深度学习(李沐)——学习笔记(一)
线性回归从0开始实现
Pytorch中的基本数据类型就是各式各样的张量,张量可以理解为多维矩阵。Pytorch中定义了一个Tensor类来实现张量,Tensor在使用上与numpy的ndarray类似,不同的是,Tensor可以在GPU上运行,但是numpy只能在CPU上运行,当然numpy与Tensor可以进行相互转换,以此使得numpy数据在GPU上运行。Pytorch中的Tensor又包括CPU上的数据类型和GPU上的数据类型,两种数据类型之间也可以进行相互转换
requires_grad是Pytorch中通用数据结构Tensor的一个属性,用于说明当前量是否需要在计算中保留对应的梯度信息
torch.rand和torch.randn有什么区别
一个均匀分布,一个是标准正态分布。


np.random.normal()的意思是一个正态分布numpy.random.normal(loc=0,scale=1e-2,size=shape) ,意义如下:

生成数据集
features = torch.randn(num_examples, num_inputs)
print(features[:, 0])
注意这输出的不是二维数组([[1],[2]])这种,输出的是一维数组([1,2,3])这种
噪声代表了数据集中无意义的干扰:
随机噪声项来生成标签,其中噪声项服从均值为0、标准差为0.01的正态分布
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
random.shuffle()
用于将一个列表中的元素打乱
a =[10,20,30,40,50,60]
random.shuffle(a)
print(a)

python中yield的用法详解
torch.index_select
torch.index_select(features,0, j)
等价于
features.index_select(0,j)
第一个参数是索引的对象,第二个参数0表示按行索引,1表示按列进行索引,第三个参数是一个tensor,就是索引的序号,比如b里面tensor[0, 2]表示第0行和第2行,c里面tensor[1, 3]表示第1列和第3列。
自动求梯度
Tensor是这个包的核心类,如果将其属性.requires_grad设置为True,它将开始追踪(track)在其上的所有操作。完成计算后,可以调用.backward()来完成所有梯度计算。此Tensor的梯度将累积到.grad属性中。
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
torch.mul() 和 torch.mm() 的区别

PyTorch中view的用法
把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。比如:
y=torch.tensor([[1,2,3,4],[2,3,4,5]])
print(y)
x=y.view(8)
print(x)
z=y.view(4,2)
print(z)
torch自动求导
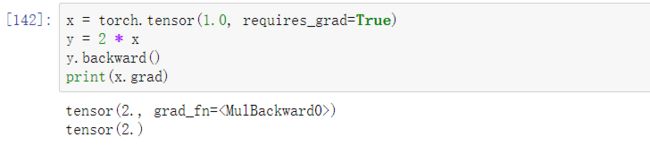
当求导函数是一个标量:
所以调用backward()时不需要指定求导变量
x = torch.tensor(1.0, requires_grad=True)
y = 2 * x
y.backward()
print(x.grad)
当求导函数不是一个标量时:
所以在调用backward时需要传入一个和y同形的权重向量进行加权求和得到一个标量
x = torch.tensor(1.0, requires_grad=True)
y = 2 * x
y.backward()
print(x.grad)

全部代码实现
生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
读取数据
# 本函数已保存在d2lzh包中方便以后使用
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
初始化模型参数
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
定义模型
def linreg(X, w, b): # 本函数已保存在d2lzh包中方便以后使用
return torch.mm(X, w) + b
定义损失函数
def squared_loss(y_hat, y): # 本函数已保存在pytorch_d2lzh包中方便以后使用
return (y_hat - y.view(y_hat.size())) ** 2 / 2
定义优化算法
def sgd(params, lr, batch_size): # 本函数已保存在d2lzh_pytorch包中方便以后使用
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
训练模型
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
# 在每一个迭代周期中,会使用训练数据集中所有样本一次(假设样本数能够被批量大小整除)。X
# 和y分别是小批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum() # l是有关小批量X和y的损失
l.backward() # 小批量的损失对模型参数求梯度
sgd([w, b], lr, batch_size) # 使用小批量随机梯度下降迭代模型参数
# 不要忘了梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
print(true_w, '\n', w)
print(true_b, '\n', b)
理解损失函数中的代码:
(y_hat - y.view(y_hat.size())) ** 2 / 2
y_hat的形状是[n, 1],而y的形状是[n],两者相减得到的结果的形状是**[n, n]**(用到了广播机制),相当于用y_hat的每一个元素分别减去y的所有元素,所以无法得到正确的损失值
理解优化函数中的代码
如果用如下方式
def sgd(params,lr,batch_size):
for param in params:
param-=lr*param.grad


也就是说torch变量带requires_grad 的不能进行+=操作
此时只需要将param改为param.data就行
def sgd(params,lr,batch_size):
for param in params:
param.data-=lr*param.grad
*unsupported operand type(s) for : ‘float’ and ‘NoneType’
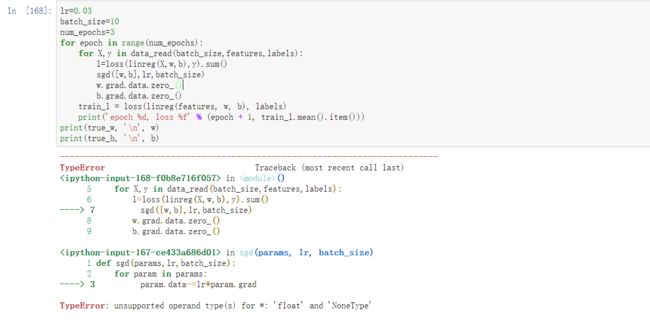
是由于忘记加l.backward()导致