Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning(TubeViT论文翻译)
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
AJ Piergiovanni Weicheng Kuo Anelia Angelova
论文链接
Abstract
我们提出了一个将ViT编码器变成一个有效的视频模型的方法,它可以无缝地处理图像和视频输入。通过对输入进行稀疏采样,该模型能够从图像和视频输入中进行训练和推理。该模型易于扩展,可以适应大规模的预训练的vit,而不需要完全的微调 。该模型在多个数据集上实现了SOTA,并且代码会在将来开源。
1. Introduction
Visual Transformers(ViT)一直是视觉表示学习的一个无处不在的主干,促进了在图像理解,多模态任务和自监督学习等方面的许多进步。然而,对视频的改编既具有挑战性,也受到计算资源的限制。所以视频版本被专门设计成处理更多的帧。例如,ViViT,MultiView,TimeSFormer等。
视频理解是计算机的基本视觉任务,目前已经开发了大量成功的视频架构。先前的 video 3D CNNs 架构通过学习时空信息来处理视频来处理视频数据;他们经常借鉴从图像中学习特征的机制。例如,使用预先训练好的针对于图像数据的CNN的权重,通过将核膨胀至3D的方法使其适用于视频。然而,一旦适用到视频中,这些内核就不再适用于图像。
此外,以前的大多数工作将图像和视频视为完全不同的输入,为视频或图像提供独立的方法,因为设计一个能够同时处理这两者的模型是具有挑战性的。同时,图像和视频输入本质上是相关的,一个单一的视觉主干应该能够处理任何一个或两个输入。以前的共同训练图像和视频的方法调整了架构,以为每个输入设计网络的重要部分。 Perceiver和Flamingo等方法通过重新采样输入,并将其压缩为固定数量的特征来解决这个问题。然而,这种重采样对于长视频来说仍然是昂贵的,并且Flamingo将视频视为以1 FPS采样的单个帧,这可能造成时间信息的缺失。对于依赖于运动和时间理解的数据集(Something-Something或者用来识别快速和简短的动作的数据集)来说,如此低的FPS采样和建模往往是不够的。 另一方面,使用上述一种具有密集帧的方法在计算上是不可行的。

为了解决这些限制,我们提出了一个简单但有效的模型,名为TubeViT。能够无差别的将图片和视频输入到标准的ViT模型中。我们提出了Sparse Video Tubes,这是一种轻量级的联合图像和视频学习的方法。我们的方法是从视频中稀疏地采样各种大小的三维时空tube,以生成可学习的token,然后将token输入到ViT中(Figure 1)。使用Sparse Video Tubes,该模型可以很容易适用于任何一个输入,并且可以更好地利用其中一个或两种数据源来进行训练和微调。Sparse Video Tubes可以自然地处理原始的视频信号和图像信号,这对理解视频中的动作和其他时空信息至关重要。
视频模型的训练成本也很昂贵,以前的工作已经研究了利用已经训练过的模型的方法,比如使用冻结层或使模型适用于视频数据。我们扩展了这些想法,并使用Sparse Video Tubes将更大的ViT模型适用到视频中来进行轻量级的训练。因此,我们用少量的资源创建了强大的大型视频模型。
我们在Kinetics-400, Kinetics-600, Kinetics-700, 和SomethingSomething V2数据集上评估该方法,其性能超过了(SOTA)方法。我们的模型是没有额外预训练或在ImageNet-1k和Kinetics数据集上进行额外预训练训练的,其性能甚至优于从非常大的数据集进行额外预先训练的方法。我们的模型也优于针对视频预训练的模型,如MAE。
我们的关键发现是,通过Sparse Video Tubes,我们能够更好地共享从图像和视频中学习到的权重。这与之前膨胀内核或添加新的特定时间层的模型形成了对比。此外,稀疏抽样使token的数量变低,对于减少计算量和提高性能都很重要。
我们的贡献是构建Sparse Video Tubes,它通过使用不同大小的三维tube对视频进行稀疏采样获得。于是我们实现了(1)一个能够将ViT模型应用到视频的通用视觉框架。(2)能够无缝地使用图像和视频输入进行特征提取。(3)易于扩展的视频理解方法,并且可以利用已经训练过的(大型)ViT模型。
2. Related work
视频理解是计算机视觉中的一个重要课题。早期的工作都是通过手工设计的轨迹特征来了解运动和时间。随着神经网络的不断发展,许多不同的方法已经发展出来,如将图像帧和运动信息的光流作为双流CNN网络的输入。通过对三维CNN进行研究发现时间核的学习是重要的,但这需要大量的数据作为支持。许多现有的视频CNN架构,都是专门用于处理视频的,这些架构并不再适用于图像。
随着transformer模型和自注意的引入,vision transformer在基于图像的任务中展现出了卓越的性能。然而,由于自注意计算中的平方复杂度和密集采样,vision transformer在视频中的使用中需要不同的元素,如时空注意力分解。这些vision transformer并没有真正在较长的视频上进行测试,而且大多是在短片中进行评估。处理大量输入帧和理解长期行动及其关系的能力至关重要,但当前的模型无法承受如此高的复杂度。
之前的研究发现,transformer只关注少数几个tokens,可以通过池化或者重组tokens的方法建立模型。许多针对视频工作都发现帧包含冗余信息,因此提出了对帧进行采样的策略。其他的工作已经研究了减少输入vision transformer 中的token数量的方法。然而,所有这些工作仍然需要对原始的视频进行密集采样,然后使用一些启发式方法来减少输入的数量。在我们的工作中,我们会更稀疏地采样输入,提高效率。
其他最近的工作研究了将视频MAE任务作为预训练,他们同样将视频视为tube,并研究了掩码方面的稀疏性,并且发现掩码方面的稀疏性是有益的。然而,他们使用的tube形状是单一的并且创建的patch是不重叠的。此外他们尚未在图像联合训练时进行研究。
这项工作还与使用来自输入数据的多个视图或流的方法有关,例如MultiView Transformers, SlowFast Networks等,这些方法都发现了多个视图和流对模型是有利的。MultiView Transformers和我们的模型一样都是用的各种不同形状的tube。关键的区别是,我们使用的稀疏采样样本输入到一个单一的ViT编码器模型,而不是多个更小的,每个视图的编码器。这进一步将该方法与图像结合起来。
在视频理解方面的另一项工作是在预训练期间利用图像数据集。这是有价值的,因为对只有图像处理的数据集更好被注释并且提供丰富的语义信息。一种方法是从图像预先训练过的模型中引导视频模型,通常是通过膨胀内核。该模型首先对图像数据进行预训练,然后只在视频上进行训练。其他工作也提出了联合训练图像和视频的方法。这些方法调整了架构,以处理可能效率低下的两种输入,例如,将图像输入视为1帧的视频,或者使用单独的网络首先对输入进行编码。
与之前的工作相比,我们的方法简单而直接。一组关键的区别是,我们将稀疏tube地应用于原始输入,这些tube形状不同、可能重叠,并使用一个单一的、共享的主干网络,不同于以前的所有方法。这就使得模型更有效和更准确。其次,更重要的是,该模型完全在图像和视频模式之间共享。这是一个重要的区别,因为它不仅提高了两个任务的性能,而且更普遍地适用于视觉任务。
3.Method
3.1 Preliminaries
标准的ViT架构将图像转换并转换为patch,例如,使用16×16 卷积内核,16×16步幅的卷积操作。这产生了一系列的patch作为图像的表示,例如,对于一个224×224的输入图像产生了196个patch。给定一个视频 V ∈ R T ∗ H ∗ W V \in \mathbb{R}^{T*H*W} V∈RT∗H∗W,之前的方法要么使用相同的、密集的2维patch(例如TimeSFormer)要么使用密集的三维内核(例如ViViT)。在这两种情况下,这都将导致显著的更多的token,例如,T∗196,其中T是帧数。然后,这些tube或patch被线性地投影到一个嵌入空间中。然后,这个token序列由Transformer编码器处理,使用标准组件,MSA -多头自注意和MLP -标准Transformer映射层(LN表示Layer Norm)。对于一系列的层 l ∈ [ 0 , 1 , . . . L ] l\in [0,1,...L] l∈[0,1,...L],我们计算表示 y i l y_{i}^{l} yil和所有 z i z_{i} zi 每一层token特征 z i l z_{i}^{l} zil

为了降低计算成本,先前的方法对注意机制进行分解,例如空间注意力机制和时间注意机制或使用更小的视图级Transformer的多个视图。
3.2 Sparse Video Tubes
我们提出了一种简单而直接的方法,它可以无缝地适用于图像和视频。我们的方法遵循图像的标准ViT标记化方法:使用核为16x16大小的二维卷积操作。我们建立在稀疏性对视频是有效的观察的基础上。我们没有遵循之前的工作,密集地标记化视频,而是使用相同的时间步幅较大的二维内核,例如,对每16帧应用一次卷积操作。因此,对于32×224×224的输入视频片段,这只产生了了392个token,而不是TimeSFormer中的6k或ViViT中的1-2k。
然而,这种稀疏的空间采样可能会丢失信息,特别是对于快速或简短的动作。因此,我们创建了不同形状的稀疏tube。例如,一个16×4×4的tube,以从低空间分辨率的许多帧中获取信息。这些tube可以有任何形状,我们通过实验探索了它们的影响。重要的是,这些tube也有很大的步幅,在不同的视图中稀疏地采样视频。我们还可以选择向起始位置添加一个偏移量,这样patch就不总是从(0,0,0)开始,这样就可以减少tube之间的重叠。这一点如图2所示。不同尺寸的tube也用于多视图方法的视频分类,但它们被多个Transformer密集采样和处理,从而产生了更大的计算开销。
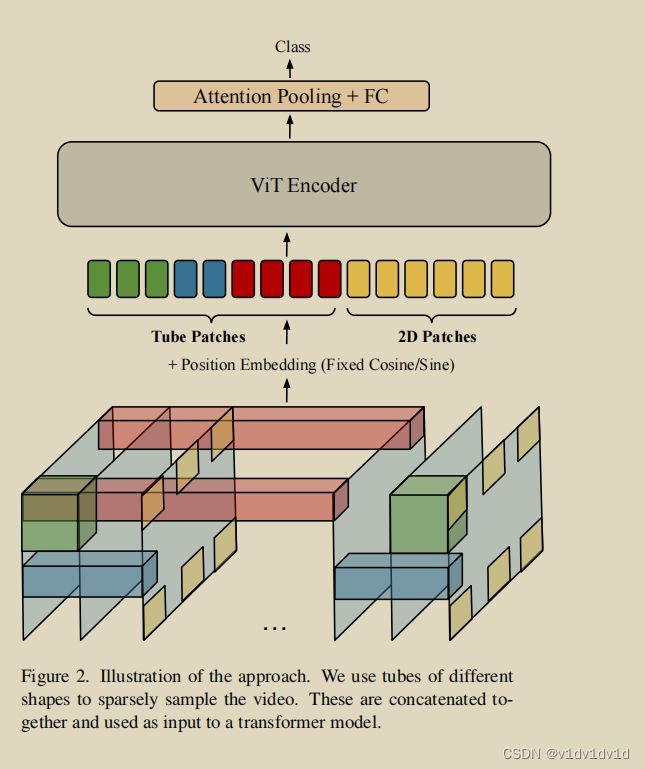
此外,与之前的工作相比,我们也允许tube之间的重叠。具体来说,我们可以将核形状表示为(T×H×W),(Ts、Hs、Ws)表示为核的时空步幅,以及(x、y、z)作为卷积起始点的偏移量。
通过提出的设计,我们的方法使图像和视频视觉信息无缝融合。稀疏空间采样允许共享图像和帧的token,稀疏视频tube创建少量的视频特定token。这使得可以在图像和视频之间更好地共享ViT模型。
3.3 Positional embedding for sparse video tubes
我们的方法的一个关键方面是位置嵌入的实现。在语言模型中,相对位置嵌入是一种常见而有效的方法。然而,在这里,两个token之间的相对位置没有太大的意义,我们不知道真正的参考patch/tube在原始视频或图像中的位置。ViT模型和类似的TimeSFormer和ViViT 对patch使用了可学习的位置嵌入。这种方法可能不适用于我们设计的这种模型,因为这些学习到的嵌入并不一定反映出patch在原始视频中的来源,特别是在patch重叠的情况下。
相反,我们使用一个固定的正弦/余弦嵌入。重要的是,当应用位置嵌入时,我们考虑了每个tube的步幅、核形状和偏移量。这确保了每个patch和tube的位置嵌入具有该tube的全局时空位置。
具体来说,我们计算嵌入如下。这里的 τ \tau τ是一个常量的超参数(我们使用了10,000)。对于j我们从0到d//6取值(d为特征数量),对于t,x,y我们从0到T,H,W取值。其中 Z i ∈ R T ∗ H ∗ W ∗ D Z_{i} \in R^{T*H*W*D} Zi∈RT∗H∗W∗D:

这将每个时空位置嵌入添加到token z i z_{i} zi的特征维度中。根据之前的工作,将对每个通道的不同长度进行此操作。使用d/6,因为我们有6个元素(每个x、y、t的正弦和余弦值),这将为表示的每个通道创建一个位置值。
重要的是,这里的 z i [ t , x , y ] z_{i} [t,x,y] zi[t,x,y]表示tube的中心,考虑到在tube结构中使用的任何步幅和偏移量(通道尺寸在这里没有显示)。
在标记化步骤之后,我们将所有token连接在一起,并输入到标准Transformer结构中。这个简单的结构允许模型在所有输入之间共享大部分的权重,我们发现这是相当有益的。
3.4 Sparse Tube Construction
我们探索了几种创建视觉tube的方法。我们的核心方法包括2种tube:1×16×16×d的tube用于标记图像和一个8×8×8×d的tube另外用于视频。两者的步幅都为16×16×16。这个基本标记器有着强大的性能,但是我们研究了它的几个变体。
Multi-Tube。我们在不同尺寸的核心方法中添加了多个tube。例如,我们可以添加时间长和空间的小的tube,如16×4×4来学习长动作,或者更多空间聚焦的tube,如2×16×16tube。我们通过实验来研究了多种不同形状和步幅的tube。
Space-to-Depth。另一种扩展核心方法的方法是受深度到空间启发的方法。这里,我们减少了tube中的通道数量,例如,减少2倍。因此,tube的形状变成了T×H×W×d/2。接下来,我们沿着通道轴连接2个token。然后我们也可以减少tube的步幅。这就产生了与原始token数量和维度都相同的新token,但在不改变参数数量的情况下有效地增加了内核大小。例如,当时间轴上的步幅减少时,token现在表示T∗2×H×W个位置,但只使用T∗H∗W参数。在实验中,我们研究了不同的设置。时间密度更大 vs 空间密度更大 vs 深度到空间的系数(2,4,8等)。
Interpolated Kernels。对于这个设置,我们不是为每个tube设置一个独一无二的内核,而是从一个8×8×8形状的3D内核开始学习。使用三线性插值将内核重塑到不同的大小,例如,4x16x16或32x4x4,等等。这取决于tube的配置。任何大小的内核都可以从这个单一的内核中创建。这种方法有几个优点。(1)它减少了仅在视频流上使用的学习参数的数量。(2)它可以更灵活地使用内核,例如,它可以在时间维度变大来处理更长的视频,或者在空间维度变大来找到小对象。
TubeViT方法包括上述Multi-Tube和Space-to-Depth思想的结合,确切的设置在补充材料中提供。我们利用Interpolated Kernels来进行消融实验。
3.5 Image and Video Joint Training
如上所述,我们的方法可以无缝地适应图像、视频或两种输入。虽然图像+视频联合输入很少,但在训练的同时同时使用它们的能力非常重要,因为许多具有有价值注释的数据集(如 ImageNet, Kinetics)要么来自图像源要么来自视频源,但不是两者都有。用我们的方法进行联合训练是很容易的——图像由二维内核标记,视频由二维patch(具有较大的时间步幅)和Sparse Tubes标记。然后将其输入到到标准ViT模型中,在任何一种情况下都将提供位置嵌入。为了使联合训练有效,还需要采用位置嵌入的方法。我们在实验第4节中演示了我们的方法对联合训练的好处。
3.6 Image-To-Video Scaling Up of Models
我们还提出了一种更有效的扩展模型的方法(图3)。训练大型ViT模型的计算成本是昂贵的,特别是对于视频。由于我们的模型的几乎所有组件都是在图像和视频之间共享的,所以我们探索了一种方法,可以利用大型模型,而不进行大量的微调。
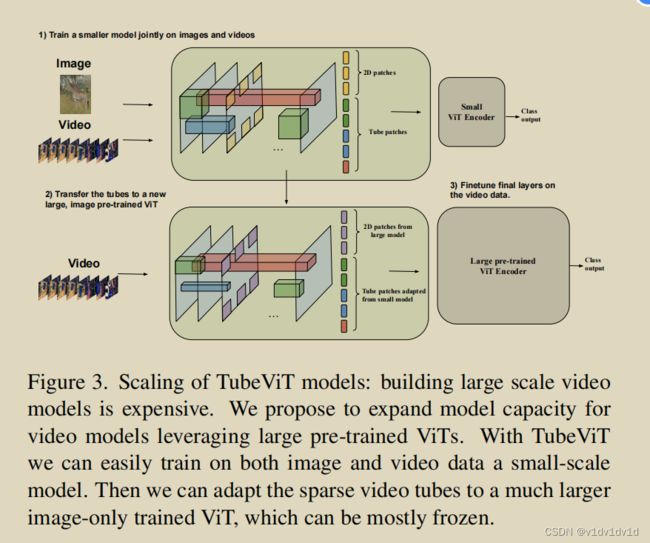
首先,我们在图像和视频上联合训练一个更小的模型。这就给了我们一组tube的权重。然后我们取一个大的,由图像预训练完毕的ViT,进一步添加tube的数量。这些tube使用与较小模型相同的内核权值,因此我们可以避免进一步训练它们。由于较大的ViT通常比较小的ViT使用更多的信道维度,因此我们在这里再次使用 space-to-depth 转换来创建具有适当信道维度的token,而不需要新的权重。
接下来,我们在网络中选择一个点,并冻结它之前的所有层,例如,ViT-H中32层中的第26层。在这一点上,我们向网络添加一个门控连接:

其中,s是网络冻结在ViT模型(例如,26)的层, z 0 z^{0} z0是来自tube的原始输入token,α是学习到的门控参数,初始化为0。在训练的第一步中,这个门对表示没有影响,因此ViT是没有变化的。然而,它可以经过学习在这一点上合并原始tube,并进一步优化后来的权重。
4.Experiments
我们在几个流行的数据集上评估了这种方法:Kinetics 400, Kinetics 600, Kinetics 700,SomethingSomething V2。这些数据集涵盖了各种各样的视频理解难题,并在文献中建立起来。主要结果在ImageNet-1k(120万张图像)和视频数据上联合训练得出来的,详见补充资料。我们使用标准的Top 1和Top 5的评估指标,并在罗列出了我们模型以及前面提到的其他的模型的参数量。我们的模型尺寸是:参数量为90M的基础版(B),参数量为311M的大版(L)。参数量为635M的巨大版(H)是通过 Image-to-Video 的缩放来“创建”的。
4.1 Main results
对于主要的结果,我们使用了4个tube,分别是如下配置(顺序为t,h,w):(1) 8×8×8步幅为(16、32、32);(2) 16×4×4步幅为6×32×32,偏移量为(4、8、8);(3) 4×12×12步幅为(16、32、32),偏移量为(0、16、16);(4)1×16×16步幅为(32、16、16)。对于32×224×224大小的输入数据,这一经过处理只会产生559个token,明显少于其他方法。在补充材料中,我们对许多tube的结构进行了详细的实验。我们想弄清楚的是,随着数据的增强,如随机空间和时间裁剪,在多个训练时期,模型将看到视频的不同部分,即使进行了稀疏采样。
于SOTA进行比较。首先,我们将我们的最终方法与以前的最优秀的(SOTA)方法进行了比较。表1、2和3显示了我们的模型与最先进的模型在 Kinetics-400 Kinetics-600和Kinetics-700数据集上的性能。这些结果表明,我们的方法在准确性和效率方面都优于SOTA。我们在图像和视频的协同训练方面也优于其他方法,以及具有强视频预训练的方法。



我们注意到,我们构造的各种规模的模型都表现良好,尽管其他模型更大或使用更大的预训练(例如,CoCa有1B参数和1.8B的预训练数据,MerlotSereke有644M参数并使用YT-1B数据集)。表4显示了我们的模型在数据集(SSv2)上的结果。这个数据集通常用于评估更动态的活动。

联合图像+视频训练。我们进一步探讨了在图像+视频数据集上进行协同训练的效果。发现这是非常有效的,如表5所示。表5在一个仅使用Kinetics(视频)与使用Kinetics和ImageNet数据集进行预训练的并排实验中评估了这一点。我们看到,使用我们的方法进行共同训练可以提升性能。我们看到,两阶段训练,即首先在一个数据集上训练,然后在第二个数据集上训练,也比联合训练弱,因为两个数据集在训练过程中不能交互。我们还与之前的方法进行了比较,如只使用密集的2Dpatch的TimeSFormer,或使用inflated的3D内核(如ViViT [3])架构。在这两种情况下,我们都看到了提出的的联合训练方法的明显好处。我们还注意到,由于通过密集采样获得了大量token,这些先前的方法有明显更多的计算量。我们观察到图像和视频的共同训练是有益的,这与之前的工作一致;这里的不同之处在于,我们有一个单一的紧凑的模型来做到这一点。

作为完整性检查,我们还比较了我们的模型在ImageNet-1k上的性能(没有任何超参数调整或添加):我们只在ImageNet上训练的ViT-B模型具有78.1的精度。当使用Kinetics-600进行联合训练时,该模型得到正确率为81.4,提高了3.4个百分点,这也显示了仅针对图像任务的联合训练的好处。这也显示了仅针对图像任务的联合训练的好处。虽然其他模型在ImageNet上获得了更高的性能,但它们经常使用专门的数据增强、学习策略和其他我们没有使用的技巧。相反,我们纯粹是在研究同时使用视频和图像的好处。
使用sparse video tubes进行缩放视频训练。在表6中,我们演示了如何利用一个小的TubeViT模型调整成只在图像上利用一个大的和(通常是独立的)仅对图像的预训练模型。我们首先利用一个大型的,经过图像预训练的ViT,这里是ViT-H。然后,我们从TubeViT-B中获取学习到的tube,并将它们与ViT-H图像标记器一起从视频中生成一组标记。然后将这些数据作为ViT-H的输入,我们只对模型的后一部分进行调整。这些结果表明,这是一种有效的扩展和利用大型ViT模型的方法,而不需要较高的计算成本来完全微调模型。我们也看到了公式8中的门口单元是有效的。我们还发现,在这种情况下,训练时间减少了43%,因为模型没有太多可以更新的参数了。

过多token的不利影响。接下来,我们研究了模型中使用的token数量的影响,如图4所示。这个结果是关于为什么我们的方法如此有效的另一个关键见解:由于有太多的token,模型性能会下降,特别是当只使用Kinetics数据时。出现这种情况的原因可能有很多,例如,自我注意机制可能难以学习较长的序列,或者可能没有足够的数据来学习较长的序列,或者可能模型与较长的序列过拟合。这一结果表明,对于当前的数据集,稀疏采样是一种有效的视频处理方法。此外,有可能存在的使用长,密集采样序列受到影响,这可能是需要分解注意模块的另一个原因。

4.2 Ablations
在本节中,我们将介绍一些消融实验来确定为什么这种方法是有效的。实验使用数据集为Kinetics 600。
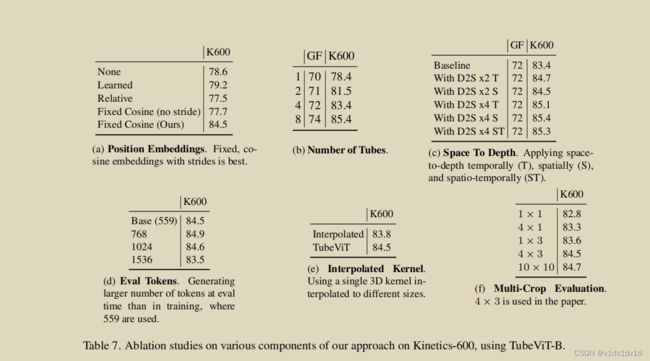
Main ablations。首先,我们研究了位置偏差的选择对性能的影响(表7a)。我们发现,添加固定余弦位置嵌入比其他嵌入效果更好。直观地说,这是有意义的,因为我们是稀疏地采样可能重叠的token,这种方法能够最好地捕获token位置。
接下来,在表7b中,我们研究了所使用的tube的数量。我们发现这与之前的多视图观察一致,即有多种tube有助于视频理解。
接下来,在表7c中,我们研究了网络的 depth-to-space 版本。在这里,我们减少了从D/S中生成的token的通道,例如,减少了2倍或4倍。然后在生成新的token之后,我们沿着通道轴将它们连接起来。我们研究了在空间和时间维度上增加标记的数量对模型性能的影响。我们发现这是一种有效的方法,因为它可以使更密集的样本,而不增加参数或token的数量。
表7d比较了比模型训练的更多patch的效果。为了做到这一点,我们减少了内核的步幅。最初,这改善了结果,但在增加了2倍后,性能开始下降,可能是因为评估数据与训练数据的差异太大。
在表7e中,我们研究了插值单核的效果。也就是说,我们是构建一个 8×8×8 3D内核,并使用插值来生成不同形状的tube。有些令人惊讶的是,我们发现这工作得相当好,同时也减少了网络中可学习参数的数量。
在表7f中,我们比较了不同时间和空间切片数量的影响。我们发现,即使是单一切片也能提供很强的性能,标准的4×3的性能几乎与10×10性能的相同,这表明稀疏样本是相当合适的。
Factorized attention ablations。在表8中,我们进一步研究了在ImageNet预训练的ViT模型中添加一个新的注意层的效果。在这里,我们使用tube方法来标记输入,但不是使用一个分解的注意模块,我们只是简单地添加了一个额外的自注意层。这与因式分解的注意方法有类似的效果,即将新的,未初始化的K,Q,V投影添加到预先训练的ViT(例如,TimeSFormer和ViViT)。这些结果表明,由于这些新的层,这些方法不能最好地利用图像预训练的网络权值。由于稀疏tube产生很少的额外token,它们可以直接使用相同的ViT模型而不需要分解注意力,从而能够更好地利用图像训练的权重。请注意,这些结果之间仍然有差异,例如token减少的数量。然而,我们认为这一观察结果是成立的,并且这可能解释了为什么ViVit中的时空注意在某些数据集上表现得更好。

Model scaling ablations。表9提供了从一个Tiny级别的模型扩展到一个Base级别的TubeViT模型的消融实验结果。即使仅仅训练最后的几层也是有效的,并且几乎可以匹配完全微调的性能。这与我们在表6中对ViT-H的观察结果一致。

图5对经过学习的3D tube和2D patch进行可视化。

5.Conclusion
我们提出了用于视频识别的sparse video tubes。利用sparse video tubes,一个ViT编码器可以转换为一个高效的的视频模型。该方法简单,可以与图像和视频进行无缝联合训练,并提高了跨多个数据集的视频识别。我们演示了我们提出的视频模型的简单缩放。我们进行了广泛的消融实验,以确定为什么该方法有效,发现联合训练、减少token数量和更好地利用共享图像+视频权重的组合为我们的方法有效的关键因素。我们得到了SOTA或以上的性能。
A.Implementation Details
我们的超参数总结在表10中。对于所有的数据集,我们采用了随机的空间和时间采样。对于大多数数据集,这些设置都是相同的。对于Charades数据集,我们减少了批处理的大小,但使用了更长的128帧进行剪辑,因为Charades数据集视频大约有30秒长,而Kinetics数据集视频只有10秒长。
当使用更大的ViT模型时,我们也发现了一些训练的不稳定性。当使用ViT-L或ViT-H模型时,我们必须降低weight decay值和学习率,否则我们发现训练精度下降到0,损失保持不变。
对于一些较小型的数据集,例如Charades 和 SSv2,我们必须增加数据增强的设置。
对于所有的数据集,我们应用了RandAugment,因为我们发现这是有益的。我们还保持了所有数据集的训练轮数不变。
ImageNet和Kinetics联合训练。当在两个(或多个)数据集上进行联合训练时,我们使用一个单独的全连接层来输出预测。例如,对于ImageNet和Kinetics-600,我们使用了一个具有1000和600个输出的FC层。然后,我们计算相关的头的损失,并反向传播它。在联合训练期间,我们使用了与表10中列出的相同的设置。我们使用了Kinetics-400、Kinetics-600和Kinetics-700的联合训练。对于Charades和SSv2,我们使用Kinetics-600+ImageNet预训练模型,并在数据集上进行微调。

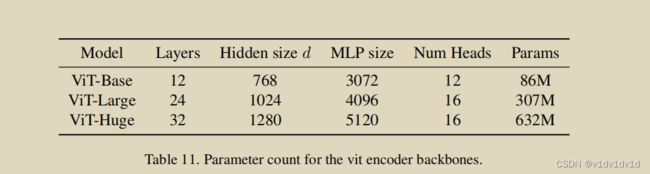
全部的模型设置。我们的模型是基于标准的ViT模型,因此该方法的核心与之前的ViTs相同。我们在表11中总结了这些设置。在表12中,我们详细介绍了每个tube的设置。

B. Additional Experiments on Charades
我们包括在 Charades数据集上训练的结果,以显示这种方法在较长的视频上的有效性,因为Charades视频平均有30秒长。然而,Charades数据集也是一个多标签的数据集,我们发现它需要不同的设置来有效地训练,所以我们在这里包含了所有这些细节。
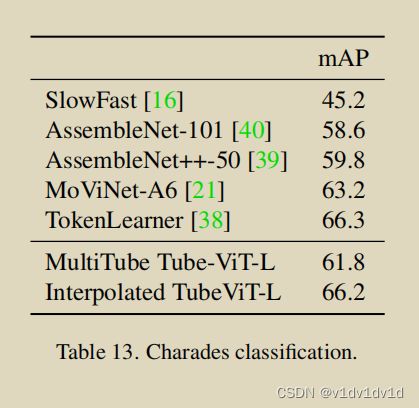
首先,我们发现core multi-tube方法表现不如之前的一些方法。由于Charades数据集有很多与对象相关的动作,并且包含更长的视频和更多的时间信息,所以我们修改了核心模型,使其更适合这些数据。首先,我们使用了插值的方法来增加tube的形状到:1 × 16 × 16,16 × 16 × 16,32 × 8 × 8,4 × 32 × 32。
我们注意到两个重要的因素。首先,由于我们使用插值来创建更大的内核,因此学习到的参数的数量是相同的,并且为其他数据集从相同的内核进行初始化。其次,由于步幅数保持不变,所以这个结果是相同数量的token。重要的是,这种变化对网络及其参数的影响很小,但使模型能够更好地捕捉Charades数据集信息。
在表13中,我们报告了结果。core MultiTube表现得相当好,但是通过插值内核,能够与最先进的 TokenLearner性能相当,同时仍然稀疏地采样视频。我们也使用明显更少的数据进行类似的操作,例如,用JFT-300M对TokenLearner进行预训练的效果和我们在没有如此大规模数据的情况下完成相同的性能。
C.Ablations on Tube Shapes.
在表14中,我们提供了对各种tube形状结构在Kinetics-600数据集上对性能影响的详细研究。我们观察到,该模型对tube的形状不是过度敏感,至少Kinetics-600上是如此,但有多个,不同的tube,以及其形状的变化通常是有益的。在这些实验中,我们使用了以下的tube:
(a) 1 × 16 × 16
(b) 4 × 32 × 32
© 4 × 4 × 4
(d) 4 × 12 × 12
(e) 8 × 8 × 8
(f) 16 × 4 × 4
(g) 16 × 16 × 16
(h) 32 × 8 × 8
下面是tube的步幅:
(i) (4, 16, 16)
(ii) (8, 8, 8)
(iii) (8, 32, 32)
(iv) (16, 16, 16)
(v) (32, 32, 32)
