初始MySQL,以及MySQL的基本语句
下面分享一个新手入门需要知道的简单语句,
虽然使用了图形化软件来操作MySQL,但是对一些简单的SQL语句还是需要有所了解
文章目录
- 1.数据库操作
- 2.表操作
- 3.数据操作
- 4.查询语句
- 5.MySQL函数
-
- 5.1常用类(不常用)
- 5.2.聚合函数(常用)
- 6.事务
- 7.索引
-
- 7.1.索引的分类
- 7.2.索引原则
1.数据库操作
既然是使用数据库,那么首先要做的当然是创建数据库:
CREATE DATABASE [IF NOT EXISTS] 数据库名

后面的一段语句是对整个数据库字符集编码的设置,如果是按照默认的设置,则无法显示中文。
创建完数据库,要先使用数据库才能进行操作,所以:
USE 数据库名
有了数据库之后,就需要创建一个个的表来装数据,通常格式如下:
CREATE TABLE [IF NOT EXISTS] `表名`(
`字段名` 列类型 [属性] [索引] [注释],
`字段名` 列类型 [属性] [索引] [注释],
`字段名` 列类型 [属性] [索引] [注释],
...
`字段名` 列类型 [属性] [索引] [注释]
)[表类型][字符集设置][注释]
以上操作每一个字段设置之后需要用英文输入法的逗号分开,最后一句可以写,可以不写。
小白看到这里就要疑惑了,字段名是什么,列类型是什么,属性又是什么…
字段名见名知意,是列表中字段的名字。
类型就相当于C语言或者Java里面,创建一个变量 你需要定义一个变量类型
而MySQL的列类型,和其他语言的类似。
属性通常是按照需求所设置。
主键一个表只能设置一个。
注释就不多讲了。

属性通常有这一些,也是见名知意的
| 属性名 | 解释 |
|---|---|
| tinyint | 非常小的数据 |
| smallint | 比较小的数据 |
| mediumint | 中等大小的数据 |
| int | 普通的整型 |
| bigint | 较大的数据 |
| float | 浮点数 |
| double | 浮点数 |
| decimal | 字符串形式的浮点数(通常要求精度很准的时候用) |
| char | 字符串 |
| varchar | 可变字符串 |
| datetime | yyyy-MM-dd HH:mm:ss (最常用的时间格式) |
2.表操作
了解完这些之后,就可以尝试对表进行一些操作了
给表进行重命名操作:
ALTER TABLE <旧表名> RENAME AS <新表名>
增加表中字段:
ALTER TABLE <表名> ADD <字段名> <列属性>
修改约束以及字段的重命名:
ALTER TABLE <表名> MODIFY <字段名> <列属性> --修改约束
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <列属性> --字段重命名
删除字段:
ALTER TABLE <表名> DROP <字段名>
删除表:
DROP TABLE [IF EXISTS] <表名>
3.数据操作
完成对表的操作之后,就可以往表中添加数据了!
INSERT INTO 表名(字段1,[字段2],[字段3]...) values'值1',['值2'],['值3'],[...]
字段与值一一对应!比如插入一条数据
INSERT INTO student (`name`,`age`,`sex`) values('绝','20','男')
修改数据:
UPDATE <表名> SET <属性>... WHERE <条件>
如果不指定条件,则修改全部
删除数据有两种方法,一种是DELETE,另一种是TRUNCATE
两种的区别在于是否会重置自增列!
看使用情况选择。
delete from 表名 [where 条件]
TRUNCATE 表名
4.查询语句
整个数据库中,用的较为多的却是查询语句,所以是重点。
这是官网文档中查询语句的用法:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr, ...
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name']
[FROM table_references
[WHERE where_definition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_definition]
[ORDER BY {col_name | expr | position}
[ASC | DESC] , ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[FOR UPDATE | LOCK IN SHARE MODE]]
所有的查询语句,都是SELECT,所以是非常重要的!对后续的学习也是影响较大的。许多工作之后的人对SELECT的使用都做不到万无一失。
这是最基础的一段查询语句。
SELECT 字段名 FROM 表名
通常不止查询一个数据信息,并且加上约束得到数据的条件语句,就变成这样
SELECT 字段名1 [字段名2] ...
FROM 表名
WHERE 条件
如果查询的数据不止存在在一张表里,我们还需要对表进行联结:
联表有7种方式,根据情况选择。
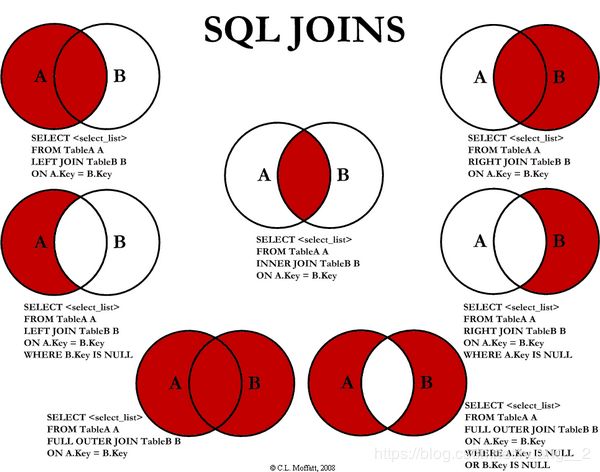
SELECT 字段名1 [字段名2] ...
FROM 表1
(INNER)/(RIGHT)/(LEFT) JOIN 表2
ON 条件
接下来就是对查询信息进行排序和分页
ORDER BY 字段名 [升序ASC]/[降序DESC]
LIMIT 起始值,页面的大小
最后是GROUP BY和HAVING的联合使用
GROUP BY 字段名
HAVING 条件
5.MySQL函数
5.1常用类(不常用)
-- ================== 常用函数 ======================
-- 数学运算
SELECT ABS(-8) -- 绝对值
SELECT CEILING(5.2) -- 向上取整
SELECT FLOOR(5.9) -- 向下取整
SELECT RAND()*10 -- 0-1随机数
SELECT SIGN(-12) -- 判断数的符号,0返回0,正数返回1,负数返回-1
-- 字符串函数
SELECT CHAR_LENGTH('呼吸不停,学习不止') -- 返回字符串长度
SELECT CONCAT('我','爱','你') -- 拼接字符串
SELECT INSERT('我爱Java',3,4,'你') -- 插入并替换掉字符串
SELECT INSERT('我爱Java',3,0,'你') -- 插入字符串
SELECT UPPER('My name is ...') -- 小写字母转大写
SELECT LOWER('HELLO WORLD') -- 大写字母转小写
SELECT INSTR('My name is CodeMan','Code') -- 查询字串所在的index
SELECT REPLACE('My name is CodeMan','Code','Happy') -- 替换字符串
SELECT SUBSTR('My name is CodeMan',12,7) -- 截取字串,从第index位置,截取lenth位
SELECT REVERSE('abc') -- 翻转字符串
-- 查询姓段的同学 转为 嘟
SELECT INSERT(studentname,1,1,'嘟')
FROM student
WHERE studentname LIKE '段%'
-- 时间和日期函数(记住)
SELECT CURRENT_DATE() -- 获取当前日期
SELECT CURDATE() -- 获取当前日期
SELECT NOW() -- 获取当前时间
SELECT LOCALTIME() -- 获取本地时间
SELECT SYSDATE() -- 获取系统时间
SELECT YEAR(NOW()) -- 年
SELECT MONTH(NOW()) -- 月
SELECT DAY(NOW()) -- 日
SELECT HOUR(SYSDATE()) -- 时
SELECT MINUTE(LOCALTIME()) -- 分
SELECT SECOND(NOW()) -- 秒
SELECT SYSTEM_USER() -- 系统用户
SELECT USER() -- 系统用户
SELECT VERSION() -- MySQL版本
有编程基础的,基本上过一遍就能记住。
5.2.聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| … | … |
6.事务
事务:将一组SQL放在一个批次中去执行!
ACID原则:原子性,一致性,隔离性,持久性 (脏读,幻读…)
-- ==================== 事务的基本流程 =======================
-- MySQL是默认开启事务自动提交的
-- 手动处理事务
SET autocommit = 0 -- 关闭自动提交
-- 事务开启
START TRANSACTION -- 标记一个事务的开始,从这个之后的SQL都在同一个事务内
INSERT XX
INSERT XX
-- 提交:持久化(成功)
COMMIT
-- 回滚:回到原来的样子(失败!)
ROLLBACK
-- 事务结束
SET autocommit = 1 -- 开启自动提交
-- 了解即可 ↓
SAVEPOINT -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT -- 回滚到保存点
RELEASE SAVEPOINT -- 撤销保存点
场景模拟:银行转账
-- 转账
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci
USE shop
CREATE TABLE `account` (
`id` INT(3) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(30) NOT NULL,
`money` DECIMAL(9,2) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
-- 模拟转账:事务
SET autocommit = 0 -- 关闭自动提交
START TRANSACTION -- 开启一个事务(一组事务)
UPDATE account SET money=money-520 WHERE `name` = '小段' -- 小段给小张转账520
UPDATE account SET money=money+520 WHERE `name` = '小张' -- 小张收到小段转账的520
COMMIT -- 提交事务,就被持久化了
ROLLBACK -- 回滚
SET autocommit = 1 -- 恢复默认值
7.索引
官方对索引的定义为:索引(index)是帮助Mysql高效获取数据的数据结构。
可以得到索引的本质:索引就是数据结构
7.1.索引的分类
- 主键索引(PRIMARY KEY):
- 唯一的标识:主键不可重复
- 唯一索引 (UNIQUE KEY):
- 避免重复的列出现,唯一索引可以重复,多个列都可以标识唯一索引
- 常规索引(KEY/INDEX):
- 默认的,可以INDEX或者KEY来设置
- 全文索引(FULLTEXT):
- 在特定的数据库引擎下才有,现在都有了,作用:快速定位数据
索引在小数据量的时候,作用不大,但是在大数据的时候,区别十分明显!
7.2.索引原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上