ShardingJDBC 分库分表详解
ShardingJDBC 分库分表详解
- 1、ShardingSphere概述
-
- 1.1、ShardingSphere概述
- 1.2、ShardingSphere-JDBC概述
- 1.3、ShardingSphere-Proxy概述
- 1.4、分库分表概述
- 1.5、分库分表应用和存在的问题
- 2、ShardingSphere-JDBC概述
-
- 2.1、水平分表
- 2.2、水平分库分表
- 2.3、垂直分库分表
- 2.4、公共表操作
- 2.5、读写分离与主从复制
- 3、ShardingProxy概述
-
- 3.1、ShardingProxy是什么
- 3.2、ShardingProxy安装
1、ShardingSphere概述
1.1、ShardingSphere概述
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
主要来说就以下三点:
- 一套开源的分布式数据库中间件解决方案
- 有三个产品:主要使用到的是Sharding-JDBC 和 Sharding-Proxy
- 定位为关系型数据库中间件,合理在分布式环境下使用关系型数据库操作
1.2、ShardingSphere-JDBC概述
定位为轻量级 Java 框架,和spring、mybatis一样,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
1.3、ShardingSphere-Proxy概述
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL、Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
1.4、分库分表概述
存在问题:数据库数据量不可控的,随着时间和业务发展,造成表里面数据越来越多,如果再去对数据库表 curd 操作时候,造成性能问题。
解决方案:
- 方案 1:从硬件上
- 方案 2:分库分表
分库分表有两种方式:垂直切分和水平切分
- 垂直切分:垂直分表和垂直分库
- 垂直分表:操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一
部分字段数据存到另外一张表里面 - 垂直分库:把单一数据库按照业务进行划分,专库专表
- 垂直分表:操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一
- 水平切分:水平分表和水平分库
- 可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,这也就是对应的分表和分库
1.5、分库分表应用和存在的问题
应用
- 在数据库设计时候考虑垂直分库和垂直分表
- 随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
分库分表问题
- 跨节点连接查询问题(分页、排序)
- 多数据源管理问题
2、ShardingSphere-JDBC概述
ShardingSphere–JDBC操作流程,而使用他它的主要目的是为了帮我们简化对分库分表之后数据相关操作
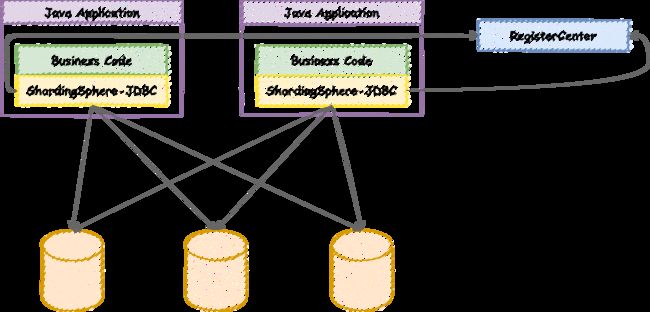
项目构建:使用springboot进行集成ShardingSphere-JDBC,使用idea进行初始化一个springboot的项目,之后我们导入关于数据库和sharding-JDBC的相关依赖。关于Springboot可参考:SpringBoot 详解
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
2.1、水平分表
约定规则:如果添加用户id是奇数把数据添加user1,如果偶数添加到user2。首先我们创建对应的两张表
create table user1(
id BIGINT(20) PRIMARY KEY,
name VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NULL
)
create table user2(
id BIGINT(20) PRIMARY KEY,
name VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NULL
)
先加上实体类、以及mapper直接继承BaseMapper进行后续操作,在启动类上加入注解 @MapperScan(mapper文件目录) 用来扫描mapper。而对于mybatis-plus可参考文章:Mybatis-Plus 详解
// 实体类
@Data
public class User {
private Long id;
private String name;
private int userId;
}
// mapper
@Repository
public interface UserMapper extends BaseMapper<User> {
}
// 启动类
@MapperScan("com.lzq.mapper")
而后需要对ShardingJdbc分表进行相关的配置:官网配置地址
# 配置真实数据源(给数据源取一个名字)
spring.shardingsphere.datasource.names=ds
# 配置第 1 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds.url=jdbc:mysql://localhost:3306/springboot?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds.username=root
spring.shardingsphere.datasource.ds.password=root
# 分表规则 表名+1,2
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds.user$->{1..2}
# 指定主键生成策略 主键id通过雪花算法生成
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 指定分片策略 根据生成的id进行分表
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user$->{id % 2 +1}
# 打印执行的sql语句日志
spring.shardingsphere.props.sql.show=true
# 防止bean已被使用
spring.main.allow-bean-definition-overriding=true
最后直接来对水平分表进行测试,直接for循环100次将数据插入到数据库当中,添加代码:
@Test
void contextLoads() {
for (int i =0;i<100;i++){
User user = new User();
user.setName("yue");
user.setUserId(i+100);
userMapper.insert(user);
}
}
@Test
void search(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("user_id",43);
wrapper.eq("id",1465571154688245765L);
List<Object> list = userMapper.selectObjs(wrapper);
for (Object user:list){
System.out.println(user);
}
}
2.2、水平分库分表
约定规则:如果添加用户id是奇数把数据添加user1,如果偶数添加到user2。这里还是用上面的表结构,但是在这里我们将创建两个库,springboot1和springboot2两个库,当userid为奇数加入springboot1这个库当中,偶数加入到springboot2这个库当中。首先将两个库以及库里面的表创建出来。
在这里修改配置文件,加入第二个数据源,以及分库的策略。其余Java代码不变,同样的直接执行test进行测试,查看对应的数据库的表数据进行验证。
# 配置真实数据源(给数据源取一个名字)
spring.shardingsphere.datasource.names=ds1,ds2
# 配置第 1 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/springboot1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
# 配置第 2 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/springboot2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
# 指定库表的分布规则
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds$->{1..2}.user$->{1..2}
# 指定主键生成策略 主键id通过雪花算法生成
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 指定分片策略 根据生成的id进行分表
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user$->{id % 2 +1}
# 指定库的分片策略
spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 +1}
# 打印执行的sql语句日志
spring.shardingsphere.props.sql.show=true
# 防止bean已被使用
spring.main.allow-bean-definition-overriding=true
2.3、垂直分库分表
加入新库和新表,
CREATE DATABASE detail;
CREATE TABLE user_detail(
user_id BIGINT(20) PRIMARY KEY,
age VARCHAR(50) NOT NULL,
sex VARCHAR(2) NOT NULL
);
修改配置文件:
# 配置真实数据源(给数据源取一个名字)
spring.shardingsphere.datasource.names=ds1,ds2,ds3
# 配置第 1 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localgost:3306/springboot1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
# 配置第 2 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/springboot2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
# 配置第 3 个数据源(对应自己的数据库)
spring.shardingsphere.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds3.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds3.url=jdbc:mysql://localhost:3306/detail?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds3.username=root
spring.shardingsphere.datasource.ds3.password=root
# 指定库表的分布规则
spring.shardingsphere.sharding.tables.user_detail.actual-data-nodes=ds3.user_detail
# 指定主键生成策略 主键id通过雪花算法生成
spring.shardingsphere.sharding.tables.user_detail.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user_detail.key-generator.type=SNOWFLAKE
# 指定分片策略 根据生成的id进行分表
spring.shardingsphere.sharding.tables.user_detail.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user_detail.table-strategy.inline.algorithm-expression=user_detail
# 打印执行的sql语句日志
spring.shardingsphere.props.sql.show=true
# 防止bean已被使用
spring.main.allow-bean-definition-overriding=true
2.4、公共表操作
在进行分库分表之后,多个数据表的数据会存在公共使用的表,在这里shardingjdbc也提供了对公共表的操作,在多个库当中的相同表,再每对其中一个公共表进行操作之后,另外库里面的公共表也会随之进行该变。在前面有使用到了三个库,直接在这三个库当中都加入一个相同表结构的表,作为一个公共表。
create table common(
common_id BIGINT(20) PRIMARY KEY,
common_name VARCHAR(50) NOT NULL,
common_detail VARCHAR(20) NOT NULL
)
而后在对于前面的配置文件进行修改,只需要加上对公共表的配置进行即可:
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=common
spring.shardingsphere.sharding.tables.common.key-generator.column=common_id
spring.shardingsphere.sharding.tables.common.key-generator.type=SNOWFLAKE
之后加上对应的实体类和mapper进行测试:直接跑一遍执行,程序跑完之后,直接在这三个库当中的common表进行查看数据。
2.5、读写分离与主从复制
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器;第二台数据库服务器,主要进行读的操作。原理∶让主数据库( master )处理事务性增、改、删操作,而从数据库( slave )处理SELECT查询操作。
在进行搭建数据库主从复制,首先我们需要准备两个数据库服务,这里以就按windows上的mysql服务为例,只需要将第一次安装的mysql服务复制一份出来,修改对应的my.ini配置文件,将端口、安装位置,数据存储目录进行相对应的修改即可。
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
#设置3307端口
port = 3307
# 设置mysql的安装目录
basedir=F:\mysql\mysql-8.0.18-winx64-slave
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 设置mysql数据库的数据的存放目录
datadir=F:\mysql\mysql-8.0.18-winx64-slave\data
default-time_zone = '+8:00'
修改完成之后,进入到复制后的bin目录当中打开cmd窗口,将这个服务进行安装,使用以下命令:
mysqld install mysqlslave --defaults-file="F:\mysql\mysql-8.0.18-winx64-slave\my.ini"
# 安装失败报错,使用管理员打开cmd安装即可
Install/Remove of the Service Denied
之后我们需要对两个mysql服务进行设置主服务器和从服务器。首先在主服务器上加上配置:
[mysqld]
server-id = 1 # 节点ID,确保唯一 一般设置为IP
binlog-do-db=springboot # 复制过滤:需要备份的数据库,输出binlog
# log config
log-bin = mysql-bin #开启mysql的binlog日志功能 可以随便取,最好有含义
sync_binlog = 1 #控制数据库的binlog刷到磁盘上去 , 0 不控制,性能最好,1每次事物提交都会刷到日志文件中,性能最差,最安全
binlog_format = mixed #binlog日志格式,mysql默认采用statement,建议使用mixed
expire_logs_days = 7 #binlog过期清理时间 二进制日志自动删除/过期的天数。默认值为0,表示不自动删除
max_binlog_size = 100m #binlog每个日志文件大小
binlog_cache_size = 4m #binlog缓存大小 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存
max_binlog_cache_size= 512m #最大binlog缓存大
binlog-ignore-db=mysql #不需要备份的数据库不生成日志文件的数据库,多个忽略数据库可以用逗号拼接,或者 复制这句话,写多行
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
#slave-skip-errors = all #跳过从库错误
slave-skip-errors = all
auto-increment-offset = 1 # 自增值的偏移量
auto-increment-increment = 1 # 自增值的自增量
而后在从服务器上同样的加上配置:
[mysqld]
server-id = 2
log-bin=mysql-bin
relay-log=mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
修改配置之后,将服务进行重启,同样,可以创建另外的用户进行测试。或者直接拿root用户进行测试。
GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'%' IDENTIFIED BY 'db_sync';
#刷新权限
FLUSH PRIVILEGES;
先进入到主服务器当中查看主服务器的状态:
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 537 | springboot | mysql | |
+------------------+----------+--------------+------------------+-------------------+
而后进入到从服务器当中,
# 先停止同步
STOP SLAVE;
# 修改从库指向到主库,使用上一步记录的文件名以及位点,对应前面主服务的状态数据
CHANGE MASTER TO
MASTER_HOST = 'localhost',
MASTER_USER = 'root',
MASTER_PASSWORD = 'root',
MASTER_LOG_FILE = 'mysql-bin.000001',
MASTER_LOG_POS = 155;
# 启动同步
START SLAVE;
# 查看Slave_IO_Runing和Slave_SQL_Runing字段值都为Yes,表示同步配置成功。
SHOW SLAVE STATUS;
# 存在问题 slave_io_running的值为NO,继续看查出来的表数据,发现在后面有一个单元格有错误的log信息,可以查看log信息:
# Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
# 因为主服务器和从服务器具有相同的MySQL服务器UUID;这些UUID必须不同,复制才能工作。
# 在前面进行复制的时候,是全量复制过来的,而UUID又没有进行修改,直接修改mysql的存放数据目录的auto.cnf文件,将UUID随便给个值,再重启从服务器即可。
最后进行验证,直接再主服务器当中对对应的库的数据进行修改或者新增等等操作,看从服务器当中的数据会不会进行相对应的改变即可。
代码实现,修改配置文件:对主服务器和从服务器进行相关配置
# 配置真实数据源(给数据源取一个名字)
spring.shardingsphere.datasource.names=ds1,s1
# 主服务器
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/springboot?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
# 从服务器
spring.shardingsphere.datasource.s1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url=jdbc:mysql://localhost:3307/springboot?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.s1.username=root
spring.shardingsphere.datasource.s1.password=root
# 主从关系
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=ds1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1
spring.shardingsphere.sharding.tables.user1.actual-data-nodes=ds1.user1
# 打印执行的sql语句日志
spring.shardingsphere.props.sql.show=true
# 防止bean已被使用
spring.main.allow-bean-definition-overriding=true
最后添加代码进行测试,加入一个插入和查询的方法,查看日志,插入操作的是主服务器,而查询数据是操作的从服务器。这样也就完成了读写分离和主从复制。
3、ShardingProxy概述
3.1、ShardingProxy是什么
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
适用于任何兼容MySQL/PostgreSQL协议的的客户端。
3.2、ShardingProxy安装
下载地址:https://archive.apache.org/dist/shardingsphere/4.1.1/