MySQL备份问题排查和思考
本文为辽宁振兴银行DBA团队投稿。
作者:roidba、流转的时光。
1. 背景
2. 疑点
3. 问题分析
4. 问题定位
5. checking permissions的疑惑
6. 探索优化思路
7. 补充:关于几个timeout参数生效点
1. 背景
行内数据库备份在使用某备份软件,使用的数据库版本MySQL 8.0社区版,全备使用mysqldump进行,DBA早上巡检发现有一套数据库全备份失败,心里一疙瘩怎么回事呢?来看看如下报错
[mysqldump: Error: 'Lost connection to MySQL server during query' when trying to dump tablespaces mysqldump: couldn't execute 'SHOW VARIABLES LIKE 'ndbinfo'\_version' MySQL server has gone away (2006)]肯定有同学有疑问?
为什么mysqldump会出现丢失连接?
为什么不使用xtrabackup呢?这需要另外章节来阐述了。
2. 疑点
为什么mysqldump会出现丢失连接?带着该问题进行以下分析:
1.检查备份软件工具负载情况
2.检查数据库中错误日志
3.数据库的负载情况
3. 问题分析
3.1 备份软件是否存在高负载、排队或超时配置导致响应超时?
对整个备份系统进行排查,虽然备份系统任务多,但并没有出现性能瓶颈导致数据库备份时超时,备份软件也没有设置备份超时时间自动断开的相关配置
3.2 检查数据库错误日志
2020-10-26T01:31:14.465387+08:00 149718 [Note] [MY-010914] [Server] Aborted connection 149718 to db: 'unconnected' user: 'root' host: 'localhost' (Got an error reading communication packets).通过数据库错误日志发现同备份软件报错一样,对于这个错误,MOS上有一个比较好的解释如下:

不管怎么样我们后面先来看备份软件触发了些什么语句。
3.3 检查数据库负载情况,备份期间cpu、io均比较正常


4. 问题定位
从上述检查来看,报错处是Got an error reading而不是timeout,关于timeout的触发方式我们最后总结。首先从备份软件架构,备份软件在数据库中部署agent,所以连接属于交互式连接受到参数interactive_timeout的影响,那么为什么导致的超时丢失连接的呢?我们可以进行问题复现,使用备份软件对数据库发起重新备份,对数据库进行监控
4.1 通过备份软件发起备份,可以看到会发起4个本地备份连接,3个处于sleep状态,一个线程处于执行状态下,如下:

SQL语句:
SELECT LOGFILE_GROUP_NAME, FILE_NAME, TOTAL_EXTENTS, INITIAL_SIZE, ENGINE, EXTRA FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = 'UNDO LOG' AND FILE_NAME IS NOT NULL AND LOGFILE_GROUP_NAME IS NOT NULL AND LOGFILE_GROUP_NAME IN (SELECT DISTINCT LOGFILE_GROUP_NAME FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = 'DATAFILE' AND TABLESPACE_NAME IN (SELECT DISTINCT TABLESPACE_NAME FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_SCHEMA IN ('xxx'))) GROUP BY LOGFILE_GROUP_NAME, FILE_NAME, ENGINE, TOTAL_EXTENTS, INITIAL_SIZE ORDER BY LOGFILE_GROUP_NAME;注意这里的状态为checking permissions,并且这个语句长期处于这个状态。我们以前理解的这个就是在鉴权,我们一般的认知是下面一些顺序:
starting:lex+yacc 语法语义解析,得到解析树
checking permissions:根据解析后的解析树,对需要访问的表进行鉴权
opening tables:打开访问的表,建立内部访问表的属性(表和字段信息),建立好和Innodb的关联,同时加上表锁(MDL LOCK)
optimizing/statistics/preparing:这3个状态处于语句的物理和逻辑优化阶段,之后建立好执行计划
Sending data( 8.0为executing):select语句MySQL层和Innodb层进行数据交互,遇到这个状态通常考虑语句是否足够优化
Update:同上insert语句,如果遇到行锁会处于这个状态下。
Updating:同上delete/update语句,如果遇到行锁会处于这个状态下。
query end(waiting for handler commit 8.0):语句的提交过程包含在这个状态下,遇到这个问题,主要考虑是否大事务的存在。
closing tables:和opening tables对应,释放表的内部访问版本放入缓存共下次使用,同时也包含语句的错误回滚也在这个状态下
freeing items:释放解析树
我们能够看到,鉴权实际上在比较靠前的位置,是不是说这里语句还没真正的开始执行呢?我们先放一放。
4.2 通过执行show processlist发现上述SQL一直处于运行状态,于是终止备份,手工运行该SQL
由此可以推测发现,备份软件在发起备份时会发起4个连接,而其中一个连接执行SQL比较久,而另外3个sleep连接在超过interactive_timeout后断开,导致agent整体退出关闭所有的数据库连接,执行的SQL也终止,所以报错Got an error reading。但是奇怪的是我们在日志并没有找到Got timeout reading communication packets的日志。
4.3 重点是该SQL为什么运行时间这么久呢?我们通过运行SQL获取执行计划和我们采用perf top+top -H的方式来看看内部的函数调用。发现如下:
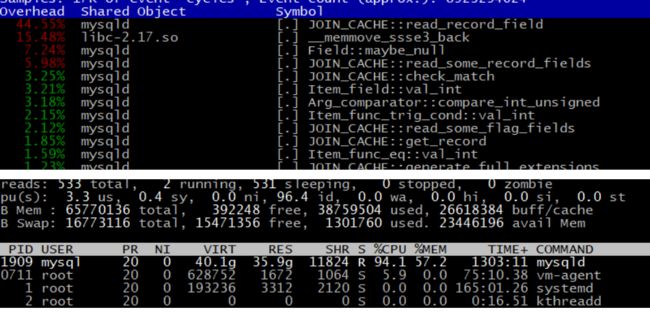

结合资源占用情况可以看到占用cpu资源最大的函数是:JOIN_CACHE::read_record_field
结合执行计划看sub_part、tsf、cat使用了临时表和join_buffer,试图分析i_s.files无果,该试图中大多是数据字典,无法访问。
这可能和我们系统中存在大量ibd文件有关。肯定很多同学会问,为什么会有这么多ibd,因为我们大量使用分库、分表、分区。
我们知道join cache 一般用在两表join连接,被驱动表没有索引的情况下,将驱动表的数据放到join cache中,当join cache满了以后驱动一次被驱动表,以此来减少被驱动表全表扫描的次数,进而提高性能。
其次我们需要知道的MySQL虽然某一个线程负载高但是,一个线程只能使用CPU核心,我们监控监控的是整体的CPU,因此虽然一个CPU已经达到99%的高负载,但是整体平均下来也不那么明显,这是我行以后监控需要持续改进的地方。
5. checking permissions的疑惑
很明显上面的分析我们发现语句实际已经执行了,但是为什么处于checking permissions状态呢?为了解开这个疑惑,我们需要将断点放到THD::enter_stage和JOIN_CACHE::read_record_field上,当然这部分我们没有深入的研究,只看debug状态,debug 什么呢,只要证明状态 executing 后进入了checking permissions状态且在checking permissions状态下执行了JOIN_CACHE::read_record_field即可如下:
这里证明了语句已经进入了执行阶段,但是每次读取一行join cache的记录转换一次状态为checking permissions,栈如下:

我们来看红色函数的注释如下:
INFORMATION_SCHEMA picks metadata from new DD using system views.显然这里和访问information_schema中的数据有关,因为这里涉及到information_schema和数据字典的实现,过于庞大,我们不做研究了。
但是我们得出一个结论,对于访问字典视图,出现比较奇怪的状态,我们应该用perf top或者pstack获取信息,而不能停留在常规的认知上。
6. 探索优化思路
肯定有同学想问mysqldump为什么要执行上面这个SQL呢?这个还需要备份厂商来解释了,该SQL在备份中还不能短时间改善,银行是非常注重备份,不可能等厂商改,所以我们放弃该思路
既然厂商无法调整,那我们就从数据库本身着手,SQL属于内部试图,我等源码基础也不好,无奈啊!只能从执行计划和占用高资源得函数着手,既然join_cache这么高,且执行计划中提示使用了join_buffer和临时表,那么我们来试图调整join_buffer_size,当前默认是2M,将join_buffer_size调整后再次执行SQL,SQL运行1min7s,效果明显。
至此,我们已经找到优化思路,调整数据库join_buffer_size来解决,肯定有同学问,这个也不能随便调整啊,因为这是一个session级别的参数,可能导致MySQLD使用内存大幅增加。但是,我们架构中设计的这个库是专门用于全备的,没有任何应用连接,所以可以调整该参数。再次发起数据库备份,观察几天时间,该问题不再发现。透过事物看本质发现,mysql中在有大量的表或分区情况下,在通过内部试图、数据字典读取操作系统中文件时可能会存在有各种性能问题,对于某些查询操作我们可以在备库进行,尽量减少对主库的冲击。
7. 补充:关于几个timeout参数生效点
接下来我们也研究了几个timeout参数, 如果出现超时遇到了日志是Got timeout reading communication packets,而不是Got an error reading communication packets。实际上几个timeout 参数都是通过poll的timeout参数实现的,我们稍微总结了一下如下:
连接进行握手,连接时poll的timeout受到connect_timout影响
loop 进入死循环
wait_timeout/interactive_timeout 参数设置poll timeout参数
堵塞等待命令来到
命令来到退出堵塞。
命令执行期间读写更改poll的参数,受net_read_timout和net_write_timeout参数影响
命令执行
命令执行完成后,再次做wait_timeout/interactive_timeout参数检查并且恢复
goto loop
因此总结一下:
Got timeout reading communication packets:可能和参数connect_timout,net_read_timout,wait_timeout/interactive_timeout 有关
Got timeout writing communication packets:可能和参数net_write_timeout有关
《实战MGR》视频课程
视频已全部上线,这是免费视频,放在腾讯课堂平台上,共有500多人报名学习了。
目前是第一期内容,相信有很多不足,甚至错漏的地方,也欢迎各位不吝留言帮忙提建议、意见,帮忙改进完善,感谢。
戳此小程序即可直达
或用微信/QQ扫码

或复制链接在浏览器中打开 GreatSQL社区《实战MGR》https://ke.qq.com/course/3677969
文章推荐:
面向金融级应用的GreatSQL正式开源
Changes in GreatSQL 8.0.25 (2021-8-26)
GreatSQL重磅特性,InnoDB并行查询优化测试
MySQL DDL简析(1):inplace DDL 主要stage介绍
Percona XtraBackup 8.0.26实战大全
一条sql语句慢在哪之抓包分析
技术分享 | Update更新慢、死锁等问题的排查思路分享
GreatSQL重磅特性,InnoDB并行并行查询优化测试
在Linux下源码编译安装GreatSQL/MySQL
扫码加入GreatSQL/MGR交流QQ群

点击文末“阅读原文”直达老叶专栏