Redis的5种基本数据类型
一、什么是Redis?
在介绍redis的五种数据类型之前,我们要知道什么是redis。redis是英文Remote Dictionary Server的缩写,也就是远程字典服务,它是一个开源的使用ANSI C语言编写的、支持网络、可基于内存亦可持久化的日志型、Key-Value型数据库、Redis 提供多种语言的API,比如我们常见的C、C++、C#、Java、Python语言都被Redis支持。
Redis会周期性的把更新的数据写入磁盘或者把修改的操作写入追加的记录文件,并在此基础上实现了mater-slave(主从)同步。
二、Redis五种基本数据类型
Redis五种数据类型包含string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(sort set有序结合)。如果将这五种数据类型与java中的模型进行类比,那么string类比String、hash类比Hashmap、list类比LinkList、set类比hashSet、 zset类TreeSet。对这Redis的这五种基本数据类型有了大致的理解之后,下面对每一种数据类型进行详细的介绍。
1、string(字符串)
1.1 数据存储
string存储单个数据,是最简单的数据存储类型,也是最常用的数据存储类型。string对应的一个存储空间保存一个数据。其存储内容通常使用字符串,如果字符串以证书的形式展示,则可以作为数字操作使用(但是仍是字符串)。
1.2 常用指令
添加、修改数据
set key value
获取数据
get key
删除数据
del key
获取数据字符个数(字符串长度)
strlen key
判断是否存在
exists key
追加信息到原始信息后部(如果原始信息存在就追加,否则新建)
append key value
演示:
127.0.0.1:6379> set name dingdada #插入一个key为‘name’值为‘dingdada’的数据
OK
127.0.0.1:6379> get name #获取key为‘name’的数据
"dingdada"
127.0.0.1:6379> get key1
"hello world!"
127.0.0.1:6379> keys * #查看当前库的所有数据
1) "name"
127.0.0.1:6379> EXISTS name #判断key为‘name’的数据存在不存在,存在返回1
(integer) 1
127.0.0.1:6379> EXISTS name1 #不存在返回0
(integer) 0
127.0.0.1:6379> APPEND name1 dingdada1 #追加到key为‘name’的数据后拼接值为‘dingdada1’,如果key存在类似于java中字符串‘+’,不存在则新增一个,类似于Redis中的set name1 dingdada1 ,并且返回该数据的总长度
(integer) 9
127.0.0.1:6379> get name1
"dingdada1"
127.0.0.1:6379> STRLEN name1 #查看key为‘name1’的字符串长度
(integer) 9
127.0.0.1:6379> APPEND name1 ,dingdada2 #追加,key存在的话,拼接‘+’,返回总长度
(integer) 19
127.0.0.1:6379> STRLEN name1
(integer) 19
127.0.0.1:6379> get name1
"dingdada1,dingdada2"
127.0.0.1:6379> set key1 "hello world!" #注意点:插入的数据中如果有空格的数据,请用“”双引号,否则会报错!
OK
127.0.0.1:6379> set key1 hello world! #报错,因为在Redis中空格就是分隔符,相当于该参数已结束
(error) ERR syntax error
127.0.0.1:6379> set key1 hello,world! #逗号是可以的
OK
自增
incr key
自减
decr key
演示:
127.0.0.1:6379> set num 0 #插入一个初始值为0的数据
OK
127.0.0.1:6379> get num
"0"
127.0.0.1:6379> incr num #指定key为‘num’的数据自增1,返回结果 相当于java中 i++
(integer) 1
127.0.0.1:6379> get num #一般用来做文章浏览量、点赞数、收藏数等功能
"1"
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> incr num
(integer) 3
127.0.0.1:6379> get num
"3"
127.0.0.1:6379> decr num #指定key为‘num’的数据自减1,返回结果 相当于java中 i--
(integer) 2
127.0.0.1:6379> decr num
(integer) 1
127.0.0.1:6379> decr num
(integer) 0
127.0.0.1:6379> decr num #可以一直减为负数~
(integer) -1
127.0.0.1:6379> decr num #一般用来做文章取消点赞、取消收藏等功能
(integer) -2
127.0.0.1:6379> decr num
(integer) -3
127.0.0.1:6379> INCRBY num 10 #后面跟上by 指定key为‘num’的数据自增‘参数(10)’,返回结果
(integer) 7
127.0.0.1:6379> INCRBY num 10
(integer) 17
127.0.0.1:6379> DECRBY num 3 #后面跟上by 指定key为‘num’的数据自减‘参数(3)’,返回结果
(integer) 14
127.0.0.1:6379> DECRBY num 3
(integer) 11
加/修改多个数据
mset key1 valueq key2 value2 …
获取多个数据
mget key1 key2 …
查询所有数据
keys *
演示:
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #插入多条数据
OK
127.0.0.1:6379> keys * #查询所有数据
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> mget k1 k2 k3 #查询key为‘k1’,‘k2’,‘k3’的数据
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> MSETNX k1 v1 k4 v4 #msetnx是一个原子性的操作,在一定程度上保证了事务!要么都成功,要么都失败!相当于if中的条件&&(与)
(integer) 0
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> MSETNX k5 v5 k4 v4 #全部成功
(integer) 1
127.0.0.1:6379> keys *
1) "k2"
2) "k4"
3) "k3"
4) "k5"
5) "k1"
截取字符串
getrange key index1 index2
替换字符串
setrange key index1 index2
演示:
#截取
127.0.0.1:6379> set key1 "hello world!"
OK
127.0.0.1:6379> get key1
"hello world!"
127.0.0.1:6379> GETRANGE key1 0 4 #截取字符串,相当于java中的subString,下标从0开始,不会改变原有数据
"hello"
127.0.0.1:6379> get key1
"hello world!"
127.0.0.1:6379> GETRANGE key1 0 -1 #0至-1相当于 get key1,效果一致,获取整条数据
"hello world!"
#替换
127.0.0.1:6379> set key2 "hello,,,world!"
OK
127.0.0.1:6379> get key2
"hello,,,world!"
127.0.0.1:6379> SETRANGE key2 5 888 #此语句跟java中replace有点类似,下标也是从0开始,但是有区别:java中是指定替换字符,Redis中是从指定位置开始替换,替换的数据根据你所需替换的长度一致,返回值是替换后的长度
(integer) 14
127.0.0.1:6379> get key2
"hello888world!"
127.0.0.1:6379> SETRANGE key2 5 67 #该处只替换了两位
(integer) 14
127.0.0.1:6379> get key2
"hello678world!"
设置过期时间
setex key time
不存在设置
setnx key value
演示:
#设置过期时间,跟Expire的区别是前者设置已存在的key的过期时间,而setex是在创建的时候设置过期时间
127.0.0.1:6379> setex name1 15 dingdada #新建一个key为‘name1’,值为‘dingdada’,过期时间为15秒的字符串数据
OK
127.0.0.1:6379> ttl name1 #查看key为‘name1’的key的过期时间
(integer) 6
127.0.0.1:6379> ttl name1
(integer) 5
127.0.0.1:6379> ttl name1
(integer) 3
127.0.0.1:6379> ttl name1
(integer) 1
127.0.0.1:6379> ttl name1
(integer) 0
127.0.0.1:6379> ttl name1 #返回为-2时证明该key已过期,即不存在
(integer) -2
#不存在设置
127.0.0.1:6379> setnx name2 dingdada2 #如果key为‘name2’不存在,新增数据,返回值1证明成功
(integer) 1
127.0.0.1:6379> get name2
"dingdada2"
127.0.0.1:6379> keys *
1) "name2"
127.0.0.1:6379> setnx name2 "dingdada3" #如果key为‘name2’的已存在,设置失败,返回值0,也就是说这个跟set的区别是:set会替换原有的值,而setnx不会,存在即不设置,确保了数据误操作~
(integer) 0
127.0.0.1:6379> get name2
"dingdada2"
1.3 应用场景
简单的举一个使用redis进行session共享的例子:
一个分布式web服务将用户的Session信息(比如:登录信息)记录到各自服务器中,这样会出现一个问题,在负载均衡(把众多的访问量分担到其他服务器上,让每个服务器的压力减少)的情况下,服务器会将用户的访问均衡到不同的服务器上,用户刷新一次访问可能就会发现需要重新登录,这个问题对于用户体验来说是无法容忍的。
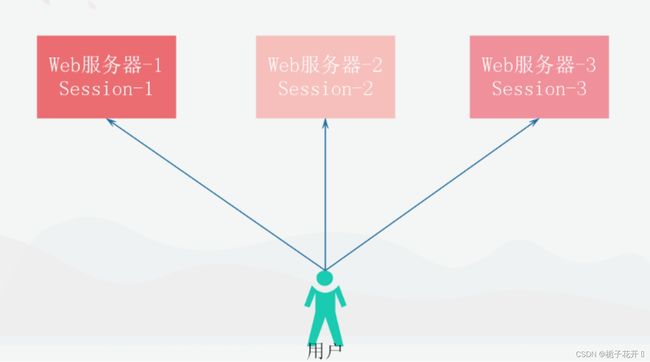
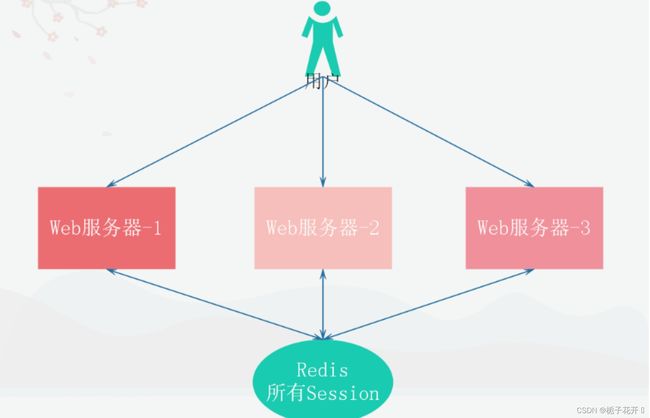
为了解决这个问题我们会是使用Redis将用户的Session进行集中管理,这样就只需要保证redis的高可用以及扩展性,每次用户的登录或者查询登录都从Redis中获取Session信息。
2、hash(哈希)
2.1 数据存储
hash对一系列存储的数据进行编组,方便管理,典型应用于存储对象信息。hash需要一个存储空间保存多个键值对数据。其底层使用哈希表结构实现数据存储。
2.2 常用指令
其常用指令与string常用指令并无太大区别,具体请看演示:
hset(添加hash)、hget(查询)、hgetall(查询所有)、hdel(删除hash中指定的值)、hlen(获取hash的长度)、hexists(判断key是否存在)操作。
127.0.0.1:6379> hset myhash name dingdada age 23 #添加hash,可多个
(integer) 2
127.0.0.1:6379> hget myhash name #获取hash中key是name的值
"dingdada"
127.0.0.1:6379> hget myhash age #获取hash中key是age的值
"23"
127.0.0.1:6379> hgetall myhash #获取hash中所有的值,包含key
1) "name"
2) "dingdada"
3) "age"
4) "23"
127.0.0.1:6379> hset myhash del test #添加
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "name"
2) "dingdada"
3) "age"
4) "23"
5) "del"
6) "test"
127.0.0.1:6379> hdel myhash del age #删除指定hash中的key(可多个),key删除后对应的value也会被删除
(integer) 2
127.0.0.1:6379> hgetall myhash
1) "name"
2) "dingdada"
127.0.0.1:6379> hlen myhash #获取指定hash的长度,相当于length、size
(integer) 1
127.0.0.1:6379> HEXISTS myhash name #判断key是否存在于指定的hash,存在返回1
(integer) 1
127.0.0.1:6379> HEXISTS myhash age #判断key是否存在于指定的hash,不存在返回0
(integer) 0
hkeys(获取所有key)、hvals(获取所有value)、hincrby(给值加增量)、hsetnx(存在不添加)操作。
127.0.0.1:6379> hset myhash age 23 high 173
(integer) 2
127.0.0.1:6379> hgetall myhash
1) "name"
2) "dingdada"
3) "age"
4) "23"
5) "high"
6) "173"
127.0.0.1:6379> hkeys myhash #获取指定hash中的所有key
1) "name"
2) "age"
3) "high"
127.0.0.1:6379> hvals myhash #获取指定hash中的所有value
1) "dingdada"
2) "23"
3) "173"
127.0.0.1:6379> hincrby myhash age 2 #让hash中age的value指定+2(自增)
(integer) 25
127.0.0.1:6379> hincrby myhash age -1 #让hash中age的value指定-1(自减)
(integer) 24
127.0.0.1:6379> hsetnx myhash nokey novalue #添加不存在就新增返回新增成功的数量(只能单个增加哦)
(integer) 1
127.0.0.1:6379> hsetnx myhash name miaotiao #添加存在则失败返回0
(integer) 0
127.0.0.1:6379> hgetall myhash
1) "name"
2) "dingdada"
3) "age"
4) "24"
5) "high"
6) "173"
7) "nokey"
8) "novalue"
2.3 应用场景
相比于string而言,hash更加适合存储对象。
举一个常用的应用场景 :购物车功能实现。
购物车功能主要是通过用户点击商品添加到购物车,前端会传递商品id以及用于需要购买的数据到后端,php 通过前端传递的参数进而完成购物车的添加,增加或者减少购物车购买数量,删除或者清空购物车等功能。
如果说是使用redis来做我们可以以用户 id 为 key,商品 id 为 field,商品数量为 value,恰好构成了购物车的3个要素。
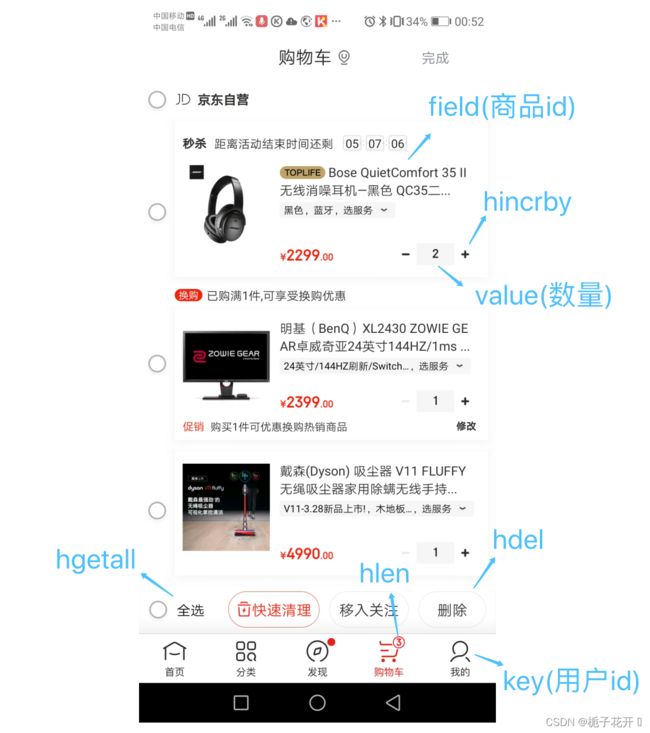
[命令] [购物车用户:ID] [产品:ID] [数量]
127.0.0.1:6379> hmset shopcartuser:1 product:1 2
OK
127.0.0.1:6379> hmget shopcartuser:1 product:1
1) "2"
127.0.0.1:6379>
3、List(列表)
3.1 数据存储
List可以存储多个数据,并对 数据进入存储空间进行顺序的区分, 一个存储空间可以保存多个数据,而且要通过数据可以体现进入顺序。List第十是通过双向链表的存储结构实现的。
3.2 常用指令
左插入、右插入、获取数据
lpush key value1 [value2] …
rpush key value1 [value2] …
lrange key start stop
演示:
#lpush
127.0.0.1:6379> lpush list v1 #新增一个集合
(integer) 1
127.0.0.1:6379> lpush list v2
(integer) 2
127.0.0.1:6379> lpush list v3
(integer) 3
#lrange
127.0.0.1:6379> LRANGE list 0 -1 #查询list的所有元素值
1) "v3"
2) "v2"
3) "v1"
127.0.0.1:6379> lpush list1 v1 v2 v3 v4 v5 #批量添加集合元素
(integer) 5
127.0.0.1:6379> LRANGE list1 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
5) "v1"
###这里大家有没有注意到,先进去的会到后面,也就是我们的lpush的意思是左插入,l--left
#rpush
127.0.0.1:6379> LRANGE list 0 1 #指定查询列表中的元素,从下标零开始,1结束,两个元素
1) "v3"
2) "v2"
127.0.0.1:6379> LRANGE list 0 0 #指定查询列表中的唯一元素
1) "v3"
127.0.0.1:6379> rpush list rv0 #右插入,跟lpush相反,这里添加进去元素是在尾部!
(integer) 4
127.0.0.1:6379> lrange list 0 -1 #查看集合所有元素
1) "v3"
2) "v2"
3) "v1"
4) "rv0"
##联想:这里我们是不是可以做一个,保存的记录值(如:账号密码的记录),
每次都使用lpush,老的数据永远在后面,我们每次获取 0 0 位置的元素,是不是相当于更新了
数据操作,但是数据记录还在?想要查询记录即可获取集合所有元素!
查询数据、获取数据长度
lindex key index
llen key
演示:
#lindex
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
2) "v3"
3) "v2"
127.0.0.1:6379> lindex list 1 #获取指定下标位置集合的元素,下标从0开始计数
"v3"
127.0.0.1:6379> lindex list 0 #相当于java中的indexof
"v4"
#llen
127.0.0.1:6379> llen list #获取指定集合的元素长度,相当于java中的length或者size
(integer) 3
删除数据(获取并删除左边第一个元素、获取并删除右边第一个元素)
lpop key
rpop key
演示:
#lpop
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
5) "v1"
127.0.0.1:6379> lpop list #从头部开始移除第一个元素
"v5"
##################
#rpop
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
2) "v3"
3) "v2"
4) "v1"
127.0.0.1:6379> rpop list
"v1"
127.0.0.1:6379> LRANGE list 0 -1 #从尾部开始移除第一个元素
1) "v4"
2) "v3"
3) "v2"
lrem(根据value移除指定的值)
lrem key count value
演示:
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
2) "v3"
3) "v2"
127.0.0.1:6379> lrem list 1 v2 #移除集合list中的元素是v2的元素1个
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
2) "v3"
127.0.0.1:6379> lrem list 0 v3 #移除集合list中的元素是v2的元素1个,这里的0和1效果是一致的
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
127.0.0.1:6379> lpush list v3 v2 v2 v2
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "v2"
2) "v2"
3) "v2"
4) "v3"
5) "v4"
127.0.0.1:6379> lrem list 3 v2 #移除集合list中元素为v2 的‘3’个,这里的参数数量,如果实际中集合元素数量不达标,不会报错,全部移除后返回成功移除后的数量值
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "v3"
2) "v4"
ltrim(截取元素)、rpoplpush(移除指定集合中最后一个元素到一个新的集合中)操作
ltrim list start stop
rpoplpush key1 key2
演示:
#ltrim
127.0.0.1:6379> lpush list v1 v2 v3 v4
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "v4"
2) "v3"
3) "v2"
4) "v1"
127.0.0.1:6379> ltrim list 1 2 #通过下标截取指定的长度,这个list已经被改变了,只剩下我们所指定截取后的元素
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "v3"
2) "v2"
################
#rpoplpush
127.0.0.1:6379> lpush list v1 v2 v3 v4 v5
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
5) "v1"
127.0.0.1:6379> rpoplpush list newlist #移除list集合中的最后一个元素到新的集合newlist中,返回值是移除的最后一个元素值
"v1"
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
127.0.0.1:6379> LRANGE newlist 0 -1 #确实存在该newlist集合并且有刚刚移除的元素,证明成功
1) "v1"
lset(更新)、linsert操作
lset key index value
linsert key before|after value1 value2
演示:
#lset
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
127.0.0.1:6379>
127.0.0.1:6379> lset list 1 newV5 #更新list集合中下标为‘1’的元素为‘newV5’
OK
127.0.0.1:6379> LRANGE list 0 -1 #查看证明更新成功
1) "v5"
2) "newV5"
3) "v3"
4) "v2"
##注意点:
127.0.0.1:6379> lset list1 0 vvvv #如果指定的‘集合’不存在,报错
(error) ERR no such key
127.0.0.1:6379> lset list 8 vvv #如果集合存在,但是指定的‘下标’不存在,报错
(error) ERR index out of range
########################
#linsert
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "newV5"
3) "v3"
4) "v2"
127.0.0.1:6379> LINSERT list after v3 insertv3 #在集合中的‘v3’元素 ‘(after)之后’ 加上一个元素
(integer) 5
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "newV5"
3) "v3"
4) "insertv3"
5) "v2"
127.0.0.1:6379> LINSERT list before v3 insertv3 #在集合中的‘v3’元素 ‘(before)之前’ 加上一个元素
(integer) 6
127.0.0.1:6379> LRANGE list 0 -1
1) "v5"
2) "newV5"
3) "insertv3"
4) "v3"
5) "insertv3"
6) "v2"
3.3 业务场景
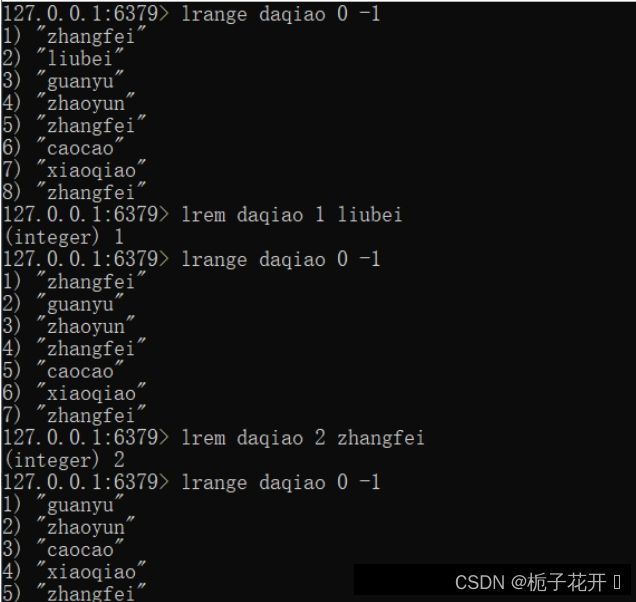
举一个比较常见的业务场景:微信朋友圈点赞,要求按照顺序显示点赞好友信息。如果取消点赞,移除对应好友信息。
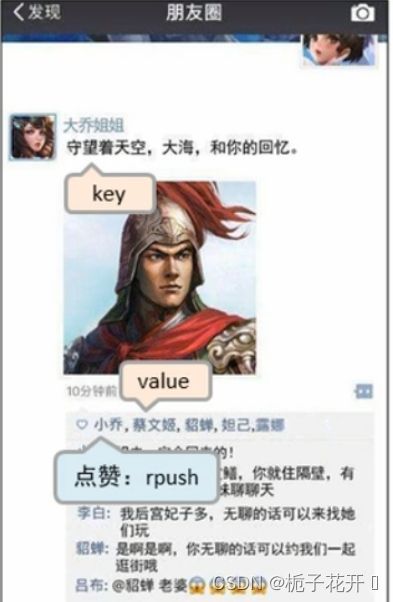
在此场景下便可以将朋友圈的内容设置为key,将点赞的用户信息设置为value。点赞时可以使用rpush添加用户信息,取消赞之后可以使用lrem对用户信息进行移除。
4.set(集合)
4.1 数据存储
Set可以存储大量的元素,同时其在查询方面提供更高的效率。因为拥有高效的内部存储机制,所以更便于查询。Set与Hash存储结构完全相同,仅存储键,不存储值,并且值是不允许重复的,简单来讲就是只有键没有值的hash。
4.2 常用指令
sadd(添加)、smembers(查看所有元素)、sismember(判断是否存在)、scard(查看长度)、srem(移除指定元素)操作
演示:
#set中所有的元素都是唯一的不重复的!
127.0.0.1:6379> sadd set1 ding da mian tiao #添加set集合(可批量可单个,写法一致,不再赘述)
(integer) 4
127.0.0.1:6379> SMEMBERS set1 #查看set中所有元素
1) "mian"
2) "da"
3) "tiao"
4) "ding"
127.0.0.1:6379> SISMEMBER set1 da #判断某个值在不在set中,在返回1
(integer) 1
127.0.0.1:6379> SISMEMBER set1 da1 #不在返回0
(integer) 0
127.0.0.1:6379> SCARD set1 #查看集合的长度,相当于size、length
(integer) 4
127.0.0.1:6379> srem set1 da #移除set中指定的元素
(integer) 1
127.0.0.1:6379> SMEMBERS set1 #移除成功
1) "mian"
2) "tiao"
3) "ding"
srandmember(抽随机)操作
演示:
127.0.0.1:6379> sadd myset 1 2 3 4 5 6 7 #在set中添加7个元素
(integer) 7
127.0.0.1:6379> SMEMBERS myset
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
127.0.0.1:6379> SRANDMEMBER myset 1 #随机抽取myset中1个元素返回
1) "4"
127.0.0.1:6379> SRANDMEMBER myset 1 #随机抽取myset中1个元素返回
1) "1"
127.0.0.1:6379> SRANDMEMBER myset 1 #随机抽取myset中1个元素返回
1) "5"
127.0.0.1:6379> SRANDMEMBER myset #不填后参数,默认抽1个值,但是下面返回不会带序号值
"3"
127.0.0.1:6379> SRANDMEMBER myset 3 #随机抽取myset中3个元素返回
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> SRANDMEMBER myset 3 #随机抽取myset中3个元素返回
1) "6"
2) "3"
3) "5"
spop(随机删除元素)、smove(移动指定元素到新的集合中)操作
演示:
127.0.0.1:6379> SMEMBERS myset
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
127.0.0.1:6379> spop myset #随机删除1个元素,不指定参数值即删除1个
"2"
127.0.0.1:6379> spop myset 1 #随机删除1个元素
1) "7"
127.0.0.1:6379> spop myset 2 #随机删除2个元素
1) "3"
2) "5"
127.0.0.1:6379> SMEMBERS myset #查询删除后的结果
1) "1"
2) "4"
3) "6"
127.0.0.1:6379> smove myset myset2 1 #移动指定set中的指定元素到新的set中
(integer) 1
127.0.0.1:6379> SMEMBERS myset #查询原来的set集合
1) "4"
2) "6"
127.0.0.1:6379> SMEMBERS myset2 #查询新的set集合,如果新的set存在,即往后加,如果不存在,则自动创建set并且加入进去
1) "1"
sdiff(差集)、sinter(交集)、sunion(并集)操作
演示:
127.0.0.1:6379> sadd myset1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd myset2 3 4 5 6 7
(integer) 5
127.0.0.1:6379> SMEMBERS myset1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> SMEMBERS myset2
1) "3"
2) "4"
3) "5"
4) "6"
5) "7"
127.0.0.1:6379> SDIFF myset1 myset2 #查询指定的set之间的差集,可以是多个set
1) "1"
2) "2"
127.0.0.1:6379> SINTER myset1 myset2 #查询指定的set之间的交集,可以是多个set
1) "3"
2) "4"
3) "5"
127.0.0.1:6379> sunion myset1 myset2 #查询指定的set之间的并集,可以是多个set
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
4.3 业务场景
set最常见的使用场景是获取共同好友。不如说微信朋友圈的点赞、评论,只能看到自己好友的信息。这就涉及到共同好友的概念,通过redis中的set集合可以很轻松的实现该功能。
实现思路就是首先将每个人的好友放在set集合中。key的名字为friend_{userId}。如下图:
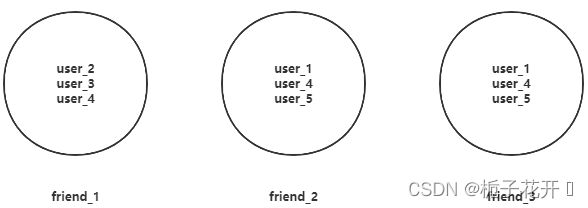
用户1的好友为2,3,4
用户2的好友为1,3,4
用户3的好友为1,4,5
交集
用户1和2是好友。他们的共同好友可以通过他们的交集获取。

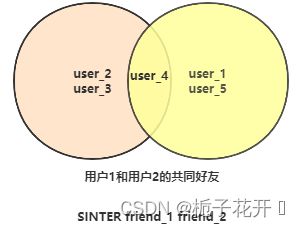
redis命令示例:
127.0.0.1:6379> sadd friend_1 2 3 4
(integer) 3
127.0.0.1:6379> sadd friend_2 1 4 5
(integer) 3
127.0.0.1:6379> SINTER friend_1 friend_2
1) “4”
5、zset(有序集合)
5.1 数据存储
Zset根据排序有利于数据的有效显示,需要提供一种可以根据自身特征进行排序的方式。zSet是在set的存储结构基础上添加可排序字段。
5.2 常用指令
zadd(添加)、zrange(查询)、zrangebyscore(排序小-大)、zrevrange(排序大-小)、zrangebyscore withscores(查询所有值包含key)操作。
演示:
127.0.0.1:6379> zadd myzset 1 one 2 two 3 three #添加zset值,可多个
(integer) 3
127.0.0.1:6379> ZRANGE myzset 0 -1 #查询所有的值
1) "one"
2) "two"
3) "three"
#-inf 负无穷 +inf 正无穷
127.0.0.1:6379> ZRANGEBYSCORE myzset -inf +inf #将zset的值根据key来从小到大排序并输出
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> ZRANGEBYSCORE myzset 0 1 #只查询key<=1的值并且排序从小到大
1) "one"
127.0.0.1:6379> ZREVRANGE myzset 1 -1 #从大到小排序输出
1) "two"
2) "one"
127.0.0.1:6379> ZRANGEBYSCORE myzset -inf +inf withscores #查询指定zset的所有值,包含序号的值
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
zrem(移除元素)、zcard(查看元素个数)、zcount(查询指定区间内的元素个数)操作。
演示:
127.0.0.1:6379> zadd myset 1 v1 2 v2 3 v3 4 v4
(integer) 4
127.0.0.1:6379> ZRANGE myset 0 -1
1) "v1"
2) "v2"
3) "v3"
4) "v4"
127.0.0.1:6379> zrem myset v3 #移除指定的元素,可多个
(integer) 1
127.0.0.1:6379> ZRANGE myset 0 -1
1) "v1"
2) "v2"
3) "v4"
127.0.0.1:6379> zcard myset #查看zset的元素个数,相当于长度,size。
(integer) 3
127.0.0.1:6379> zcount myset 0 100 #查询指定区间内的元素个数
(integer) 3
127.0.0.1:6379> zcount myset 0 2 #查询指定区间内的元素个数
(integer) 2
5.3 业务场景
Zset由于本身的特性,常用来进行成绩表排序,工资表排序,年龄排序等等。在这里举一个百度热榜的例子。

例如上图的百度热榜,众所周知新闻的热度是根访问量来确定的,那么它就代表zset的score选项。而左边的文字就是zset的member成员,我们会先使用id来代表这个member,例如10001代表 “#李铁涉嫌严重违法接受监察调查#”,10002代表 “乌鲁木齐市火灾四问” 。这样就能使用zset做到热搜榜的排行。
虽然上面的member是id,但是上图看到的这些主题文字如何保存、以及点击后该怎么显示这些内容呢,很明显,需要一个额外的hash结构来存储这些内容。其中hash的key为:id。例如hash:id,具体点可以是hot:20220226:10001。
然后这个id的热搜的hash结构可以存储本身的id、text主题、点击后展示该热搜的url等等hash字段。
# hot:20221126:hot代表热搜这个功能。20221126代表22年11月26号这一天的热搜。
# 1. 假设有10个热搜榜,首次阅读量都为1。用户通过点击新闻次数来改变score,从而改变热搜榜的顺序。
192.168.1.9:6379> zincrby hot:20221126 1 10001
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10002
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10003
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10004
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10005
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10006
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10007
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10008
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10009
"1"
192.168.1.9:6379> zincrby hot:20221126 1 10010
"1"
192.168.1.9:6379>
# 2. 然后通过用户的点击新闻行为,来改变score,从而改变热搜榜。
# 假设我们想让10001增加30点击数,10005增加20点击数,10010增加10点击数。其它不变。
192.168.1.9:6379> zincrby hot:20221126 10 10010
"11"
192.168.1.9:6379> zincrby hot:20221126 20 10005
"21"
192.168.1.9:6379> zincrby hot:20221126 30 10001
"30"
192.168.1.9:6379>
# 3. 获取前10个排行榜。
# 因为zrang默认返回的是从小到大的,即点击数从小到大,所以我们热搜榜需要返回点击数从大到小的,这样才是热搜榜。
# 下面看到,10001点击数最多所以排行第一,其次是10005,到10010,其余可以不理,因为我给的都是默认值。他们会按照score相同时,member的字母来排序,然后根据zrevrange倒转返回,最终显示下面的结果。
192.168.1.9:6379> zrevrange hot:20221126 0 9 withscores
1) "10001"
2) "31"
3) "10005"
4) "21"
5) "10010"
6) "11"
7) "10009"
8) "1"
9) "10008"
10) "1"
11) "10007"
12) "1"
13) "10006"
14) "1"
15) "10004"
16) "1"
17) "10003"
18) "1"
19) "10002"
20) "1"
192.168.1.9:6379>
# 实际上也可以使用ZRANG命令,但是需要加上REV选项。结果与zrevrange是一样的。
192.168.1.9:6379> zrange hot:20221126 0 9 withscores rev
1) "10001"
2) "31"
3) "10005"
4) "21"
5) "10010"
6) "11"
7) "10009"
8) "1"
9) "10008"
10) "1"
11) "10007"
12) "1"
13) "10006"
14) "1"
15) "10004"
16) "1"
17) "10003"
18) "1"
19) "10002"
20) "1"
192.168.1.9:6379>