分库分表技术之ShardingJDBC
1.1 分库分表方式回顾
分库分表的目的就是将我们的单库的数据控制在合理的范围内,从而提高数据库的性能
–垂直拆分:(按照结构分)
- 垂直分表:将一张宽表(字段很多的表) 按照字母的访问顺序进行拆分,就是按照表单结构进行拆
- 垂直分库:根据不同的业务,将表进行分类,拆分到不同的数据库,这些库可以部署在不同的服务器,分摊访问压力。
水平拆分:(按照数据行分)
- 水平分库:将一张表的数据(按照数据行)分到多个不同的数据库,每库的表结构相同,每个库都只有这张表的部分数据,当表单的数据量过大的时候,如果继续使用水平分库,那么数据库的和实例就会不断增加,不利于系统的维护,这时候就要水平分表。
- 水平分表:将一张表的数据(按照数据行) ,分配到同一个数据库的多张表中,每个表都只有一部分数据。
什么时候会用到分库分表呢?
在系统设计阶段,就要完成垂直分库和垂直分表. 在数据量不断上升,数据库性能无法满足需求的时候, 首先要考虑的是缓存、 读写分离、索引技术等方案.如果数据量不断增加,并且持续增长再考虑水平分库 水平分表.
1.2 ShardingJDBC 简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成,我们只关注 Sharding-JDBC即可.
官方地址:
https://shardingsphere.apache.org/document/current/cn/overview/
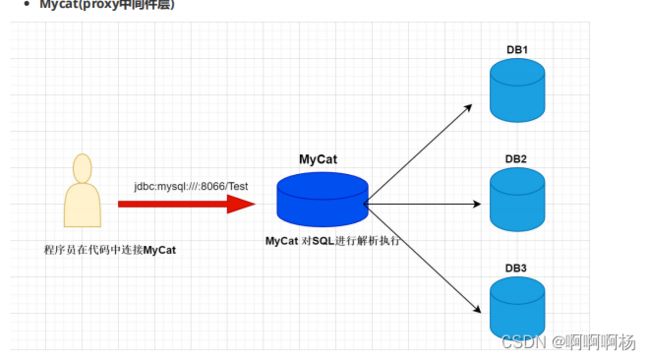
Sharding-JDBC 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架的使用。

上图展示了Sharding-Jdbc的工作方式,使用Sharding-Jdbc前需要人工对数据库进行分库分表,在应用程序中加入Sharding-Jdbc的Jar包,应用程序通过Sharding-Jdbc操作分库分表后的数据库和数据表,由于Sharding-Jdbc是对Jdbc驱动的增强,使用Sharding-Jdbc就像使用Jdbc驱动一样,在应用程序中是无需指定具体要操作的分库和分表的。
Sharding-JDBC与MyCat的区别
- mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
- 使用mycat时不需要修改代码,而使用sharding-jdbc时需要修改代码
- Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而
Sharding-JDBC 是基于 JDBC 的扩展,是以 jar 包的形式提供轻量级服务的。
分片规则配置(水平分表)
使用sharding-jdbc 对数据库中水平拆分的表进行操作,通过sharding-jdbc对分库分表的规则进行配
置,配置内容包括:数据源、主键生成策略、分片策略等。
application.properties:
基础配置:
spring.application.name = sharding-jdbc-simple
server.servlet.context-path = /sharding-jdbc
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
数据源:
# 定义数据源
spring.shardingsphere.datasource.names = db1
spring.shardingsphere.datasource.db1.type =
com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name =
com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url =
jdbc:mysql://localhost:3306/ywc_order?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123789
配置数据节点:
#配置数据节点,指定节点的信息
spring.shardingsphere.sharding.tables.pay_order.actual-data-nodes =
db1.pay_order_$->{1..2}
配置主键生成策略:
#指定pay_order表 (逻辑表)的主键生成策略为 SNOWFLAKE
spring.shardingsphere.sharding.tables.pay_order.keygenerator.column=order_id
spring.shardingsphere.sharding.tables.pay_order.key-generator.type=SNOWFLAKE
使用shardingJDBC提供的主键生成策略,全局主键
为避免主键重复, 生成主键采用 SNOWFLAKE 分布式ID生成算法
配置分片算法:
#指定pay_order表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.pay_order.tablestrategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.pay_order.tablestrategy.inline.algorithm-expression = pay_order_$->{order_id % 2 + 1}
分表策略表达式: pay_order_$-> {order_id % 2 + 1}
{order_id % 2 + 1} 结果是偶数 操作 pay_order_1表
{order_id % 2 + 1} 结果是奇数 操作 pay_order_2表
打开sql日志
# 打开sql输出日志
spring.shardingsphere.props.sql.show = true
步骤总结:
- 定义数据源
- 指定pay_order 表的数据分布情况, 分布在 pay_order_1 和 pay_order_2
- 指定pay_order 表的主键生成策略为SNOWFLAKE,是一种分布式自增算法,保证id全局唯一
- 定义pay_order分片策略,order_id为偶数的数据下沉到pay_order_1,为奇数下沉到在
pay_order_2
编写程序:
@mapper
@Component
public interface PayOrderDao{
/**
* 新增订单
* */
@Insert("insert into pay_order(user_id,product_name,COUNT) values(#
{user_id},#{product_name},#{count})")
int insertPayOrder(@Param("user_id") int user_id, @Param("product_name")
String product_name, @Param("count") int count);
}
测试:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RunBoot.class)
public class PayOrderDaoTest {
@Autowired
PayOrderDao payOrderDao;
@Test
public void testInsertPayOrder(){
for (int i = 1; i < 10; i++) {
//插入数据
payOrderDao.insertPayOrder(1,"小米电视",1);
}
}
}
1.3 ShardingJDBC执行流程
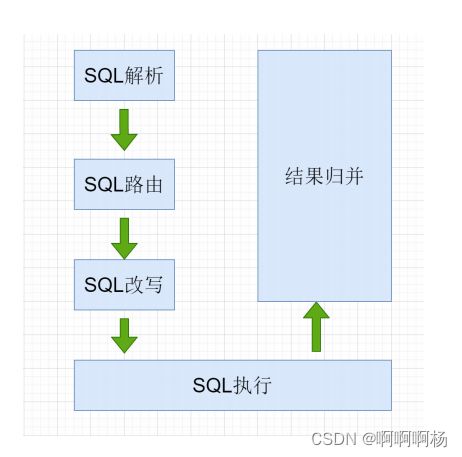
- SQL解析: 编写SQL查询的是逻辑表, 执行时 ShardingJDBC 要解析SQL ,解析的目的是为了找到需
要改写的位置. - SQL路由: SQL的路由是指 将对逻辑表的操作,映射到对应的数据节点的过程. ShardingJDBC会获取
分片键判断是否正确,正确 就执行分片策略(算法) 来找到真实的表. - SQL改写: 程序员面向的是逻辑表编写SQL, 并不能直接在真实的数据库中执行,SQL改写用于将逻辑
SQL改为在真实的数据库中可以正确执行的SQL. - SQL执行: 通过配置规则 pay_order_$->{order_id % 2 + 1} ,可以知道当 order_id 为偶数时 ,
应该向 pay_order_1表中插入数据, 为奇数时向 pay_order_2表插入数据. - 将所有真正执行sql的结果进行汇总合并,然后返回。