deepstream框架下多路源模型部署参考步骤
目录
1.dynamic onnx的生成
2.tensorRT engine模型的生成
3.配置文件的参数指定
在deepstream框架下,想测试SCRFD模型的多路分布式运行,当修改配置文件中相应的batch参数后,运行报错如下
0:00:08.390136614 8575 0xaaab0daf9c70 WARN nvinfer gstnvinfer.cpp:643:gst_nvinfer_logger: NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::checkBackendParams() [UID = 1]: Backend has maxBatchSize 1 whereas 2 has been requested
0:00:08.390549772 8575 0xaaab0daf9c70 WARN nvinfer gstnvinfer.cpp:643:gst_nvinfer_logger: NvDsInferContext[UID 1]: Warning from NvDsInferContextImpl::generateBackendContext() [UID = 1]: deserialized backend context :/home/leedarson/workspace/models/scrfd_500m_bnkps_shape640x640.engine failed to match config params, trying rebuild
0:00:08.396210854 8575 0xaaab0daf9c70 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger: NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() [UID = 1]: Trying to create engine from model files
ERROR: failed to build network since there is no model file matched.
ERROR: failed to build network.
0:00:10.735614046 8575 0xaaab0daf9c70 ERROR nvinfer gstnvinfer.cpp:640:gst_nvinfer_logger: NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::buildModel() [UID = 1]: build engine file failed

查看报错信息,大概是SCRFD模型engine的maxBatchSize=1,而使用时却给的参数值为2,所以engine的创建失败。查看deepstream中给出的多路视频运行的配置文件示例,尽管模型实现的功能相同,但是不同的batch使用的模型却不同,这才想起onnx可以分为模型有静态和动态两种,所谓静态onnx模型的输入和输出都是指定好的,转模型的时候不能随意更改,所以如果batchsize一旦给定就不能更改,我一开始生成的SCRFD模型就是静态的,给定batchsize=1,尝试batchsize>1时运行就会报错;而动态onnx模型,可以支持动态给定输入和输出,在转其他模型或者执行的时候指定相应的参数即可。因此如果需要在deepstream框架上进行多路分布式部署运行模型,大概需要三步:1.生成dynamic onnx;2.将dynamic onnx在模型的运行平台上转tensorRT engine;3.在配置文件中给定相应的参数。
1.dynamic onnx的生成
insightface中提供的有SCRFD模型转onnx的Python文件,刚开始按照提示,指定的命令行参数如下运行生成onnx
|
|
可以在Netron看到生成的onnx模型输入输入结构如下

有太多的参数未指定,在转相应的tensorRT engine时就遇到了如下的报错
|
|
根据trtexec的报错信息,可以理解大概是onnx的输入参数问题。回到insightface的scrfd2onnx.py文件中,查看其对于动态维度的指定代码如下
|
|
将其更改为如下后
|
|
执行如下命令,生成相应的dynamic onnx模型。
|
|
生成的dynamic onnx模型输入输出参数如下图。
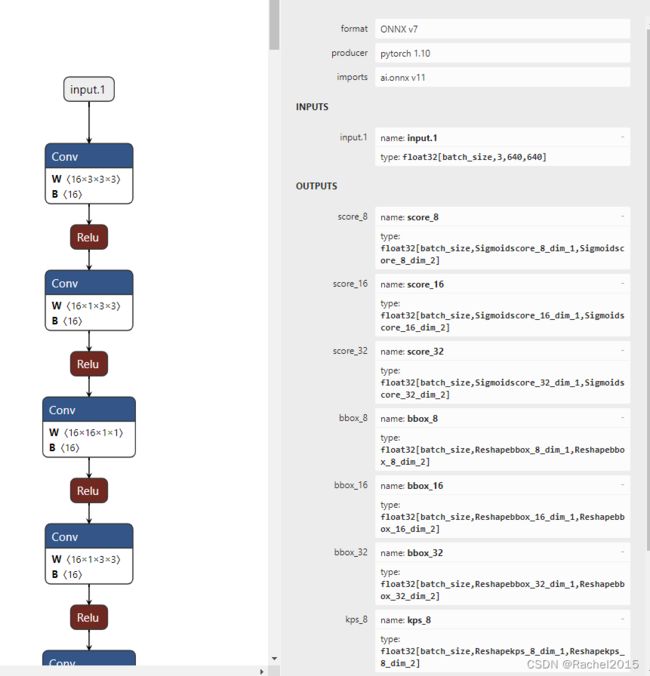
2.tensorRT engine模型的生成
deepstream框架下模型的推理运行使用的是tensorRT组件,所以如果要在deepstream框架上运行模型,需要将待运行的模型在将要运行的硬件平台上转为tensorRT能进行推理的engine文件。对于已经生成的dynamic onnx模型文件,执行如下命令进行engine模型文件的生成。
|
|
参考相应的static onnx转engine命令如下。
|
|
可以看到对于dynamic onnx需要指定minShapes、optShapes和maxShapes,通常情况下optShapes和maxShapes可以给成相同的值。
注:生成tensorRT engine文件的硬件平台必须和模型推理部署的硬件平台保持一致,即转模型和推理部署都必须要在同一个硬件设备上执行,否则会导致推理部署失败。
3.配置文件的参数指定
在生成tensorRT engine文件时,已指定maxShapes=input.1:8x3x640x640,因此该engine最多可以指定8路同时运行,配置文件中batchsize<=8都可以,注意保持[source0]、[streammux]、[primary-gie]、[tiled-display]等组件的batchsize相同即可。模型SCRFD的参考配置参数如下。
config_face.txt
|
|
config_detection.txt内容如下。
|
|
执行如下命令
|
|
对比deepstream推理SCRFD时解析的网络参数如下。
dynamic engine推理时解析的网络层参数

static engine推理时解析的网络层参数

运行结果如下
8路640x480大小的视频同时在NVIDIA NX平台上运行,帧率大概16fps;
4路640x480大小的视频同时在NVIDIA NX平台上运行,帧率大概30fps。