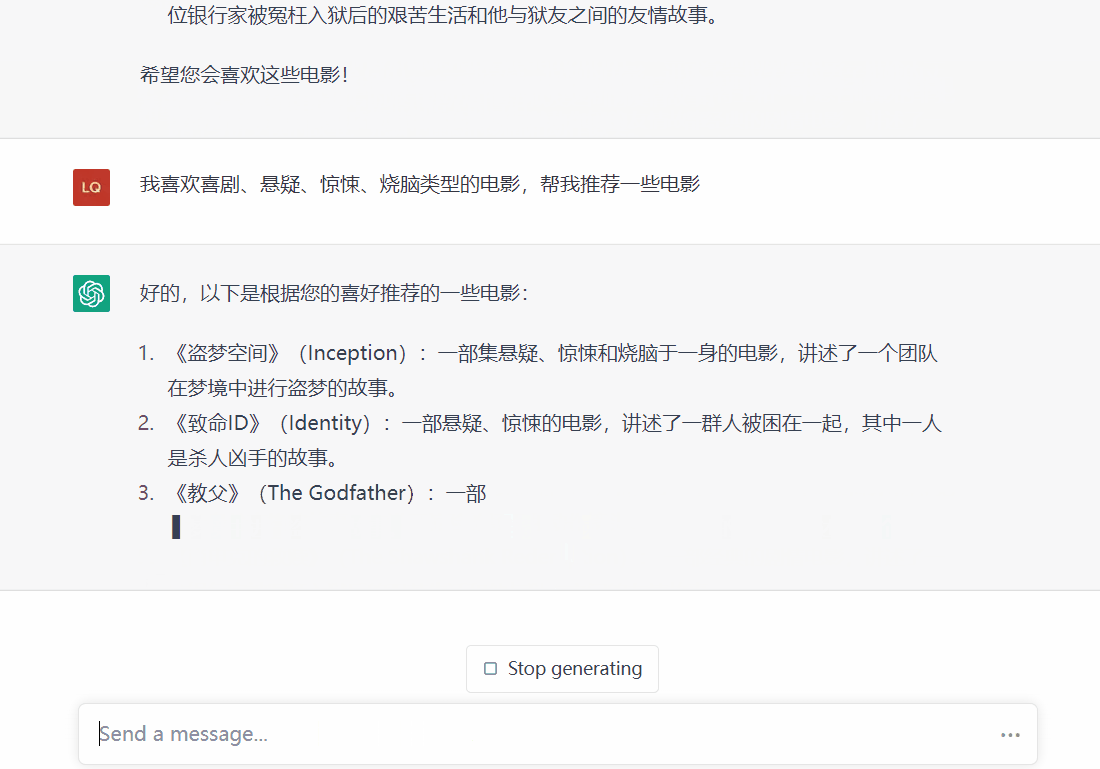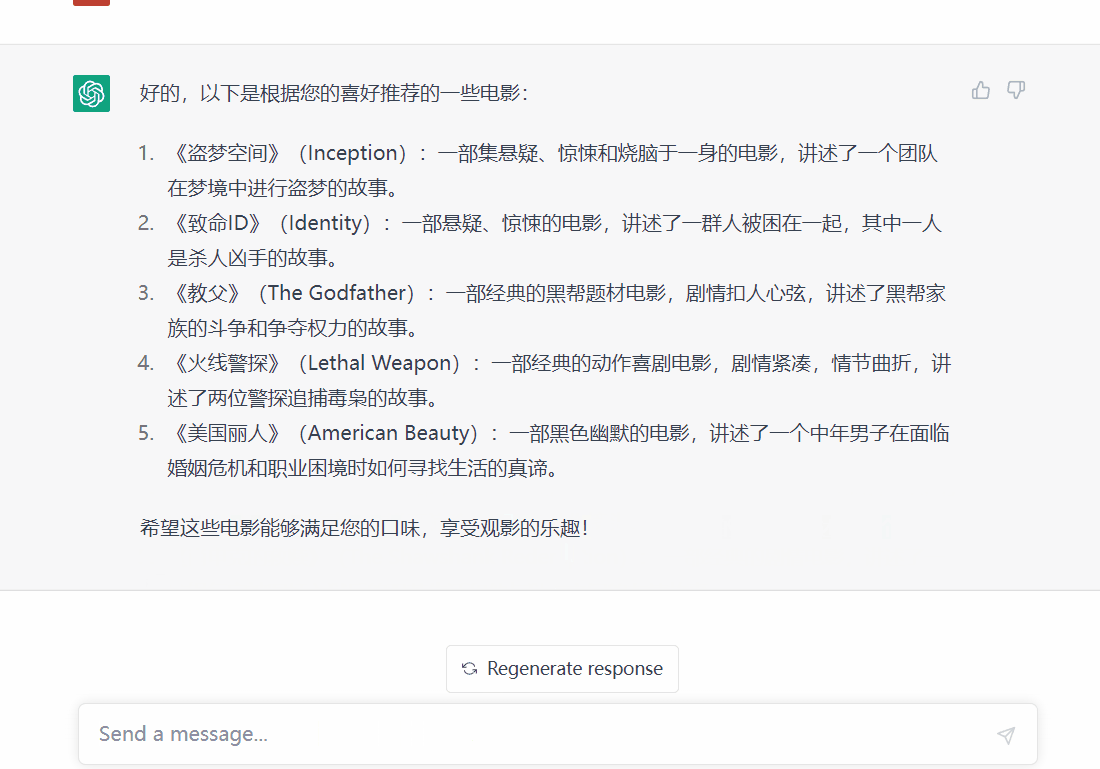
(1)根据用户的兴趣标签
通过用户输入的兴趣标签进行电影的匹配
(2)根据关联类似主题的题材
(3)根据特定的电影明星

2.2 技术架构

2.3 技术栈
| 模块 | 语言及框架 | 涉及的技术要点 |
|---|---|---|
| 小程序前端 | 基于VUE 2.0语法+Uni-app跨平台开发框架 |
Http接口通信、Flex布局方式、uView样式库的使用、JSON数据解析、定时器的使用 |
| 小程序接口服务端 | Python + Flask WEB框架 |
rest接口的开发、 ChatGPT API接口的数据对接 |
| 小程序数据爬虫服务端 | Python + Request 库 |
Xpath路径元素解析、Http请求爬虫 |
三、项目功能的实现
3.1 小程序端设计与实现
| 首页 | 标签选择 |
|---|---|
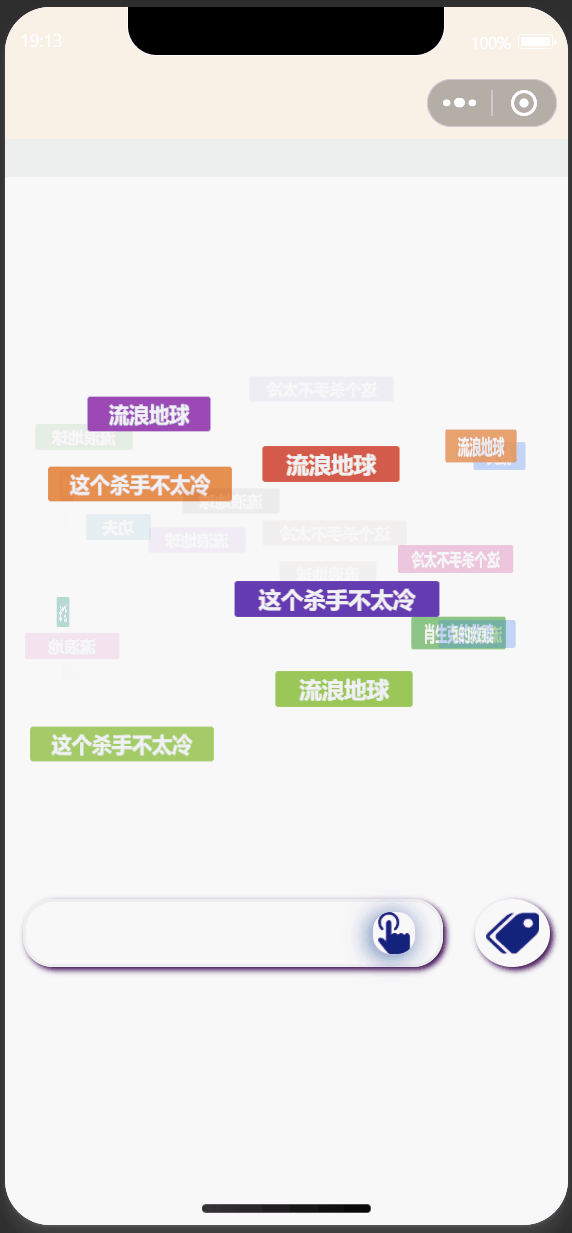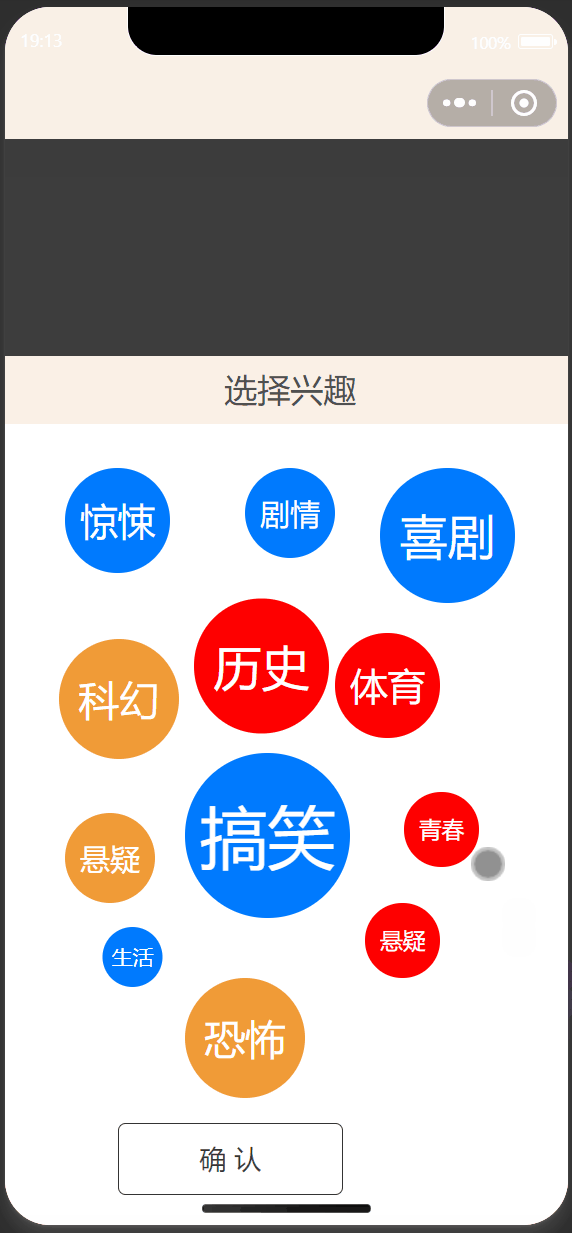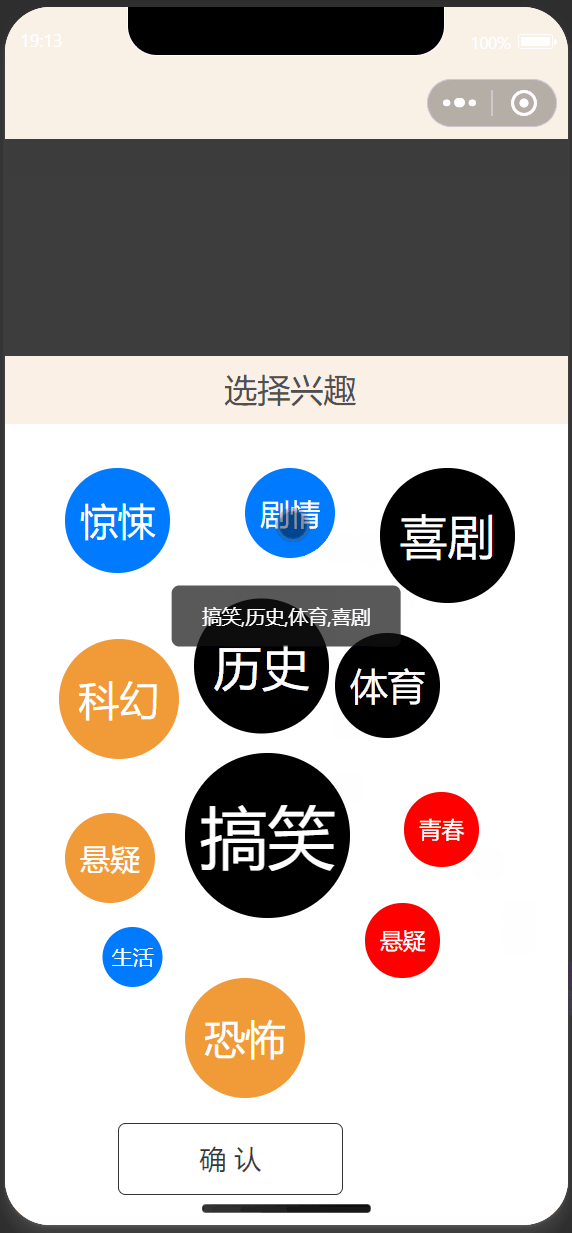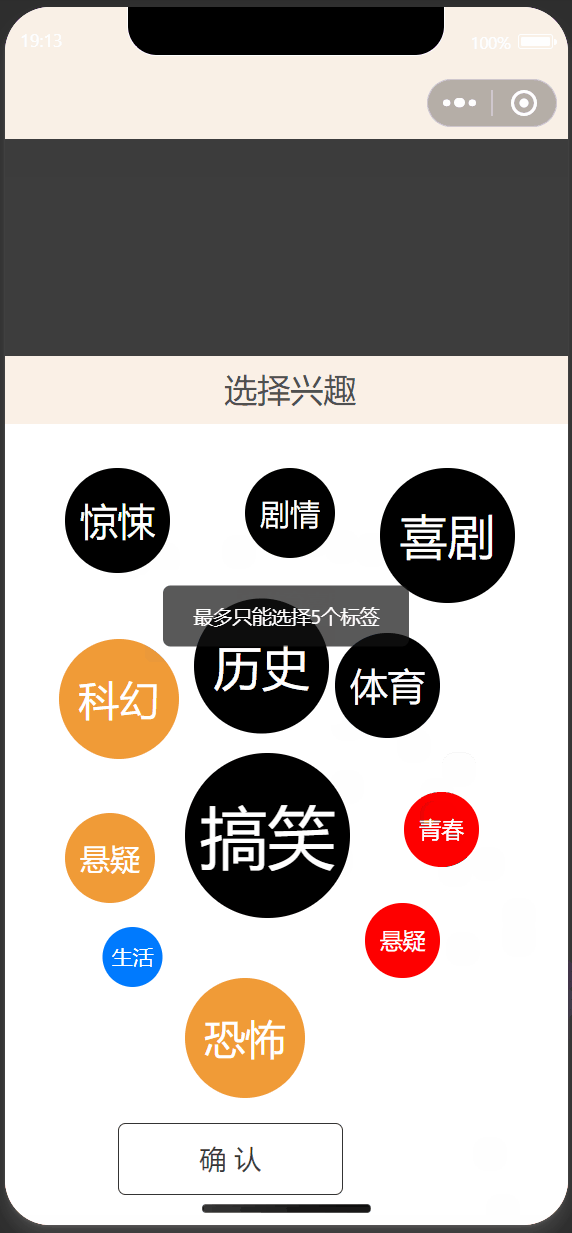 |
| 推荐电影列表页 | 电影详情页 |
|---|---|
3.2 数据后端设计与实现
- 注重介绍后端服务接入 ChatGPT API,需要按照以下步骤进行操作:
- 注册一个账号并登录到OpenAI的官网:https://openai.com/
- 在Dashboard页面上,创建一个API密钥。在“API Keys”选项卡下,点击“Generate New Key”按钮。将生成的密钥保存好,以备后续使用。
- 选择所需的API服务,例如“Completion” API,以使用OpenAI的文本生成功能。

使用Python调用ChatGPT API实现代码如下:
- 方法一:使用
request库
import requests
import json
# 构建API请求
url = "https://api.openai.com/v1/engines/davinci-codex/completions"
headers = {"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"}
data = {
"prompt": "Hello, my name is",
"max_tokens": 5
}
# 发送API请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 解析API响应
response_data = json.loads(response.text)
generated_text = response_data["choices"][0]["text"]
print(generated_text)
- 方式二:使用
openAI库
from flask import Flask, request
import openai
app = Flask(__name__)
openai.api_key = "YOUR_API_KEY_HERE"
@app.route("/")
def home():
return "Hello, World!"
@app.route("/chat", methods=["POST"])
def chat():
data = request.json
response = openai.Completion.create(
engine="davinci",
prompt=data["message"],
max_tokens=60
)
return response.choices[0].text
if __name__ == "__main__":
app.run()
3.3 数据智能获取功能设计与实现
定义一个函数来实现电影信息的爬取,该函数的输入参数为电影名,输出为该电影的名称、导演、主演、类型、上映时间、评分等信息。具体实现步骤如下:
-
构造请求 URL,其中电影名需要进行 URL 编码。
-
发送 HTTP 请求,获取豆瓣电影页面的 HTML 内容。
-
使用 lxml 库解析 HTML 文档,提取电影信息。
import requests
from lxml import etree
def crawl_movie_info(movie_name):
# 1. 构造请求 URL
url = f'https://www.douban.com/search?q={movie_name}'
# 2. 发送 HTTP 请求,获取 HTML 内容
response = requests.get(url)
html = response.content.decode()
# 3. 解析 HTML 文档,提取电影信息
tree = etree.HTML(html)
# 获取搜索结果列表中的第一个电影条目
movie_link = tree.xpath('//div[@class="result"]/div[@class="content"]/h3/a/@href')[0]
response = requests.get(movie_link)
html = response.content.decode()
# 解析电影页面 HTML 文档,提取电影信息
tree = etree.HTML(html)
# 电影名称
movie_title = tree.xpath('//span[@property="v:itemreviewed"]/text()')[0]
# 导演
directors = tree.xpath('//a[@rel="v:directedBy"]/text()')
director = ' / '.join(directors)
# 主演
actors = tree.xpath('//span[@class="actor"]/span[@class="attrs"]/a/text()')
actor = ' / '.join(actors)
# 类型
genres = tree.xpath('//span[@property="v:genre"]/text()')
genre = ' / '.join(genres)
# 上映日期
release_date = tree.xpath('//span[@property="v:initialReleaseDate"]/text()')[0]
# 评分
rating = tree.xpath('//strong[@class="ll rating_num"]/text()')[0]
# 返回电影信息
return {
'电影名称': movie_title,
'导演': director,
'主演': actor,
'类型': genre,
'上映时间': release_date,
'评分': rating,
}
- 我们可以通过调用该函数,传入电影名参数来获取电影信息。例如:
Copy code
movie_name = '大赢家'
movie_info = crawl_movie_info(movie_name)
print(movie_info)
- 输出结果如下:
{'电影名称': '大赢家', '导演': '李伟 / 黄伟明', '主演': '赵本山 / 贾玲 / 小沈阳 / 张子枫 / 李春
四、推荐阅读
入门和进阶小程序开发,不可错误的精彩内容 :
- 《小程序开发必备功能的吐血整理【个人中心界面样式大全】》
- 《微信小程序 | 借ChatGPT之手重构社交聊天小程序》
- 《微信小程序 | 人脸识别的最终解决方案》
- 《微信小程序 |基于百度AI从零实现人脸识别小程序》
- 《吐血整理的几十款小程序登陆界面【附完整代码】》