mysql innodb如何解决幻读_innodb如何解决幻读
准备
众所周知,数据库事务有以下四种隔离级别,其中mysql默认隔离级别是RR,但是mysql的innodb引擎一定程度可以避免幻读。
事务隔离级别
脏读
不可重复读
幻读
读未提交(read-uncommitted)
是
是
是
不可重复读(read-committed)
否
是
是
可重复读(repeatable-read)
否
否
是
串行化(serializable)
否
否
否
当前读
读取的是最新版本。UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE是当前读。
快照读
读取的是快照版本,也就是历史版本。普通的SELECT就是快照读
数据准备
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test` VALUES (11, 11);
INSERT INTO `test` VALUES (33, 33);
INSERT INTO `test` VALUES (55, 55);
INSERT INTO `test` VALUES (58, 55);
INSERT INTO `test` VALUES (60, 55);
INSERT INTO `test` VALUES (77, 77);
INSERT INTO `test` VALUES (99, 99);
MVCC
MVCC的实现依赖于undo-log,每行的隐藏字段,以及readview。
undo-log
undo log 与 redo log 一起构成了 MySQL 事务日志,并且我们上篇文章中提到的日志先行原则 WAL 除了包含 redo log 外,也包括 undo log,事务中的每一次修改,innodb 都会先记录对应的 undo log 记录。与 redo log 用于数据的灾后重新提交不同,undo log 主要用于数据修改的回滚
三个隐藏字段
DB_TRX_ID -- 记录插入或更新该行的最后一个事务的事务 ID
DB_ROLL_PTR -- 指向改行对应的 undolog 的指针
DB_ROW_ID -- 单调递增的行 ID,他就是 AUTO_INCREMENT 的主键 ID
readview
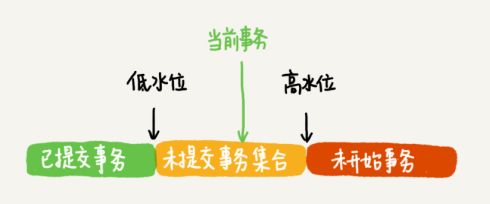
readview可以理解为一种数据结构,主要用来判断数据可见性,有以下几个重要属性
low_trx_id记录了当前事务开启时全局事务 ID + 1,也就是高水位线
up_trx_id表示当前事务开启时所有未提交事务 ID 的最小值,也就是低水位线
trx_ids表示所有事务链表中事务的id集合。
可见性规则
读某一行数据的时候,如果发现他的事务id < up_limit_id (活跃id列表最小值),可见。
如果发现数据的事务id>=low_limit_id(ReadView时系统中最大的事务id),不可见。
如果发现数据的事务id在列表范围内
如果是id集合中的,不可见
如果不在id集合中,可见
readview保存了不应该让这个事务看到的其他的事务 ID 列表
实验
事务A
事务B
1
begin;
select * from test where id>44;

2
begin;
insert into test values (66,66);
commit;
3
select * from test where id>44;

select * from test where id>44 for update;
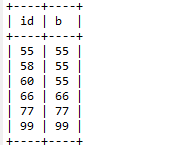
都是快照读的情况下,由于MVCC的作用,不会存在幻读情况,如果事务B执行之后使用当前读,MVCC失去作用,就会发生幻读。
实验结果分析
解释完MVCC,我们来分析一下上面的实验结果,假设事务A在1处开启的事务id为10,此时trx_ids(活跃事务id列表)只有[]10],,low_trx_id为当前事务id+1,即11,up_trx_id为活跃事务id中最小的事务id,也是10。此时事务B开始事务id为11,提交id为66的数据,该数据隐藏列DB_TRX_ID即为11,此时回到事务A,id=66的数据事务id>=low_limit_id,所以该行数据不可见,于是通过该行的隐藏字段DB_ROLL_PTR 读取undo-log日志进行回溯。
next-key lock
InnoDB有三种行锁的算法:
1,Record Lock:单个行记录上的锁。
2,Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
3,Next-Key Lock:1+2,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
加锁规则
两个原则,两个优化,一个bug
原则1:加锁的基本单位是next-key lock。希望你还记得,next-key lock是前开后闭区间。
原则2:查找过程中访问到的对象才会加锁。
优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。
优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。
一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
实验1
事务A
事务B
begin;
select * from test where b=55 for update;
begin;
insert into test values(44,44);#阻塞
insert into test values(66,66);#阻塞
insert into test values(78,55);#阻塞
insert into test values(76,77);#阻塞
insert into test values(78,77);
delete from test where b=77;
delete from test where b=33;
根据原则1,会在((33,33),(55,55)]上加锁,b是普通索引,会一直向后查询,一直到b=77,根据原则2,在((55,55),(77,77)]上加锁,根据优化2,最后一个值不满足b=55,所以退化成间隙锁(Gap锁),
索引锁的范围是((33,33),(77,77))
实验2
事务A
事务B
begin;
explain select * from test where b>=33 and b<55 for update;(用explain分析下防止数据过少优化为锁全表影响实验结论)

select * from test where b>=33 and b<55 for update;
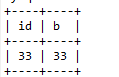
begin;
insert into test values (51,55);#阻塞
insert into test values (32,33);#阻塞
insert into test values (12,11);#阻塞
insert into test values (56,55);
insert into test values (10,11);
delete from test where b=11;
delete from test where id=55;#阻塞
delete from test where id=58;
根据加锁规则,会在((11,11),(33,33)],((33,33),(55,55)] 上加锁,因为不是唯一索引,不会优化,所以锁住的范围是((11,11),(55,55])
结论
innodb通过mvcc解决快照读的幻读,通过next key lock解决当前读的幻读。
参考: