数据仓库综述
1. 传统数据和数据仓库
1.1 数据仓库和传统业务数据库
业务数据是面向业务处理,即事务处理的—OLTP。
数据仓库是面向业务分析,决策—OLAP。
面向主题,集成,非易失(作为业务数据的冷却数据,所以保存要一致)
所以,根据不同的特点,其存储结构有着巨大差异。
传统业务数据库是事务型数据库,支持保证业务的流畅处理,所以业务控制精细。
但,容量有限。
数据仓库,以只读为主,基本很少更新,侧重点是大容量,快速的聚合和统计。
一般的操作,会把业务数据中的非热点数据迁移到仓库中,业务数据只保留业务自身数据。
另外,还有一个差异,业务数据,在一个公司内部,通常时多个的,而且格式不尽相同和统一,这个好理解,格式优先满足各个不同的业务需要。但是数据进入仓库后,就是统一的,规范的,满足统一的融合分析。
1.2 Mmp数仓和分布式数仓
MMP就是传统数仓,就是把单机数据库改成集群数据库。

单个节点包含了数据和计算,节点间并发计算,如果关联数据,就迁移数据,节点间可以调用其他节点数据。
数据量不能太大。
1.3. 分布式数据
数据和计算是分离的,数据是分布式存储。建议是数据不迁移,迁移算法。
数据共享,把算法分发下去再汇总
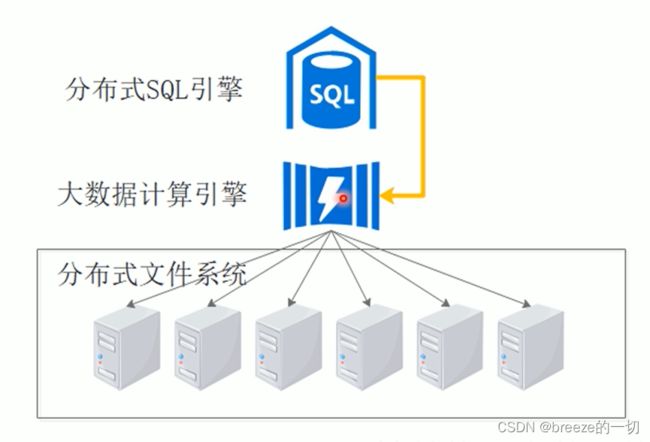
问题是,算法调度,分片,汇总,管理,本身就很重,无论计算数据多大。
所以,如果数据量不大的时候,很重的调度计算汇总,就非常不划算。
2 数据仓库的架构
2.1. 概述

ETL 负责迁移数据
ODS 就是业务数据的克隆部分,不对数据修改。
DWD 就是详细数据,对原始数据进行清洗整理。
DWS 就是为业务数据做简单的汇总,比如汇总所有用户属性的大宽表,中间建模。
ADS 就是面向业务的面向业务的具体分析。
2.2. ETL
2.3. ODS层

冷却数据要修改,也支持两种方法。
一个是有新数据进来,插入一条新数据,然后删除原来的老数据。然后update_type是UPDATE类型
另外一种方式,用外连接。
2.4. DWD
数据明细,就要开始对原始数据的改造了。
首先,要清洗不合规的数据。
其次,维度退化,把关联表合并成一个大的宽表,增加属性。同理不同业务部门的同样对象描述,也进行合并操作。
再次,数据格式进行统一化处理,比如性别,统一格式类型。
再再次,合并数据,比如来自不同地区的数据。
2.5. DWS
面向汇聚统计的主题,做适度的汇总,便于后续进一步的分析操作。
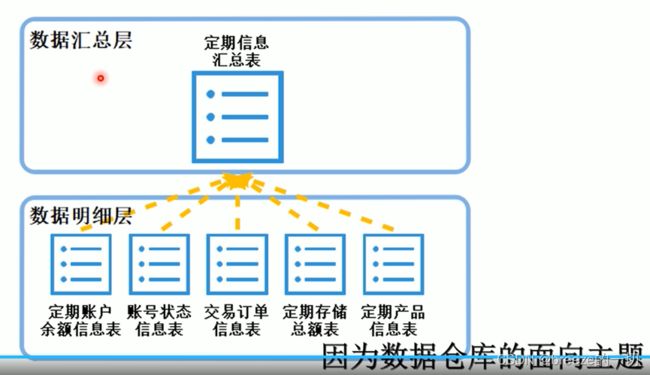
2.6. ADS
ADS实际就是把DWS分析的结果写入到结果表中,便于外部的查询

3 建模方法
3.1. ROLAP
ROLAP通常用维度分析法。
就是建模的时候,分成事实表和维度表。
维度其实就是筛选的时间,把所有的筛选条件做成一个维度表。
做成维度的时候,在实际应用的时候,又会把这些维度表整合成一个大的宽表。
3.2. MOLAP
他提前将数据统计数据先统计好,后面再汇总的时候,就会非常的快。


3.3. 多维分析
钻取
就是切换维度,由高维度转成低纬度查询就是下钻。
由低维度转成高维度就是上卷
比如,原来按月查询,数量太少,改成按年份查询
切片
就是按照一个高维度查询后,其结果再按照其他维度进行一次拆分。

切一个维度就是切片,多个维度切就是切块
旋转
改变查询条件的先后顺序
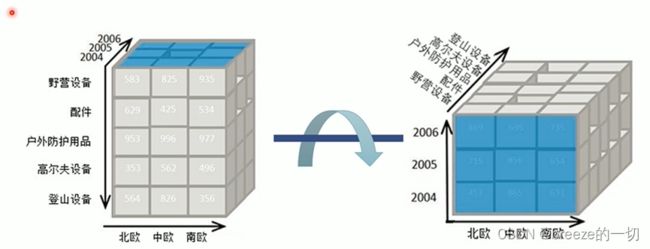
比如,先查询查产品类型,再查询时间。
旋转则变成先查询时间再查询类型。
4 任务调度

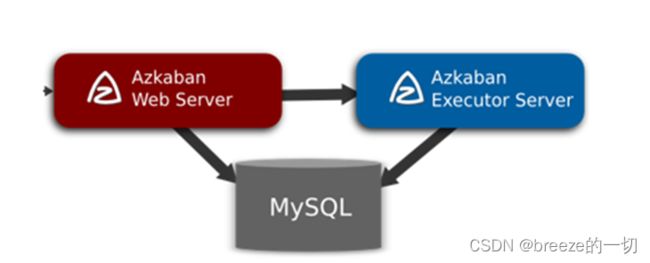
用现成的工具,比如Azkaban比较好
4.1. 安装
前置软件安装
新版本的azkaban不是手动解压缩的,而是通过下载源代码进行打包编译安装的。
首先,需要jdk。需要安装jdk,并且设置好对应的home目录。
其次要安装git 通过 yum install -y git安装
Azkaban整体架构
获得软件
进入官网,下载部分,https://azkaban.github.io/downloads.html
这个页面会最终导航到git上
https://github.com/azkaban/azkaban/releases
进入这个页面,下载里面的源码,比如zip版本
但azkaban是要源码编译的,但是当前他们的仓库是自建的仓库,而他们的自建仓库已经被移走了,所以,他们家的代码目前最新的安装方法就是取main分支下来编译。
编译构建
解压,然后开始编译
构建项目:
sudo ./gradlew build -x test
想废掉,恢复的话,可以:
sudo ./gradlew clean
运行模式说明
solo mode modemode
用于测试工作流的开发
最简单的模式:类似于本地模式
不使用MySQL存储元数据,用自带的H2数据库来存储元数据
webserver和ExecServer都在一个JVM中
two server mode
Azkaban在3.x稳定之前最多的模式
用MySQL数据库来存储元数据
WebServer和ExecServer是独立的进程,运行在不同的JVM中
一个WebServer节点、一个Exec节点
Multiple executor mode
相比较于Two Server模式的区别:该模式支持多个ExecServer。
3.0版本之后才支持的功能。
Solo模式
构建后,可执行包在:
azkaban-4.0.0/azkaban-solo-server/build/distributions
这里有两类压缩包,zip的tar.z的,应该都可以。
把文件拷贝出去到要安装的目录中,然后解压。
安装结束。
启动
一定要在跟目录下,不要在bin目录下:
sudo ./bin/start-solo.sh
two module 模式
mysql数据库
元数据要存储到这里,所以要先把数据库初始化好:
##解压 azkaban-db-0.1.0-SNAPSHOT.tar.gz压缩包
tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz
cd azkaban-db-0.1.0-SNAPSHOT
##登陆MySQL数据库
mysql -uroot -p
##创建azkaban的数据库
create database azkaban;
##创建azkaban的用户名
create user 'azkaban'@'%' identified by 'azkaban';
##对azkaban用户进行授权操作azkaban数据库
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
##刷新权限
flush privileges;
##执行azkaban-db-xxx目录中的建表语句
use azkaban;
source /root/create-all-sql-0.1.0-SNAPSHOT.sql;
坑:
首先azkaban用的是5.x的mysql数据库,无法使用8.x的数据库!即便是换了jdbc包也不行。
最快速的方式就是安装docker然后启动mysql,但是如果用docker的话。Mysql客户端:
mysql -uroot -p
是连不上的,因为这个客户端用了一个什么socket一旦判断是本地的,就要跑到mysql的安装目录下找socket文件。Docker安装的显然没有这个文件,所以启动失败。正确的方式是:
mysql -h127.0.0.1 -uroot -p密码
注意,一定要用127.0.0.1
安装webserver
到安装包中解压azkaban-web-server-0.1.0-SNAPSHOT.zip
放到对应的目录中。
在4.0中,支持不用ssl。建议不要用,因为没有域名,自己申请个假域名,还不如不申请。
解压后,直接改配置文件:
vi conf/azkaban.properties
有几个地方要修改:
web.resource.dir=/usr/local/Azkaban/azkaban-web/web/----这个地方改成绝对路径
default.timezone.id=Asia/Shanghai---这个地方改成对应时区
user.manager.xml.file=/usr/localhost/azkaban/conf/azkaban-users.xml ------改成绝对路径
jetty.use.ssl=false --不用ssl
jetty.maxThreads=25
jetty.port=8443 ------web的端口
----以下是几个mysql的配置
database.type=mysql
mysql.port=3306
mysql.host=192.168.50.1
mysql.database=azkaban
mysql.user=azkaban
mysql.password=azkaban
mysql.numconnections=100
安装exec
azkaban-exec-server-0.1.0-SNAPSHOT.zip
解压
然后直接编辑里面的配置文件:
vi azkaban.properties
web.resource.dir=/usr/local/azkaban/azkaban-web-server/web/ ---很奇怪,但这个要改成绝对路径
user.manager.xml.file=/usr/local/azkaban/azkaban-web-server/conf/azkaban-users.xml—绝对路径
jetty.port=8111 ---这里一套是改成web的端口
# Where the Azkaban web server is located
azkaban.webserver.url=http://localhost:8111
---然后是mysql的一套配置
mysql.port=25000
mysql.host=df
mysql.database=azkaban
mysql.user=azkaban
mysql.password=azkaban
mysql.numconnections=100
executor.maxThreads=50
executor.flow.threads=30
executor.port=12321 ---这个要手动加上去,其他executor的配置是默认的
executor.props.resolve.overrideExisting.enabled=false
坑:
exec是配置里面jetty.port=8111,azkaban.webserver.url=http://localhost:8111
是无用配置来的。
真正侦听的端口不是这个8111而是后面executor.port的12321这个。
启动
一定要先启动exec
bin/start-exec.sh
然后要手动激活一次
curl -G "[ip]:$(<./executor.port)/executor?action=activate" && echo
例如:
curl -G "127.0.0.1:$(<./executor.port)/executor?action=activate" && echo
然后再启动web
bin/start-web.sh
访问改过的那个端口进入
使用
创建工程

然后上传job
helloC.job文件如下(扩展名一定是job)
type=command
command=echo ‘hello’
然后选中文件,直接打包成zip包。
到页面上上传:
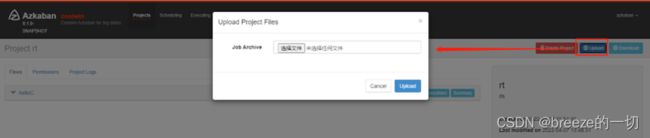
上传后,执行execute flow,就可以运行并看到结果
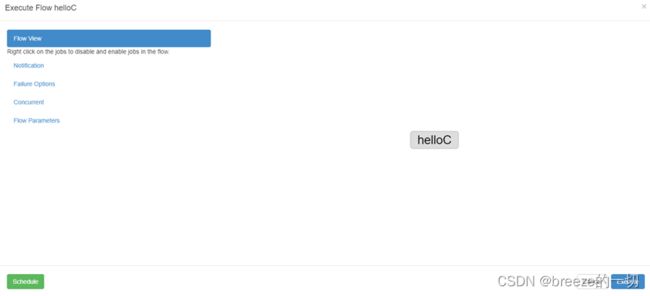
左边schedule是调度用的
右表execute是立即执行
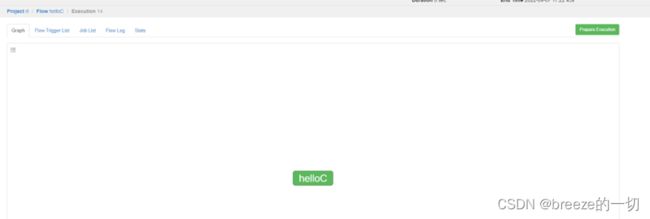
这个就是执行结果。绿色表示执行成功。
红色是失败。
灰色是pending。
上面可以看日志:
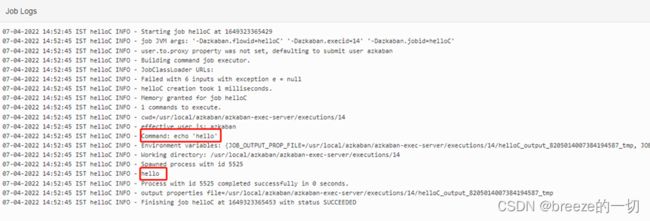
hello就是大屏信息内容
这里有一个巨坑:
type=command
这里command后面,千万千万千万,不能有空格,否则会失败,失败原因是找不到对应的类型:

如果要多个作业:
再来一个helloD.job
type=command
dependencies=helloC
command=echo bar
然后helloC.job和helloD.job一起打包到一个zip文件上传,执行。就可以看到结果了。
当然这里要注意
dependencies=helloC
千万不要写错,写错了,就认为两个没有关联,上传后,就会被丢到两个不同的flow中了。
就是说,一个project支持多个flow的。如果你设置了关联,那么就会认为在一个flow里面。
下面,来一个高难度的,就是用python文件调度。
文件内容如下:
azkabantest目录其实是python的模块目录,这个是便于测试python多模块执行的功能
里面的内容如下:

def show(str):
print(str)
helloA.py
import azkabantest.showWord
import sys
import os
azkabantest.showWord.show(sys.argv[1])
# 下面写入参数环境
filename = os.getenv("JOB_OUTPUT_PROP_FILE")
param = '{"myparam":"ok!"}'
f = open(filename, 'w')
f.write(param)
f.close()
这里有一点注意的,就是环境变量JOB_OUTPUT_PROP_FILE是用于上一个job和下一个job之间传递参数用的,可以把这些个参数写入到这个环境变量所指定的那个文件中,注意,内容必须是json格式,是一个严格要求的json格式,参数必须是”不是能是’
helloB.py
import azkabantest.showWord
import sys
azkabantest.showWord.show(sys.argv[1])
没啥特别的
再看两个job
helloA.job
type=command
command=python3 helloA.py a z k a b a n . f l o w . s t a r t . y e a r − {azkaban.flow.start.year}- azkaban.flow.start.year−{azkaban.flow.start.month}-${azkaban.flow.start.day}
$…后面的参数,是azkaban支持的年月日的参数信息
helloB.job
type=command
dependencies=helloA
command=python3 helloB.py ${myparam}
${myparam}
其实就是在helloA.py中输出到指定文件中的参数,这个可以加载到azkaban环境里面。
然后把这些内容,打包上传。执行。即可。
这里有个配置的坑:
在web模块中的配置文件
azkaban.use.multiple.executors=true
//execute主机过滤器配置
azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
其中MinimumFreeMemory过滤器会检查executor主机空余内存是否会大于6G,如果不足6G,则web-server不会将任务交由该主机执行。这样,执行的job会是灰色,一直处于pennding状态。
job参数
参数 说明
azkaban.job.attempt job重试次数,从0开始增加
azkaban.job.id 运行的job name
azkaban.flow.flowid 运行的job的flow name
azkaban.flow.execid flow的执行id
azkaban.flow.projectid 工程id
azkaban.flow.projectversion project上传的版本
azkaban.flow.uuid flow uuid
azkaban.flow.start.timestamp flow start的时间戳
azkaban.flow.start.year flow start的年份
azkaban.flow.start.month flow start 的月份
azkaban.flow.start.day flow start 的天
azkaban.flow.start.hour flow start的小时
azkaban.flow.start.minute start 分钟
azkaban.flow.start.second start 秒
azkaban.flow.start.millseconds start的毫秒
azkaban.flow.start.timezone start 的时区
flot文件
从上面可以看出,一个job对应一个命令。多个命令组合成一个flow
4.2. 参考文档
https://blog.csdn.net/wangqinyi574110/article/details/118199988
https://blog.csdn.net/helloxiaozhe/article/details/81224501
5 仓库建设
5.1. 概述
仓库有多种,实时仓库和离线仓库。
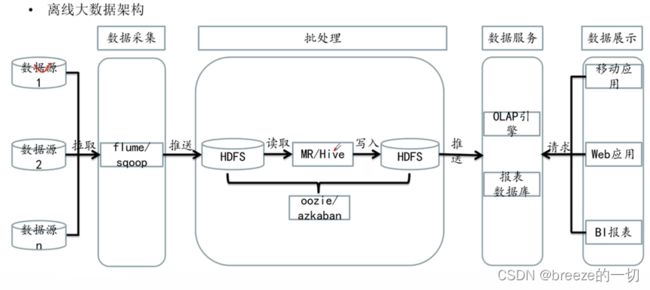
离线仓库结构如下:
实时仓库结构如下:
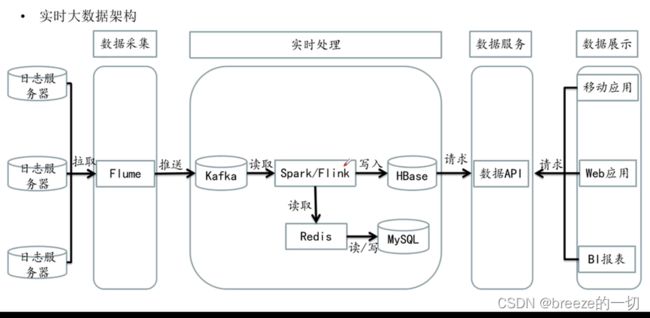
实时仓库技术积累不多,相对没有离线仓库那么成熟,方案多变。
整体的处理架构如下:

6 其他一些大数据各个层的工作工具
使用 Flume 采集日志数据
使用 Sqoop 采集数据库数据
Maxwell和 Canal 同步数据库业务表
熟悉 Finereport、FineBI 可视化报表制作工具
使用 kettle 完成数据抽取
Spark创建任务
流式计算引擎:spark,flink
调度用Azkaban

