1、Elasticsearch简介与安装使用
一、Elastic Stack 是什么
Elastic Stack 是 ELK Stack 的更新换代产品,通过访问官网,可以看到 Elastic 产品的生态分布情况,如图所示:
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash和 Kibana。Elasticsearch 是一个搜索和分析引擎,通常简写成 ES;Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 ES 等“存储库”中;Kibana 则可以让用户在 ES 中使用图形和图表对数据进行可视化。
接下来,将陆续更新ES、Logstash、Kibana等相关的内容,先从 Elasticsearch 开始吧。ES 的版本更新是相对较快的(最新为8.2),目前我从 Elastic中文社区下载 的 ES 版本为6.8,将用这个版本作为学习和使用的参考。
二、Elasticsearch 简介
Elasticsearch 是一个分布式的基于 REST 风格的强大搜索引擎,底层是使用 Java 语言编写并使用 Lucene 来建立索引并实现搜索功能,然而 ES 目的是通过简单连贯的 RESTful API 让全文搜索变得更加简单并隐藏了 Lucene 的复杂性。
Lucene 又是啥呢?可以访问它的官网一探究竟,官网上的大致介绍可知,Lucene 是 Apache下的一个子项目,是一个开放源代码的全文检索引擎工具包。注意,Lucene 不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,可以提供完整的查询引擎和索引引擎,以及部分文本分析引擎等功能。
然而,Elasticsearch 不仅仅是 Lucene 和全文搜索引擎,ES 还提供了:分布式的实时文件存储,每个字段都被索引并可被搜索;实时分析的分布式搜索引擎;可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据等功能。
总结下 Elasticsearch 的显著特点:
- 支持多个索引、支持索引级别的配置(如分片数/索引存储等);
- 支持分布式和高可用,在每个索引都使用可配置数量的分片进行完全分片,每个分片都可以有一个或多个副本,在任何副本分片上可执行读取/搜索操作;
- 每个分片都是一个功能齐全的 Lucene 索引,Lucene 的所有功能都可以通过简单的配置/插件轻松暴露;
- 支持多种 API,比如 HTTP RESTful API、Native Java API 等,所有 API 都执行自动节点操作重新路由;
- ES 是面向文档进行数据存储的,文档是ES最小单元,支持多种数据类型,单文档级操作具有原子性/一致性/隔离性和持久性,我们可以通过定义文档结构而创建索引;
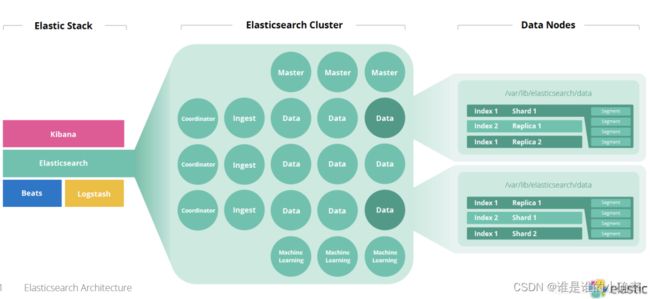
Elasticsearch 有许多基础而重要的概念,例如集群(Cluster)、节点(Node)、分片(Shard)、副本(Replica)、索引(Index)、文档(Document)、类型(type)等等,后面会详细的介绍说明,它们的关系如图所示:
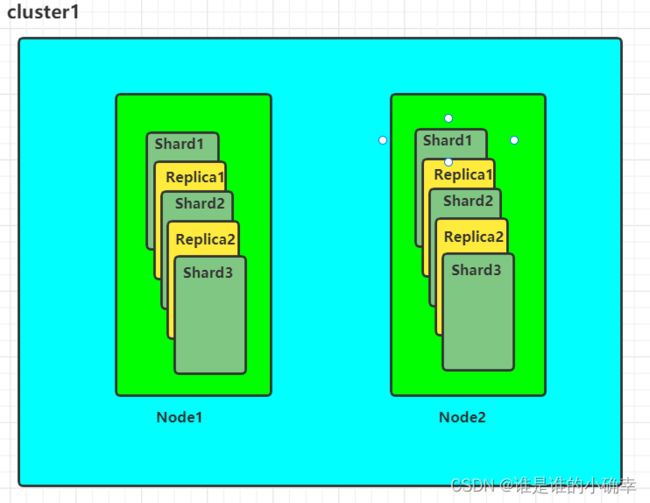
1、集群 Cluster
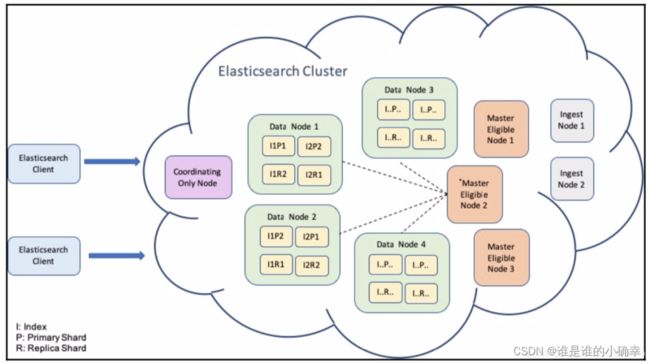
它由一个或多个节点 Node 组成,可通过其集群名称进行标识,集群名称可以在 config/elasticsearch.yml 文件中进行配置,默认为“elasticsearch”。一个 ES Cluster 的组成,如下图所示:
我们可以通过如下命令,查看集群的状态信息:
GET _cluster/state2、节点 Node
在上面 ES 集群的示意图中可以看到有许多类型的节点 Node,通常根据功能和用途,Node 可分为以下几种类型:
- master-eligible Node:如果成为主节点,将负责管理整个集群的设置和更新;
- data Node:数据节点;
- ngest Node:数据接入节点(比如 pipepline);
- machine learning Node:专有的机器学习节点。
通常,一个 Node 可具有上面的多种类型,而实际不会去这么配置。在 config/elasticsearch.yml 文件中,我们可以进行配置 Node 在集群中所扮演的角色,如图所示:
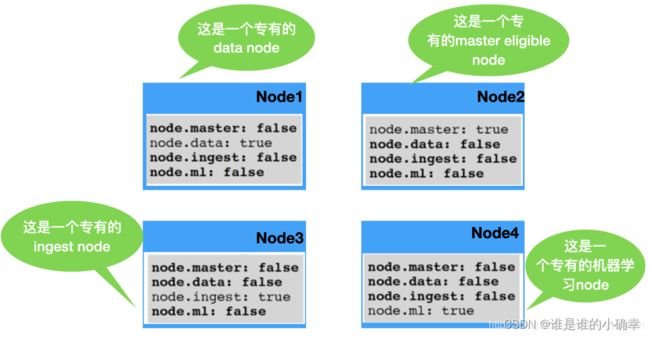
请注意,当配置文件没有进行 Node 参数的任何配置时,则会认为该 Node 是一个 coordination node(协作节点,它可以接受外部的请求,并转发到相应的节点来处理)。
在实际部署到现网时,最好是一台服务器上运行一个 Node,我们可把请求发送给 data Node,而不是发送给 master Node。关于 data Node 在整个集群中的地位,如下图所示:
3、文档 Document
文档 Document 是 ES 索引或搜索的最小数据单元。通常,文档之间是独立的,并且用Json数据格式表示,如果类比关系型数据库的话,ES 文档相当于数据库的表的行。
4、类型 type
类型 type 是文档 Document 的逻辑容器,在默认的情况下是 _doc。在 ES 6.0 之后,一个索引只能含有一个类型 type,而这其中的原因是:相同索引的不同映射 type 中具有相同名称的字段是相同的;在索引中,不同映射 type 中具有相同名称的字段在 Lucene 中被同一个字段支持。在 ES 8.0 的版本中,type 将会被彻底删除。这里呢,只做简单了解即可。
5、分片 Shard 与 副本 Replica
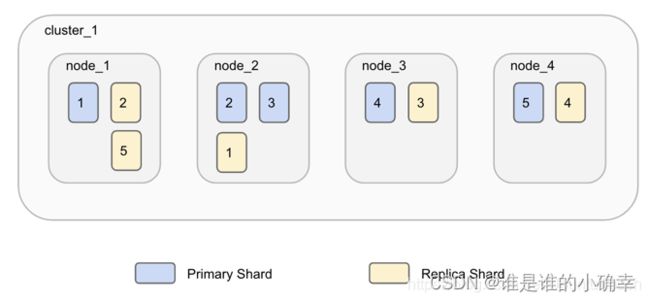
ES 是分布式的,它会把一个索引拆成多份进行排列,这个拆成多份的能力称为分片 shard。而创建索引的时候,是可以指定分片数量的,指定多个分片的话,ES 会自动管理这些分片的排列,并且还根据需要重新平衡分片,而我们无需担心细节。
分片 shard 有两种类型:主分片 primary shard 、副本分片 replica shard。索引可以包含一个或多个主分片 Primary shard,在索引创建后,是无法更改索引中的主分片数的。索引的每个文档都存储在一个Primary shard,当索引文档时,首先在 Primary shard上编制索引,然后在此分片的所有副本上(replica)编制索引,从而保持了分片与副本的数据一致性。
每个主分片可以具有零个或多个副本分片 replica shard,replica 是主分片的副本,这样设计的好处在于可以提高搜索查询性能,及增加故障转移能力。
默认情况下,ES 为每个索引创建一个主分片和一个副本分片,分配多个分片和副本分片是分布式搜索功能设计的本质,能提供高可用性和快速访问索引中的文档。请注意,ES 永远不会在与其主分片相同的节点上启动副本分片,如下图所示:
在最新的 ES 集群设计中,可使用 auto_expand_replica 这个配置来让 ES 自动决定有多少个副本。当有一个节点时,通过这个选项设置,可能会得到0个副本 replica 从而保证整个集群的健康状态。这里顺便区分下,分片 shard 的健康标识:
- 红色:集群中未分配至少一个主分片。
- 黄色:已分配所有主副本,但未分配至少一个副本。
- 绿色:分配所有分片。
6、索引 Indexes
ES 的索引是一个逻辑命名空间,它映射到一个或多个主分片,并且可以具有零个或多个副本分片。索引也是由一个或多个文档 document 组成的,并且这些文档 documents 可以分布于不同的分片之中。
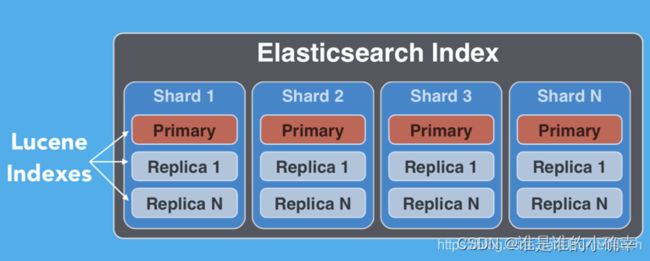
每当一个文档进来后,根据文档ID会自动进行 hash 计算,并存放于计算出来的 shard 实例中,这样的结果可以使得所有的 shard 都比较有均衡的存储:
shard_num = hash(_routing) % num_primary_shards请注意,这里的 _routing 是空文档的 _id,且 shard 数目是不可以动态修改的,否则会找不到相应的 num_primary_shards,而副本 replica 的数目是可以动态修改的。
三、Elasticsearch 安装、配置及简单使用
Elasticsearch 支持在 Windows、MacOS、Linux 等系统上进行安装,这里,我使用的是Linux的CentOS7.9系统。
1、Installing Elasticsearch
Elasticsearch 安装教程,我参考的是官网提供的指南,地址如下:
Installing Elasticsearch | Elasticsearch Guide [6.8] | Elastic
Elasticsearch 中文社区的下载界面,提供了各种版本的下载链接:(这里,我选择的是Linux64(TAR),6.8.10版本)
下载中心 - Elastic 中文社区
请注意,ES 是不允许使用 root 用户安装的,在解压 tar.gz 之前,需要创建一个用户:
# 暂定用户myes,密码为20220621
[root@localhost /]# useradd myes
[root@localhost /]# passwd myes
更改用户 myes 的密码 。
新的 密码:
无效的密码:密码未通过字典检查 - 它没有包含足够的不同字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@localhost /]# su myes
[myes@localhost /]$完成上面的步骤后,将下载的 tar.gz 上传到/home/myes/目录,并解压到该目录下:
[myes@localhost ~]$ tar -zxvf elasticsearch-6.8.6.tar.gz
# 查看es目录
[myes@localhost elasticsearch-6.8.6]$ ll
bin
config
lib
LICENSE.txt
logs
modules
NOTICE.txt
plugins
README.textile2、Configuring Elasticsearch
接着,可以对JVM、ES、日志等配置文件进行相关配置(这里我只配置单点):
[myes@localhost config]$ ls
elasticsearch.yml jvm.options log4j2.properties role_mapping.yml roles.yml users users_roles
# 修改jvm.options配置文件,比如调整JVM内存大小
[myes@localhost config]$ vi jvm.options
# 修改elasticsearch.yml配置文件,可以设置集群,节点等,指定数据和日志目录等
[myes@localhost config]$ vi elasticsearch.yml
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /home/myes/elasticsearch-6.8.6/data
#
# Path to log files:
#
path.logs: /home/myes/elasticsearch-6.8.6/logs
#
---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
#http.port: 9200
#3、Elasticsearch Bootstrap Checks
至此,可以对 ES 服务进行启动检查了。
<1>. 启动es:
[myes@localhost elasticsearch-6.8.6]$ ./bin/elasticsearch
启动时,这里出现了2个问题:文件权限不足、虚拟内存不足,解决方法如下:
[myes@localhost elasticsearch-6.8.6]$ su root
密码:
# 文件权限不足,增加以下四个配置:
[root@localhost elasticsearch-6.8.6]# vi /etc/security/limits.conf
# -
#
#* soft core 0
#* hard rss 10000
#@student hard nproc 20
#@faculty soft nproc 20
#@faculty hard nproc 50
#ftp hard nproc 0
#@student - maxlogins 4
* soft nofile 65535
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
# 虚拟内存不足,增加以下内容
[root@localhost elasticsearch-6.8.6]# vi /etc/sysctl.conf
#
vm.max_map_count=524240
# 重启终端窗口
[root@localhost elasticsearch-6.8.6]# sysctl -p
vm.max_map_count = 524240
# 重新启动es:
[root@localhost elasticsearch-6.8.6]# su myes
[myes@localhost elasticsearch-6.8.6]$ ./bin/elasticsearch 问题解决后,启动日志如下:
当然,也可以通过 jps 命令查看 ES 进程是否在运行:
[myes@localhost elasticsearch-6.8.6]$ jps
30449 Elasticsearch
30974 Jps通过浏览器访问宿主机的IP:9200,可以看到默认集群名称为"elasticsearch"的信息,如下:
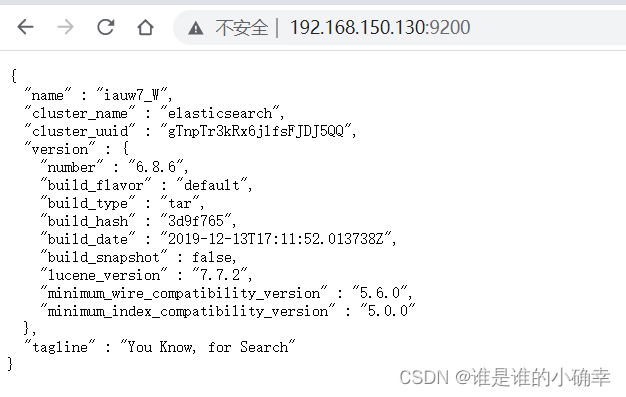
<2>. 运行守护进程:
如果希望 ES 进程以后台方式运行,我们可以使用守护进程运行 ES,设置如下:
[myes@localhost elasticsearch-6.8.6]$ ./bin/elasticsearch -d
[myes@localhost elasticsearch-6.8.6]$ jps
31347 Elasticsearch
31389 Jps最后
Elasticsearch 是开发常用的一种分布式搜索技术,这里对它的基础而重要的概念进行了介绍说明,并使用6.8版本进行安装、配置和使用的演示。下篇,将重点介绍 Elasticsearch 的分词器及使用。