大数据架构
目前大数据主要的结构如下:
从最下面一层往上依次为:

一、接入层
1、DataX
a) dataX是一个ETL工具,阿里出品
b) 采用Framework + plugin架构构建,幸运的是自带了常用的插件,比如MysqlReader、HdfsWriter等
c) Standalone,无中心,每个实例之间无关联
d) 性能强劲、相对于sqoop,配置更简单
e) 稳定高效,我们引入DataX以来,从来没有在数据传输上出过问题

2、DTS/Canal
a) Canal是基于Mysql binlog变动,实时同步数据变化的工具
b) DTS是阿里云提供的一套数据产品,原理和Canal类似,我们想监听某个表的变动,只需订阅,就可以获取到数据的实时变化
c) 迁云之后,主要使用DTS
d) 数据落地我们使用kafka,topic一般是schema.table_name
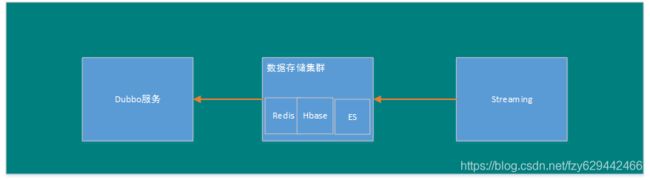
e) 消费方一般是streaming、airflow调度的spark作业等,计算后的数据二次落地在redis、hbase、es等数据集群中
3、Logstash
a) 因为配置相对于flume简单,并且和elasticsearch、kibana紧密结合,我们的应用日志大部分使用logstash进行收集
b) logstash将日志落地到kafka,我们的计算引擎进行计算

4、Flume
a) flume主要是采集了移动端的track log,用于计算骑手的轨迹
b) app和flume之间我们搭建了一个nodejs写的web应用,示意如下:

二、存储层
存储层包含hdfs、kafka、hbase、redis和elasticsearch等,其中redis、hbase、es作为数据二次落地(最终计算结果)的存储介质。
1、redis
首先如果数据结构符合kv结构,首选redis,因为redis非常快,毫秒级别,哪怕mget一万个key。
2、hbase
其次对于需要多个查询条件进行检索的数据,我们一般放到hbase中,应用通过phoenix引擎读取hbase,hbase如果rowkey设计合理,几十毫秒的rt是可以满足的,但是如果设计不合理,那是非常缓慢的,设计rowkey时,可以把能够过滤最多记录的key放在rowkey最前面,依次类推。
3、elasticsearch
对于写少读多的数据,而且检索条件非常丰富,我们放到elasticsearch中,比如历史订单查询。
三、计算层
1、Hive(MR)
a) hive主要用于离线数据分析
b) hql能实现大部分场景的数据统计,复杂处理逻辑使用hive udf,hql中调用udf函数就可以了
c) 分区方案采用按日分区的,部分表使用日期+小时+分钟的分区方案
2、Spark
a) spark我们主要使用spark sql和spark streaming(当然包含spark core),前者主要处理批处理和交互式查询,后者用于实时计算,spark mllib暂时没用到
b) 大部分实时处理使用spark streaming,吞吐量高,并不需要纯实时和高可靠地事务机制,
c) 为了便于管理,和hive mr一样,统一使用yarn调度,后续可能考虑部分小内存的spark job使用standalone调度
3、Storm
a) storm用得不多
b) 主要是云上的dts任务和云下仪表盘的influxdb writer
四、调度层
1、Yarn
Yarn(MR2)上面跑了两种作业:hive和spark作业
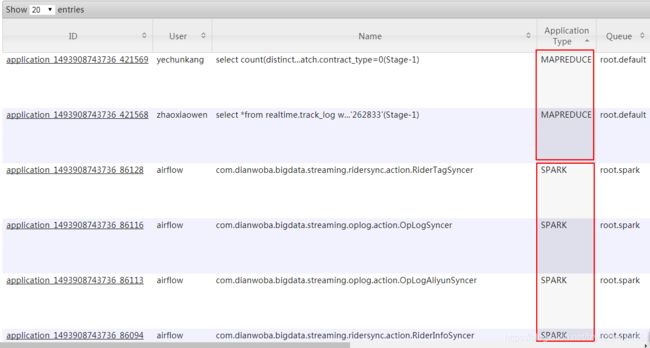
a) hive(mr) job
hive作业一般是airflow调度的每日例行作业,或者是数据分析人员(技术、bi、运力、运营等部门)通过hive cli、hue等工具提交的离线作业,运行在root.default队列上。可以自定义Map/Reduce Container的资源大小,如在hive中分别指定:
set mapreduce.map.memory.mb=4096; set mapreduce.reduce.memory.mb=4096;
b) spark on yarn
在yarn上运行的spark作业分为streaming作业和spark批处理作业,分别运行在root.spark和root.airflow队列上。可指定driver、executor占用资源:
$SPARK_HOME/bin/spark-submit --master yarn --deploy-mode cluster --queue spark --executor-cores 1 --executor-memory 2g --num-executors 1 --driver-memory 1g --driver-cores 1
2、Airflow
a) 我们的daily任务、5/15/30min任务都靠airflow调度
b) 一个支持dag(有向无环图)的任务调度工具
c) 一个任务失败了,它的所有downstream任务都是失败的,都不会运行,保证了数据的正确性
d) python编写,配置比oozie简单

五、OLAP层
1、hive数据仓库
hive数据仓库是任何大数据平台中基础的基础,任何业务数据都按照某种分区规则存放在此,是各种计算引擎的数据基础。我们在设计hive仓库时,根据hive表的作用范围划分为几个命名空间,分别是:
alt a) ODS
ODS(Operational Data Store)代表记录层面,在我们这里代表etl拉过来的基础数据,通俗地说,就是datax拉的数据表
b) DW
DW是根据业务分析需求,在ods的基础上进行最基础的聚合,是所有统计分析数据的基础
c) DWS/Report
DWS/Report是DW的基础上进行聚合,面向某一统计主题的、对调用者而言无需再进行join的

2、Presto
Presto集群可以拉取hive表,到内存中计算,比hive快很多,支持Ad-hoc,没有引入Presto之前,cube的数据源是hive计算后通过datax将结果导入到mysql。
但是随着业务的发展,一个报表需求的查询维度是任意维度的,也就是通常所说的ad-hoc,这样一来,我们要为每一个查询维度生成一张hive表,然后hive表导入到mysql,这样既给数仓层的设计造成了不便,同时mysql也保存了所有维度的大量数据,mysql表只保存最终统计结果的目标也就失去了意义,引入presto后,解决了我们这些棘手的问题。
3、Cube
Cube是一个数据呈现平台,主要用于公司业务人员和分析部门的数据需求,所有数据从Presto中读取,目前分为PC端和移动端,经过产品上线以来的运营情况,移动端的数据需求占比越来越高。

4、数据大屏
数据大屏用来展示点我达规模、质量等服务运营指标,为公司内部和外部相关人群提供运营指标参考。数据大屏采用阿里云的datav数据可视化产品搭建,非本地部署方式,我们采购了4个显示大屏用于展示我们创建的4个datav屏幕,具体工作方式为:
a) 登录datav控制台,创建“可视化屏幕”
b) 设置屏幕的数据来源url、展示数据的格式和布局
c) 发布屏幕
d) 将配置完成的4张屏幕投放到大屏显示器中
5、hive元数据管理warden
对于bi分析人员,如果没有一个便捷的工具,在庞大的hive数据仓库中找到想要的指标是意见很困难的事情,为此,我们开发了一套hive元数据查询系统,比如,我关心订单妥投情况,我直接在全文检索搜索框中输入“妥投”,就会找到有哪些hive表包含了这个信息,截图如下:

六、OLTP层
用于内部系统的数据服务调用,使用dubbo rpc提供服务,每一个dubbo服务,后面都有一个或者多个streaming任务进行计算 数据服务简单列举几个:
POI服务:经纬度相关兴趣点服务
商家交易:商家通过app可以查看交易、账户等
骑手交易:骑手通过app查看交易、账户等
fft、fat:预测订单完成时间、预测骑手到店时间
天气服务:天气影响骑手考核和补贴
骑手轨迹:后台crm可以查看骑手的轨迹和到店、完成时点情况
历史订单查询:我们的业务库一般保留当天数据,ES提供历史订单的全文检索功能
订单压力(热力图):根据传递的经纬度,获取所覆盖的所有小方格的geohash及其订单压力情况,后台streaming算好了每个geohash的压力值,存储于redis中
七、高可靠性保证
对于大数据团队内部产品而言,OLAP应用一般是离线的或者使用者是内部用户,容许一定的延时,但OLTP服务一般处于整个OLTP系统的调用链中,需要高可靠性服务保证,我们从服务降级和监控报警处理两个层面实现服务的可靠性。
1、服务降级
比如压力服务,当我们的streaming任务挂掉或者处理缓慢怎么办,这时候我们起了一个每5分钟执行一次的备份job,当dubbo服务执行时,它首先检查streaming任务的最后写入redis key的时间,当此时间与当前时间差距超过我们设定的阈值时,就判定streaming任务异常,这时候就获取备份job的数据,极大地保证了压力服务的可靠性,示意图如下:

2、监控报警体系
a) 基础平台告警(仪表盘)
仪表盘是点我达通用的一套监控报警系统,可以设定阈值,如果某个监控的标的超过阈值,可以邮件、短信息实时告警,可以在第一时间处理。比如我们的dubbo服务,最起码的一个监控指标是执行时长,我们做了一个注解"@Monitor"和处理此注解的切面程序,如何方法只要加入了这个注解,会把这个方法的执行时长加入到监控系统中,在仪表盘监控页面中就可以看到这个方法的监控项(当然需要自己添加graph和influxdb mesurement) 对于另外个性化指标的监控,则每个服务自己去控制。

b) 大数据报警体系
大数据自身的报警体系如下图所示:

八、踩坑记录
大数据团队发展至今,遇到过很多问题,有大有小,不一而足,以下列举几个:
1、phoenix版本不匹配
查询和建表使用的phoenix版本不一致导致的数据重复的问题。phoenix表是使用4.9建的,dubbo里面用的是phoenix4.7,读取的时候发现读取到的数据有重复,后来升级dubbo服务的phoenix版本到4.9,解决了此问题
2、spark2.1.1的bug
代码示例:
val df = spark.sql( “”“select user_id, timestamp, order_id, user_name, lng, lat, status, leave_tm from ( select cast(user_id as bigint) user_id, cast(timestamp as bigint) timestamp, cast(coalesce(get_json_object(args,’ . o r d e r I d ′ ) , ′ 0 ′ ) a s i n t ) o r d e r i d , u s e r n a m e , c a s t ( l o n g i t u d e a s i n t ) l n g , c a s t ( l a t i t u d e a s i n t ) l a t , g e t j s o n o b j e c t ( a r g s , ′ .orderId'),'0') as int) order_id, user_name, cast(longitude as int) lng, cast(latitude as int) lat, get_json_object(args,' .orderId′),′0′)asint)orderid,username,cast(longitudeasint)lng,cast(latitudeasint)lat,getjsonobject(args,′.status’) status, cast(get_json_object(args,’$.leaveTm’) as bigint) leave_tm from logs where event=‘rider_trace’) t where user_id is not null and timestamp is not null and order_id is not null and status is not null “””)
这段代码是从logs数据源中读取和解析数据,其中 get _json _object 一直报错,提示 java.io.CharConversionException: Invalid UTF-32 character 0x7b2265(above 10ffff) at char #192, byte #771) at com.fasterxml.jackson.core.io.UTF32Reader.reportInvalid(UTF32Reader.java:189) at com.fasterxml.jackson.core.io.UTF32Reader.read(UTF32Reader.java:150) at com.fasterxml.jackson.core.json.ReaderBasedJsonParser.loadMore(ReaderBasedJsonParser.java:153) at com.fasterxml.jackson.core.json.ReaderBasedJsonParser._skipWSOrEnd(ReaderBasedJsonParser.java:1855) at com.fasterxml.jackson.core.json.ReaderBasedJsonParser.nextToken(ReaderBasedJsonParser.java:571) at org.apache.spark.sql.catalyst.expressions.GetJsonObjectKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲eval$2anonfun$4.apply(jsonExpressions.scala:142) 提示是说某些非法字符,因为我们没有捕获异常,报错了程序也不退出,反复处理这一条脏数据,后来临时改一下代码,把 get _json _object 去掉,绕过了这一条数据,再把程序改回来,后来在网上搜索了一下,发现是spark2.1.1的bug,已经在spark2.2.0之后的版本修复了。

3、yarn资源设置不当引起离线dag处理失败
为了提高作业的并发量,我们减少了单个map/reduce container的内存大小,结果某个订单的大作业无足够资源,运行失败,导致当日离线报表无数据。其实也是一个权衡,过大浪费资源、并发作业少;过小则大作业无法运行,需要我们对比较耗费资源的作业做到心里有数,对大作业单独指定资源
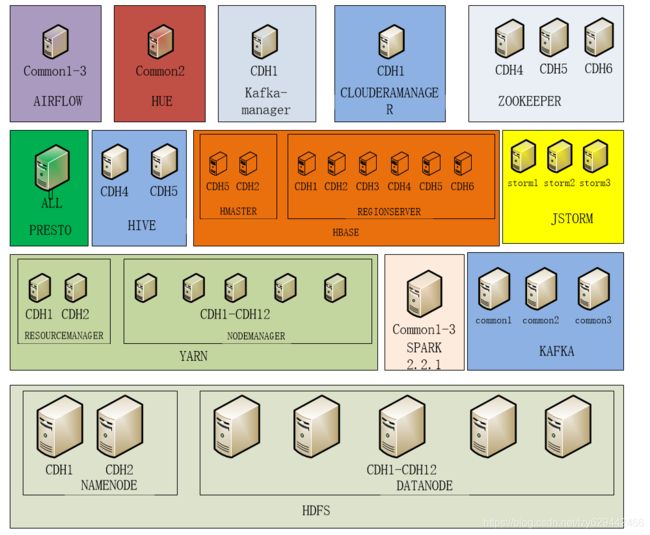
九、集群部署结构
附录点我达大数据服务集群部署结构如图示