Java架构师面试必备题(含答案)
第一题:一条sql执行过长的时间,你如何优化,从哪些方面?
答:1、查看sql是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度
4、针对数量大的表进行历史表分离(如交易流水表)
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,MySQL有自带的binlog实现 主从同步
6、explain分析sql语句,查看执行计划,分析索引是否用上,分析扫描行数等等
7、查看mysql执行日志,看看是否有其他方面的问题
第二题:深入理解CAP
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)这三个要素最多只能同时实现两点,不可能三者兼顾。分布式系统肯定优先保证P,多数时候是在C和A之间做权衡选择!
C:各个节点查询的数据都一致;
A:所有节点尽量可用;
P:节点之间无法通信;
AP架构
向一个节点A写入数据成功后,立刻给客户端响应写成功的信号。
如果此时集群节点之间网络断开了,由于其可用性,其他节点仍然提供服务,但是A节点的数据还未写入到其他节点,当访问除A之外的其他节点时,就会出现数据不一致的问题,当网络恢复后,才会通过心跳保证最终一致性!
CP架构
在向一个节点A写入数据成功后,并不是马上给客户端响应写成功的信号,而是等待数据同步到其他节点后(个数取决于配置),才响应客户端,表示此次写数据成功了!这在一定程度上保证了数据一致性。为了防止数据混乱,写数据时只允许往Leader节点写,读数据时可以从所有节点读取!
CP架构下具有特殊的Leader - Flower机制,当发生网络分区时,非Leader分区下的节点会变成不可用,重新进入选举状态。
第三题:双十一秒杀高可靠如何实现?
Sentinel承接了阿里10年的促销场景,利用:流量控制(通过设置QPS来控制),容错(熔断就是切断坏路,让后续新流量再走这个坏路),降级(备选B角,走了try-cath的机制,),三板斧解决高可靠。熔断机制:通过滑动时间窗口实现的,对前一段时间的错误比例来设置熔断点。
第四题:分布式事务问题如何解决?
Seata:服务端也是通过安装和配置来实现,使用很简单,实现了事务协调功能,需要加一个依赖包,然后加一个注解@globalTranscational, AT模式,是最推荐的一种,举例:Seata如何协调订单和库存?要求同时成功或者失败。一阶段:订单和库存,都先做回滚日志记录在本地事务中,二阶段:如果有一个失败,通过回滚日志来回到回到初始。
第五题:nacos和zookeeper是如何防止脑裂的?
集群的脑裂通常是发生在集群之间通信不可达(分区)的情况下,一个大集群会分裂成不同的小集群,小集群中又各自选举出自己的master节点,导致原先的集群出现多个master节点对外提供服务的情况!
leader选举时,要求节点获取到的投票数量 > 总节点数量/2,有了这个选举原则,当发生网络分区时,无论如何最多只有一个小集群选出leader,避免集群发生脑裂。
第六题目:Redis为什么单线程还很快?

第七题:Spring Cloud 和dubbo区别?
1)服务调用方式
dubbo是RPC
SpringCloud采用Rest Api
2)注册中心
dubbo 是nacos、zookeeper
SpringCloud是eureka,也可以是nacos、zookeeper
3)服务网关
dubbo本身没有实现,只能通过其他第三方技术整合,
SpringCloud有Zuul路由网关,作为路由服务器,进行消费者的请求分发,springcloud支持断路器,与git完美集成配置文件支持版本控制,事物总线实现配置文件的更新与服务自动装配等等一系列的微服务架构要素。
第八题:线程间是怎么通信的,通过调用几个方法来交互的?
线程是通过wait , notify等方法相互作用进行协作通信;
wait()方法使得当前线程必须要等待,直到到另外一个线程调用notify()或者notifyAll()方法唤醒
wait()和notify()方法要求在调用时线程已经获得了对象锁,因此对这两个方法的调用需要在 synchronized修饰的方法或代码块中。
Wait,notify,notifyAll都必须在synchronized修饰的方法或代码块中使用,都属于Object的方法,可以被所有类继承,都是final修饰的方法,不能通过子类重写去改变他们的行为
第十题:SpringMVC工作流程?
1.用户请求旅程的第一站是DispatcherServlet。
2.收到请求后,DispatcherServlet调用HandlerMapping,获取对应的Handler。
3.如果有拦截器一并返回。
4.拿到Handler后,找到HandlerAdapter,通过它来访问Handler,并执行处理器。
5.执行Handler的逻辑。
6.Handler会返回一个ModelAndView对象给DispatcherServlet。
7.将获得到的ModelAndView对象返回给DispatcherServlet。
8.请求ViewResolver解析视图,根据逻辑视图名解析成真正的View。
9.返回View给DispatcherServlet。
10.DispatcherServlet对View进行渲染视图。
11.DispatcherServlet响应用户。
第十一题:阐述设计模式的责任链?
责任链模式定义:
使多个对象都有机会处理请求,从而避免请求的发送 者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一 个对象处理它为止。
责任链模式应用场景:
1) 有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定。
2) 你想在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
3) 可处理一个请求的对象集合应被动态指定。
责任链模式由两个角色组成:
1) 抽象处理者角色(Handler):它定义了一个处理请求的接口。当然对于链子的不同实现,也可以在这个角色中实现后继链。
2) 具体处理者角色(Concrete Handler):实现抽象角色中定义的接口,并处理它所负责的请求。如果不能处理则访问它的后继者。
举例如下:
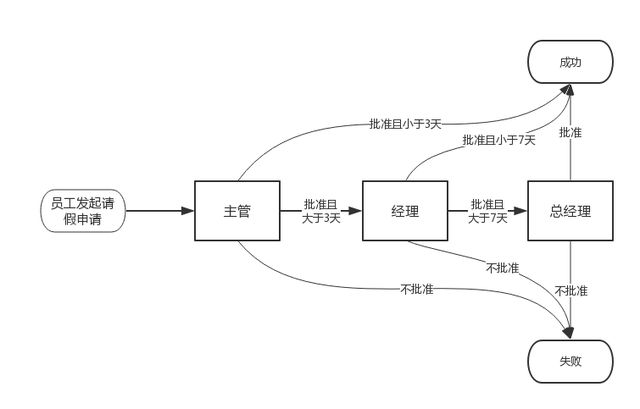

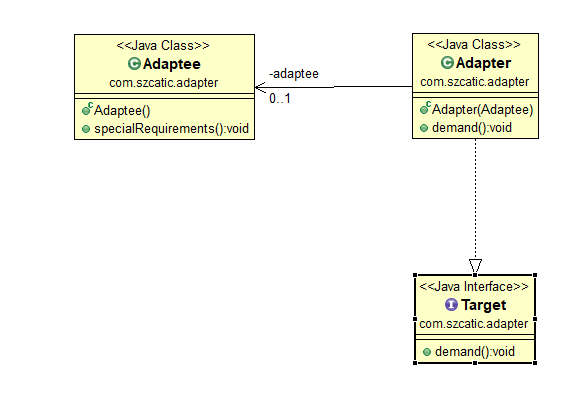
目标角色(Target):客户所期待得到的接口。
源角色(Adaptee):需要适配的类。
适配器角色(Adapter):通过包装一个需要适配的对象,把原接口转换成目标接口。
具体代码:
1.目标角色类
package com.szcatic.adapter;
public interface Target {
void demand();
}
2.源角色类
package com.szcatic.adapter;
public class Adaptee {
public void specialRequirements() {
System.out.println("特殊要求");
}
}
3.适配器角色类
package com.szcatic.adapter;
public class Adapter implements Target {
private Adaptee adaptee;
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void demand() {
adaptee.specialRequirements();
}
}
4.测试类
package com.szcatic.adapter.test;
import org.junit.jupiter.api.Test;
import com.szcatic.adapter.Adaptee;
import com.szcatic.adapter.Adapter;
public class AdapterTest {
@Test
void testDemand() {
new Adapter(new Adaptee()).demand();
}
}
优点:
1、可以让任何两个没有关联的类一起运行。
2、提高了类的复用。
3、增加了类的透明度。
4、灵活性好。
缺点:
1、过多地使用适配器,会让系统非常零乱,不易整体进行把握。