7 mysql
mysql
https://blog.csdn.net/liu_weiliang10405/article/details/123930244
官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-locks-set.html
1、什么是幻读?为什么会产生幻读,MySQL中是怎么解决幻读的?
幻读就是:A事务开启先使用普通查询查询id为3的数据,发现没有,准备插入的时候,B事务开启并插入了id为3的数据并提交了事务。此时A再去插入数据发现插入不了,所以A再次查询了数据,发现还是没有,提交事务后查询,发现出现了数据,就好像出现了幻觉一样。
这里要区分什么是快照读和当前读。
快照读就是开启事务后第一次查询数据库返回的数据,这个数据会一直保留到事务提交或者使用一次当前读。因为mysql默认事务级别为可重复读。
当前读就是返回数据库中的最新数据。
如何解决幻读
目的:在一次事务中多次读到的结果永远一样。Mvcc只有快照读确实能解决幻读(就是说在这个事务内不进行当前读,如果使用了当前读还会出现幻读),当前读还是会有幻读现象
即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。
为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁(Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。也就是说,我们的表 t 初始化以后,如果用 SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。
根据语句查找的范围不同,会将搜索范围都加上间隙锁,不允许插入数据。单条的一般只锁两边,且一个next key为左开右闭,之后在到右边那个一个,(E,W] (W,+∞)
比如:select * from t where 非唯一索引=3,这个会将这一列关于3的记录锁住,是一个间隙,无论insert一条该列为3或者修改一条该列记录为3都是不允许的,这就是间隙锁的作用https://www.cnblogs.com/phyger/p/14377651.html
画出二级索引图来比较明白
锁的二级索引中叶子节点的指针?
间隙锁是在可重复读隔离级别下才会生效的
怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。但是如果b事务commit,这个gap锁就会释放
但是注意,**对于可重复读默认使用的就是next key lock,但是对于“唯一索引”,比如主键的索引,next key lock会降级成行锁,而不会锁住一个区间。**因此,如果上面的事务1的update使用的是主键,事务2也使用主键进行插入,那么实际上事务2根本不会被阻塞,可以立即插入并返回。而对于非唯一索引,next key lock则不会降级。
https://blog.csdn.net/qq_35590091/article/details/107734005https://juejin.cn/post/6844904121758138382#heading-16 这里的锁锁的是非唯一索引
https://www.cnblogs.com/phyger/p/14377651.html 间隙锁好评
https://dev.mysql.com/doc/refman/8.0/en/innodb-locks-set.html 8.0语句加锁情况
https://dev.mysql.com/doc/refman/5.7/en/innodb-locks-set.html 5.7语句加锁情况
https://www.zhihu.com/question/437140633 知乎的也挺靠谱的
知乎的要点:加间隙锁的时候,如果没有走索引就会导致锁住整张表,因为加的间隙就是整张表。如果有索引就在索引的叶子节点的两边加就好了。和上面的间隙锁好评那样画的一样。
还需要注意的一点是,间隙锁和间隙锁是不会产生冲突的。
MVCC只能解决更新问题,不能解决插入问题。Mvcc只有快照读确实能解决幻读,当前读还是会有幻读现象
2、MVCC实现原理
作用:解决了脏读和不可重复读的问题。多版本并发控制,能在写的时候不会阻塞读线程,读的时候不阻塞写线程。
https://blog.csdn.net/USTC_Zn/article/details/123622672?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-123622672-blog-118552170.pc_relevant_multi_platform_whitelistv1&spm=1001.2101.3001.4242.1&utm_relevant_index=2
https://juejin.cn/post/6844904115353436174#heading-16 这个比较好
MVCC实现可重复读原理:生成一个read view,里面记录了三个字段(活跃事务集合、集合中最小的事务号、创建readview时下一个事务号) , 在每一个数据行中还有两个隐藏字段(最新修改了数据的事务id,undolog指针)
一个事务进行查询的时候,执行的第一条当前读,会生成readview,当本次事务去查询的时候会去查找数据库中最新的数据行信息,拿到更新这条数据的最新事务id记为now,拿now去和readview中最小事务号比较,如果now小于最小事务号,则表示now是在创建readview之前就提交了数据的,此时可以读取信息,直接返回给客户端;如果大于最小事务号则进入第二步
第二步:now与创建readview下一个事务比较,大于则表示这条信息是在创建完readview时还未提交的,所以看不了;如果小于则表示可能可以看见,执行第三步
第三步:查找集合,看看活跃事务中是否有now事务id,没有则表示已经提交的数据,这时本事务就可以看见了。否则是未提交事务,不能被看见。
这样就能控制读取数据永远是一致的了。
在一二步不可见,则会去使用undo指针查找上一条数据,再重复第一到第三步,直到找到相应的数据。
RC与RR区别:RC每次执行select普通读,都会生成一个readview(就三个字段),而RR只会复用第一个select的readView
3、三大范式
前置知识
主键:能唯一表识一行数据
候选键:一行众多属性都能唯一表识一行数据,则这些都是候选键
主属性:候选键中的所有单属性列的集合
非主属性:就是除了主属性列之后的列。
传递依赖:A->B,A!=B,B->C,则A->C,这就是传递依赖
部分函数依赖:(A,B)->C,A->C,则A到C存在部分函数依赖
第一范式:属性不能再分开
第二范式:不存在部分函数依赖,非主属性完全依赖于主键
第三范式:不存在传递函数依赖,将传递依赖打断,让非主属性直接依赖于候选键
4、数据库引擎区别
1、Innodb:这是我们最常用的一个存储引擎,支持事务、外键,支持行级锁和表级锁,锁粒度比MyIsam小,但是储存空间较大,索引和数据存储在一个文件中。不支持全文索引。没有保存每个表的数据行数,需要全表扫描。(5.7以后的InnoDB也支持全文索引)
2、MyIsam:这时一个不支持事务,只有表级锁,不支持MVCC,不支持外键约束,但是他支持全文索引。查询速度比Innodb快,适合不使用事务的查询。保存了数据行数,在进行查询表行数时能直接返回数据。
3、Memory:这个存储引擎将数据存储在内存中,速度快,但是由于存储在内存中,一但内存断点,数据将会丢失,且要消耗内存。
5、ACID事务
1、事务特性
A:原子性,C:一致性,I:隔离性,D:持久性
事务特性:要么全部成功要么全部失败。
2、如何保证事务?
使用undolog与redolog保证
在执行一条语句时,首先会先写日志(这一点和redis区别开来,redis是先写如数据在写日志,所以不支持回滚),在写数据,如果在事务期间发生了错误,使用undolog回滚,且日志要先落盘之后才写数据,这样能够保证数据不丢失。
3、事务隔离级别
读未提交:脏读、不可重复读、幻读
读已提交:不可重复读、幻读
可重复读:幻读
串行化:解决上面的问题,但是效率变低
mysql默认隔离级别为可重复读。
6、索引
1、索引分类
按数据结构分:Hash索引、B树索引(多路搜素树,每个节点存放数据)、B+数索引(多路搜素树,节点存放值,只有叶子节点还有指针,用于顺序移动)
按应用类型分:普通索引、唯一索引、主键索引、全文索引、组合(联合)索引:多个列组成一个索引
按物理顺序分:聚集索引、非聚集索引
2、索引失效
使用了函数、不等号、模糊匹配时使用%开头,隐式字符转化、is not null作为条件,组合索引没有使用最左边的作为条件
1、使用了函数,例如now,会导致索引失效
2、出现类型转换,比如数据库中的字段为string类型,我们的value没有使用引号引起来
3、使用like且使用了%通配符开头
4、在使用组合索引时,没有遵循最左匹配原则
5、使用了is not null作为条件
6、使用了不等号作为条件。
3、为什么索引选择B+树?
因为B+树在叶子节点存放数据,其他节点存放索引,这样能降低树的高度,从而减小查询时间。O(log(n))
hash索引不适合范围查找,因为它使用hash表来存放数据,如果是精确数据则能够快速返回。
4、聚集索引与非聚集索引区别
1、聚集索引在物理存储数据时是顺序的,而非聚集索引是随机的。
2、聚集索引一个表只能有一个,非聚集索引可以有多个
3、聚集索引的叶子节点存放数据,非聚集索引存放的还是索引,要想获得真正的数据需要回表查询,使用了覆盖索引不用回表
5、索引策略
1、覆盖索引:就是索引中包含了要查询的字段,避免了回表
2、最左匹配原则:创建组合索引的时候,(a,b,c)实际上创建了(a)、(a,b)、(a,b,c)三个索引,但是一般值匹配最左边的那一个,其他是乱序的。
3、索引下推ICP:原本在执行引擎层是不使用where条件过滤的,执行引擎将所有结果返回之后在服务层进行过滤。开启ICP之后就将过滤任务加到执行引擎层了,这样就能减少返回的数据。
6、hash索引和B+数索引
hash索引用于等值查询,且效率比B+数索引高
但是Hash索引不能使用模糊查询、排序、范围查询、不支持最左匹配原则
7、创建索引的原则
1、不要在频繁更新的字段上创建索引
2、在频繁查询的字段上创建索引
3、在数据量较少的表中不必创建索引,因为索引也是需要消耗资源的
4、不要在区分度很低的列上创建索引,例如性别上面,因为只有男和女区分不出来啥,索引就是为了查询速度快有区别才快。
7、锁
1、锁分类
https://blog.csdn.net/u010841296/article/details/84204701?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-84204701-blog-124074013.pc_relevant_sortByStrongTime&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-84204701-blog-124074013.pc_relevant_sortByStrongTime&utm_relevant_index=1
对数据操作划分:共享锁、排它锁
锁粒度分:行级锁、表级锁
对待锁的态度:悲观锁、乐观锁

2、innodb行锁实现
InnoDB是基于索引来完成行锁。
3、如何解决死锁问题
https://www.cnblogs.com/konggg/p/14695311.html 这个是show engine innodb status;的详解
https://juejin.cn/post/6844904121758138382 死锁排查
预防为主
锁记录会在mysql的系统表中记录,分别是:infomation_schema.trx(所有事务信息)、infomation_schema.locks(阻塞队列,包含正在使用锁的事务)、infomation_schema.lock_waits(正在等待资源的事务信息)
通过查找lock_waits来查找被阻塞的事务,根据被阻塞锁事务查询事务信息,进而查询发生事故的车,进而选择是否需要关闭事务。
show full processList;来查找当前数据库中所有的线程,且能查找的对应的语句。
4、死锁处理
让最小的事务回滚
5、死锁避免方法
1、将事务变小,这样就能快速释放锁。
2、使用串行访问方法
3、一次性锁住所有要用的资源
6、select for update
这个是会加锁,普通的select是不加锁的,这个加行锁还是表锁要看是否使用了索引,如果使用了索引就是行锁,否则是表锁。
如果查询条件用了索引/主键,那么select … for update就会进行行锁。
如果是普通字段(没有索引/主键),那么select … for update就会进行锁表。
加的是排他锁
7、意向锁
意向锁 相关
意向锁是表锁,作用是为了让别的事务知道当前表中有的行加了锁。
当我们需要加一个排他锁时,需要根据意向锁去判断表中有没有数据行被锁定(行锁);
(1)如果意向锁是行锁,则需要遍历每一行数据去确认;
(2)如果意向锁是表锁,则只需要判断一次即可知道有没数据行被锁定,提升性能。
8、锁升级
mysql的行锁是通过索引来实现的,如果SQL语句没有使用到索引则会变成表锁。
当非唯一的区分度只有一半时,这时就会变成表锁,因为才一半的区分度,维护索引都比全表消耗的资源多,所以还不如使用表锁。
8、优化SQL
1、SQL优化
1、创建索引并尽量使用索引
2、使用联合查询来替代子查询:
https://blog.csdn.net/weixin_44041590/article/details/114343328 https://www.bilibili.com/read/cv16081040(这个好一点)
在我们使用子查询的时候,往往将他作为where字句中的in的后缀,比如
查询19级学生的班主任信息
select * from teacher where teacherId in (selcet teacherId from student where 年级=19)
上面的就是子查询,因为in字句要,所以读取teacher表时,都要去遍历一遍in的集合,如果使用联合查询就只会遍历一次学生表
select * from teacher,student where 年级=19 and teacher.teacherId=student.teacherId
这个只会遍历一遍联合表,而子查询如果返回结果较多的话就相当于多次遍历student表。
3、只返回需要的数据,指的是返回指定的列和行
4、使用分库分表
5、提高硬件水平
2、分库分表
水平分表:就是分区表
水平分库:同样也是分区表,只不过这里变成了分库表,将不同分区分在不同的数据库中。
垂直分表:按照字段的重要程度,新建一个从表存放一些不太重要的数据,范式
垂直分库:和上面类似,将从表放在另一个从数据库中。
3、分库分表导致的问题及解决
如果是分表的话,在插入的时候就要考虑事务,要保持事务一致性。
主键问题:如果是同一个表能够使用主键自增来解决,但是不同表就会导致主键问题,可以使用UUID,或者雪花算法。
4、limit 100000很慢怎么办
1、在业务上修改,让用户只能一页一页往下翻
2、想方设法使用到索引,可以先使用索引找到对应的数据,再使用索引链接原表和过滤表,这样通过就能快速匹配链接了。
SELECT a.* FROM employee a, (select id from employee where 条件 LIMIT 1000000,10 ) b where a.id=b.id
3、返回上一次最后的id号,这样直接根据索引定位到指定的起始行就能防止从头开始遍历。
5、优化慢SQL
1、开启慢日志,这个日志默认没有开启,需要手动开启 https://blog.csdn.net/chengqiuming/article/details/120402562
2、通过explain来分析SQL语句,是否使用了索引,看看extra信息是不是使用了啥外排序。关键字段:type(对表的访问方式all、index(相当于全表扫描了,但是只遍历了索引树)、range、ref(非唯一性索引,只查找了一些)、eqref(使用了唯一性索引,只查找一条数据)、const、system)、key(使用了那个索引)、Extra(一些其他信息,比如说使用了什么排序)
https://blog.csdn.net/weixin_29038345/article/details/113441388
6、exist与in的区别
https://www.cnblogs.com/hooong/p/14927399.html
https://blog.csdn.net/weixin_41979002/article/details/118730611 这个好一点
exist是存在的意思,会去查询外循环,将外循环的所有数据和exist字句的每一个做判断,如果在exist中存在,则返回这条外循环数据。否则返回false。
而in则是先查询in字句,之后每查询到一条外查询的数据,都要和in数据集的所有数据做比对,看是否存在该数据。
我们想要提高效率,就要小表驱动大表,用小表去连接大表,因为小表连接次数较少,连接是比较耗费时间的。
因此,我们要选择最外层循环小的,也就是,如果B的数据量小于A,适合使用in,如果B的数据量大于A,即适合选择exists,这就是in和exists的区别。
7、大表优化查询
优化SQL
分库分表
增加索引
增加缓存大小
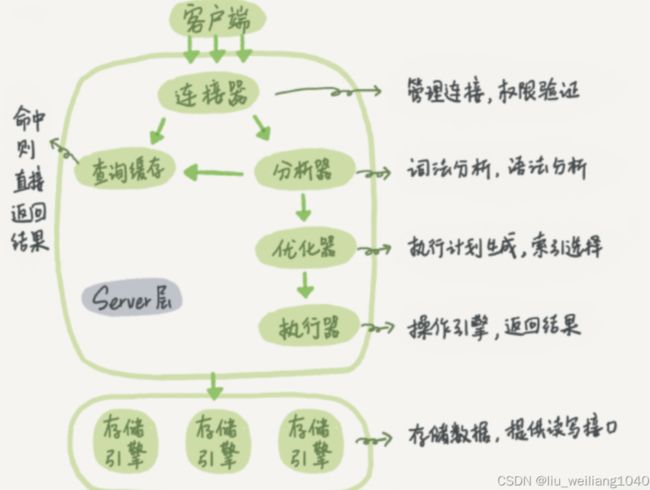
8、SQL的运行流程
当客户端收到一条SQL语句,首先会去查找缓存中有没有,如果有则返回结果,否则进行SQL语法解析,之后进行优化SQL语句,输出执行计划交给执行器,执行器通过调用引擎层来执行SQL语句,将返回结果返回给客户端。
这里的客户端相当于java程序,连接器来做权限认证。

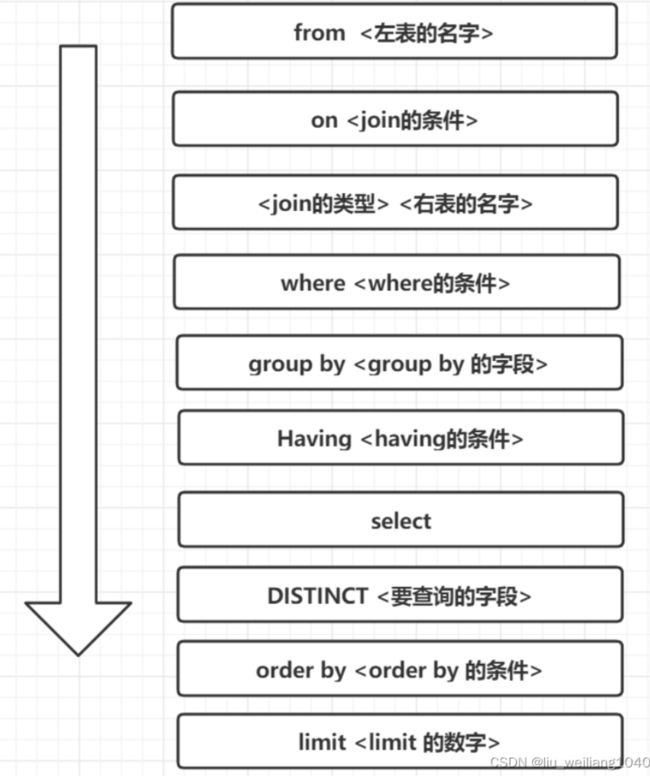
9、SQL各种关键字的执行顺序
先连接,where过滤,分组,分组过滤,开始筛选查询结果,对结果集去重排序,返回指定行数结果集

10、为什么不要定义为null
null值会占用更多的字节,并且null有很多坑的。
Mysql难以优化引用可空列查询,它会使索引、索引统计和值更加复杂。可空列需要更多的存储空间,还需要mysql内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致MYisam 中固定大小的索引变成可变大小的索引。
—— 出自《高性能mysql第二版》
9、分布式
1、主键id策略
1、雪花算法
2、redis生成,因为redis是单线程的,安全
3、使用zookeeper生成
4、UUID
5、主键自增
2、如何解决并发修改
1、加锁:乐观锁和悲观锁
3、主从复制
https://www.cnblogs.com/lqlqlq/p/14046535.html 从库执行SQL的策略
在支持 并行复制的 Mysql 版本中,从库中负责执行 relay log 的 线程 sql_thread 被分成
一个 coordination 线程 和 多个 work 线程,具体可以设置 work 线程数量,具体实现应该是使用类似线程池的方式。
每个版本有自己不同的 relay log 分配策略。
思路:
1.按表分发事务:如果多个事务更改同一个表,则最后变成单线程执行,作用不大。
每次 coordination 线程在 取 relay log 的时候,都会检查取得 relay log 的事务(按事务为单位取 relay log ?),并且分析这个事务中涉及到修改的表 的集合
1. 如果 集合 中的表 和 当前的 work 们修改的表 没有冲突,则可以直接将这个事务分配给 任意一个 work
2. 如果 集合 中的表 和 当前的 work 们的一个 work 有冲突,则直接分配给这个 work
3. 倘若 集合 中的表 和 多于 一个 work 有冲突,则coordination 线程 等待,直到只有一个 work 修改的表和 这个事务有冲突,进行 2
2.按行分发:需要解析 binlog ,太耗费资源,不被使用
3.(5.7 slave-parallel-type = DATABASE)按库分发:不常用
4.(5.7 slave-parallel-type = LOGIC_CLOCK)按照 commit_id 分发
redolog 可以组提交,意味着组提交的一组事务是可以并行执行的,因为如果不能并行执行(比如被行锁锁住),那么就不能执行 commit 事务,不能进入 prepare write 阶段,必须进入 prepare write 阶段才能使用组提交,所以可以组提交的事务们一定是能够并行执行的。将同一组事务 打上相同的 commit_id ,写入 binlog
以此,有相同 commit_id 的事务会被分发到不同的线程 ,因为他们可以并行执行。所以如果主库能够组提交更多的事务,并且从库能够开多一点线程,那么主从同步效率很高。
5.(5.7.22 控制参数 binlog-transaction-dependency-tracking)
COMMIT_ORDER : 也就是 4
WRITESET : 按照WRITE_SET , 这个 set 里的东西是 (库+表名+所有唯一索引名+所有唯一索引的值) 的 hash 值(这个hash记在binlog 中每条语句后面,以此来唯一识别一行,为什么有了主键索引,还要其他唯一索引呢?主键索引已经可以唯一识别一行了吧?), 每个事务都有自己的 WRITE_SET ,两个事务只有 SET 里的 hash 值都不相同,才能并行执行(如果无主键和唯一索引,则),表明这两个事务不会修改同一行。和2.按行分发的差不多,但是有点在于不用解析 binlog ,节省CPU时间,并且binlog 不要求是 row 格式。
WRITESET_SESSION : 被同一个session 执行的事务,也就是被同一个线程执行的事务,在从库也保证先后顺序执行
1、主库开启binlog日志
2、当从库连接上从库之后,使用io线程请求读取指定位置下的binlog日志
3、主库发送binlog日志给从库io线程,io线程将binlog日志写入重放日志文件中,并且记录读取到的binlog位置,方便下一次读取
4、从库开启SQL线程执行从放日志中的SQL语句
4、主从复制延迟咋办?
通过show slave status查看主从延时,往往出现问题就是从库写磁盘比较慢
从硬件入手:提高从库的硬件水平
从软件入手:
- 将从库的安全级别调低,就是将刷盘频率降低,减少io操作
- 增大从库的缓存空间大小
- 升级到5.7版本使用并行复制来提高效率
- 优化SQL语句
- 将大事务改成小事务
10、数据库连接
1、数据库连接
- 通过TCP三次握手与数据库建立连接
- 发送账号密码给数据库客户端验证
- 进行SQL操作
- 关闭连接,四次挥手
2、什么是数据库连接池?
就是事先创建好几个数据库连接对象,这几个数据库连接对象被数据库连接池管理,规定了连接的生命周期,防止内存泄漏。
好处:
- 资源共享,减少创建连接的时间,因此有更快的连接速度
- 统一管理,防止数据库连接泄漏(设置了空闲时间)
11、其他问题
1、数据库存储日期选择
使用timestamp来存储,这样他就能根据当地时区自动做出转化。
2、连接
内连接:只有两个连接字段相同才显示数据
左连接:无论右边的表是否存在该行都显示左行数据
右连接:和左连接相反
3、innodb4大特性
1、插入缓冲insert buffer:改名叫change buffer,主要目的是为了将访问非唯一索引的数据的非顺序io改成顺序io。实现原理:将对二级索引更改的语句按主键大小缓存起来,目的是将非顺序io改变为顺序io,之后根据策略将这个缓冲中语句顺序写入主键索引树中(叶子节点存放了真实的数据)
2、自适应哈希索引 :innodb会监控二级索引数据的访问程度,如果二级索引被频繁访问,这时innodb就会对该数据自动生成hash索引, 这个过程我们无法控制。
3、double write:在刷脏页(就是读取到内存中的被修改了的数据页)先将数据写入double write缓冲区,之后写入共享表空间中的double write中,这个过程是顺序io,一次写1M,很快,效率很高,基本不会丢失。在将double write缓冲区中的数据在使用普通的读写写入指定单独的表空间。这次写的比较小,一次只能写几k,且不是顺序io,可能会出现错误,这时要恢复只需要从doublewrite中获取到写的副本就能恢复了。
4、预读
9、触发器
有点像函数的回调,在某些条件成立的时候会自动执行触发器的内容,比如用来级联删除一些东西。有六种触发器,增删改的前后,一共六次。
10、存储过程
就好像java中的方法,能够复用,在一定条件下保护了数据安全。
12、视图
1、什么是视图
视图就是虚拟的表,数据是真实表中的数据,能够获取多个表中的数据。
但是存储的是SQL语句,并不会存储真实的数据
对视图的修改会修改到基表,但是如果数据来自多个基本表,则不允许添加和删除。
2、视图的优缺点
1、能够保护数据,这只是一张虚拟的表,用来展现数据
2、在要修改展示的数据时,能够使用视图来显示,而不必修改基本表
3、简化SQL查询,就好像查询一张表一样查询视图,不同再去复杂的写那些联表查询了。
13、SQL语法
各子句执行顺序:Select from where group by having order by limit
1、DDL
1、添加索引
https://www.cnblogs.com/sunAnqing/p/15930592.html
[值]表示可选,这里不显示给索引名将会自动生成一个
#添加公共方法索引
alter table 表名 add 索引类型 [索引名] (加在哪一列)
#具体添加主键索引
alter table 表名 add primary key [索引名] (列名)
#添加唯一索引
alter table 表名 add union [索引名] (列名)
#添加普通索引
alter table 表名 add index [索引名] (列名)
#添加复合索引
alter table 表名 add index [索引名] (列1,列2)
#添加全文索引
alter table 表名 add fulltext [索引名] (列名)
2、删除索引
#删除索引
alter table 表名 drop index 索引名
#例子,删除主键索引不需要名字,因为他是唯一的
alter table customers drop primary key;
#方法二
drop index 索引名 on 表名
2、limit字句
limit 起始行号,行数,结果为:[行号,行号+行数-1],因为行号是从0开始计算的。
简写limit 行数,这样默认从第一行即0行开始拿行数条数据。
limit字句一般放在最后面。
3、order by
可以使用order by进行排序
select prod_id,prod_price,prod_name from products order by prod_price[desc],prod_name [desc];
这句话的意思是先按照price进行排序, 如果遇到相同的price时,才使用name进行排序,否则不使用name字段进行排序。
可以指定排序方向,使用desc来选择降序排序
指定多个字段时,还可以对各个字段进行指定升序还是降序。9-2
4、where字句
常用的有:=,<>(不等于),!=,<,<=,>,>=,between 参数 and 参数(相当于闭区间)
5、连接函数concat()
这个相当于java中的string类的+。
语法:concat(列名,‘字符串’,列名,‘字符串’) 这个用在列名上,用来重写组装一列。
比如说:商品名(产地),商品名 是一个列,产地是一个列,要将他们合并为一列,只需要
select concat(商品名,'(',产地,')') from product;
6、RTrim()函数
用来去掉括号中列数据的右边的空格,如:一个数据为:广东空格空格,使用Rtrim之后,就会去掉空格为广东。
7、在列名上进行算数运算
这样可以新增一列计算后的数据,例如表中有基本价格和折扣力度,我们要求最后的价格
select name,price,discount,price*discount as finalprice;
8、Group by
https://blog.csdn.net/qq_35069223/article/details/84343961
group by 是先分完组之后才使用聚合函数来进行计算的。
group by主要是用来配合聚合函数来进行处理数据表。
group by后面可以接多个数据列,多个数据列会看成一个整体,只有整体相同的时候才会聚合成一行。
聚合时因为,一行一个空只能有一个值,所以,多余的值需要使用聚合函数进行聚合,比如说求和。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EWKLlai0-1668351948923)(http://upload.lihuijun.fun/img/image-20220810193908455.png)]
总结:group by就是将后面的列看成一个整体进行找相同,整体相同的行分在一起,有一列或者多列不同的值需要使用聚合函数求和,或者不要显示该行数据,因为一行只能显示一个数据。
比如下面的例子:

要求:按照年级求每个班男女同学的总分。
#按照年级、班级、性别求总分
select year,class,sex,sum(score) sum
from students inner join sc on students.id=sc.sid
GROUP BY year,class,sex;
这里将year class sex看成一个整体,相同的才会聚合计算。

create table students(
id int PRIMARY key,
class int not null,
name varchar(10) not null,
year int not null);
create table sc(
cid int PRIMARY key,
sid int not null,
cname varchar(10) not null,
foreign key(sid) references students(id));
insert into students
values(1,1,'lihua',2019),
(2,1,'zhangsan',2019),
(3,2,'lisi',2019),
(4,2,'wangwu',2019);
alter table sc add score int;
insert into sc values(1,1,'数学',99),(2,1,'语文',99),
(3,2,'数学',99),(4,2,'语文',99),
(5,3,'数学',99),(6,3,'语文',99),
(7,4,'数学',99),(8,4,'语文',99);
#查询每个学生的总分
select year,class,sum(score) sum, name from sc,students where sc.sid=students.id group by year,class,students.id;
#按年份查询每个班级的总分
select year,class,sum(score) sum from sc inner join students on students.id=sc.sid group by year,class;
#修改学生表增加一个性别列
alter table students add sex int;
#向性别插入数据0表示女,1表示男
update students set sex=1 where students.id in (1,3);
update students set sex=0 where students.id in (2,4);
#将性别反转
update students set sex=if(sex=1,0,1) ;
#按照年级、班级、性别求总分
select year,class,sex,sum(score) sum
from students inner join sc on students.id=sc.sid
GROUP BY year,class,sex;
9、IF语句
https://blog.csdn.net/weixin_45659364/article/details/115468039
1、IF(expr1,expr2,expr3); 如果expr1为TRUE,则IF()返回值为expr2,否则返回值为expr3
update salary set sex =if(sex = ‘男’,‘女’,‘男’)
#这是leetcode上的一道题,将salary表中的性别进行转换,男变女,女变男
有点像三元表达式
2、ifNULL
IFNULL(expr1,expr2) 假如expr1不为null,则返回expr1,否则返回expr2
3、IF…ELSE…语句
IF search_condition THEN
statement_list
ELSE
statement_list
END IF;
和普通的if else语句类似,只不过多了then,和linux中shell编程类似
search_condition表示条件,如果成立时执行THEN后面的statement_list语句,否则执行ELSE后面的statement_list语句。
search_condition是一个条件表达式,可以由条件运算符组成,也可以使用AND、OR、NOT对多个表达式进行组合
10、常见字符处理函数(重要
https://blog.51cto.com/u_13737909/4828038
主要有concat、left、right、upper、lower、substring、insert(替换),还有length()获取长度
这里left(str,length)指的是长度
concat()拓展,group_concat()将分组后的多个数据合并,并且使用逗号分割,可以使用distinct来去重,默认按照字典排序
Group_concat(distinct product) products

11、正则表达式
这个可以去java基础看
使用regexp ‘正则表达式’ 来筛选字符串
12、几种连接方式
https://www.jb51.net/article/247214.htm#_label5
https://dev.mysql.com/doc/refman/8.0/en/join.html 官网
table_reference {[INNER] JOIN | {LEFT|RIGHT} [OUTER] JOIN} table_reference ON conditional_expr
https://blog.csdn.net/Sihang_Xie/article/details/125571345 这个有图
mysql没有full join连接,就是不能将不同的数据空出来。
https://blog.csdn.net/weixin_42103983/article/details/107047928
left join 和left outer join是一样的,outer可以省略
13、case when语句
https://blog.csdn.net/u013514928/article/details/80969949
https://www.cnblogs.com/chenduzizhong/p/9590741.html
https://blog.csdn.net/weixin_44688973/article/details/118808601 这个简单一些
http://www.mybatis.cn/archives/916.html 这个比较标准

这里的值1,值2就是字段3查表中获取的值。

这个有点像if elseif elseif语句,case就是开始表示符,而when就elseif
最后结尾需要end来表示结束。
练习看4-3
SELECT u.user_id buyer_id, join_date, SUM(CASE YEAR(order_date) WHEN '2019' THEN 1 ELSE 0 END) orders_in_2019
FROM Users u LEFT JOIN Orders o
ON u.user_id = o.buyer_id
GROUP BY u.user_id
14、时间处理函数
https://blog.csdn.net/m0_70157790/article/details/124728924?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-124728924-blog-123365010.t0_layer_eslanding_sa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-124728924-blog-123365010.t0_layer_eslanding_sa&utm_relevant_index=10
时间相差值
datadiff(date1,date2),使用date2-date1来获取差值。练习看SQL练习6-1
timediff(datetime1,datetime2) select timediff(‘2021-02-06 15:02:41’,‘2021-02-05 15:28:56’) – 结果 23:33:45
日期时间向加减
https://blog.csdn.net/web18334137065/article/details/124150039 日期相加减返回日期对象
date_add(‘某个日期时间’,interval 数量 时间种类名);
date_add(‘1998-01-01’, interval 1 day);
date_sub(‘1998-01-01’, interval 1 day);
注意:时间相加减千万不能使用简单的减号和加号。这样他计算会按照10进制来计算,不是按照月份计算

max()等函数也可以计算日期的最大值。
15、having字句
这个是和group by字句配合使用的。对分组后求得的合并列值进行过滤。
比如说:求每个人花钱数的排名。因为每条消费记录是分开的,所有使用人的id聚合起来之后,将所有消费金额使用sum计算完成之后,可以对总额进行过滤,也就是说having子句中可以使用sum()、count()等聚合函数,这是和where子句不同的地方。
having子句必须放在group by子句后面,不然会报错
select Email from person
group by Email
having count(id)>=2;
16、Round(数值,小数位数)
Round(数值,保留小数的位数)
他会自己四舍五入进行计算。
17、数值处理函数
好像这些函数都可以使用逻辑表达式来计算符合逻辑的行数。但是count不行
1、sum(重要
SUM(DISTINCT expression) //更多请阅读:https://www.yiibai.com/mysql/sum.html
这个函数是求该列的总和的,参数可以为列,也可以统计符合条件的行数,即逻辑判断,有点牛逼
select round (
#这里可以是逻辑判断
sum(order_date = customer_pref_delivery_date) /
count(*) * 100,
2
) as immediate_percentage
from Delivery
作者:LeetCode-Solution
链接:https://leetcode.cn/problems/immediate-food-delivery-i/solution/ji-shi-shi-wu-pei-song-i-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2、avg(重要
他会对分完组后的数据,对每个分组分别进行求平均值。
1173. 即时食物配送 I
求平均值,这个也可以使用逻辑判断语句,统计的是符合条件行数占总行数的大小,即符合条件/分组后每个分组的总行数
avg好像和sum不能嵌套使用,因为avg会自动求和后计算平均值
#avg用法,这个不用求总数
select round(avg(order_date = customer_pref_delivery_date) * 100, 2) as immediate_percentage
from Delivery;
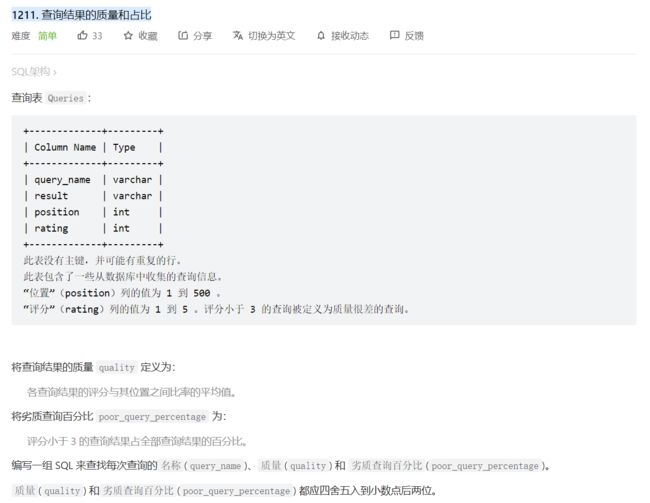
1211. 查询结果的质量和占比
select query_name, round(avg(rating/position),2) quality,
round(avg(rating<3)*100,2) poor_query_percentage
from queries
group by query_name;
18、窗口函数(组内排名
https://www.cnblogs.com/SmithBee/p/16056458.html 详细
https://blog.csdn.net/weixin_57355007/article/details/125314046 粗略
语法:


1112. 每位学生的最高成绩
这是14.2 3-3
使用这个函数之后不必使用group by进行分组了
19、count函数
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
20、递归处理函数
https://www.cnblogs.com/guohu/p/14990788.html
group_concat 函数更强大,可以分组的同时,把字段以特定分隔符拼接成字符串。
用法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
可以看到有可选参数,可以对将要拼接的字段值去重,也可以排序,指定分隔符。若没有指定,默认以逗号分隔。
14、SQL练习
1、总结
当遇到一张表的时候,考虑自连接,或者新建一张临时表进行链接
行转列、列转行
对于一些范围问题,先进行筛选数据,之后考虑分组,最后使用计算函数进行计算,
对于一些聚集函数如max()、sum(),这些都相当于是在遍历表中的数据,且会自动维持一个临时变量来实现函数功能。
例如sum函数,在遍历的时候会自动将遍历到的行的结果存下来,这个结果我们是可以改变的,sum函数就是让该列所有值加起来,我们可以在遍历的时候使用if表达式修改当前行的当前值,从而来改变计算结果,练习看:9-1
#通过if来改变行的值。
select stock_name , sum(if(operation='buy',-price,price)) capital_gain_loss
from stocks
group by stock_name
如果正向数据不好分析,就使用逆向数据来过滤,使用not in 或者 not exist
分组操作
对于分组操作,分为两组
1、group by
这个主要是直接分组,对组内多个行按照分组表识列进行聚合,不能对每个分组的每个行进行单独操作
配合having字句对分组整体进行操作。
2、窗口函数over
这个能对分组的每个行进行单独操作,相当于每个分组是一个单独的表,可以进行排序
14.2 3-3
转换思路
对于一个表内的顺序交换,可以交换id而不是数据部分
14.2 6-2
单表上下有联系的
一般可以使用笛卡尔集,通过计算主键的差值为1来判断是否连续,使用abs来相减,且还要注意去重,因为下面的会拿到上面的,下面的也会拿到上面的。
14.2 7-1
2、排序&修改
1、删除重复邮箱
196. 删除重复的电子邮箱


#删除重复邮箱
create table person(
id int,
email varchar(20));
insert into person
values
(1,'[email protected]'),
(2,'[email protected]'),
(3,'[email protected]');
#官方解法,说实话有点难理解,就是先根据两个条件自连接,之后删除p1中p1.id>p2.id的记录,还是下面的好理解。
DELETE p1.*
from Person p1, Person p2
where p1.email = p2.email and p1.id > p2.id
#就是使用分组去重,并且找到最小的那一个,使用where来删除不满足的记录
#这里会报错说不能修改查询到的值。可能的原因为生成的readview,解决方法:添加一个临时表即可
delete from person where id not in (select min(id) id from person t group by email);
#解决方法
# 方法一:DELETE + 子查询,实测效率更高
DELETE FROM Person
WHERE Id NOT IN ( -- 删除不在查询结果中的值
SELECT id FROM
(
SELECT MIN(Id) AS Id -- 排除Email相同时中Id较大的行
FROM Person
GROUP BY Email
) AS temp -- 此处需使用临时表,否则会发生报错
)

方法二就是删除where字句
2、变更性别
627. 变更性别

这个使用if函数很快解决
update set sex=if(sex='f','m','f');
if语句的意思看下面
3、计算特殊奖金
1873. 计算特殊奖金

select employee_id,if(employee_id%2!=0 and name not like 'M%',salary,0) bonus from employees
order by employee_id;
同样也是使用if字句来写。第一个表达式是要返回一个布尔值。但是=号是只写一个就表示判断内的。
3、字符串处理函数/正则
1、1667. 修复表中的名字
使用字符串处理函数来解决
先使用left找到开头的一个字母,right+length找到右边的字母,分别去大小写之后使用concat()来拼接
select user_id,concat(upper(left(name,1)),lower(right(name,length(name)-1))) name from users order by user_id;
2、1484. 按日期分组销售产品(重要
concat()拓展,group_concat()将分组后的多个数据合并,并且使用逗号分割,可以使用distinct来去重,默认按照字典排序
select sell_date,count(distinct product) num_sold,
Group_concat(distinct product) products
from Activities
group by sell_date
order by sell_date;
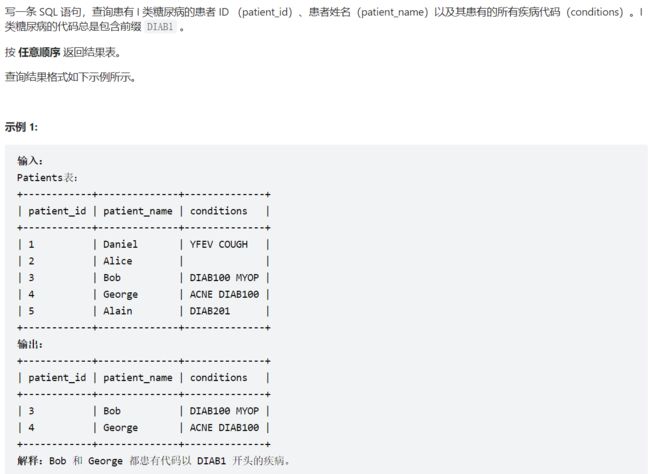
3、1527. 患某种疾病的患者
这个可以使用模糊匹配来写,也可以使用正则表达式来写
模糊匹配为:
# 注意上面的DIAB1前有一个空格,防止匹配到类似'ABCDIAB1'这种字符串
select * from patients where conditions like '% DIAB1%' or like 'DIAB1%'
# 为了匹配conditions字段以DIAB1开头的记录,因此没有空格


4、组合查询 & 指定选取
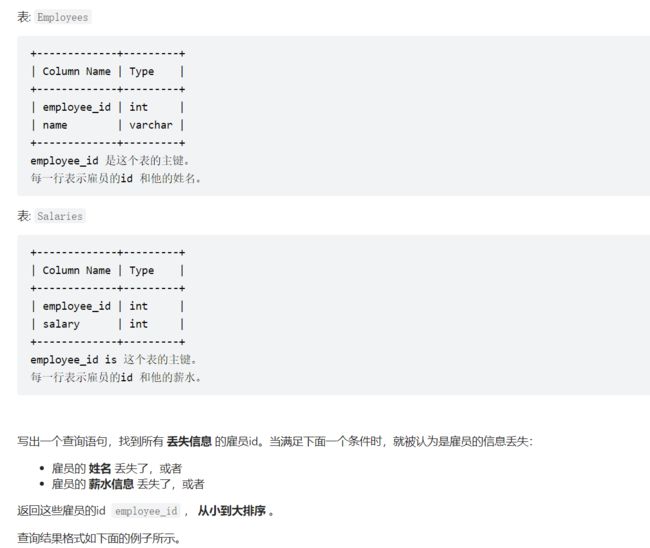
1、1965. 丢失信息的雇员


因为mysql不支持 full join,因此使用union和left join、right join来组合成全连接。
select employees.employee_id from employees left join salaries
on employees.employee_id=salaries.employee_id
where salaries.salary is null
union #union可以去重,去重就是去掉了4和5重复的那一个。
select salaries.employee_id from employees rigth join salaries
on employees.employee_id=salaries.employee_id
where employees.name is null
2、1795. 每个产品在不同商店的价格(重要

这有一个总结:https://leetcode.cn/problems/students-report-by-geography/solution/zong-jie-ge-lei-biao-ge-ge-shi-hua-wen-t-tl4e/
这题考察的行转列和列转行,他将行转为列store1转为store1列是直接拿结果我是没想到的。
使用union all将第一条SQL和下面的SQL拼接起来。
select product_id,'store1' as store,store1 price from products
where store1 is not null
union all #不去重,将上面作为行输出
select product_id,'store2' as store ,store2 price from products
where store2 is not null
union all #不去重,将上面作为行输出
select product_id,'store3' as store ,store3 price from products
where store3 is not null
#下面是将上面转化号的表又转换回去,其实就是使用分组+计算值来解决。
SELECT
product_id,
SUM(IF(store = 'store1', price, NULL)) 'store1',
SUM(IF(store = 'store2', price, NULL)) 'store2',
SUM(IF(store = 'store3', price, NULL)) 'store3'
FROM
Products1
GROUP BY product_id ;
作者:ESQIImULMe
链接:https://leetcode.cn/problems/rearrange-products-table/solution/by-esqiimulme-pjiy/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3、608. 树节点

使用左连接将此节点和他的子节点连接起来。self.id=child.id,这样查找叶子节点就是child.id=null
查找根节点就是self.parentid=null
查找中间节点就是self.parentid!=null,child.id!=null


4、176. 第二高的薪水

# Write your MySQL query statement below
#这里使用临时表来避免只有一条数据。
select(select distinct salary from employee order by salary desc limit 1,1) SecondHighestSalary
5、合并
1、175. 组合两个表

select firstName,lastName,city,state from person left join address
on person.personId=address.personId
2、1581. 进店却未进行过交易的顾客

先让两张表使用visitid进行左连接,这样没消费的却光临过的那一行的交易号就会为空,这时为了按人统计,所以就使用用户id来进行分组,这样就能统计来的次数和消费次数的差值了。
select customer_id,count(visits.visit_id)-count(transaction_id) count_no_trans
from visits left join transactions on visits.visit_id=transactions.visit_id
where transactions.transaction_id is null
group by visits.customer_id
3、1148. 文章浏览 I

太简单
select distinct author_id id from views where author_id=viewer_id order by author_id;
6、合并
1、197. 上升的温度


此题关键:计算时间之间的差值。使用DateDiff(date1,date2)函数,date1,date2:合法的日期或日期/时间表达式。
datediff():返回两个日期或时间之间的天数。注意这个函数是使用后面的date2-date1来获取差值,也就是说后面的数要比date1大才会返回正值。
下面是我自己的方法,效率较低。但是好理解:对每一天查找所有后一天的数据,如果后一天温度大于前一天温度,则返回后一天的id,这里a相当于后天,而b则为前一天。
效率高的写法是将两个表进行笛卡尔积,查找差值为一天的值,比较即可。
select id from weather a
where a.temperature>(select temperature from weather b
where datediff(a.recorddate,b.recorddate) =1)
2、607. 销售员

#查找向red交易过的销售,需要和order联表,需要去重,因为一个交易员可以多次交易
select distinct salesperson.sales_id from salesperson,company,orders
where salesperson.sales_id=orders.sales_id and orders.com_id=company.com_id
and company.name='RED';
#既然找到了交易过得,那么现在找所有交易员不在这份名单中的人
select name from salesperson where sales_id not in
(select distinct salesperson.sales_id from salesperson,company,orders
where salesperson.sales_id=orders.sales_id and orders.com_id=company.com_id
and company.name='RED')
7、计算函数
1、1141. 查询近30天活跃用户数

select activity_date day, count(distinct user_id) active_users from activity
#先找出截止日期之前30天的日期
where activity_date between '2019-06-28' and '2019-07-28'
#按照日期聚合
group by activity_date
这里日期有点问题,不做细究
日期加减法:Date_sub,Date_add ,可以看13-14
2、1693. 每天的领导和合伙人

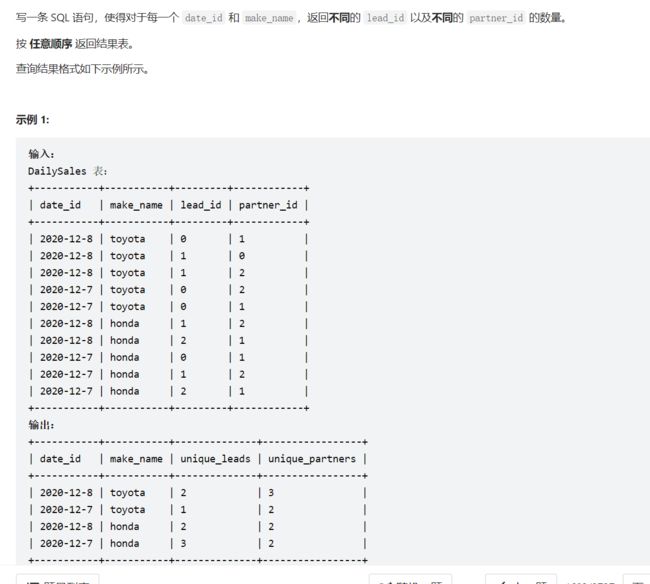
# Write your MySQL query statement below
select date_id,make_name,count(distinct lead_id) unique_leads ,
count(distinct partner_id) unique_partners from dailysales group by date_id,make_name;
此题没啥意义,只是单纯的使用group by 和count 和distinct而已。
3、1729. 求关注者的数量
此题也很简单
select user_id,count(distinct follower_id) followers_count
from followers group by user_id
order by user_id;
8、计算函数
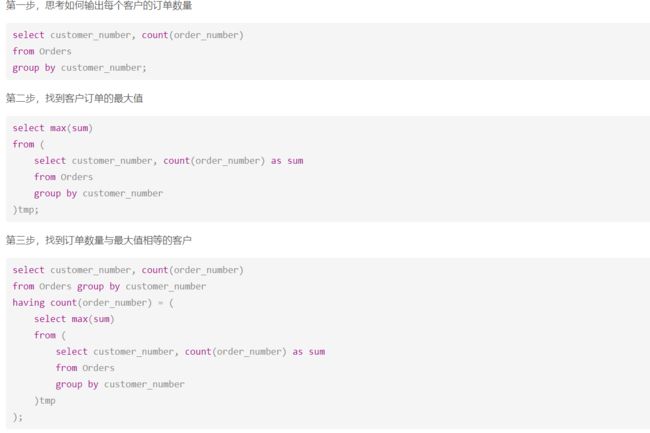
1、586. 订单最多的客户

先分组后倒叙求第一条即可。
select customer_number from orders
group by customer_number
order by count(order_number) desc limit 1
我觉得也可以使用having来解决
评论区中的,和我想的差不多。因为它要求得是用户id,所以还有再使用第四部来求用户id.

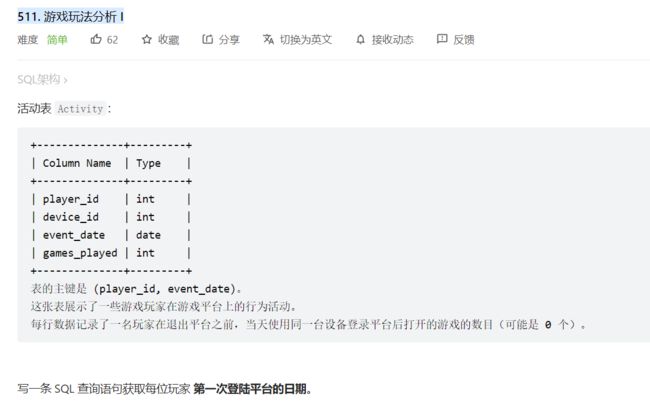
2、511. 游戏玩法分析 I

这个比较简单,聚合求最小值即可
select player_id ,min(event_date) first_login from activity
group by player_id ;
3、1890. 2020年最后一次登录
select user_id,max(time_stamp) last_stamp from logins
where time_stamp>='2020-01-01 00:00:00' and time_stamp<='2020-12-31 23:59:59'
group by user_id;
思路比较简单:先使用where条件过滤时间,在这些时间内聚合求最大值
4、1741. 查找每个员工花费的总时间

思路:先按照人和日期将那人一天内的进出统计起来,计算差值的总和即可。

#先按照人和日期将那人一天内的进出统计起来
select event_day day,emp_id,sum(out_time-in_time) total_time
from employees
group by emp_id,event_day
9、控制流
1、1393. 股票的资本损益

本题使用if控制流来改变当前值
select stock_name , sum(if(operation='buy',-price,price)) capital_gain_loss
from stocks
group by stock_name
2、1407. 排名靠前的旅行者

这题也比较简单,先用左连接连接两表,之后使用if判断进行让没有骑行记录的人距离为0即可。
select name,sum(if(distance is null,0,distance)) travelled_distance
from users left join rides on users.id=rides.user_id
group by users.id
order by travelled_distance desc,name;
#使用ifnull 也是可以的,直接拿最后的结果进行置换。
IFNULL(SUM(r.distance),0)
3、1158. 市场分析 I
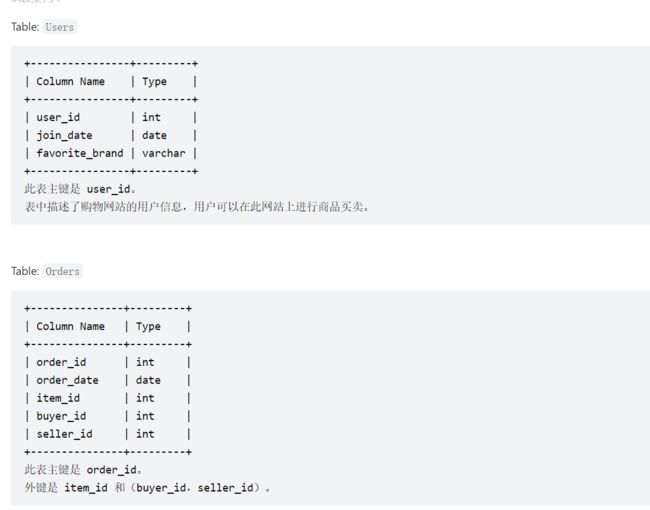

#这个也比较简单,只是左连接使用日期过滤,使用id分组,使用count统计即可。
select users.user_id buyer_id,join_date,ifnull(count(order_id),0) orders_in_2019
from users left join orders on users.user_id=orders.buyer_id
and order_date between '2019-01-01' and '2019-12-31'
group by users.user_id;
10、过滤
1、182. 查找重复的电子邮箱

select Email from person
group by Email
#having子句必须放在group by后面,不然报错,因为线分组后过滤嘛
having count(id)>=2;
2、1050. 合作过至少三次的演员和导演

select actor_id,director_id from actorDirector
group by actor_id,director_id
having count(timestamp)>=3
和上面一样。
3、1587. 银行账户概要 II
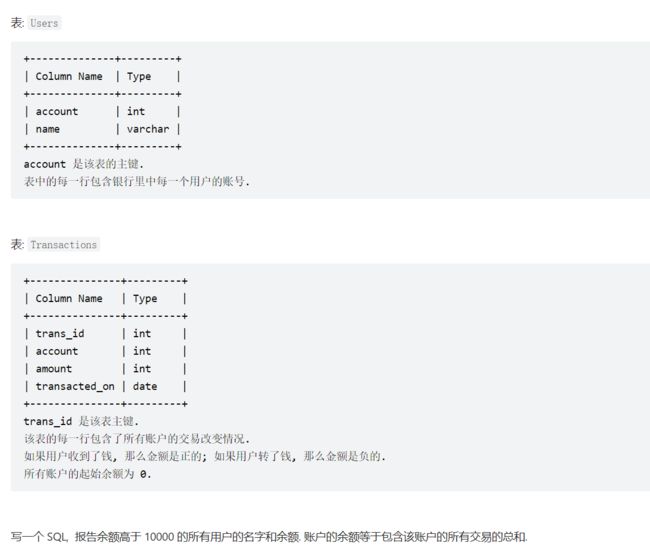
简单
having 子句的作用
select name,sum(amount) balance from users inner join transactions on users.account=transactions.account
group by users.account
having sum(amount)>=10000
4、1084. 销售分析III

使用排除法来解决
select product_id,product_name from product
where product_id not in (
#查找在其他日期销售过的id,使用not in来排除掉
select product_id from sales
where sale_date<'2019-01-01' or sale_date>'2019-03-31'
) and product_id in (
#防止在春季也没有卖过的商品出现在这里
select product_id from sales
where sale_date between '2019-01-10' and '2019-03-31'
)
#大神写法
SELECT p.product_id,product_name FROM sales s,product p
WHERE s.product_id=p.product_id
GROUP BY p.product_id
#直接统计在最大值和最小值日期以外的订单数
HAVING SUM(sale_date < '2019-01-01')=0
AND SUM(sale_date>'2019-03-31')=0;
14.2、SQL练习2
1、数值处理函数
1、1699. 两人之间的通话次数

人家已经有提示了,让person1 此题的新函数Round(数值,保留小数的位数) 警示我们要使用关联 此题使用窗口函数比较好写,因为直接使用排名就能获取到对应的值,不过要注意使用窗口函数的排名时,不能直接获取到,因为他是一个临时表,排名需要生成临时表后才能使用该字段 sum函数的使用,可以使用条件判断的。 直接分成经理表和员工表好了,这里注意四舍五入可以使用Round函数自动实现。 针对的是单表查询,但是也可以直接使用注解来写SQL https://blog.csdn.net/feiying0canglang/article/details/123681896 from countries c, weather w [外链图片转存中…(img-iVry6Xiv-1668351948952)] [外链图片转存中…(img-nC1JrRrN-1668351948953)] sum函数的使用,可以使用条件判断的。 [外链图片转存中…(img-4YFgEuXK-1668351948953)] [外链图片转存中…(img-nB5zq9qr-1668351948954)] 直接分成经理表和员工表好了,这里注意四舍五入可以使用Round函数自动实现。 针对的是单表查询,但是也可以直接使用注解来写SQL https://blog.csdn.net/feiying0canglang/article/details/123681896 https://blog.csdn.net/lizhe0327/article/details/119759208#要想找到打电话双方所有记录,首先得对原表进行处理一下,让id号小的在前面,之后使用group by,就能实现了
select
person1,person2,
count(*) call_count,
sum(duration) total_duration
from (
select
#这里的if是拿原数据行进行比较和替换的,所以结果集不会改变原表数据
if(from_id>to_id,to_id,from_id) person1,
if(from_id>to_id,from_id,to_id) person2,
duration
from calls
) a
group by person1,person2
2、1251. 平均售价

#先计算每个价格区间的总价,之后使用聚合求总和,在求平均值
select product_id, Round(sum(sums)/sum(units),2) average_price
from (
#查询出各购买日期的总价格和数量,之后外查询在聚合取值即可
select prices.product_id,price*units sums,units
from prices,unitssold
where prices.product_id=unitssold.product_id
and purchase_date>=start_date and purchase_date<=end_date
) temp
group by product_id;
3、1571. 仓库经理

#较为简单,使用分组聚合即可
select name warehouse_name,sum(width*products.length*height*units) volume
from warehouse,products
where warehouse.product_id=products.product_id
group by name
4、1445. 苹果和桔子

#比较简单,自关联,过滤两个水果相同的行和左边为橘子以及右边为苹果的行计算即可
select a.sale_date,a.sold_num-b.sold_num diff
from sales a,sales b
where a.sale_date=b.sale_date and b.fruit!='apples' and a.fruit!='oranges'
group by a.sale_date
2、数值处理函数
1、1193. 每月交易 I

#此题也比较简单,只需要通过使用left来获取子串聚合日期和国家,通过sum和if来条件判断统计条件即可
select left(trans_date,7) month,country,count(*) trans_count,
sum(if(state='approved',1,0)) approved_count,sum(amount) trans_total_amount,
sum(if(state='approved',amount,0)) approved_total_amount
from transactions
group by left(trans_date,7),country
2、1633. 各赛事的用户注册率

#此题也比较简单,只需要使用子查询,查询出所有人数相除就行
select contest_id ,round(count(*)/(
select distinct count(*) from users
)*100,2) percentage
from register
group by contest_id
order by percentage desc,contest_id ;
3、1173. 即时食物配送 I
select round (
sum(order_date = customer_pref_delivery_date) /
count(*) * 100,
2
) as immediate_percentage
from Delivery
select round (
sum(case when order_date = customer_pref_delivery_date then 1 else 0 end) /
count(*) * 100,
2
) as immediate_percentage
from Delivery
#自己的
select round(count(*)/(
select count(*) from delivery
)*100,2) immediate_percentage from delivery
where order_date=customer_pref_delivery_date
#avg用法,这个不用求总数
select round(avg(order_date = customer_pref_delivery_date) * 100, 2) as immediate_percentage
from Delivery;
4、1211. 查询结果的质量和占比

select query_name, round(avg(rating/position),2) quality,
round(avg(rating<3)*100,2) poor_query_percentage
from queries
group by query_name;
3、连接
1、1607. 没有卖出的卖家


#打败了50%
select
seller_name
from
Seller a
left join
Orders b
on a.seller_id=b.seller_id
and year(sale_date)=2020
where b.order_id is null
order by seller_name
#打败了5%
select seller_name from seller
where seller_id not in(
select distinct seller_id from orders
where year(sale_date)=2020
)
order by seller_name
2、619. 只出现一次的最大数字

#比较简单,先子查询后判断即可
select ifnull(max(num),null) num
from (
select num
from mynumbers
group by num
having count(*)=1
) a
3、1112. 每位学生的最高成绩

#使用窗口函数写法
select student_id,course_id,grade
from (
select *,
#这个函数是求排名的,同时使用over表示对分组后进行组内排名
rank() over(
partition by student_id
order by grade desc,course_id asc
) ranking
from enrollments
) a
where ranking=1
order by student_id
#常规写法,两者时间上好像差不多,这个比较快
#先分组找出所有分数最大的行,在找出count_id最小的返回即可
SELECT
student_id, min(course_id) AS course_id, grade
FROM
Enrollments
WHERE
(student_id, grade)
IN(
#这个子查询只取出了id和成绩,没有取出课程号,这样就能使用这个条件来查找最课程号最小的值了。
SELECT
student_id, max(grade)
FROM
Enrollments
GROUP BY
student_id
)
#因为我们是通过id和成绩来查课程id,所以这里要组合分组。
GROUP BY student_id, grade
ORDER BY student_id ASC
作者:JinZou
链接:https://leetcode.cn/problems/highest-grade-for-each-student/solution/san-bu-jie-ti-by-nian-nian-be-if34/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
4、1398. 购买了产品 A 和产品 B 却没有购买产品 C 的顾客(重要

select o.customer_id,customer_name
from orders o,customers c
where o.customer_id=c.customer_id
group by o.customer_id
#下面就是买了a,b却没买c的过滤,统计分组后组内的各个数量
having sum(product_name='A')>0 and sum(product_name='B') and sum(product_name='C')=0
4、连接
1、1440. 计算布尔表达式的值

select left_operand,operator,right_operand,
case
when operator='>' then if(v1.value>v2.value,'true','false')
when operator='=' then if(v1.value=v2.value,'true','false')
when operator='<' then if(v1.value<v2.value,'true','false')
end value
from expressions e
left join variables v1 on e.left_operand=v1.name
left join variables v2 on e.right_operand=v2.name
这题卡了很久是因为没认真看题目,我还以为只有一个表呢,这里要使用左连接将x和y的值赋值上去。
2、1264. 页面推荐

#找出id为1的所有朋友 再找出他朋友喜欢页面,查找自己喜欢的页面,取差集
select page_id recommended_page
from (
#找到朋友们喜欢的页面
select distinct page_id from likes where user_id in(
#首先得查找到user_id=1的朋友们
select user2_id from (
#因为朋友是相互的,所以要将他们排好序再来求朋友,将序号小的放前面,序号大的放后面
select if(user1_id>user2_id,user2_id,user1_id) user1_id,
if(user1_id<user2_id,user2_id,user1_id) user2_id from friendship
) s where user1_id=1
)
)a
where page_id not in(
#查询我喜欢的界面,之后将其排除即可
select page_id from likes where user_id=1
)
#官方使用union all来查找所有朋友
SELECT DISTINCT page_id AS recommended_page
FROM Likes
WHERE user_id IN (
SELECT user1_id AS user_id FROM Friendship WHERE user2_id = 1
UNION ALL
SELECT user2_id AS user_id FROM Friendship WHERE user1_id = 1
) AND page_id NOT IN (
SELECT page_id FROM Likes WHERE user_id = 1
)
#用case来查找朋友
SELECT (
CASE
WHEN user1_id = 1 then user2_id
WHEN user2_id = 1 then user1_id
END
) AS user_id
FROM Friendship
WHERE user1_id = 1 OR user2_id = 1
#case完整写法
SELECT DISTINCT page_id AS recommended_page
FROM Likes
WHERE user_id IN (
SELECT (
CASE
WHEN user1_id = 1 then user2_id
WHEN user2_id = 1 then user1_id
END
) AS user_id
FROM Friendship
WHERE user1_id = 1 OR user2_id = 1
) AND page_id NOT IN (
SELECT page_id FROM Likes WHERE user_id = 1
)
作者:LeetCode-Solution
链接:https://leetcode.cn/problems/page-recommendations/solution/ye-mian-tui-jian-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3、570. 至少有5名直接下属的经理

#比较简单
select a.name
from employee a left join employee b on a.id=b.managerid
group by a.id
having count(*)>=5
4、1303. 求团队人数

#比较简单,生成一个临时表连接即可
select employee_id,team_size
from (select team_id,count(*) team_size from employee group by team_id) a,employee
where a.team_id=employee.team_id
5、连接
1、1280. 学生们参加各科测试的次数


# select a.student_id,a.student_name,examinations.subject_name,count(examinations.student_id) attended_exams
# from (
# select student_id,student_name,subject_name
# from students join subjects
# ) a left join examinations on a.student_id=examinations.student_id
# and a.subject_name=examinations.subject_name
# group by a.student_id,a.subject_name
# order by a.student_id,a.subject_name
#我觉得上面的一个也是行的,但是老是出现null值,这题我悟了能够连续连接。使用笛卡尔积为 join
select stu.student_id, stu.student_name, sub.subject_name, count(e.student_id) as attended_exams
from Subjects sub join Students stu left join Examinations e
on e.subject_name = sub.subject_name and e.student_id = stu.student_id
group by sub.subject_name, stu.student_id
order by stu.student_id, sub.subject_name;
2、1501. 可以放心投资的国家


# Write your MySQL query statement below
#首先得找出通话记录中各个国家的通话时长,根据用户表的电话号码和用户id来确定
#让country和person联表,得到用户id和国家号
select p.id,p.name,p.phone_number,c.name,c.Country_code
from person p inner join country c on left(p.phone_number,3)=c.Country_code
#使用用户id和calls表的caller和callee分别连接,因为他是单独计算
select cname,avg(duration)
from (
select p.id,p.name pname,p.phone_number,c.name cname,c.Country_code
from person p inner join country c on left(p.phone_number,3)=c.Country_code
) b inner join calls on b.id=calls.caller_id or b.id=calls.callee_id
group by cname
#此时已经计算出每个国家的平均值,要算出全球的就直接对calls avg*2
select avg(duration) global
from calls
#将两个表进行比较即可
select cname country
from (
select cname,avg(duration) avgs
from (
select p.id,p.name pname,p.phone_number,c.name cname,c.Country_code
from person p inner join country c on left(p.phone_number,3)=c.Country_code
) b inner join calls on b.id=calls.caller_id or b.id=calls.callee_id
group by cname
) t,(
select avg(duration) global
from calls
) y
where t.avgs>global
3、184. 部门工资最高的员工


select d.name department,e.name employee,salary,rank() over(
partition by d.id
order by e.salary desc) ranks
from employee e inner join department d on e.departmentId=d.id
where ranks=1
#上面作为错误示范,使用窗口函数的字段必须使用临时表
select d.name department,e.name employee,salary
from (
select * ,
rank() over(partition by departmentId order by salary desc) as ranks
from employee
) e left join department d on e.departmentId=d.id
where e.ranks=1
4、580. 统计各专业学生人数

6、连接
1、1294. 不同国家的天气类型

# 比较简单,按照要求组装即可
select country_name,
case
when avg(weather_state)<=15 then 'Cold'
when avg(weather_state)>=25 then 'Hot'
else 'Warm'
end weather_type
from weather inner join countries on weather.country_id=countries.country_id
where day between '2019-11-01' and '2019-11-30'
group by country_name
#这里可以使用like来进行一个月份的匹配,不要忘了
select c.country_name,
case when sum(weather_state)/count(*)<= 15 then 'Cold'
when sum(weather_state)/count(*) >= 25 then 'Hot'
else 'Warm' end weather_type
from countries c, weather w
where c.country_id = w.country_id
and day like "2019-11%"
group by c.country_name
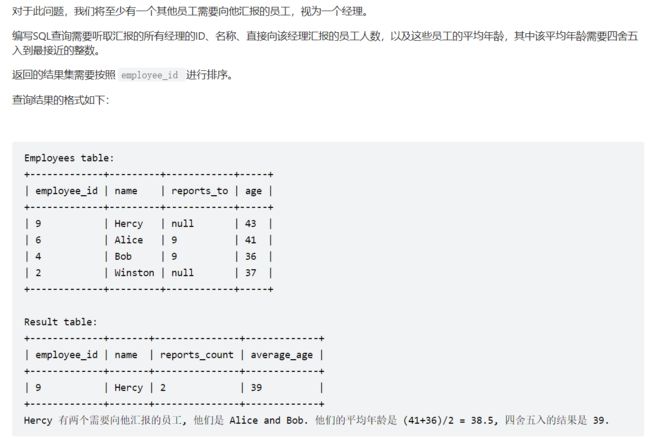
2、626. 换座位
# Write your MySQL query statement below
#应该对id进行改变,而不是改变名字
select case
#这一句用来判断id为最后一个且总数为奇数的情况
when id%2=1 and id=(select count(*) from seat) then id
when id%2=1 then id+1
when id%2=0 then id-1
end id
,student
from seat
order by id
3、1783. 大满贯数量


select player_id,player_name,
sum(player_id = Wimbledon)+sum(player_id = Fr_open)+
sum(player_id = US_open)+sum(player_id = Au_open) grand_slams_count
from players,championships
group by player_id
having grand_slams_count>0
7、不等式连接
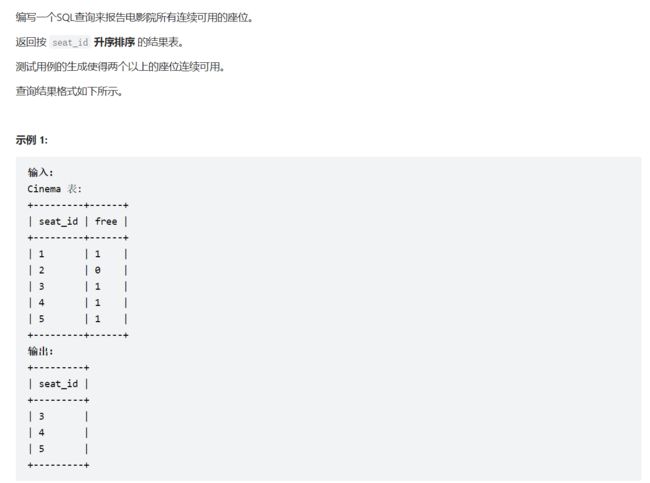
1、603. 连续空余座位
#先进行笛卡尔集连接,通过过滤差值来查找连续的座位并且还要空的集合。
select distinct a.seat_id
from cinema a,cinema b
where abs(b.seat_id-a.seat_id)=1
and a.free=1 and b.free=1
order by a.seat_id
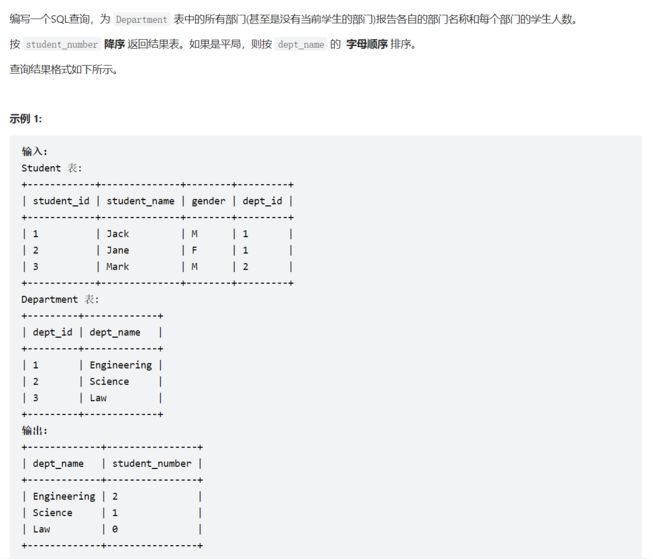
2、1731. 每位经理的下属员工数量
#这个只找到员工
# select employee_id,name,count(reports_to) reports_count,
# round(avg(age),0) average_age
# from employees
# where reports_to is not null
# group by reports_to
# order by employee_id
#直接连接,安照经理号来连接
select a.employee_id,a.name,count(b.reports_to) reports_count,
round(avg(b.age),0) average_age
from employees a,employees b
where a.employee_id=b.reports_to
group by a.employee_id
order by a.employee_id
15、mybatis-plus使用
1、多表查询
else 'Warm' end weather_type
where c.country_id = w.country_id
and day like “2019-11%”
group by c.country_name
### 2、[626. 换座位](https://leetcode.cn/problems/exchange-seats/)
[外链图片转存中...(img-yTEzYA7t-1668351948952)]
```sql
# Write your MySQL query statement below
#应该对id进行改变,而不是改变名字
select case
#这一句用来判断id为最后一个且总数为奇数的情况
when id%2=1 and id=(select count(*) from seat) then id
when id%2=1 then id+1
when id%2=0 then id-1
end id
,student
from seat
order by id
3、1783. 大满贯数量
select player_id,player_name,
sum(player_id = Wimbledon)+sum(player_id = Fr_open)+
sum(player_id = US_open)+sum(player_id = Au_open) grand_slams_count
from players,championships
group by player_id
having grand_slams_count>0
7、不等式连接
1、603. 连续空余座位
#先进行笛卡尔集连接,通过过滤差值来查找连续的座位并且还要空的集合。
select distinct a.seat_id
from cinema a,cinema b
where abs(b.seat_id-a.seat_id)=1
and a.free=1 and b.free=1
order by a.seat_id
2、1731. 每位经理的下属员工数量
#这个只找到员工
# select employee_id,name,count(reports_to) reports_count,
# round(avg(age),0) average_age
# from employees
# where reports_to is not null
# group by reports_to
# order by employee_id
#直接连接,安照经理号来连接
select a.employee_id,a.name,count(b.reports_to) reports_count,
round(avg(b.age),0) average_age
from employees a,employees b
where a.employee_id=b.reports_to
group by a.employee_id
order by a.employee_id
15、mybatis-plus使用
1、多表查询