LVS+KeepAlived快速入门
目录
- 1 构建高可用集群
-
- 1.1 什么是高可用集群
- 1.2 高可用衡量标准
- 1.3 高可用保障
-
- 1.3.1 负载均衡
- 1.3.2 健康监测和自动切换
- 1.4 高可用拓扑图
- 2 软件负载均衡技术LVS
-
- 2.1 LVS简介
-
- 2.1.1 什么是lvs
- 2.1.2 lvs官方资料链接
- 2.2 lvs拓扑
-
- 2.2.1 lvs术语
- 2.2.2 工作原理和拓扑图
- 2.3 lvs的四种工作模式
-
- 2.3.1 TUN模式
- 2.3.2 NAT模式
- 2.3.3 DR模式
- 2.3.4 FULLNAT模式
- 2.4 LVS调度算法
-
- 2.4.1 静态调度算法
- 2.4.2 动态调度算法
- 2.5 lvs基本命令
-
- 2.5.1 集群服务管理
- 2.5.2 集群RS管理
- 2.6 lvs实战
-
- 2.6.1 NAT模式实战
- 2.6.2 DR模式实战
- 2.6.3 四个问题
- 3 KeepAlived
-
- 3.1 keepAlived简介
- 3.2 keepAlived主要特点
-
- 3.2.1 健康检查
- 3.2.2 故障迁移
- 3.3 keepAlived原理
- 3.4 分布式选主策略
-
- 3.4.1 仅设置priority
- 3.4.2 设置priority和weight
1 构建高可用集群
1.1 什么是高可用集群
高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的得服务器
集群技术。它通过保护用户得业务程序对外部间断提供的服务,把因为软件,硬件,认为造成的故障对
业务得影响降低到最小程度。总而言之就是保证公司业务7*24小时不宕机
1.2 高可用衡量标准
衡量集群的可用性(HA)高低,可以从MTTF(平均无故障时间)和MTTR(平均故障维修时间)进行考
量,公式为:HA=MTTF/(MTTF+MTTR)*100%,具体衡量标准可以参考下表

1.3 高可用保障
对集群中的服务器进行负载均衡、健康监测,并在服务器出现故障时能进行故障转移,自动切换到正常
服务器是高可用保障的必要手段。
1.3.1 负载均衡
常见的负载均衡手段如下:
硬件负载均衡,如F5
软件负载均衡,如nginx、haproxy、lvs
几种软件负载均衡技术比较

1.3.2 健康监测和自动切换
常见的健康监测和自动切换软件有keepAlived和heartBeat,其二者对比如下:
Keepalived使用更简单:从安装、配置、使用、维护等角度上对比,Keepalived都比Heartbeat要简单
Heartbeat功能更强大:Heartbeat虽然复杂,但功能更强大,配套工具更全,适合做大型集群管理,
而Keepalived主要用于集群倒换,基本没有管理功能
1.4 高可用拓扑图

2 软件负载均衡技术LVS
2.1 LVS简介
2.1.1 什么是lvs
基础知识:网络协议必知必会
LVS是Linux Virtual Server的简写,在1998年5月由章文嵩博士成立。
工作在OSI模型的四层,基于IP进行负载均衡。
在linux2.2内核时,IPVS就已经以内核补丁的形式出现。
从2.4版本以后,IPVS已经成为linux官方标准内核的一部分。
2.1.2 lvs官方资料链接
a. lvs项目介绍 http://www.linuxvirtualserver.org/zh/lvs1.html
b. lvs集群的体系结构 http://www.linuxvirtualserver.org/zh/lvs2.html
c. lvs集群中的IP负载均衡技术 http://www.linuxvirtualserver.org/zh/lvs3.html
d. lvs集群的负载调度 http://www.linuxvirtualserver.org/zh/lvs4.html
e. lvs中文站点 http://zh.linuxvirtualserver.org
2.2 lvs拓扑
2.2.1 lvs术语
LVS服务器(DS)
集群中节点服务器(RS)
虚拟IP地址(VIP),用于向客户端提供服务的IP地址(配置于负载均衡器上)
真实服务器的IP地址(RIP), 集群中节点服务器的IP地址
负载均衡器IP地址(DIP),负载均衡器的IP地址,物理网卡上的IP
客户端主机IP地址(CIP),终端请求用户的主机IP地址
2.2.2 工作原理和拓扑图
LVS负载均衡调度技术是在linux内核中实现的,使用配置LVS时,不是直接配置内核中的IPVS,而是通
过IPVS的管理工具IPVSADM来管理配置,LVS集群负载均衡器接受所有入站客户端的请求,并根据算法
来决定由哪个集群的节点来处理请求。

2.3 lvs的四种工作模式
2.3.1 TUN模式
TUN(Tunneling)模式需要服务器支持IP隧道(IP tunneling)技术,限制较大,一般不用。

2.3.2 NAT模式
NAT(Network Address Translation)模式是基于NAT技术实现的。在此模式中,LVS服务器既要处理请 求的接入,又要处理请求的响应。因此存在较大的性能瓶颈。

2.3.3 DR模式
DR(Direct Routing)模式是LVS的默认工作模式,也叫直接路由模式。只处理请求的接入,不处理请求的
响应。因此性能高,瓶颈小。

2.3.4 FULLNAT模式
FULLNAT( Full Network Address Translation)可以说是淘宝定制化的技术,linux内核不支持。
2.4 LVS调度算法
2.4.1 静态调度算法

2.4.2 动态调度算法

2.5 lvs基本命令
对于lvs的操作,主要是通过ipvsadm软件实现,常用的lvs操作命令如下:
2.5.1 集群服务管理
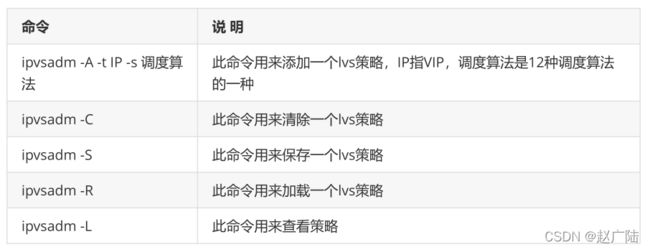
2.5.2 集群RS管理

2.6 lvs实战
2.6.1 NAT模式实战
NAT实战拓扑图

NAT模式实现
按照上面的拓扑图,进行NAT实战,步骤如下:
A. 准备4台linux虚拟机,并确定每台虚拟机的角色,为了方便区分,可以对每台虚拟机设置新的主机
名,比如 LVS服务器可以设置主机名为lvs,设置方式如下
#设置主机名
hostnamectl set-hostname lvs
#断开远程连接
logout
#重新连接即可看到主机名已经更改
.然后对四台虚拟机分别进行配置如下:
RS1和RS2配置
-
配置网卡为NAT模式
-
下载安装httpd服务,命令如下
yum install -y httpd
- 设置首页内容(RS2把内容改为this is RS2)
echo this is RS01 > /var/www/html/index.html
- 启动httpd
systemctl start httpd
- 在RS1和RS2上测试访问,能输出 this is RS01或this is RS02即为成功
[root@rs01 ~]# curl localhost
this is RS01
-
RS1设置静态IP为192.168.25.112,RS2设置静态IP为192.168.25.113。
RS1和RS2指定网关为192.168.25.110,子网掩码255.255.255.0 -
查看网关是否生效
[root@rs01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.25.110 0.0.0.0 UG 100 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.25.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
LVS服务器配置
- 安装ipvsadm
yum install -y ipvsadm
- 设置双网卡
仅主机网卡一块,IP配置为10.0.0.8,此IP是接受外部请求的VIP
NAT网卡一块,IP配置为192.168.25.110,此IP是与后端RS服务器通信的DIP
- 配置ip_forward转发
vi /etc/sysctl.conf
#添加如下内容并保存退出
net.ipv4.ip_forward = 1
#执行如下命令使修改生效
sysctl -p
- 使用ipvsadm进行负载均衡配置
#指定负载80端口的VIP,并指定调度策略为轮询
[root@lvs01 ~]# ipvsadm -A -t 10.0.0.8:80 -s rr
#添加两台RS,并指定负载均衡工作模式为NAT
[root@lvs01 ~]# ipvsadm -a -t 10.0.0.8:80 -r 192.168.25.112 -m
[root@lvs01 ~]# ipvsadm -a -t 10.0.0.8:80 -r 192.168.25.113 -m
#查看上述配置是否生效
[root@lvs01 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.8:80 rr
-> 192.168.25.112:80 Masq 1 0 0
-> 192.168.25.113:80 Masq 1 0 0
client虚拟机配置和测试
配置网卡为仅主机模式,IP为10.0.0.10,网关无需配置即可。
在client上测试负载均衡效果,如下:
[root@client ~]# curl 10.0.0.8
this is RS01
[root@client ~]# curl 10.0.0.8
this is RS02
[root@client ~]# curl 10.0.0.8
this is RS01
[root@client ~]# curl 10.0.0.8
this is RS02
NAT模式存在的问题–>LVS性能瓶颈
2.6.2 DR模式实战
小贴士: ARP(Address Resolution Protocol)地址解析协议,是根据IP地址获取物理地址
(MAC)的一个 TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的
所有主机,并接收返 回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址
存入本机ARP缓存中并 保留一定时间,下次请求时直接查询ARP缓存以节约资源。
DR模式拓扑图

DR模式实现
通过对比NAT模式和DR模式的拓扑图可以发现,需要让LVS和RS在同一个网段,并且在两个RS服务器上
也需要绑定VIP。所以DR模式实验可以在刚才的基础上进行,步骤如下:
- 在RS1和RS2上进行如下ARP抑制操作,并配置VIP到lo网卡上,如下:
#arp抑制
[root@rs02 ~]# echo 1 > /proc/sys/net/ipv4/conf/ens33/arp_ignore
[root@rs02 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@rs02 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
[root@rs02 ~]# echo 2 > /proc/sys/net/ipv4/conf/ens33/arp_announce
#配置VIP到lo网卡 这里的子网掩码需要4个255
[root@rs01 network-scripts]# ifconfig lo:9 192.168.25.100 netmask
255.255.255.255
[root@rs01 network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.25.112 netmask 255.255.255.0 broadcast 192.168.25.255
inet6 fe80::64ba:dea0:c4c3:6593 prefixlen 64 scopeid 0x20<link>
inet6 fe80::fe9:a7ce:86ef:28b0 prefixlen 64 scopeid 0x20<link>
inet6 fe80::c569:ba05:f195:be69 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4e:1b:47 txqueuelen 1000 (Ethernet)
RX packets 482152 bytes 670785221 (639.7 MiB)
RX errors 0 dropped 2 overruns 0 frame 0
TX packets 132454 bytes 12853590 (12.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 63 bytes 5791 (5.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 63 bytes 5791 (5.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo:9: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 192.168.25.100 netmask 255.255.255.255
loop txqueuelen 1 (Local Loopback)
注意:RS1和RS2在之前进行NAT模式实验时设置了网关为LVS的DIP,这里进行DR试验时需要把
网关删除
2) 在LVS服务器上关闭之前的ens37网卡(注意:你的网卡名称可能不是这个)
ifconfig ens37 down
- 在lvs的ens33网卡上绑定VIP192.168.25.100
[root@lvs01 ~]# ifconfig ens33:9 192.168.25.100/24
[root@lvs01 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:29:8e:46:ec txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.25.110 netmask 255.255.255.0 broadcast 192.168.25.255
inet6 fe80::20c:29ff:feb6:e4aa prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:b6:e4:aa txqueuelen 1000 (Ethernet)
RX packets 4213 bytes 491171 (479.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2890 bytes 463923 (453.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:9: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.25.100 netmask 255.255.255.0 broadcast 192.168.25.255
ether 00:0c:29:b6:e4:aa txqueuelen 1000 (Ethernet)
- 在lvs服务器上清空LVS策略,并重新设置DR模式策略
#查看策略
[root@lvs01 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.8:80 rr
-> 192.168.25.112:80 Masq 1 0 1
-> 192.168.25.113:80 Masq 1 0 0
#清空策略
[root@lvs01 ~]# ipvsadm -C
#再次查看策略
[root@lvs01 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
设置DR策略
#设置规则
[root@lvs01 ~]# ipvsadm -A -t 192.168.25.100:80 -s rr
#添加RS
[root@lvs01 ~]# ipvsadm -a -t 192.168.25.100:80 -r 192.168.25.112 -g
[root@lvs01 ~]# ipvsadm -a -t 192.168.25.100:80 -r 192.168.25.113 -g
#查看策略
[root@lvs01 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.25.100:80 rr
-> 192.168.25.112:80 Route 1 0 0
-> 192.168.25.113:80 Route 1 0 0
-
修改client服务器配置,更改使用NAT网卡,并设置IP为192.168.25.199
-
在client测试效果
[root@client network-scripts]# curl 192.168.25.100
this is RS01
[root@client network-scripts]# curl 192.168.25.100
this is RS02
[root@client network-scripts]# curl 192.168.25.100
this is RS01
[root@client network-scripts]# curl 192.168.25.100
this is RS02
- 在LVS服务器上查看调度情况
[root@lvs01 ~]# ipvsadm -Lnc
IPVS connection entries
pro expire state source virtual destination
TCP 01:49 FIN_WAIT 192.168.25.199:60392 192.168.25.100:80 192.168.25.113:80
TCP 01:52 FIN_WAIT 192.168.25.199:60396 192.168.25.100:80 192.168.25.113:80
TCP 01:51 FIN_WAIT 192.168.25.199:60394 192.168.25.100:80 192.168.25.112:80
TCP 01:48 FIN_WAIT 192.168.25.199:60390 192.168.25.100:80 192.168.25.112:80
2.6.3 四个问题
a. 如果LVS服务器挂了会出现什么问题?
b. 如何进行故障转移、自动切换?
b. 如果后端某台RS服务器挂了会出现什么问题?
d. 如何获知RS服务器状态?
3 KeepAlived
3.1 keepAlived简介
Keepalived的作用是检测服务器状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检
测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正
常后Keepalived自动将服务器加入到服务器群中。
3.2 keepAlived主要特点
3.2.1 健康检查

3.2.2 故障迁移
VRRP协议
在现实的网络环境中。主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的
路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决
这个问题,就引入了VRRP协议。
VRRP协议是一种容错的主备模式的协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代
替出现故障的路由器进行工作,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之
间的数据通信。
故障迁移原理
在 Keepalived 服务正常工作时,主 Master 节点会不断地向备节点发送(多播的方式)心跳消息,用
以告诉备 Backup 节点自己还活着,当主 Master 节点发生故障时,就无法发送心跳消息,备节点也就
因此无法继续检测到来自主 Master 节点的心跳了,于是调用自身的接管程序,接管主 Master 节点的
IP 资源及服务。而当主 Master 节点恢复时,备 Backup 节点又会释放主节点故障时自身接管的 IP 资源
及服务,恢复到原来的备用角色。
3.3 keepAlived原理
Keepalived工作在TCP/IP参考模型的三层、四层、五层,其原理如下:

3.4 分布式选主策略
3.4.1 仅设置priority
在一个一主多备的Keepalived集群中,priority值最大的将成为集群中的MASTER节点,而其他都是
BACKUP节点。在MASTER节点发生故障后,BACKUP节点之间将进行“民主选举”,通过对节点优先级值
priority和weight的计算,选出新的MASTER节点接管集群服务。
3.4.2 设置priority和weight
weight值为正数时
在vrrp_script中指定的脚本如果检测成功,那么MASTER节点的权值将是weight值与priority值之和;如
果脚本检测失效,那么MASTER节点的权值保持为priority值
MASTER 节点vrrp_script脚本检测失败时,如果MASTER节点priority值小于BACKUP节点weight值与
priority值之和,将发生主、备切换。
MASTER节点vrrp_script脚本检测成功时,如果MASTER节点weight值与priority值之和大于BACKUP节
点weight值与priority值之和,主节点依然为主节点,不发生切换。
weight值为负数时
在vrrp_script中指定的脚本如果检测成功,那么MASTER节点的权值仍为priority值,当脚本检测失败
时,MASTER节点的权值将是priority值与weight值之差
MASTER节点vrrp_script脚本检测失败时,如果MASTER节点priority值与weight值之差小于BACKUP节
点priority值,将发生主、备切换。
MASTER节点vrrp_scrip脚本检测成功时,如果MASTER节点priority值大于BACKUP节点priority值时,
主节点依然为主节点,不发生切换。
weight设置标准
对于weight值的设置,有一个简单的标准,即weight值的绝对值要大于MASTER和BACKUP节点priority
值之差。由此可见,对于weight值的设置要非常谨慎,如果设置不好,主节点发生故障时将导致集群角
色选举失败,使集群陷于瘫痪状态。