【数据压缩】LZW编解码原理及算法实现
一、LZW简介
LZW压缩(LZW compression)是一种由Abraham Lempel、Jacob Ziv和Terry Welch发明的基于表查寻算法把文件压缩成小文件的无损压缩方法。
LZW算法又叫“串表压缩算法”就是通过建立一个字符串表,用较短的代码来表示较长的字符串来实现压缩。
其基本原理为提取原始文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符索引来替代原始文件数据中的相应字符,减少原始数据大小。这里的编译表不是事先创建好的,而是根据原始文件数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表。
二、LZW编解码算法及举例
1、LZW编码算法思想
LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流。
LZW编码算法的步骤如下:
步骤1:将词典初始化为包含所有可能的单字符(常用ASCII码表),
当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中。
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2。
举例:输入流 a b b a b a b a c
首先,以ASCII码为基础词典
已编码:a b
- 遇到a,用97表示,编码为97。
- 遇到b,用98表示,编码为98。
- 发现ab,加入词典,ab索引为256。
已编码:a b b a b
- 遇到b,编码为98,发现bb,加入词典,索引为257。
- 遇到a,发现ba,加入词典,索引为258。
- 遇到b,ab已存在词典内,编码为256。
已编码:a b b a b a b a c
- 遇到a,发现aba,加入词典,索引为259。
- 遇到b,ab已存在词典。
- 遇到a, aba已存在词典内,编码为259。(这里刚加入词典就用到了)
- 遇到c,编码为99,发现abac,加入词典,索引为260。
- 编码结束,编码码流和输入码流对比为:
a b b a b a b a c
97 98 98 256 259 99
输入:8bit × 9=72bit
输出:9bit × 6=54bit
2、LZW解码算法思想
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解
码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串string.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串string.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串string.CW输出到字符流。
当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前前缀-符串string.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前缀-符串string.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
解码过程举例:
97 98 98 256 259 99
- 遇到97,在基础词典,解码为a。
- 遇到98,在基础词典,解码为b,发现ab,可知256对应ab。
- 遇到98,在基础词典,解码为b,发现bb,可知257对应bb。
- 遇到256,解码为ab,发现ba,可知258对应ba。
已编码:a b b a b
- 遇到259,目前词典没有259,为什么会发生这种情况?
只有当码字刚加入词典就被用于编码时,才会出现这一情况,则下一个字符(这里的第六个字符)与上一个码字构成新加入词典的码字,并与后面字符共同编码为这一码字。故而这一字符,与上一个码字的头个字符相同。 - 259解码为aba(“ab"+“a”)。
- 遇到99,在基础词典,解码为c。
- 解码结束。
已解码:a b b a b a b a c
三、LZW编码算法实现
1、数据结构
struct {//词典节点结构体
int suffix; //后缀字符
int parent, firstchild, nextsibling;//母节点、第一个孩子节点、兄弟节点
} dictionary[MAX_CODE+1]; //数组下标为编码
typedef struct{//二进制文件结构体
FILE *fp;//输出文件指针
unsigned char mask;//掩码
int rack;//缓存,每写入8位,写入rack
}BITFILE;
2、编码代码分析
(1)编码总流程
void LZWEncode( FILE *fp, BITFILE *bf){
int character;//字符
int string_code;//前缀
int index;//编码
unsigned long file_length;//文件大小
fseek( fp, 0, SEEK_END);//文件指针定位到文件最后
file_length = ftell( fp);//输入文件大小
fseek( fp, 0, SEEK_SET);//文件指针定位到文件起始
BitsOutput( bf, file_length, 4*8);//将输入文件大小写入输出文件。32位表示文件大小
InitDictionary();//词典初始化
string_code = -1;//前缀初始化
while( EOF!=(character=fgetc( fp))){//依次扫描输入文件,取出各字符
index = InDictionary( character, string_code);//判断码字string+character是否在词典中
if( 0<=index){ // string+character在词典中
string_code = index;//将string+character对应编码作为前缀
}else{ // string+character不在词典中
output( bf, string_code);//输出前缀
if( MAX_CODE > next_code){ // 若词典有剩余空间
// 将string+character加入词典
AddToDictionary( character, string_code);
}
string_code = character;//将新字符作为新的前缀
}
}
output( bf, string_code);//文件扫描完毕,将最后未输出的前缀输出
}
(2)词典初始化
void InitDictionary( void){//词典初始化即将0-255根节点初始化
int i;
for( i=0; i<256; i++){//下标为ASCII码值
dictionary[i].suffix = i;//根的后缀字符为对应ASCII码
dictionary[i].parent = -1;//没有母节点
dictionary[i].firstchild = -1;//暂时没有第一个孩子节点
dictionary[i].nextsibling = i+1;//下一个兄弟节点下标为下一个ASCII码值
}
dictionary[255].nextsibling = -1;//最后一个根节点没有下一个兄弟节点
next_code = 256;//下一个编码为256
}
(3)判断码字是否在词典中
int InDictionary( int character, int string_code){//判断码字string+character是否在词典中 string_code前缀 character后缀
int sibling;
if( 0>string_code) return character;//文件第一个字符,故而编码为character的ASCII码值
/*自左向右遍历string_code节点的所有孩子(第一个孩子的所有兄弟)*/
sibling = dictionary[string_code].firstchild;//string_code节点的第一个孩子
while( -1<sibling){//sibling=-1时说明所有兄弟遍历结束
if( character == dictionary[sibling].suffix) return sibling;//若找到兄弟节点的后缀是character,则返回此节点的编码即下标sibling
sibling = dictionary[sibling].nextsibling;//若该兄弟节点后缀不是character,则寻找下一个兄弟节点
}
return -1;//若遍历所有兄弟节点的后缀后,都找不到该字符,说明string+character不在字典中,返回-1
}
(4)将码字添加到词典中
void AddToDictionary( int character, int string_code){//码字不在词典,添加进词典中,并编码为next_code
int firstsibling, nextsibling;
if( 0>string_code) return;
dictionary[next_code].suffix = character;//新节点的后缀为该字符
dictionary[next_code].parent = string_code;//新节点的母亲节点为该前缀
dictionary[next_code].nextsibling = -1;//新节点下一个兄弟节点暂不存在
dictionary[next_code].firstchild = -1;//新节点的第一个孩子节点暂不存在
firstsibling = dictionary[string_code].firstchild;//新节点的母亲节点的第一个孩子
/*设置新节点的兄弟关系*/
if( -1<firstsibling){ // 若新节点的母亲节点原本有孩子
nextsibling = firstsibling;
while( -1<dictionary[nextsibling].nextsibling ) //循环找到该母亲节点的最后一个孩子即新节点的最后一个兄弟
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;//将新节点设为最后一个兄弟的下一个兄弟
}else{// 若新节点的母亲节点原本没有孩子
dictionary[string_code].firstchild = next_code;//则新节点是母亲节点的第一个孩子
}
next_code ++;//下一个编码增加1
}
(5)打开二进制文件
BITFILE *OpenBitFileOutput( char *filename){//输出文件名
BITFILE *bf;
bf = (BITFILE *)malloc( sizeof(BITFILE));
if( NULL == bf) return NULL;
if( NULL == filename) bf->fp = stdout;//如果参数为NULL,则指向屏幕
else bf->fp = fopen( filename, "wb");//以二进制只写的方式打开文件
if( NULL == bf->fp) return NULL;
bf->mask = 0x80;//掩码为10000000
bf->rack = 0;//缓存为0
return bf;
}
(6)按位输出数据到输出文件
void BitsOutput( BITFILE *bf, unsigned long code, int count){
unsigned long mask;
/*计算掩码值,位数为count的数值且最高位为1,例如若count为16,则mask=1000 0000 0000 0000*/
mask = 1L << (count-1);
while( 0 != mask){//mask为0时,说明code的count位数字输出完毕,注意:LZW是等长码
BitOutput( bf, (int)(0==(code&mask)?0:1));//按位输出code
mask >>= 1;//掩码向右移位
}
}
void BitOutput( BITFILE *bf, int bit){
/*若bite=1,则本code输出结束,此时mask为1,rack为0,则缓存rack变为1
若bit=0,则尚未输出结束,此时mask向右移位,为0,rack不变*/
if( 0 != bit) bf->rack |= bf->mask;
bf->mask >>= 1;//mask向右移1位
/*若mask溢出为0,则表示成功累计写入8位,则直接输出rack,
并将rack初始化为0,mask初始化为1000 0000*/
if( 0 == bf->mask){ // eight bits in rack
fputc( bf->rack, bf->fp);
bf->rack = 0;
bf->mask = 0x80;
}
}
(7)关闭二进制输出文件
void CloseBitFileOutput( BITFILE *bf){
// 输出剩余的二进制数
if( 0x80 != bf->mask) fputc( bf->rack, bf->fp);
fclose( bf->fp);//关闭二进制输出文件
free( bf);//释放内存
}
3、以文本文件为输入,得到输出的LZW编码文件
调试LZW的编码程序,以一个文本文件作为输入,得到输出的LZW编码文件。
这里输入文本文件text1内容为英文文章,得到输出文件text2。

四、LZW解码算法实现
1、解码代码编写与分析
(1)得到输入文件数据
以count位为单位得到输入文件中的数据
unsigned long BitsInput( BITFILE *bf, int count){
unsigned long mask;//掩码
unsigned long value;//
/*计算掩码值,位数为count的数值且最高位为1,例如若count为16,则mask=1000 0000 0000 0000*/
mask = 1L << (count-1);
value = 0L;//初始化value为0
/*mask由1000 0000 0000 0000向右移位至溢出为0时循环结束,取得16位的等长码*/
while( 0!=mask){
/*输出文件下一位为1时,value相应位变为1,为0时不作变化,遍历下一位*/
if( 1 == BitInput( bf))
value |= mask;//value在mask对应位置的二进制数字变为1
mask >>= 1;//mask向右移动一位
}
return value;
}
逐位得到输出文件中的二进制数字(从右向左)
int BitInput( BITFILE *bf){
int value;
if( 0x80 == bf->mask){//当mask为1000 0000时,从文件中得到一字节数据
bf->rack = fgetc( bf->fp);
if( EOF == bf->rack){//若成功得到数据
fprintf(stderr, "Read after the end of file reached\n");//输出
exit( -1);
}
}
value = bf->mask & bf->rack;//取得mask掩码所表示的位置所在处的二进制数字
bf->mask >>= 1;//mask向右移动一位
if( 0==bf->mask) bf->mask = 0x80;//若溢出为0,则mask重新初始化为1000 0000
return( (0==value)?0:1);//value为0则返回0,为其它数字则返回1
}
(2)解码总流程
void LZWDecode( BITFILE *bf, FILE *fp){
//需填写
int character;//新/旧编码首字母
int new_code;//新编码
int last_code = -1;//起初旧编码空缺,初始化为-1
int string_length;//输出字符串长度
unsigned long file_length;//输出文件大小
file_length = BitsInput(bf, 4*8);//输入文件起始处为输出文件大小,共32位
if (-1 == file_length) file_length = 0;//若文件无内容,大小为0
InitDictionary();//词典初始化,设置0-255的根节点
while (file_length > 0) {//若读取到最后一个编码,结束循环
new_code = input(bf);//16位读取新编码
if (new_code >= next_code) {//若字典中没有新编码
d_stack[0] = character;//character为旧编码last_code的首字母,将其放置在数组d_stack[0]首位
/*遍历旧编码last_code所在树,将last_code对应字符串放入d_stack,前缀在栈底,后缀在d_stack[1]。返回字符串长度*/
string_length = DecodeString(1, last_code);
}
else {//若字典中已有新编码
/*遍历新编码new_code所在树,将new_code对应字符串放入d_stack,前缀在栈底,后缀在d_stack[0]。返回字符串长度*/
string_length = DecodeString(0, new_code);
}
/*若新读取的编码不存在于词典中,character为旧编码last_code的首字母
若新读取的编码存在于词典中,character为新编码new_code的首字母*/
character = d_stack[string_length - 1];
/*若新读取的编码不存在于词典中,输出旧编码last_code对应字符串+last_code的首字母
若新读取的编码存在于词典中,输出新编码new_code对应字符串*/
while (string_length > 0) {
string_length--;
fputc(d_stack[string_length], fp);
file_length--;
}
/*若新读取的编码不存在于词典中,将last_code对应字符串+last_code的首字母添加到词典
若新读取的编码存在于词典中,将last_code对应字符串+new_code的首字母添加到词典*/
if (MAX_CODE > next_code) {
AddToDictionary(character, last_code);
}
last_code = new_code;//新编码变为旧编码
}
}
(3)将字符串放入d_stack,得到解码后字符串长度
int DecodeString( int start, int code){
//需填充
int count = start;//d_stack下标
while (code >= 0) {//code=-1时到达根节点循环结束
d_stack[count] = dictionary[code].suffix;//下标为code的节点中的后缀字母放置数组对应位置,这里是d_stack[0/1]
code = dictionary[code].parent;//节点上移至母节点
count++;//字符数增加1
}
return count;//返回字符串长度
}
(4)当前码字在词典中不存在时应如何处理
当前码字在词典中不存在时,该码字对应字符串=旧编码对应字符串+旧编码的首字符,此时则直接输出旧编码对应字符串+旧编码的首字符,并将其加入词典。
原因在实例中进行了说明,在编码时,上一个新的词条刚被编码,下一个词组就使用到了它。由于解码端的解码会比编码晚一步,我们没有得到最新的词条就使用了。此时下一个词组的首字符与上一个词条首字符相同。故而下一个编码字符串为旧编码对应字符串+旧编码的首字符。
2、以之前得到的LZW编码文件作为输入,得到输出的解码文件
以之前得到的LZW编码文件text2作为输入,得到输出的解码文件text1_decode。

打开文件可以发现,text1_decode与text1内容相同,解码成功。

五、LZW压缩效率
选择至少十种不同格式类型的文件,使用LZW编码器进行压缩得到输出的压缩比特
流文件。对各种不同格式的文件进行压缩效率的分析。
原文件如下图所示。
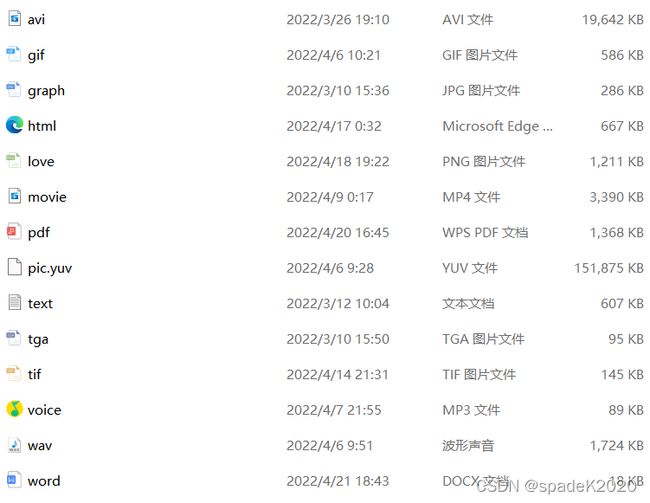
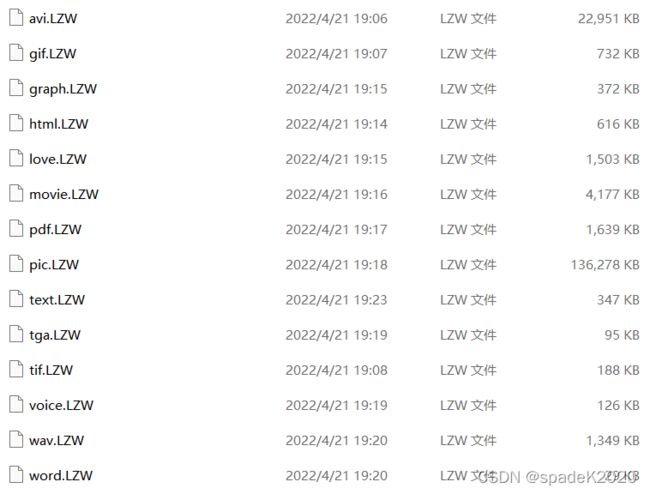
使用LZW编码器进行压缩后文件如下图。
压缩比如下图所示。

可以发现,此实验中除txt文本文件、html文本文件、wav音频文件和yuv视频文件的压缩比小于1外,其它10种文件压缩比均大于1。LZW的编码思想是不断从字符流中提取新的字符串,只有重复字符串越多,才能使词典越小,压缩效率越大。在应用中可能因为文件中重复字符串过少,导致压缩后文件大小不降反升。
附件:完整代码
1、lzw.c
#include \n" , argv[0]);
fprintf( stdout, "\t: E or D reffers encode or decode\n" );
fprintf( stdout, "\t: input file name\n" );
fprintf( stdout, "\t: output file name\n" );
return -1;
}
if( 'E' == argv[1][0]){ // LZW编码
fp = fopen( argv[2], "rb");//输入文件名
bf = OpenBitFileOutput( argv[3]);//输出文件名
if( NULL!=fp && NULL!=bf){
LZWEncode( fp, bf);
fclose( fp);
CloseBitFileOutput( bf);
fprintf( stdout, "encoding done\n");
}
}else if( 'D' == argv[1][0]){ // LZW解码
bf = OpenBitFileInput( argv[2]);//输入文件名
fp = fopen( argv[3], "wb");//输出文件名
if( NULL!=fp && NULL!=bf){
LZWDecode( bf, fp);
fclose( fp);
CloseBitFileInput( bf);
fprintf( stdout, "decoding done\n");
}
}else{
fprintf( stderr, "not supported operation\n");
}
return 0;
}
2、bitio.h
#ifndef __BITIO__
#define __BITIO__
#include 3、bitio.c
#include 参考
LZW压缩-百度百科
LZW编解码算法实现与分析_C语言实现