【SPDK】什么是SPDK?为什么用SPDK
目录
什么是SPDK
为什么要引入SPDK?
架构
SPDK的组件构成
典型使用场景
SPDK例子
名词解释
作者:bandaoyu 地址:https://blog.csdn.net/bandaoyu/article/details/124740721
什么是SPDK
SPDK 存储性能开发套件(Storage Performance Development Kit ) —— 针对于支持nvme协议的SSD设备。 SPDK是一种高性能的解决方案。
硬件推动软件革新需求。
Intel发布的,提供了一整套工具和库,以实现高性能、扩展性强、全用户态的存储应用程序。它是继DPDK之后,intel在存储领域推出的又一项颠覆性技术,旨在大幅缩减存储IO栈的软件开销,从而提升存储性能,可以说它就是为了存储性能而生。
为什么要引入SPDK?
原因
因为nvme已经快到一定程度了,很多东西,尤其是软件已经赶不上他了,此时软件反而成为了系统IO的瓶颈。
一般来说读写数据的运作方式是这样的:OS kernel请求一组数据,硬盘回应“嗯,没问题”,但是NAND闪存挺慢的,所以需要一点时间。将数据载入到硬盘的缓存中,准备好了就会告诉OS kernel,给CPU发送一个中断信号,“嘿,数据已经准备好了,没问题了,可以来取那组数据了”。
但是如果这个中断信号在去到目标CPU核心的过程中,CPU核心正在忙着处理其他事情,或者暂时处于睡眠状态,或者被重新分配到其他任务上的话(这种情况在多核心CPU中是很常见的),那么这个中断信号永远到不了,那么CPU永远不会去取那组数据。
也就是说当CPU在执行大量的计算任务时或者很繁忙的时候,那么读写任务可能受到严重的影响。
也就是说,使用nvme磁盘的系统,在CPU高负载的情况下可能会出现问题。
对此业界给出了一个解决方案,对于超高速设备(比如这里的nvme磁盘,基于RAM的缓存盘)以一种叫做“轮询”的模式运作。这是一种完全不同的模式。说人话就是:系统内核假定设备非常快,快到“不用问准备好了没,问就是准备好了”。(设备速度很快,马上就可以把数据准备好)。
当然如果在比较慢的硬盘(比如机械硬盘)上这么搞会带来很大的性能损耗。因为系统会不停的问“嘿,准备好了吗?嘿,准备好了吗?”,这样一来,IO时延变高了,同时读写带宽也会受影响。但是对于nvme盘,特别是前面提到的超快速的存储设备,这么做是值得的。
而spdk的存在就是提供一种以轮询的方式来访问硬盘的方式,在高速设备上用于取代中断的访问方式。https://www.cnblogs.com/powerrailgun/p/12389660.html?ivk_sa=1024320u
针对HDD的方案在面临SSD时的缺点
2、以前的linuxIO栈针对HDD做了诸多优化:page cache等;内核采用中断方式进行DMA(外部设备不通过CPU而直接与系统内存交换数据的接口技术)。
而现在ssd的出现,这样的优化会使ssd的硬盘存在空缺(OS kernel请求数据-->等待对方准备后的过程:去做别的事情/休眠 -->取数据。ssd很快,根本不需要OS kernel 做这个过程来等待),不能充分利用。
3、以前的方式会存在大量的内核上下文切换和中断,造成大量的延迟和开销。
现在spdk采用将设备驱动代码放在用户态,避免内核上下文切换。spdk采用轮询模式代替传统的IO模型。
在传统的I/O模型中,应用程序提交读写请求后进入睡眠状态,一旦I/O完成,中断就会将其唤醒。
轮询的工作方式则不同,应用程序提交读写请求后继续执行其他工作,以一定的时间间隔回头检查I/O是否已经完成。(因为SSD很快,这样一来 “请求后进入睡眠再醒来过程太慢”)
传统的方式:中断开销只占整个I/O时间【io读取慢】的很小的百分比,因此给系统带来了巨大的效率提升。
现在的方式:持续引入更低时延的持久化设备,中断开销成为了整个I/O时间中不可忽视的部分。所以我们必须区优化,使其达到平衡。
原文链接:https://blog.csdn.net/qq_41108558/article/details/118102087
针对SSD,SPDK的方案
(SPDK) 提供了一组工具和库,用于编写高性能、可扩展的用户模式存储应用程序。它通过使用一些关键技术实现高性能:
- 将所有必要的驱动程序移动到用户空间,从而避免 syscalls,并允许从应用程序中访问零拷贝。
- 对硬件进行完成轮询,而不是依赖中断,这降低了总延迟和延迟方差。
- 避免 I/O 路径中的所有锁,而是依靠消息传递。
为此SPDK主要运用了两项关键技术:UIO和pooling,使用SPDK的存储系统能轻松达到数百万IOPS。
首先,将设备驱动代码运行在用户态,避免内核上下文切换和中断将会节省大量的处理开销,允许更多的时钟周期被用来做实际的数据存储。无论存储算法(去冗,加密,压缩,空白块存储)多么复杂,浪费更少的时钟周期总是意味着更好的性能和时延。
其次,采用轮询模式改变了传统I/O的基本模型。在传统的I/O模型中,应用程序提交读写请求后进入睡眠状态,一旦I/O完成,中断就会将其唤醒。轮询的工作方式则不同,应用程序提交读写请求后继续执行其他工作,以一定的时间间隔回头检查I/O是否已经完成。这种方式避免了中断带来的延迟和开销,并使得应用程序提高了I/O效率。
概括:要在用户态实施一套基于用户态软件驱动的完整I/O栈。
传统的IO需要syscalls
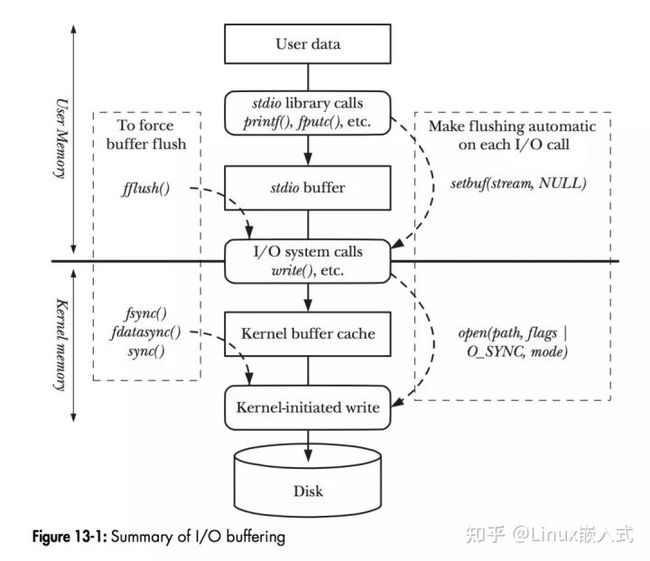 详细讲解Linux内核IO技术栈原理:https://zhuanlan.zhihu.com/p/484945013
详细讲解Linux内核IO技术栈原理:https://zhuanlan.zhihu.com/p/484945013
与RDMA的结合
rdma应用跑在用户态能减小存储时延,spdk在用户态实现nvme驱动,天然能和rdma结合,而且两者的队列能一一映射,能达到锦上添花的效果。坏处就是kernel upstream实现的nvme代码无法复用,网卡硬件得支持rdma,rdma的库很多,出了问题估计会有找不得北的感觉。
用SPDK实现存储加速;https://zhuanlan.zhihu.com/p/403051094
SPDK 是CAS(缓存加速软件)的两种实现之一
CAS提供了两种实现,一个是Open CAS Linux,另一个是 SPDK Block Device。
存储领域的CAS是什么:https://blog.csdn.net/bandaoyu/article/details/122742029
SPDK入门 :https://zhuanlan.zhihu.com/p/388959241
SPDK的设计理念
Intel开发了一套基于nvme-ssd的开发套件,SPDK ,存储性能开发套件。
使用了两项关键技术UIO(Userspace I/O)以及polling,
spdk主要通过引入以下技术,实现其高性能方案。
- 将存储用到的驱动转移到用户态,从而避免系统调用带来的性能损耗,顺便可以直接使用用态内存落盘实现零拷贝
- 使用polling模式
- 轮询硬件队列,而不像之前那样使用中断模式,中断模式带来了不稳定的性能和延时的提升
- 任何业务都可以在spdk的线程中将轮询函数注册为poller,注册之后该函数会在spdk中周期性的执行,避免了epoll等事件通知机制造成的overhead。
- 避免在IO链路上使用锁。使用无锁队列传递消息/IO
- spdk设计的主要目标之一就随着使用硬件(e.g. SSD,NIC,CPU)的增多而获得性能的线性提升,为了达到这目的,spdk的设计者就必须消除使用更多的系统资源带来的overhead,如:更多的线程、进程间通信,访问更多的存储硬件、网卡带来的性能损耗。
- 为了降低这种性能开销,spdk引入了无锁队列,使用lock-free编程,从而避免锁带来的性能损耗。
- spdk的无锁队列主要依赖的dpdk的实现,其本质是使用cas(compare and swap)实现了多生产者多消费者FIFO队列。
spdk编程最基本的准则,就是避免在spdk核上出现进程上下文切换。其会打破spdk高性能框架,造成性能降低甚至不能工作。
进程上下文切换原因很多,大致列举如下:
- cpu时间片耗尽
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 进程主动调用sleep等函数让出cpu使用权。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 硬件中断会导致CPU上的进程被挂起,转而执行内核的中断服务程序。
spdk bdev
spdk在上述加速访问NVMe存储的基础上,提供了块设备(bdev)的软件栈,这个块设备并不是linux系统中的块设备,spdk中的块设备只是软件抽象出的接口层。
spdk已经提供了各种bdev,满足不同的后端存储方式、测试需求。如NVMe (NVMe bdev既有NVMe物理盘,也包括NVMeof)、内存(malloc bdev)、不落盘直接返回(null bdev)等等。用户也可以自定义自己的bdev,一个很常见的使用spdk的方式是,用户定义自己的bdev,用以访问自己的分布式存储集群。
spdk通过bdev接口层,统一了块设备的调用方法,使用者只要调用不同的rpc将不同的块设备加到spdk进程中,就可以使用各种bdev,而不用修改代码。并且用户增加自己的bdev也很简单,这极大的拓展了spdk的适用场景。
讲到这里,各位同学应该明白了,spdk目前的的应用场景主要是针对块存储,可以说块存储是整个存储的基石,再其之上我们又构建了各种文件存储、对象存储、表格存储、数据库等等,我们可以如各种云原生数据库一样将上层的分布式系统直接构建在分布式块存储、对象存储之上,也可以将其他存储需要管理的元数据、索引下推到块层,直接用spdk优化上层存储,比如目前的块存储使用lba作为索引粒度管控,我们可以将索引变为文件/对象,在其之上构建文件/对象存储系统。
架构

SPDK的存储架构分为四层:驱动层、块设备层、存储服务层、存储协议层
驱动层
NVMe driver:SPDK的基础组件,高度优化且无锁的驱动提供了前所未有的高扩展性,高效性和高性能 IOAT:基于Xeon处理器平台上的copy offload引擎。通过提供用户空间访问,减少了DMA数据移动的阈值,允许对小尺寸I/O或NTB(非透明桥)做更好地利用。
块设备层:
NVMe over Fabrics(NVMe-oF)initiator:本地SPDK NVMe驱动和NVMe-oF initiator共享一套公共的API。本地远程API调用及其简便。 RBD:将rbd设备作为spdk的后端存储。 Blobstore Block Device:基于SPDK技术设计的Blobstore块设备,应用于虚机或数据库场景。由于spdk的无锁机制,将享有更好的性能。 Linux AIO:spdk与内核设备(如机械硬盘)交互。
存储服务层:
bdev:通用的块设备抽象。连接到各种不同设备驱动和块设备的存储协议,类似于文件系统的VFS。在块层提供灵活的API用于额外的用户功能(磁盘阵列,压缩,去冗等)。 Blobstore:SPDK实现一个高精简的类文件的语义(非POSIX)。这可为数据库,容器,虚拟机或其他不依赖于大部分POSIX文件系统功能集(比如用户访问控制)的工作负载提供高性能支撑。
存储协议层
iSCSI target:现在大多使用原生iscsi NVMe-oF target:实现了新的NVMe-oF规范。虽然这取决于RDMA硬件,NVMe-oF target可以为每个CPU核提供高达40Gbps的流量。 vhost-scsi target:KVM/QEMU的功能利用了SPDK NVMe驱动,使得访客虚拟机访问存储设备时延更低,使得I/O密集型工作负载的整体CPU负载有所下降。
从流程上来看,spdk有数个子构件组成,包括网络前端、处理框架和存储后端。
总结
从流程上来看,spdk子构件组成,包括网络前端、处理框架、存储后端组成。 网络前端接受数据,处理框架把iSCSI转换成SCSI块级命令、后端对设备进行读写。
实现细节
前端由DPDK、网卡驱动、用户态网络服务构件组成。DPDK给网卡提供一个高性能的包处理框架;网卡驱动提供一个从网卡到用户态空间的数据快速通道;用户态网络服务则破解TCP/IP包并生成iSCSI命令。
处理框架得到包的内容,并将iSCSI命令翻译为SCSI块级命令。不过,在将这些命令送给后端驱动之前,SPDK提供一个API框架以加入用户指定的功能,即spcial sauce(上图绿框中)。例如缓存,去冗,数据压缩,加密,RAID和纠删码计算等,诸如这些功能都包含在SPDK中。不过这些功能仅仅是为了帮助我们模拟应用场景,需要经过严格的测试优化才可使用。
数据到达后端驱动,在这一层中与物理块设备发生交互,即读与写操作。SPDK包括了几种存储介质的用户态轮询模式驱动: NVMe设备; inux异步IO设备如传统磁盘; 基于块地址的内存应用的内存驱动(如RAMDISKS) 可以使用Intel I/O加速技术设备。
SPDK的组件构成

SPDK中大概有三类子组件:网络前端、处理框架、后端。
网络前端子组件:包括DPDK网卡驱动和用户态网络服务UNS(这是一个Linux内核TCP/IP协议栈的替代品,能够突破通用TCP/IP协议栈的种种性能限制瓶颈)。DPDK在网卡侧提供了一个高性能的发包收包处理框架,在数据从网卡到操作系统用户态之间提供了一条快速通道。UNS代码则继续这一部分处理,稍加处理TCP/IP数据包的标准处理方式,并形成iSCSI命令。
处理框架:包括iSCSI Target和Customer Storage App,“处理框架”部分拿到了数据包内容,将iSCSI命令转换为SCSI块级命令。然而,在它将这些命令发到“后端”驱动之前,SPDK提供了一套API框架,让厂商能够插入自己定义的处理逻辑(架构图中绿色的方框)。通过这种机制,存储厂商可在这里实现例如缓存、去重、压缩、加密、RAID计算,或擦除码(Erasure Coding)计算等功能,使这些功能包含在SPDK的处理流程中。
后端:数据到达了“后端”驱动层,在这里SPDK和物理块设备交互(读和写操作)。这一系列后端设备驱动涵盖了不同性能的存储分层,保证SPDK几乎与每种存储应用形成关联。
典型使用场景
- 提供块设备接口的后端存储应用,诸如iSCSI Target和 NVMe-oF Target;
- 对虚拟机中I/O (virtio) 的加速,主要支持Linux系统下的QEMU/KVM作为hypervisor 管理虚拟机的场景,使用vhost交互协议实现基于共享内存通道的高效vhost用户态target (例如vhost SCSI/blk/NVMe target)
- SPDK加速数据库存储引擎。通过实现了RocksDB中的抽象文件类,SPDK的blobfs/blobstore目前可以和Rocksdb集成,用于在NVMe SSD上加速实现RocksDB引擎的使用。该操作的实质是bypass kernel文件系统将完全使用基于SPDK的用户态I/O stack。
SPDK例子
hello-world.c
重要概念
让我们先搞清楚两个问题:
-
问题1: 每一块NVMe固态硬盘里都一个控制器(Controller), 那么发现的所有NVMe固态硬盘(也就是NVMe Controllers)以什么方式组织在一起?
-
问题2: 每一块NVMe固态硬盘都可以划分为多个NameSpace (类似逻辑分区的概念), 那么这些NameSpace以什么方式组织在一起?
链表。
代码主要流程
spdk_env_opts_init(&opts);
spdk_env_init(&opts);
rc = spdk_nvme_probe(NULL, NULL, probe_cb, attach_cb, NULL);
hello_world();
cleanup();
-
1-2,初始化spdk环境及其配置基本项
-
3,调用函数spdk_nvme_probe()主动发现NVMe SSDs设备。 关键函数是spdk_nvme_probe()。
-
4,调用函数hello_world()做简单的读写操作
-
5,调用函数cleanup()以释放内存资源,卸载NVMe SSD设备等。
probe_cb和attach_cb是两个callback函数, (其实还有remove_cb)
-
probe_cb: 当扫描NVMe设备后被调用
-
attach_cb: 当一个NVMe设备已经被挂接到一个用户态的NVMe 驱动的时候被调用
继续看代码:
static void
hello_world(void)
{
struct ns_entry *ns_entry;
struct hello_world_sequence sequence;
int rc;
size_t sz;
TAILQ_FOREACH(ns_entry, &g_namespaces, link) {
/*
* Allocate an I/O qpair that we can use to submit read/write requests
* to namespaces on the controller. NVMe controllers typically support
* many qpairs per controller. Any I/O qpair allocated for a controller
* can submit I/O to any namespace on that controller.
*
* The SPDK NVMe driver provides no synchronization for qpair accesses -
* the application must ensure only a single thread submits I/O to a
* qpair, and that same thread must also check for completions on that
* qpair. This enables extremely efficient I/O processing by making all
* I/O operations completely lockless.
*/
ns_entry->qpair = spdk_nvme_ctrlr_alloc_io_qpair(ns_entry->ctrlr, NULL, 0);
if (ns_entry->qpair == NULL) {
printf("ERROR: spdk_nvme_ctrlr_alloc_io_qpair() failed\n");
return;
}
……
spdk_nvme_ctrlr_alloc_io_qpair:分配一个qpair,一个是submit queue,一个是complete queue,进行读写操作。一般都是一个sq和cq对应。创建好qpair后就可以通过qpair下发IO操作了。

rc = spdk_nvme_ns_cmd_write(ns_entry->ns, ns_entry->qpair, sequence.buf,
0, /* LBA start */
1, /* number of LBAs */
write_complete, &sequence, 0);
spdk_nvme_ns_cmd_write:提交一个写请求到ns和qpair
static void
write_complete(void *arg, const struct spdk_nvme_cpl *completion)
{
……
rc = spdk_nvme_ns_cmd_read(ns_entry->ns, ns_entry->qpair, sequence->buf,
0, /* LBA start */
1, /* number of LBAs */
read_complete, (void *)sequence, 0);
……
}
static void
read_complete(void *arg, const struct spdk_nvme_cpl *completion)
{
struct hello_world_sequence *sequence = arg;
printf("%s", sequence->buf);
}
sdpk推荐文档:https://spdk.io/doc/
作者:九楼记
链接:https://www.jianshu.com/p/f8a008ea4e44
名词解释
- iSCSI
Internet小型计算机系统接口,又称为IP-SAN,是一种基于因特网及SCSI-3协议下的存储技术,由IETF提出,并于2003年2月11日成为正式的标准
- CPU状态之间的转换
用户态转换到内核态:唯一途径是通过中断、异常、陷入机制(访管指令) 内核态转换到用户态:设置程序状态字psw
DPDK:全称Intel Data Plane Development Kit,是intel提供的数据平面开发工具集,为Intel architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持。通俗地说,就是一个用来进行包数据处理加速的软件库。
CBDMA :全称Crystal Beach DMA是一个CPU里面的DMA引擎,有了它之后就能够在不中断CPU的情况下执行高效的内存拷贝。
NVMe SSD:有一个SSD Controller,同时存储空间划分成若干个独立的逻辑空间,每个空间逻辑块地址(LBA)范围是0到N-1 (N是逻辑空间大小),这样划分出来的每一个逻辑空间我们就叫做NameSpace。