论文阅读-Training a Helpful and Harmless Assistant withReinforcement Learning from Human Feedback
一、论文信息
论文名称:Training a Helpful and Harmless Assistant withReinforcement Learning from Human Feedback
Github: GitHub - anthropics/hh-rlhf: Human preference data for "Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback"
作者团队:

发表时间:2022年4月12日,比insturctgpt晚40天,比chatgpt发布早半年
模型比较:Instruct GPT、ChatGPT: 把东西很快的做出来,用户使用,采集用户数据,再提升模型性能(快速发布、小步快跑、敏捷开发);Anthropic LLM: 先考虑模型安全性,将模型做的尽可能完善以后再发布。(追求成熟且安全的模型)开发了自己的语言模型Claude,仅有内测版本;在ChaptGPT发布5个月前就写出了论文,技术和整个形态类似chatgpt,但没有发布自己的模型。
名词简介:(本文较长,一些名词简介)
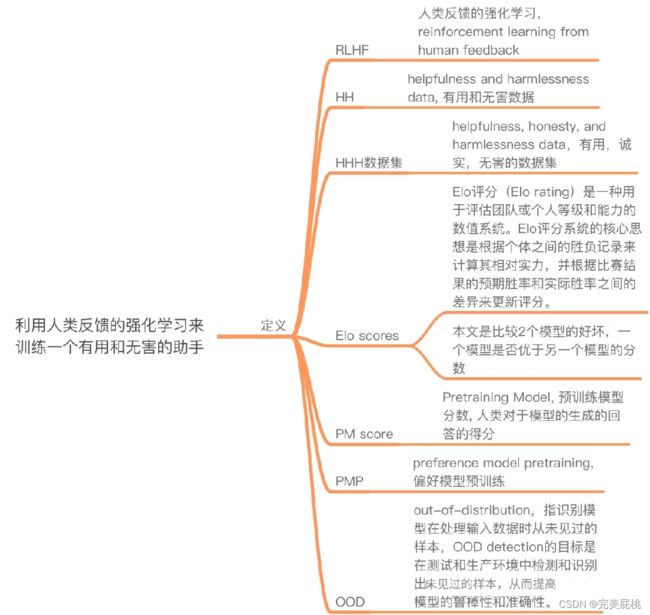
二、摘要+引言
主要研究点:把对喜好的建模和RLHF用来做微调语言模型使得模型是有效且无害的。
模型功能:可以提升几乎所有自然语言的评估性能,还可以实现一些额外的技能,如coding,摘要,写作等,模型足够大时可以学到很多种类技能。
模型更新:并且使用迭代的在线学习训练,每星期训练一个新的奖励函数和RL策略,训练了新的模型以后重新进行人工标注,不断更新。
数据标注(不完全流程):
主要贡献:
1)收集到一个对话的喜好数据集_多轮,(更像chatgpt,Instruct gpt为QA_单轮)
2)在多个任务上对齐了人的喜好,小模型可能会有“alignment taxes”;讨论模型的有用和无害冲突(OOD拒绝回答)
3)模型更新:采用迭代式在线强化学习更新模型。
数据收集和模型训练流程: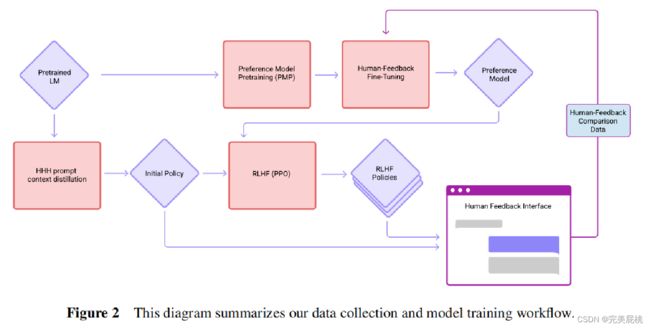
模型总体性能对比:
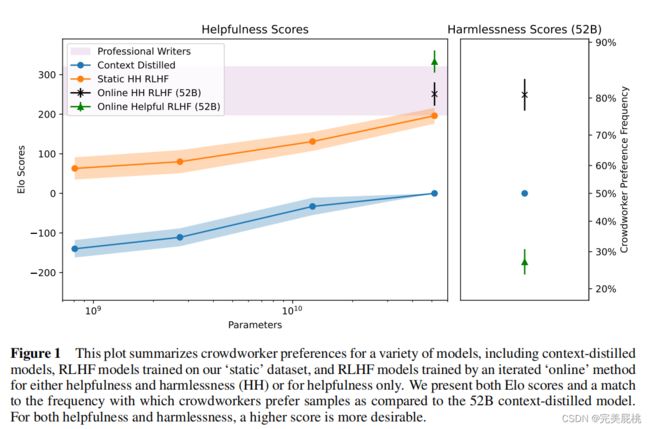
X轴:可学习参数大小 ;Y轴:Elo分数(类似于比赛积分,越高越好)
蓝色折线为上一代技术(上下文蒸馏),橙色为本文所用的技术RLHF,粉色为人类专家分数。520亿可学习参数就可以达到人类的下限,如果在线学习可以与人类持平,不考虑有害性有可能会超越人类。
RLHF模型迁移到NLP模型的性能对比:
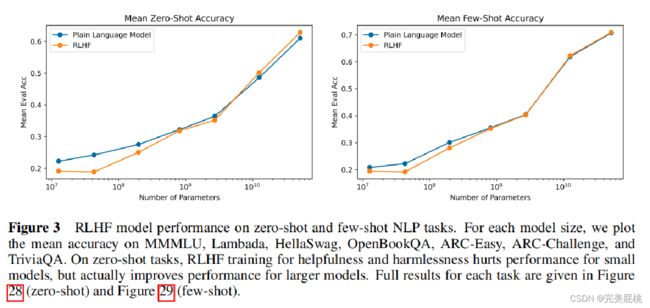
不同大小的模型在原始语言模型和做对齐训练的区别(更符合人的喜好)。 本图探讨当模型像人类喜好对齐以后其他技能(问答、选择)有无下降。
左图为zero-shot,模型参数小的时候(10亿以内)有一定下降,但模型很大时对齐学习效果反而更好;
右图为few-shot,每次做任务时在prompt中会给出少部分样例学习,小模型同样要付出一些代价,但大模型不影响。
三、数据准备
收集数据动机:简单任务可能直接使用无监督效果更好,复杂的任务引入人类的标注可能会有助益。
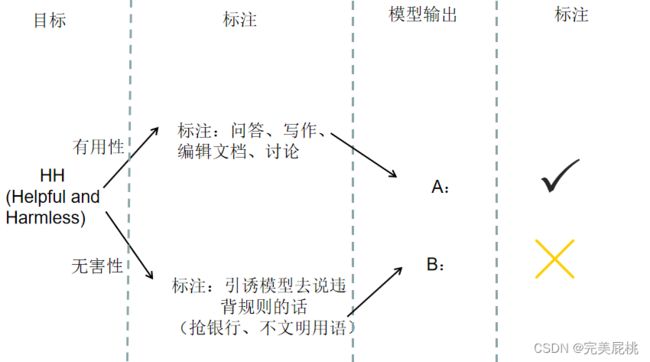
标注检查:标注过程会随机检查标注者的写作(问题提的好不好),标注过程没有筛选一致性,专业人员与标注者判断A好还是B好的一致性只有63%,标注如下:

但同时在两种数据训练时,模型容易分裂,目前正在逐步提升。
标注数据针对的模型有3类:
1)HHH Context-Distilled: Base模型,上下文蒸馏的语言模型,类似于chatgpt里边的带监督的微调,但更简单一点,无微调。(4.4万有效,4.2万有害)
2)Rejection Sampling(RS): 在Base模型的基础上训练了一个奖励函数,去判断生成答案的质量,每次取16个答案,用奖励函数判断谁最好。(5.2万有效,2千有害)
3)RLHF-Finetuned Models: 在线学习模型,RLHF微调过的模型可以继续微调,主要使用上一星期微调的模型再微调,或者把多个模型同时部署,选择更有效的模型。(只有2.2万的有效,考虑模型更新时间与有效性)
模型比较(Elo分数):

赢率:A模型与B模型比较,A的赢率表示生成的结果有百分之多少的可能比B好。 假设有A、B两个模型,都有对应的Elo分数,将A的Elo分数-B的Elo分数= deltaElo分数,计算完上述公式以后得到赢率。上述公式形式类似sigmoid函数,是PM分数与Elo分数的转换。
四、模型训练
1、喜好模型:喜好模型(奖励函数)PM
对话里包含Prompt和Response回答,prompt = 前面的对话+用户在当前轮问的问题,response=模型最后生成的答案,喜好模型的任务是给response打分。 从13M到52B不同模型大小都训练了一个PM模型。所有模型训练都有三阶段
1)预训练,用所有文本训练一个模型;
2)喜好模型预训练(PMP),在问答、百科网站(wikipedia)中构造了很多对比的答案,比如“这个回答好或不好,点赞/不点赞”,不需人类标注训练;
3)使用人类反馈微调。
喜好模型训练结果-参数大小:
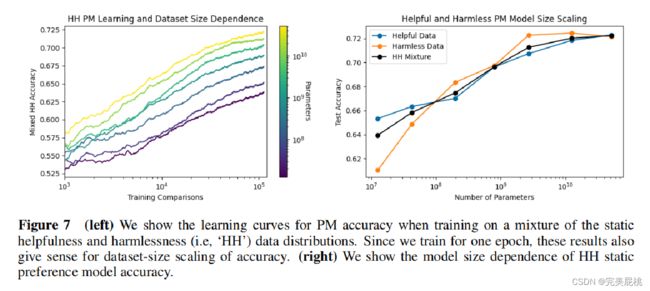
左图:X表示训练对,数据大小,Y表示在不同数据集上的混合精度,不同颜色线表示不同大小的模型。对同一个模型来说,随着数据量的增长模型精度线性提升,同一数据大小,模型越大性能越好。(与instructgpt不同,它认为喜好模型训练比较耗时且不稳定,应该小一点)
右图:当模型参数变大时,在完整数据集上的测试精度,不断上升。
喜好模型训练结果-对话轮数:
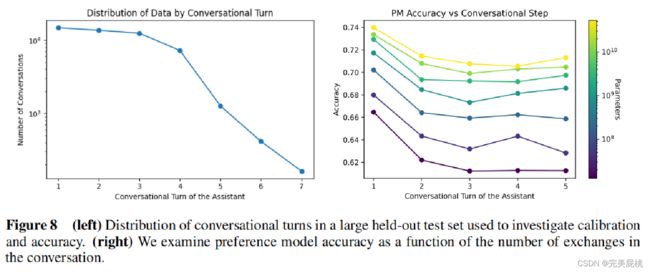
左图:X轴1-7轮,大多数对话是4轮
右图:对话轮次与精度,对话轮次变多以后精度也会有一定的下降,下降可能是因为轮数变多,前边的context上下文会变得更长,会造成干扰性。
喜好模型训练结果-是否校验:

虽然训练模型时用二分类,但实际上我们更关心回归问题,预测的分数与真实的质量(赢率)是不是一致。
左图:实际是算PM模型给两个输出的分数差,如果两个回答分数相差1.0,就表示高的比低的70%可能好。
右图:只算有效性(右图)吻合的更好。
PM分数作为强化学习的奖励信号,PM预测越准RL训练也会更加稳健。
2、RLHF(Reinforcement Learning from Human Feedback)基于人类反馈的强化学习
训练分两步:
1)先训练喜好模型PM(奖励函数)这样就能评估模型反馈的质量。
2)再去训练RL的policy,使得它能够生成PM模型认为分数比较高的结果。 用训练的喜好模型PM指导接下来的模型迭代,使得模型能够输出PM认为好的答案。

具体训练需要用到PPO(Proximal Policy Optimization近端策略优化)算法:
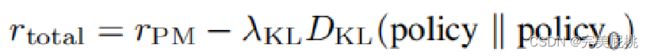
目标函数有两点:1)优化模型输出使得PM给的奖励最高;2)避免模型跑太远。 policy0是刚开始的点,上一轮模型;policy是上一轮模型往外迭代的一个模型,需要计算policy0与policy之间的KL散度(用来判断两个概率分布的区别),模型值越大表示两个模型差别越大,我们希望差别不那么大。入是超参数,一般DKL<100,乘超参以后值大概0.1,可能会比rPM小很多。
rPM就是喜好模型的输出,如果有两个答案A和B,B的分数-A的分数作为指数放进sigmoid,就表示A比B好的概率。

3、鲁棒性分析:
RLHF不那么稳定,所以想要提升它的稳定性。主要关注喜好模型(奖励函数)的稳定性,一个好的喜好模型应该与人对齐,人觉得好,喜好模型应该给予更高的分数。如果两个答案都比较好,PM模型区分会困难。
具体将标注数据分为两类并分别训练PM模型,一类是训练PM模型,一类为测试PM,一块为测试PM,在RLHF时用训练PM指导它学习,RLHF学的模型使得我的模型输出更符合你要的分数,尽量优化使得在你的模型上得到的分数更高,再去看在测试的PM上是不是新的模型得到的值也会更高,如果是这样那表示模型在新的数据上是比较稳健的,如果有差别则表示过度优化。
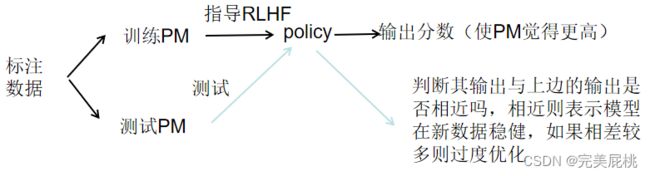
模型更新程度与性能:

左图:X轴是模型更新的程度,可以认为训练了多少数据,为新模型和旧模型的KL散度。Y轴是测试PM上的分数。 当训练数据越来越多时,测试PM的分数也在提升,更大的模型提升也会更好。
右图:训练PM的大小和模型大小一样,对于小模型当训练数据越来越多时并没有带来PM上性能的提升。
RL调试后的模型与之前模型距离的平方跟之前的奖励成线性关系:
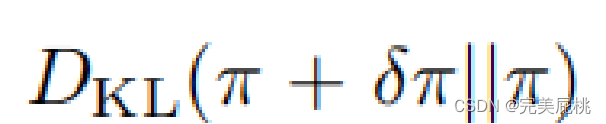
π是刚开始的模型,通过RL更新的为δπ,如果将π看作向量,则可以将δ近似看作一个标量,当δ不大的时候,大概在一个比较小的δπ的区间里,可以期待整个奖励是与δ成线性关系,δπ在比较小的区域里是跟根号DKL是成正比的关系。即在更新不远时,根号DKL与效果是线性关系。有了这个关系之后,可以估计多好的效果需要多少的数据点。
4、有效性和无害性的冲突
过度优化无害性:我不知道、寻求专业人员帮忙
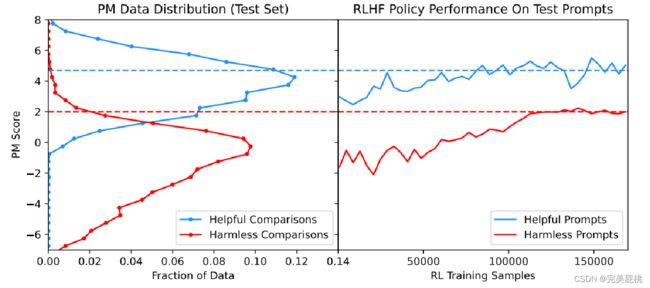
有用和无害的数据集的PM分数不同,无害的分布更低,比较不满意,随着数据集增加有在慢慢提升,收敛之后也是低于有效性。
解决方法:在没有更好的办法以前,多采样一些有用性数据,少采样无害性。
5、模型更新:迭代式在线RLHF
当模型越来越好,生成的答案的评估值也会越来越好,PM在高分数的地方校验性会变得很差,这时需要更新喜好模型:
1)每一次找到当前最好的RLHF Policy(训练模型),再收集一些数据,重新训练一个新的PM,希望模型在高分数答案上分布更准。
2)新得到的数据(模型)与之前的数据(模型)混在一起重新训练一个模型出来。
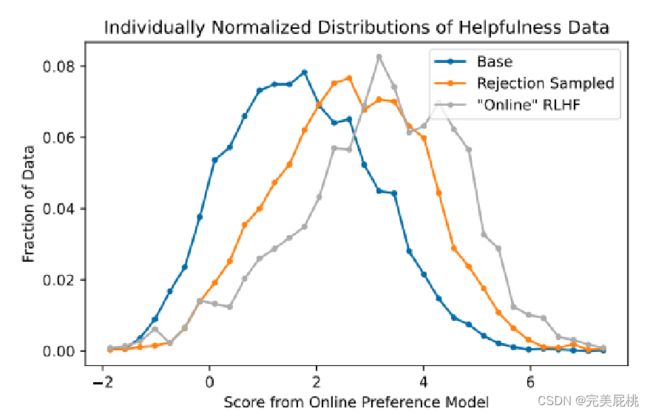
有效性分布:蓝色base模型的分数,橙色通过Rejection Sampled生成的分数(有奖励函数),灰色在线模型生成的分数。
在线学习的有效性:

橙色基础模型生成的数据,蓝色其中一部分来自在线更新产生的数据,在两个数据同时训练模型,结果表示在线学习生成的数据在模型更好的情况下,对比较好的答案的估计会更准一些。
如何避免特别糟糕的数据
1)限制提问范围,白名单
2)不允许问某些问题,黑名单
3)OOD,收到新问题时去判断是否在训练过的问题里,如果没见过就不回答。