论文阅读《Iterative Geometry Encoding Volume for Stereo Matching》
论文地址:https://arxiv.org/pdf/2303.06615.pdf
源码地址:https://github.com/gangweiX/IGEV
概述
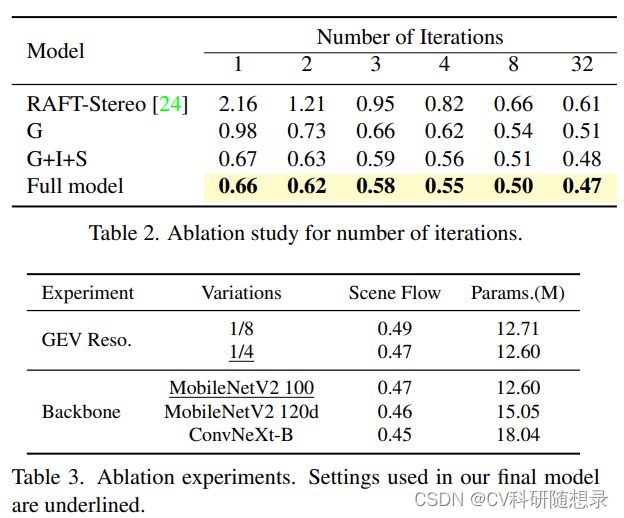
该文章针对立体匹配中 All-pair correlations 缺乏非局部几何知识,难以处理病态区域中的局部歧义性的问题,提出 Iterative Geometry Encoding Volume(IGCV-Stereo) 用于立体匹配。该模型构建了一个 Combined Geometry Encoding Volume 来学习几何信息与上下文信息,并通过迭代优化的策略来更新视差图。
模型架构
Feature Extractor
Feature Network
给定左右图像 I l ( r ) ∈ R 3 × H × W \mathbf{I_{l(r)}}\in \mathbb{R}^{3\times H\times W} Il(r)∈R3×H×W,使用在ImageNet上预训练得到的 MobileNetV2 来提取尺寸为原图大小 1 32 \frac{1}{32} 321 的特征图,然后使用带有残差连接的上采样模块来得到不同尺度的特征图: f l , i , f r , i ∈ R C i × H i × W i , ( i = 4 , 8 , 16 , 32 ) \mathbf{f}_{l,i}, \mathbf{f}_{r,i}\in \mathbb{R}^{C_i\times \frac{H}{i}\times \frac{W}{i}},(i=4, 8, 16, 32) fl,i,fr,i∈RCi×iH×iW,(i=4,8,16,32) , C i C_i Ci 为特征通道数。 f l , 4 \mathbf{f}_{l, 4} fl,4 与 f r , 4 \mathbf{f}_{r, 4} fr,4 用来构建代价体,且 f l , i , ( i = 4 , 8 , 16 , 32 ) \mathbf{f}_{l, i}, (i=4, 8, 16, 32) fl,i,(i=4,8,16,32) 用来引导代价体正则化。
Context Network
参考RAFT,上下文网络由一系列残差块和下采样层组成。它能够生成分辨率分别为输入图像的 1/4、1/8 和 1/16,通道数为 128 的多尺度的上下文特征。这些多尺度的上下文特征用于初始化基于 ConvGRU 的更新算子的隐藏状态,并在每次迭代中插入到 ConvGRUs 中。
Combined Geometry Encoding Volume
参考GwcNet,给定 f l , 4 \mathbf{f}_{l, 4} fl,4 与 f r , 4 \mathbf{f}_{r, 4} fr,4, 沿着特征维度将特征图分为8组用于构建组相关代价体:
C c o r r ( g , d , x , y ) = 1 N c / N g ⟨ f l , 4 g ( x , y ) , f r , 4 g ( x − d , y ) ⟩ (1) \mathbf{C}_{c o r r}(g, d, x, y)=\frac{1}{N_{c} / N_{g}}\left\langle\mathbf{f}_{l, 4}^{g}(x, y), \mathbf{f}_{r, 4}^{g}(x-d, y)\right\rangle\tag{1} Ccorr(g,d,x,y)=Nc/Ng1⟨fl,4g(x,y),fr,4g(x−d,y)⟩(1)
考虑到仅基于特征相关性的代价体 C c o r r C_{corr} Ccorr 缺乏捕获全局几何结构的能力。为了解决该问题,使用轻量级的 3D 正则化网络 R R R 对 C c o r r C_{corr} Ccorr 进行正则化,以获得几何编码代价体(geometry encoding volume) C G C_G CG:
C G = R ( C c o r r ) (2) C_G = \mathbf{R}(C_{corr})\tag{2} CG=R(Ccorr)(2)
3D 正则化网络 R \mathbf{R} R 为轻量级的 3D UNet,其中由 3 个下采样块和 3 个上采样块组成。每个下采样块由两个 3 × 3 × 3 3×3×3 3×3×3 的 3D 卷积组成。3个下采样块的通道数分别为 16、32、48。每个上采样块由一个 4 × 4 × 4 4×4×4 4×4×4 的 3D 转置卷积和两个 3 × 3 × 3 3×3×3 3×3×3 的 3D 卷积组成。此外,还参考 CoEx 的方法,使用左视图的特征图来生成引导权重来对代价体的通道进行加权:
C i ′ = σ ( f l , i ) ⊙ C i (3) \mathbf{C}_{i}^{\prime}=\sigma\left(\mathbf{f}_{l, i}\right) \odot \mathbf{C}_{i}\tag{3} Ci′=σ(fl,i)⊙Ci(3)
其中 σ \sigma σ 是 sigmoid 函数, ⊙ \odot ⊙ 表示哈达玛积。使得模型能够有效地推断和传播场景几何信息,从而形成几何编码体积。此外,还计算相应的左右特征之间的 all-pairs correlations(APC) 来捕获局部特征信息。为了增加模型的感受野,使用 kernel size = 2,stride = 2 的平均池化层沿着视差维度进行池化,构建两级 C G C_G CG 金字塔和all-pairs correlation C A C_A CA 金字塔。继而将 C G C_G CG 金字塔和 C A C_A CA 金字塔结合起来形成一个组合几何编码体积(combined geometry encoding volume)。
ConvGRU-based Update Operator
使用 soft argmin 函数来将 C G C_G CG 回归处初始视差图:
d 0 = ∑ d = 0 D − 1 d × Softmax ( C G ( d ) ) (4) \mathbf{d}_{0}=\sum_{d=0}^{D-1} d \times \operatorname{Softmax}\left(\mathbf{C}_{G}(d)\right)\tag{4} d0=d=0∑D−1d×Softmax(CG(d))(4)
其中 d 0 \mathbf{d}_{0} d0 为原图尺寸的 1/4,然后将其作为初始视差图,使用多尺度的上下文特征(Context features)来初始化3级GRU的隐藏层,继而使用 ConvGRUs 模块来对视差图迭代优化。
每次迭代过程中,使用当前的视差图 d k d_k dk 来对几何编码体积中的代价体进行索引(线性插值)得到 G f G_f Gf :
G f = ∑ i = − r r Concat { C G ( d k + i ) , C A ( d k + i ) , C G p ( d k / 2 + i ) , C A p ( d k / 2 + i ) } , (5) \mathbf{G}_{f}=\sum_{i=-r}^{r} \text { Concat }\left\{\mathbf{C}_{G}\left(\mathbf{d}_{k}+i\right), \mathbf{C}_{A}\left(\mathbf{d}_{k}+i\right),\right. \left.\mathbf{C}_{G}^{p}\left(\mathbf{d}_{k} / 2+i\right), \mathbf{C}_{A}^{p}\left(\mathbf{d}_{k} / 2+i\right)\right\},\tag{5} Gf=i=−r∑r Concat {CG(dk+i),CA(dk+i),CGp(dk/2+i),CAp(dk/2+i)},(5)
其中 d k d_k dk 为当前视差图, r r r 为索引半径, p p p 为池化操作。将 G f G_f Gf 与 d k d_k dk 进行编码后与 d k d_k dk 进行拼接,得到一个新的特征 x k x_k xk,然后使用 ConvGRUs来更新隐藏层 h k − 1 h_{k-1} hk−1:
x k = [ Encoder g ( G f ) , Encoder d ( d k ) , d k ] z k = σ ( Conv ( [ h k − 1 , x k ] , W z ) + c k ) r k = σ ( Conv ( [ h k − 1 , x k ] , W r ) + c r ) h ~ k = tanh ( Conv ( [ r k ⊙ h k − 1 , x k ] , W h ) + c h ) , h k = ( 1 − z k ) ⊙ h k − 1 + z k ⊙ h ~ k (6) \begin{aligned} x_{k} & =\left[\operatorname{Encoder}_{g}\left(\mathbf{G}_{f}\right), \text { Encoder }_{d}\left(\mathbf{d}_{k}\right), \mathbf{d}_{k}\right] \\ z_{k} & =\sigma\left(\operatorname{Conv}\left(\left[h_{k-1}, x_{k}\right], W_{z}\right)+c_{k}\right) \\ r_{k} & =\sigma\left(\operatorname{Conv}\left(\left[h_{k-1}, x_{k}\right], W_{r}\right)+c_{r}\right) \\ \tilde{h}_{k} & =\tanh \left(\operatorname{Conv}\left(\left[r_{k} \odot h_{k-1}, x_{k}\right], W_{h}\right)+c_{h}\right), \\ h_{k} & =\left(1-z_{k}\right) \odot h_{k-1}+z_{k} \odot \tilde{h}_{k} \end{aligned}\tag{6} xkzkrkh~khk=[Encoderg(Gf), Encoder d(dk),dk]=σ(Conv([hk−1,xk],Wz)+ck)=σ(Conv([hk−1,xk],Wr)+cr)=tanh(Conv([rk⊙hk−1,xk],Wh)+ch),=(1−zk)⊙hk−1+zk⊙h~k(6)
c k c_k ck, c r c_r cr和 c h c_h ch 是从context network 生成的上下文特征。ConvGRUs的隐藏状态中的通道数为128,context feature 的通道数也为128。 Encoder g \operatorname{Encoder}_g Encoderg 和 Encoder d \operatorname{Encoder}_d Encoderd 分别由两个卷积层组成。基于隐藏状态 h k h_k hk,通过两个卷积层来预测残差视差 △ d k △d_k △dk用于更新当前视差: d k + 1 = d k + Δ d k (7) \mathbf{d}_{k+1}=\mathbf{d}_{k}+\Delta \mathbf{d}_{k}\tag{7} dk+1=dk+Δdk(7)
Spatial Upsampling
通过对预测的1/4分辨率视差 d k d_k dk 进行加权组合来输出全分辨率视差图,使用更高分辨率的上下文特征来获得权重。然后对隐藏状态进行卷积以生成特征,将其上采样到1/2分辨率后将上采样的特征与左图像的 f l , 2 f_{l,2} fl,2 拼接后以产生权重 W ∈ R H × W × 9 W∈\mathbb{R}^{H×W×9} W∈RH×W×9。通过对其粗分辨率邻域的加权组合来输出全分辨率视差图。
损失函数
L init = Smooth L 1 ( d 0 − d g t ) L stereo = L init + ∑ i = 1 N γ N − i ∥ d i − d g t ∥ 1 (8) \begin{array}{l} \mathcal{L}_{\text {init }}=\text { Smooth }_{L_{1}}\left(\mathbf{d}_{0}-\mathbf{d}_{g t}\right)\\ \mathcal{L}_{\text {stereo }}=\mathcal{L}_{\text {init }}+\sum_{i=1}^{N} \gamma^{N-i}\left\|\mathbf{d}_{i}-\mathbf{d}_{g t}\right\|_{1} \end{array}\tag{8} Linit = Smooth L1(d0−dgt)Lstereo =Linit +∑i=1NγN−i∥di−dgt∥1(8)
其中 γ = 0.9 \gamma=0.9 γ=0.9
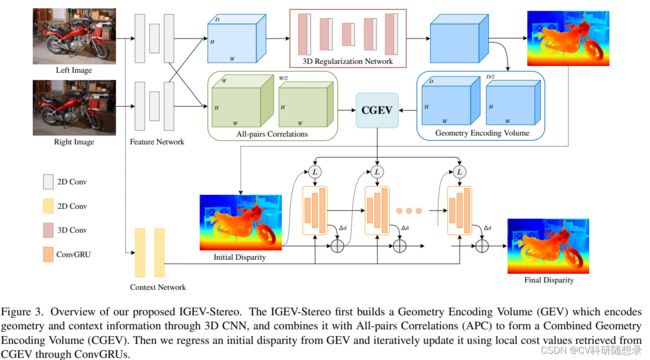
实验结果